







11月30日,由深度学习技术及应用国家工程研究中心主办、百度飞桨承办的WAVE SUMMIT+ 2022深度学习开发者峰会圆满落幕。
本次峰会上,百度AI技术生态总经理马艳军发布了飞桨开源框架2.4版本,并携手NVIDIA等12家生态伙伴发布了飞桨生态发行版,为开发者提供更好的软硬一体化体验。
作为飞桨的深度合作伙伴,NVIDIA也出席了这场盛大的线上峰会。NVIDIA亚太区资深产品负责人Adam Zheng还带来了以“NVIDIA全新一代产品,极致性能赋能飞桨落地千行百业”为主题的分享,以下为内容概要。
NVIDIA推出Hopper架构
掀起新一代加速计算浪潮
NVIDIA作为计算加速行业的领导者,正在通过全栈创新推动高性能计算的发展。从芯片和系统,到它们运行的算法和应用程序,NVIDIA平台将AI带入了全球最大的行业,提供包括推荐系统、AR、VR、自动驾驶汽车等解决方案,并加速科学研究。

今年春季GTC大会上,NVIDIA发布了Hopper全新一代GPU架构,提供了六项突破性创新(如上图):
创新一
世界上最先进的芯片。由800亿个晶体管构建而成,这些晶体管采用了专为NVIDIA加速计算需求设计的尖端的TSMC 4N工艺,因而能够显著提升AI、HPC、显存带宽、互连和通信的速度,并能够实现近5TB/s的外部互联带宽。此外,该款芯片也是首款支持PCIe 5.0的GPU,也是首款采用HBM3的GPU,可实现3TB/s的显存带宽。20个芯片便可承载相当于全球互联网的流量,使其能够帮助客户推出先进的推荐系统以及实时运行数据推理的大型语言模型。
创新二
新的Transformer引擎——Transformer现在已成为自然语言处理的标准模型方案,也是深度学习模型领域最重要的模型之一。新的Transformer引擎,可以将这些网络的速度提升至上一代的六倍,而不会损失精度。
创新三
第二代安全多实例GPU——MIG技术支持将单个GPU分为七个更小且完全隔离的实例,以处理不同类型的作业。与上一代产品相比,在云环境中Hopper架构通过为每个GPU实例提供安全的多租户配置。
创新四
机密计算——全球首款具有机密计算功能的加速器,可保护AI模型和正在处理的客户数据。客户还可以将机密计算应用于医疗健康和金融服务等隐私敏感型行业的学习,也可以应用于共享云基础设施。
创新五
第4代NVIDIA NVLink——为加速大型AI模型,NVLink结合全新的外接NVLink Switch,可将NVLink扩展为服务器间的互联网络。相比上一代HDR Quantum InfiniBand,实现9倍的速度提升,并可连接多达256个GPU。
创新六
DPX指令——新的DPX指令可加速动态规划,适用于包括路径优化和基因组学在内的一系列算法,与CPU和上一代GPU相比,其速度提升分别可达40倍和7倍。
AI开发只有顶尖的芯片是不够的,还需要软硬全栈和广阔的生态。NVIDIA提供端到端的AI软件套件,覆盖数据准备、训练、推理优化到大规模部署等多个环节,以强大的资源调度和管理能力助力客户加速AI开发与部署。NVIDIA在加速计算领域的沉淀,以及其全新一代产品,为赋能飞桨生态奠定了基础。
NVIDIA携手百度飞桨
加速535万开发者的AI进程
百度飞桨是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。近年来,飞桨的技术实力深受广大硬件厂商认可,合作日趋紧密,软硬一体协同发展,生态共创硕果累累。
