






phoenix
1.文档编写目的
- 内容概述
- 安装及配置Phoenix
- Phoenix的基本操作
- 使用Phoenix bulkload数据到HBase
- 测试环境
1.CDH6.2
2.Centos7.9
3.Phoenix5.0.0
- 前置条件
- CDH集群正常运行
- HBase服务已经安装并正常运行
- Centos中的httpd服务已安装并正常使用
2.在CDH集群中安装Phoenix
1.下载Phoenix的Parcel,具体需要下载的三个文件地址为:
在/var/www/html/下创建Phoenix_Parcel目录并下载所需要的文件
wget https://archive.cloudera.com/phoenix/6.2.0/csd/PHOENIX-1.0.jar
wget https://archive.cloudera.com/phoenix/6.2.0/parcels/PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el6.parcel.sha
wget https://archive.cloudera.com/phoenix/6.2.0/parcels/PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el6.parcel
2.可以用浏览器打开页面进行测试。
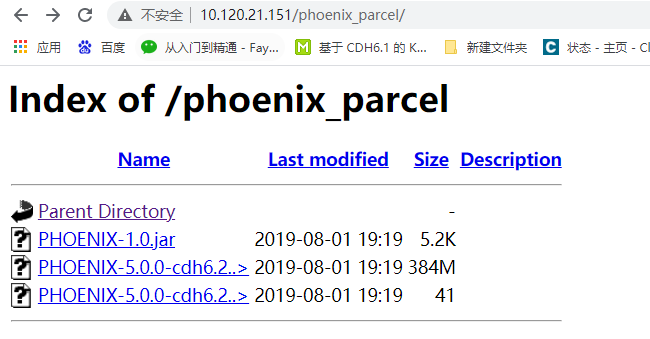
3.从Cloudera Manager点击“Parcel”进入Parcel管理页面
点击“配置”,输入Phoenix的Parcel包http地址。
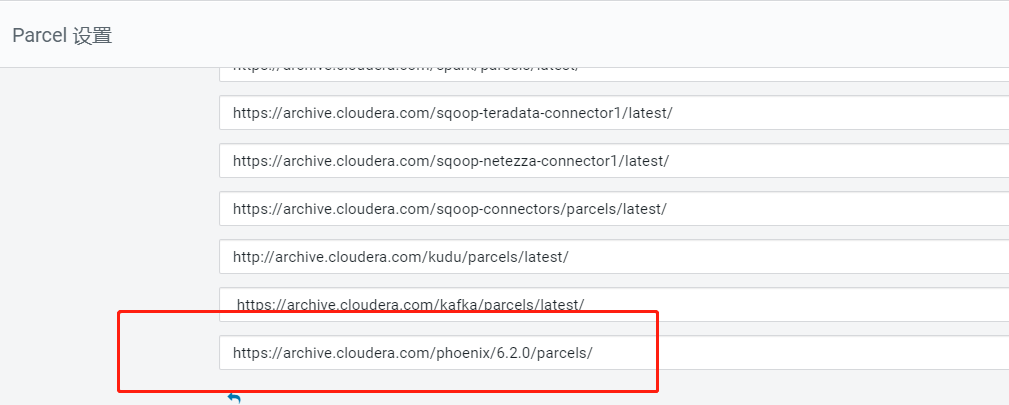
点击“保存更改“回到Parcel管理页面,发现CM已发现Phoenix的Parcel。
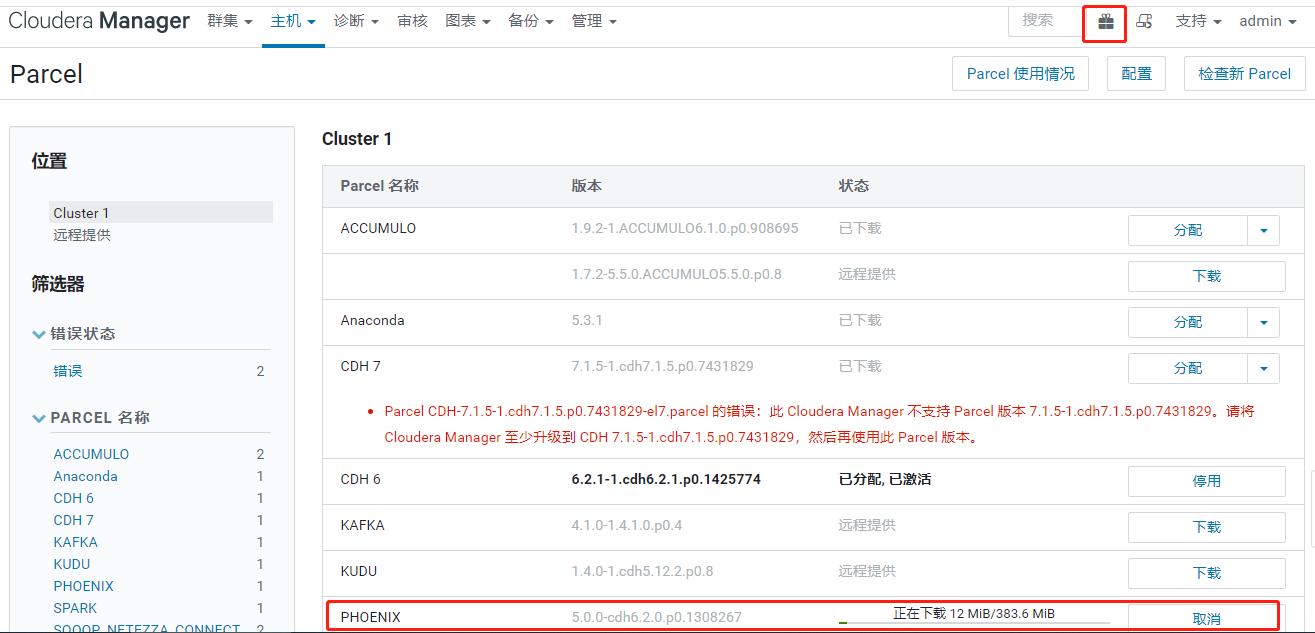
点击“下载”->“分配”->“激活”
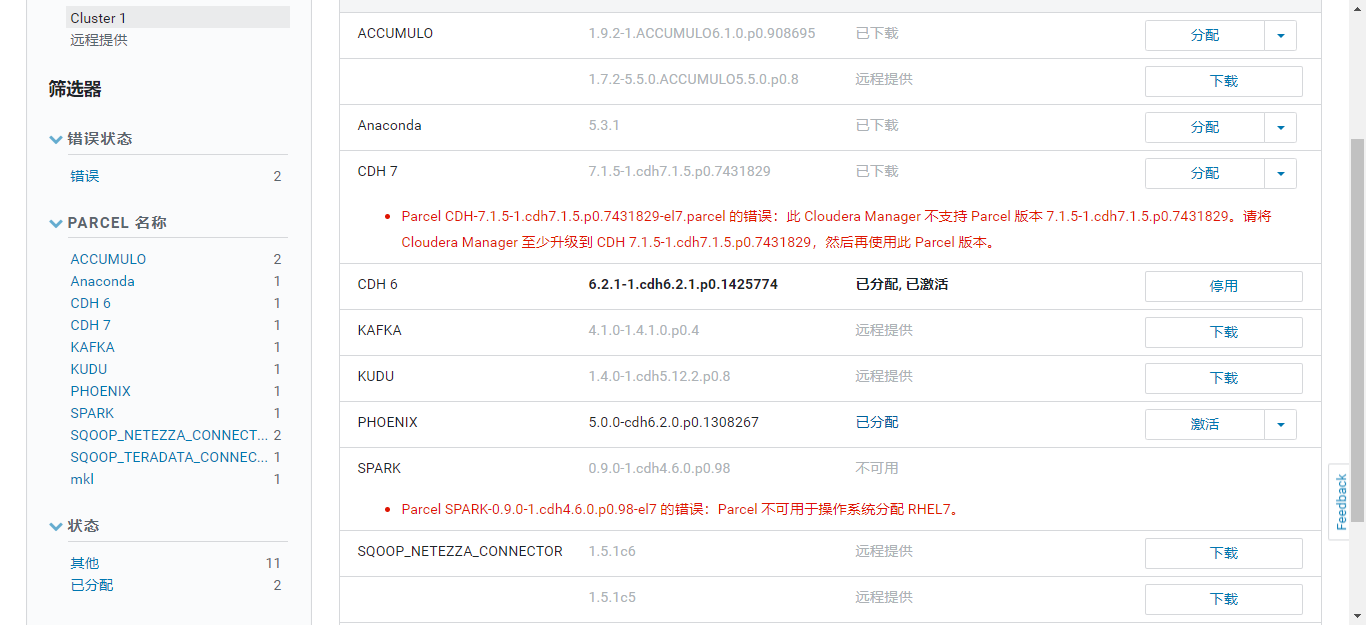
4.回到CM主页,发现HBase服务需要部署客户端配置以及重启
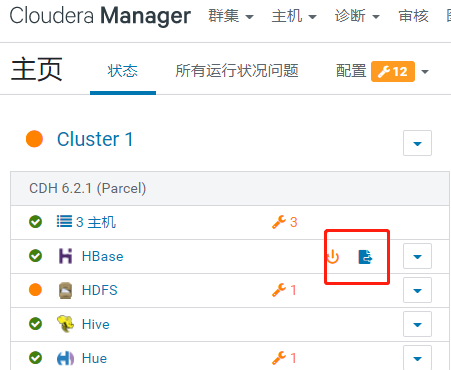
重启HBase服务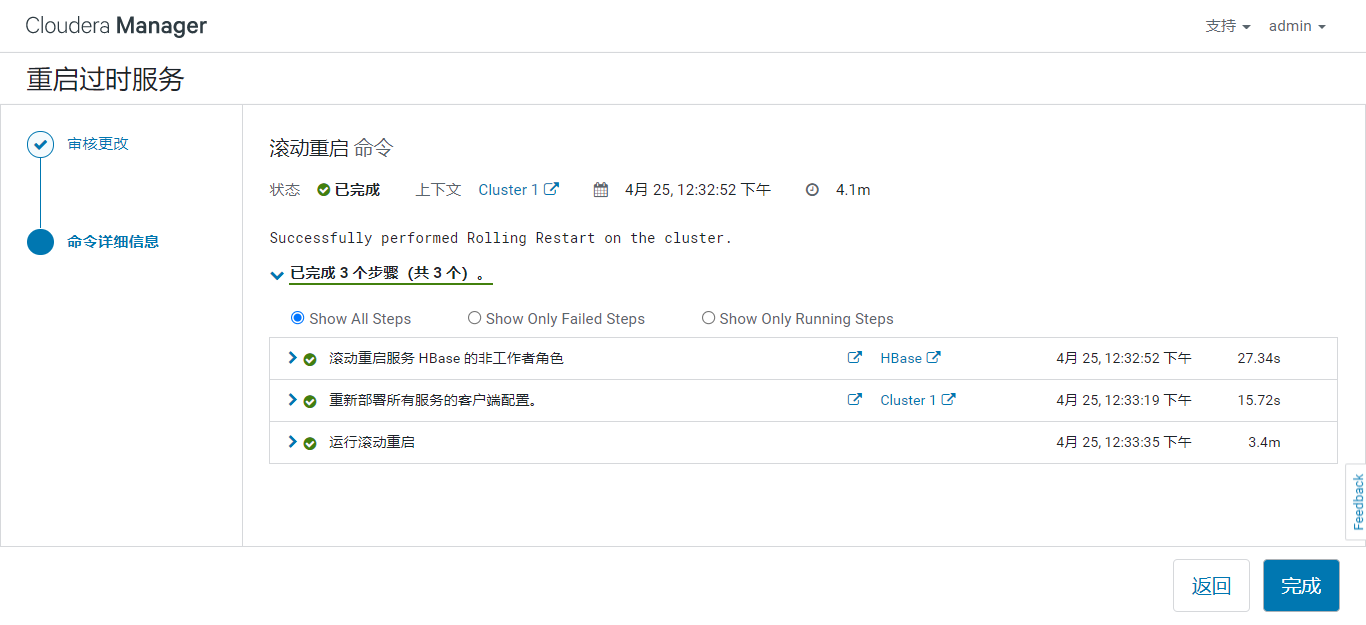
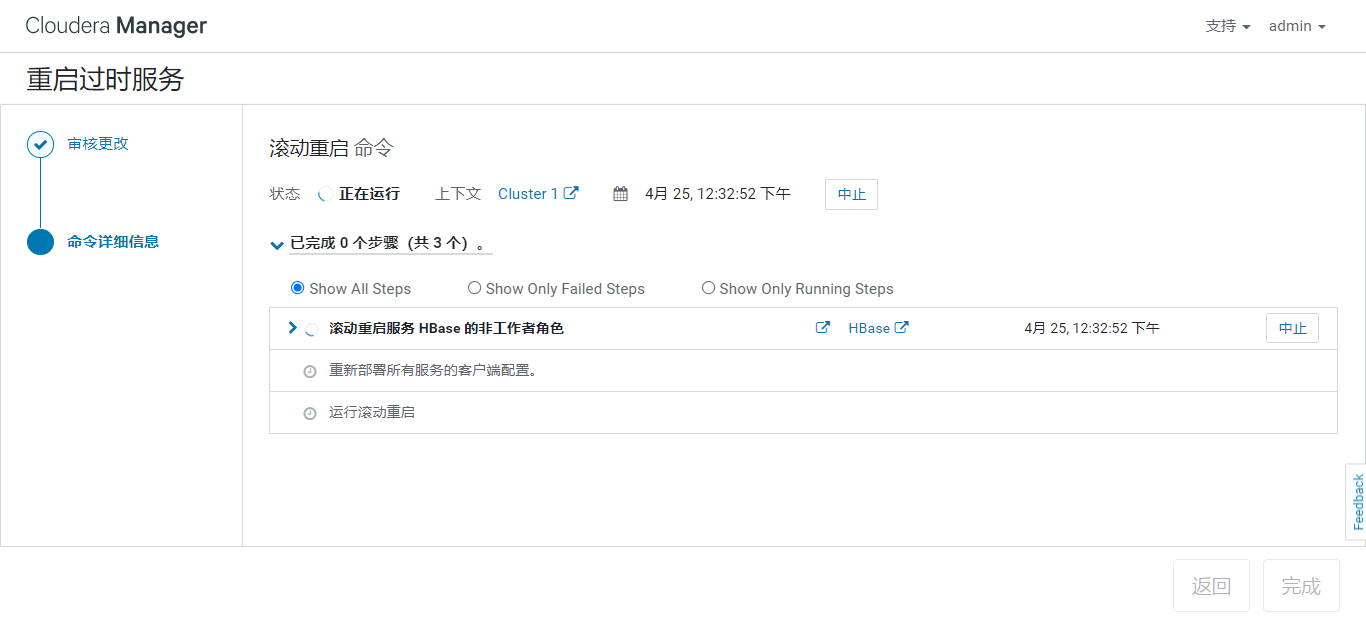
安装完成。
3.如何在CDH集群中使用Phoenix
3.1Phoenix的基本操作
进入Phoenix的脚本命令目录
[root@dloss1 /]# cd opt/cloudera/parcels/PHOENIX-5.0.0-cdh6.2.0.p0.1308267/bin/
[root@dloss1 bin]# ll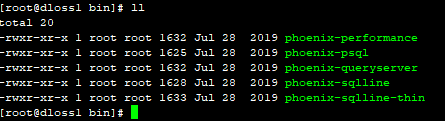
使用Phoenix登录HBase
[root@dloss1 bin]# ./phoenix-sqlline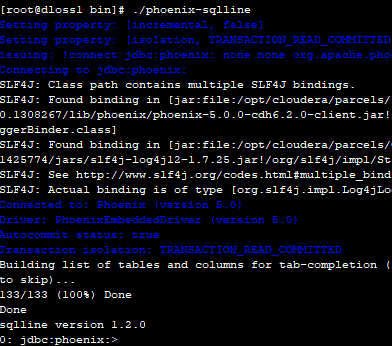
需要指定Zookeeper
[root@dloss1 bin]# ./phoenix-sqlline dloss1:2181:/hbase
0: jdbc:phoenix:dloss1:2181:/hbase> !tables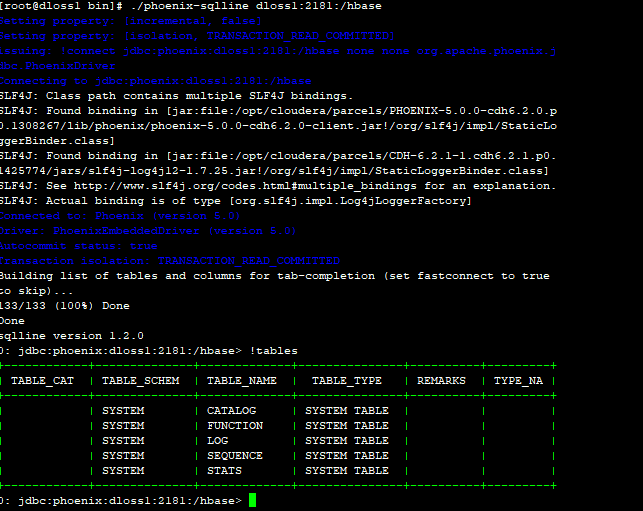
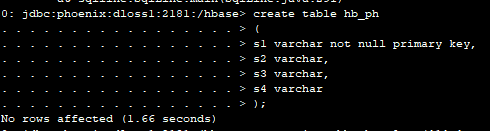
创建一张测试表
注意:建表必须指定主键。