NVIDIA非常重视中国市场,特别关注中国的生态伙伴,而当前飞桨拥有535万的开发者。过去的几年中,NVIDIA与飞桨一直保持着深度全面的合作关系。双方一起做了大量的开发与优化工作。
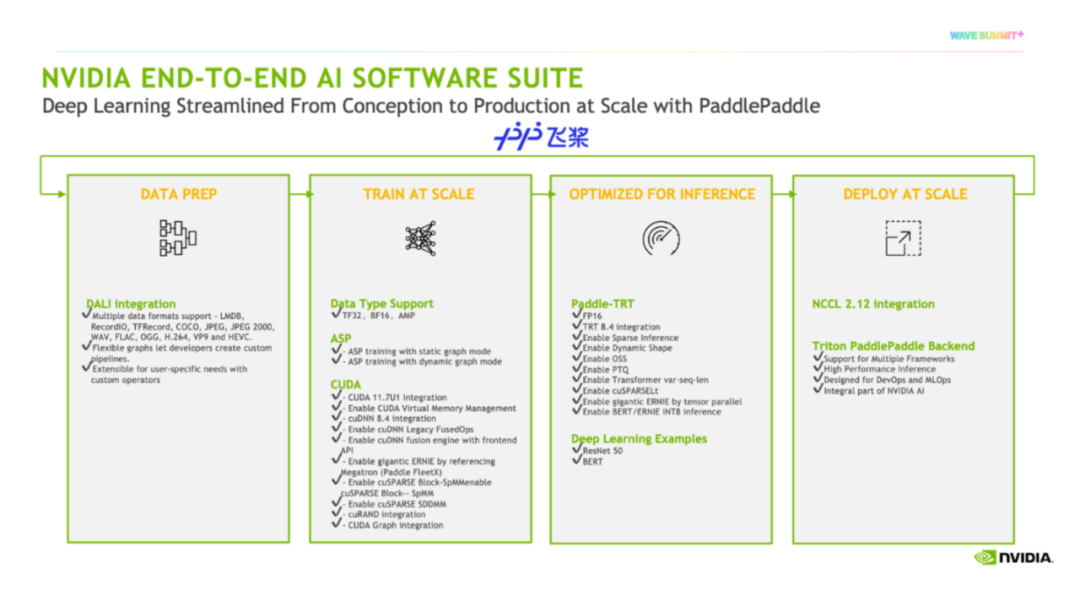
今年,我们将飞桨列为NVIDIA全球前三的深度学习框架合作伙伴,在中国设立了专门的工程团队支持,赋能飞桨。关于NVIDIA与飞桨的合作,由于篇幅原因,我们仅从硬件适配的角度,沿用上图的四个阶段做一个简要的介绍。
在数据处理方面,帮助飞桨集成DALI;
大规模训练,支持各类数据格式、ASP、CUDA等算子函数API;
优化推理方面,开发了Paddle-TRT、Deep Learning Examples;
在规模部署方面,集成了NCCL,开发了Triton PaddlePaddle Backend。
刚才这些适配仅仅是让飞桨的开发者拥有高性能的推理训练成为可能,但是这些离行业开发者还很远,门槛还很高,难度还很大。为此,NVIDIA将刚刚这些集成和优化的工作整合到三大产品线中:
NVIDIA NGC PaddlePaddle Container——NGC飞桨容器,致力为开发者提供了一个最佳的飞桨开发环境,包含最新的NVIDIA工具包版本(CUDA, DALI等)。
NVIDIA Deep Learning Examples——飞桨深度学习模型示例,让开发者能够快速使用一系列拥有极致性能的经典模型 ,例如ResNet 50、BERT等。
NVIDIA DLI (Deep Learning Institute)——飞桨共建课程。为了能更好地提高推训性能并简化代码,NVIDIA深度学习培训中心(DLI)也准备了系列免费课程,以及由NVIDIA与飞桨联名的DLI课程证书,赋能开发者并给于权威认可。
在这三大举措中,NGC飞桨容器最引人注目。
飞桨和NVIDIA团队从与开发者用户的持续交流中,收集到了一些使用上的痛点需求。比如,在提供NGC飞桨容器前,飞桨用户如果希望使用NVIDIA最新软件栈进行开发、训练、部署,需要做大量的手动配置工作,这对不少用户而言是一个巨大的工程挑战。
针对这些需求,NVIDIA与百度飞桨联合开发了NGC飞桨容器,将最新的飞桨与最新的NVIDIA的软件栈进行了无缝的集成与性能优化,最大程度地释放飞桨框架在NVIDIA最新硬件上的计算能力。这样,用户不仅可以快速开启AI应用,专注于创新和应用本身,还能够在AI训练和推理任务上获得飞桨+NVIDIA带来的飞速体验。
NGC飞桨容器具有以下优点:
以月为单位升级更新,每月底发布全新版本,无需注册即可下载,支持多GPU和多节点系统。
适配最新版本的NVIDIA软件栈(例如最新版本CUDA),更多功能,更高性能。
安全可靠。扫描漏洞和加密,适合在工作站、服务器、云上运行并经过测试。满足NVIDIA NGC开发及验证规范,质量管理。
专为企业和高性能计算设计,支持Docker。
适配各种硬件环境:裸机、虚拟机、K8S、X86、ARM、Power、云、本地、边缘等。
应用广泛。适合各种工作内容、工作场景、各行业的应用。
性能优化。我们将其进行优化,并且具有很好的可扩展性。
为了让飞桨开发者用上基于NVIDIA最新的高性能硬件和软件栈,我们借用NVIDIA NGC完善的开发体系、质量管理、测试流程、文档规范、安全扫描等,开发了基于NVIDIA GPU平台最好的飞桨开发环境。
NVIDIA飞桨容器现已开放免费下载,扫描下方二维码加入NGC飞桨容器用户体验群,提交体验报告更可获得精美礼品!