0: jdbc:phoenix:dloss1:2181:/hbase> create table ha_ph
. . . . . . . . . . . . . . . . . > (
. . . . . . . . . . . . . . . . . > s1 varchar not null primary key,
. . . . . . . . . . . . . . . . . > s2 varchar,
. . . . . . . . . . . . . . . . . > s3 varchar,
. . . . . . . . . . . . . . . . . > s4 varchar
. . . . . . . . . . . . . . . . . > );
在hbase shell中进行检查
[root@dloss1 ~]# hbase shell
hbase(main):001:0> list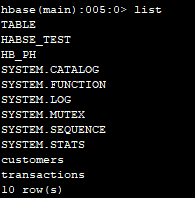
插入一行数据。注意:Phoenix中没有insert语法,用upsert代替。参考:http://phoenix.apache.org/language/index.html
upsert into hbase_test values('1','name1','name2','name3');
select * from hb_ph;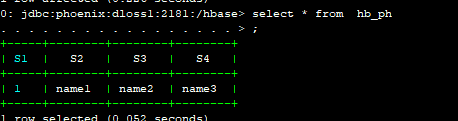
在hbase shell中进行检查
hbase(main):006:0> scan 'HB_PH'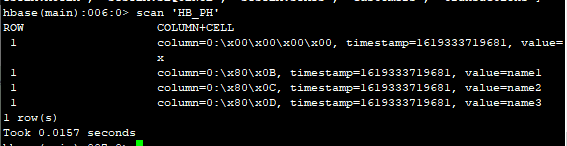
删除这行数据,delete测试
0: jdbc:phoenix:dloss1:2181:/hbase> delete from hb_ph where s1='1';
0: jdbc:phoenix:dloss1:2181:/hbase> select * from hb_ph;
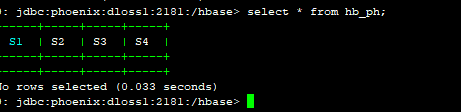
在hbase shell中进行检查
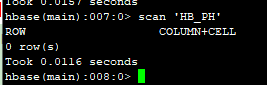
更新数据测试,注意Phoenix中没有update语法,用upsert代替。插入多条数据需要执行多条upsert语句,没办法将所有的数据都写到一个“values”后面。
upsert into hb_ph values('1','testname','testname1','testname2');
upsert into hb_ph values('2','testname','testname1','testname2');
upsert into hb_ph values('3','testname','testname1','testname2');
select * from hb_ph;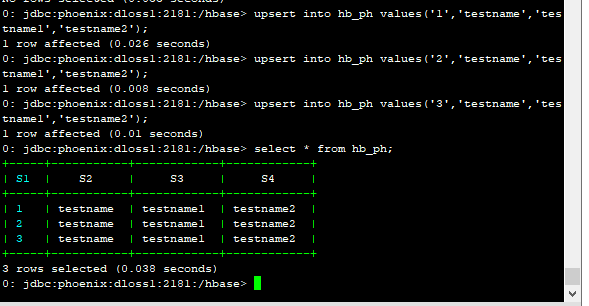
修改数据
0: jdbc:phoenix:dloss1:2181:/hbase> upsert into hb_ph values('1','ting','testname1','testname2');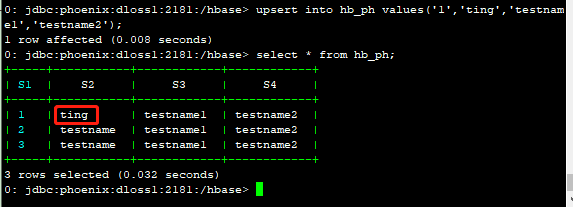 在hbase shell中进行检查
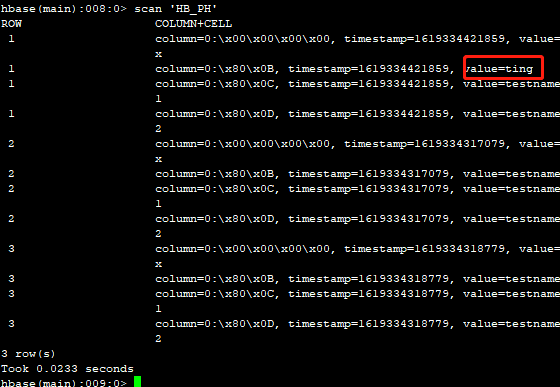
在hbase shell中进行检查
批量更新测试,创建另外一张表hb_ph1,表结构与hb_ph一样,并插入五条,有两条是hb_ph中没有的(主键为4,5),有一条与hb_ph中的数据不一样(主键为1),有两条是完全一样(主键为2,3)。