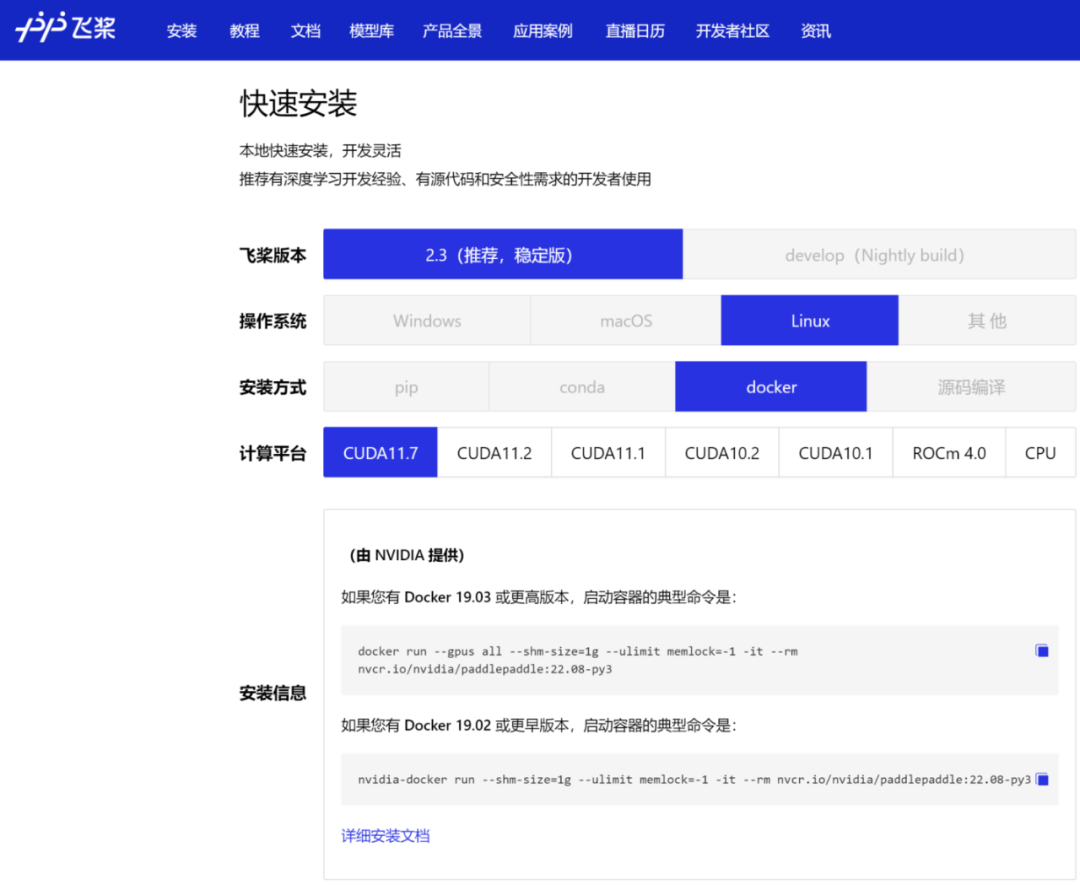
通过飞桨官网快速获取NGC飞桨容器(如下图):
环境准备
使用NGC飞桨容器需要主机系统(Linux)安装以下内容:
Docker引擎
NVIDIA GPU驱动程序
NVIDIA容器工具包
有关支持的版本,请参阅NVIDIA框架容器支持矩阵和NVIDIA容器工具包文档。不需要其他安装、编译或依赖管理。无需安装NVIDIA CUDA Toolkit。
NGC飞桨容器正式安装
要运行容器,请按照NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container一章中的说明发出适当的命令,并指定注册表、存储库和标签。有关使用NGC的更多信息,请参阅NGC容器用户指南。如果您有Docker 19.03或更高版本,启动容器的典型命令是:
1docker run --gpus all --shm-size=1g --ulimit memlock=-1 -it --rm nvcr.io/nvidia/paddlepaddle:22.08-py3详细安装介绍《NGC飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
下面,我们介绍一下NVIDIA Deep Learning Examples,这是NVIDIA优化的工业级模型库,目标是让基于NVIDIA GPU的开发者复现极致精度和高性能的模型。NVIDIA Deep Learning Examples中包括针对不同行业的模型,包括机器人、数字孪生、金融等等。
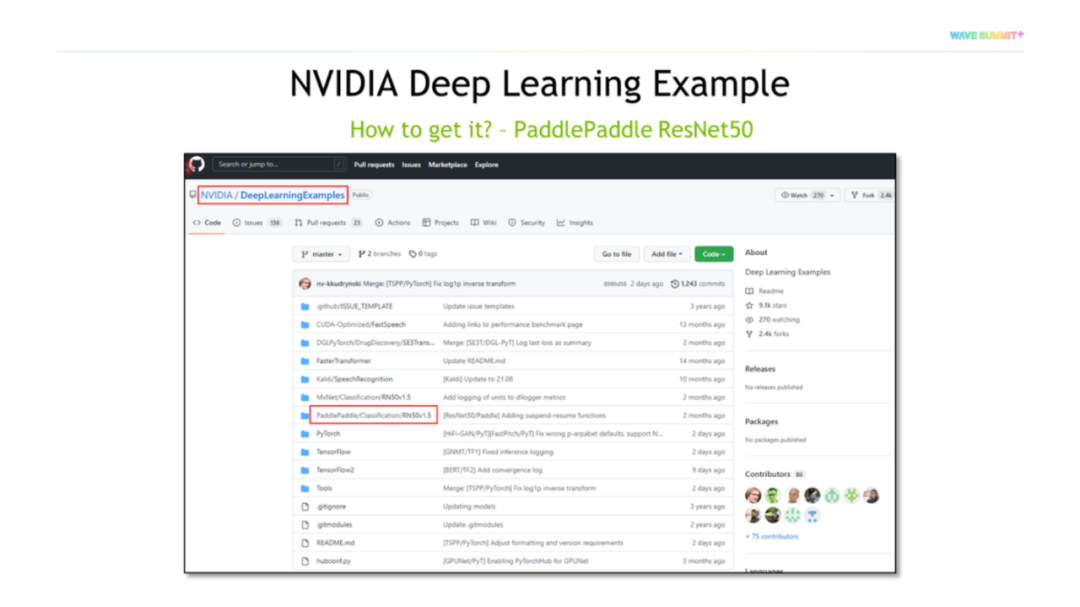
今年我们发布了NVIDIA Deep Learning Examples PaddlePaddle ResNet50,只需要在GitHub中打开NVIDIA Deep Learning Examples Repo,找到主页中的PaddlePaddle Classification ResNet50文件就可以得到它,里面有非常丰富的文档和信息。NVIDIA基于各类网卡、A10、A30,基于各类拓扑结构,单机单卡、单机多卡等,都做了大量测试,并分享了详细的Benchmark供开发者参考(如下图)。
在本届WAVE SUMMIT+ 开始前,NVIDIA更与百度飞桨联合主办了“2022飞桨×NVIDIA AI技术开放日”。作为WAVE SUMMIT+的 “前哨站” ,本次活动邀请双方公司的AI技术专家与超过2000名开发者共同开展深度技术交流,内容囊括NGC飞桨容器特点、应用场景、模型优化,以及部署实践案例。
欲了解更多NGC飞桨容器,可查看以下延展介绍,或关注微信公众号【NVIDIA英伟达企业解决方案】。
详细产品介绍视频
【飞桨开发者说|NGC飞桨容器全新上线NVIDIA产品专家全面解读】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
详细安装介绍《NGC飞桨容器安装指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html

关注【飞桨PaddlePaddle】公众号
点击菜单栏「WAVE回放」查看峰会精彩内容















 1869
1869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