0: jdbc:phoenix:dloss1:2181:/hbase> create table hb_ph1
. . . . . . . . . . . . . . . . . > (
. . . . . . . . . . . . . . . . . > s1 varchar not null primary key,
. . . . . . . . . . . . . . . . . > s2 varchar,
. . . . . . . . . . . . . . . . . > s3 varchar,
. . . . . . . . . . . . . . . . . > s4 varchar
. . . . . . . . . . . . . . . . . > );
upsert into hb_ph1 values('1','ting','testname1','testname2');
upsert into hb_ph1 values('2','testname','testname1','testname2');
upsert into hb_ph1 values('3','testname','testname1','testname2');
upsert into hb_ph1 values('4','testname','testname1','testname2');
upsert into hb_ph1 values('5','testname','testname1','testname2');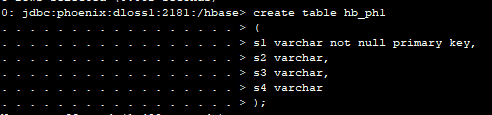
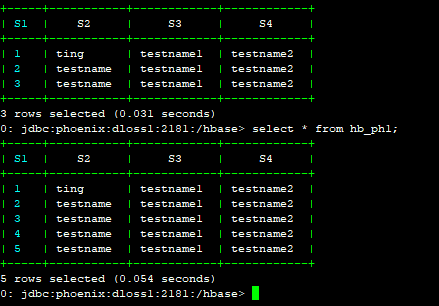
批量更新,我们用hb_ph1中的数据去更新hb_ph。
0: jdbc:phoenix:dloss1:2181:/hbase> upsert into hb_ph select * from hb_ph1;
0: jdbc:phoenix:dloss1:2181:/hbase> select * from hb_ph;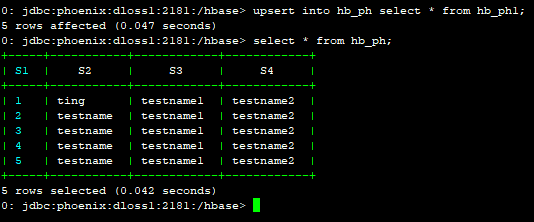
批量更新发现对于已有的数据,如果值不一样,会覆盖,对于相同的数据会保持不变,对于没有的数据会直接作为新的数据插入。
3.2使用Phoenix
创建Orders.csv文件并写入数据
1630781,C004,I001,650,09-01-2013
1630782,C003,I006,2500,09-02-2013
1630783,C002,I002,340,09-03-2013
1630784,C004,I006,1260,09-04-2013
1630785,C005,I003,1500,09-05-2013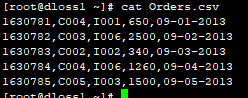
上传该文件到HDFS
hadoop fs -put Orders.csv /user/fayson (使用hdfs用户登录)
Hadoop fs -ls /user/fayson
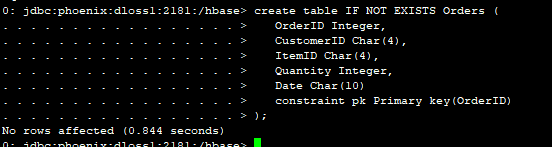
通过Phoenix创建Orders表
create table IF NOT EXISTS Orders (
OrderID Integer,
CustomerID Char(4),
ItemID Char(4),
Quantity Integer,
Date Char(10)
constraint pk Primary key(OrderID)
);
执行bulkload命令导入数据
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-2.1.0-cdh6.2.1.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/PHOENIX-5.0.0-cdh6.2.0.p0.1308267/lib/phoenix/phoenix-5.0.0-cdh6.2.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t Orders -i /user/fayson/Orders.csv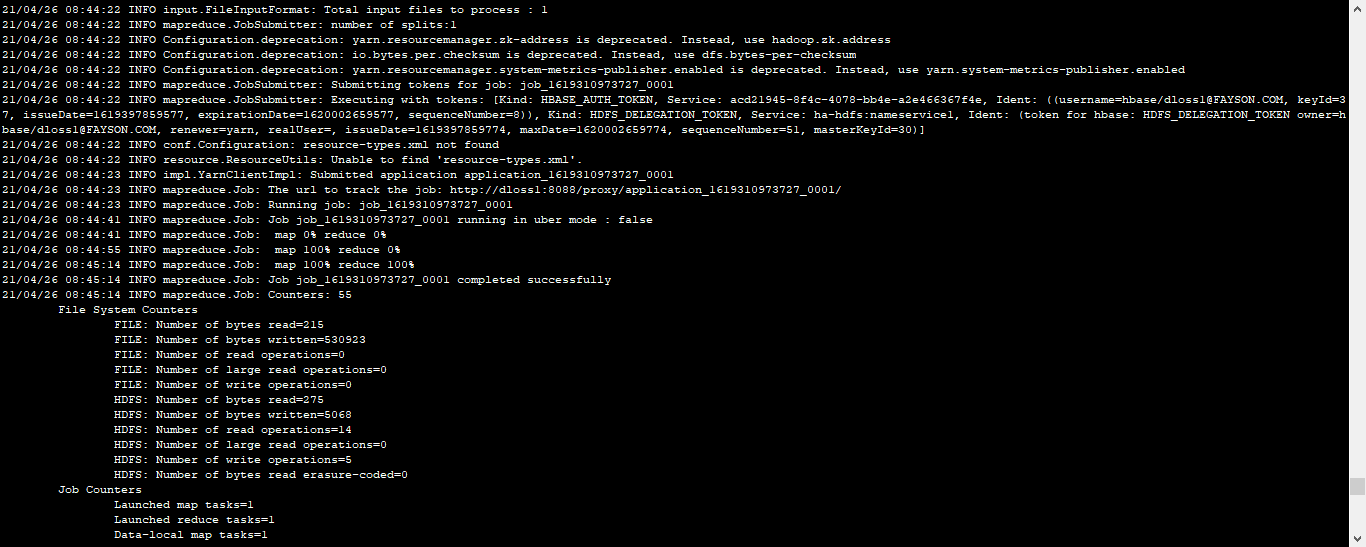
报错Permission denied: user=hbase, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x
注意登录正确的用户并保证需要的文件和目录有足够的权限
在Phoenix查询该表
0: jdbc:phoenix:dloss1:2181:/hbase> select * from Orders;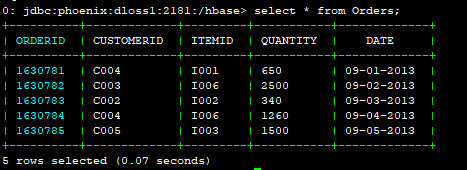
在HBase中查询该表
scan 'ORDERS'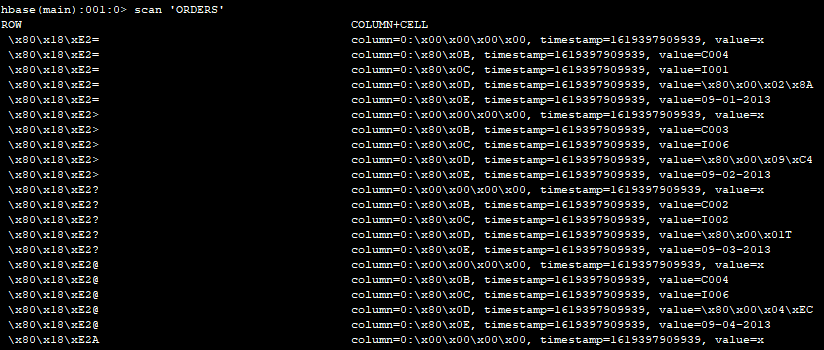
入库条数查询
Phoenix
0: jdbc:phoenix:dloss1:2181:/hbase> select count(*) from Orders;
shell
[root@dloss1 ~]# cat Orders.csv | wc -l















 1948
1948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









