







在 AI 应用的开发过程中,部署环节尤为关键。将训练好的模型以及多个模型之间的串联逻辑迅速且有效地整合到实际生产环境中,对于 AI 技术向可持续商业价值的转化具有深远意义。近期,PaddleX 团队发布了全新的 PaddleX 3.0-beta1版本,该版本充分考虑到部署环节的重要性,在部署方面进行了大量的功能升级。具体而言,PaddleX 3.0-beta1 在高性能推理、服务化部署以及端侧部署三大核心领域分别提供了适应实际需求的解决方案,致力于满足用户在多样化应用场景下的部署需求。下面,我们对这些解决方案逐一进行说明。
 高性能推理
高性能推理

背景解读
在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。由于深度学习模型在推理及前后处理过程中常常需要进行复杂的计算,模型的端到端推理(包括模型推理与前后处理)速度往往是影响系统性能的关键因素。为此,PaddleX 推出了高性能推理插件,旨在实现对模型推理端到端推理流程的显著提速。

功能介绍
高性能推理插件集成了全场景高性能AI部署工具FastDeploy的核心能力,对模型推理性能进行了深度优化。
高性能推理插件可以根据当前运行环境以及预先测量的性能指标,自动选择最优推理配置,使用户无需关注细节设置,进而省去了传统部署流程中费时费力的配置调优步骤。
高性能推理插件对模型的前后处理流程进行了优化,使用 C++ 实现前后处理算子串联逻辑,并对部分算子做融合优化处理,从而进一步提升性能。
启用高性能推理插件后,模型使用 GPU 推理的耗时可缩短 39%,使用 CPU 推理的耗时平均可缩短 45%。对于部分模型,推理耗时可缩短 80% 以上。部分模型使用高性能推理插件前后推理耗时对比如下:
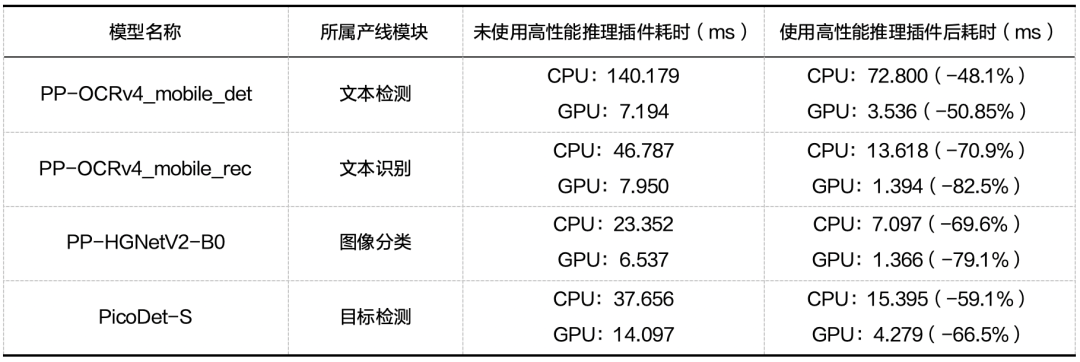
以上测试使用 1 块 Intel Xeon Gold 5117 CPU 与 1 块 NVIDIA Tesla T4 GPU,仅记录模型对于单张输入图像的推理耗时(不含前后处理耗时)。

使用方法
启用高性能推理插件十分方便:用户只需在星河社区免费获取序列号,然后在使用 PaddleX CLI、Python API 时,打开use_hpip开关并指定序列号即可。CLI 和 Python API 的例子分别如下:
paddlex \
--pipeline OCR \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png \
--device gpu:0 \
--use_hpip \
--serial_number {序列号}from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="OCR",
use_hpip=True,
hpi_params={"serial_number": "{序列号}"},
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png")更多细节请参考PaddleX官方仓库高性能推理相关文档:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/docs/pipeline_deploy/high_performance_inference.md

服务化部署
背景解读
在大规模应用中,将模型产线部署为服务是一种常见且高效的策略,这种策略充分发挥了服务作为独立单元的优势,使得各个服务能够独立进行开发和扩展,并通过网络请求与其它服务或系统组件实现交互。服务化部署使得系统内各模块之间实现了有效的解耦,从而显著提升了系统的灵活性、扩展性和维护性。针对该需求,PaddleX 基于 FastAPI 框架实现了简单易用的产线服务化部署方案。

功能介绍
该方案为服务接受的请求与返回的响应内容进行详细的数据校验,增强服务的可靠性;
该方案利用 Python 基于协程的异步特性以更高效地处理 I/O 密集型任务,这提升了服务处理并发请求时的性能。目前,PaddleX 已集成的所有官方产线均支持服务化部署。

使用方法
与高性能推理一样,PaddleX 对服务化部署能力进行了插件化,将其作为可选功能,以降低 PaddleX 核心部分的安装成本。使用 PaddleX CLI 安装服务化部署插件:
paddlex --install serving安装完成后,通过 PaddleX CLI,用户可以一键将产线部署成服务,例如:
paddlex --serve --pipeline OCR服务启动成功后,可以看到类似以下展示的信息:
INFO: Started server process [63108]INFO: Waiting for application startup.INFO: Application startup complete.INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)服务启动后,用户可参考 PaddleX 产线使用教程中的 API 参考与多语言调用示例(覆盖 Python、C++、Java、Go、C#、JavaScript、PHP 等 7 种语言)对服务进行调用。Python 和 C# 的调用示例分别如下:
import base64
import requests
API_URL = "http://localhost:8080/ocr" # 服务URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# 对本地图像进行Base64编码
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64编码的文件内容或者图像URL
# 调用API
response = requests.post(API_URL, json=payload)
# 处理接口返回数据
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected texts:")
print(result["texts"])using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/ocr";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// 对本地图像进行Base64编码
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } }; // Base64编码的文件内容或者图像URL
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// 调用API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// 处理接口返回数据
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
Console.WriteLine("\nDetected texts:");
Console.WriteLine(jsonResponse["result"]["texts"].ToString());
}
}更多细节请参考PaddleX官方仓库服务化部署相关文档:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/docs/pipeline_deploy/service_deploy.md

端侧部署

背景解读
端侧部署是指将深度学习模型直接部署在用户的终端设备或边缘服务器上。这种部署方式对于需要快速响应、减少数据传输延迟、保护用户隐私以及在网络连接不稳定的环境中保持应用运行的应用场景尤为重要。随着移动设备性能的提升和深度学习模型的优化,端侧部署已成为实现人工智能应用落地的关键技术之一。

功能介绍
PaddleX 提供基于Paddle Lite框架实现的一系列 Android demo,帮助用户在端侧 ARM CPU 和 Mali/Adreno GPU(OpenCL)上部署模型产线。Paddle Lite 框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel 优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。目前端侧部署示例覆盖 4 条产线、8 个模型,各 demo 均配套有完善的使用文档。目前已支持端侧部署的产线和模型如下:
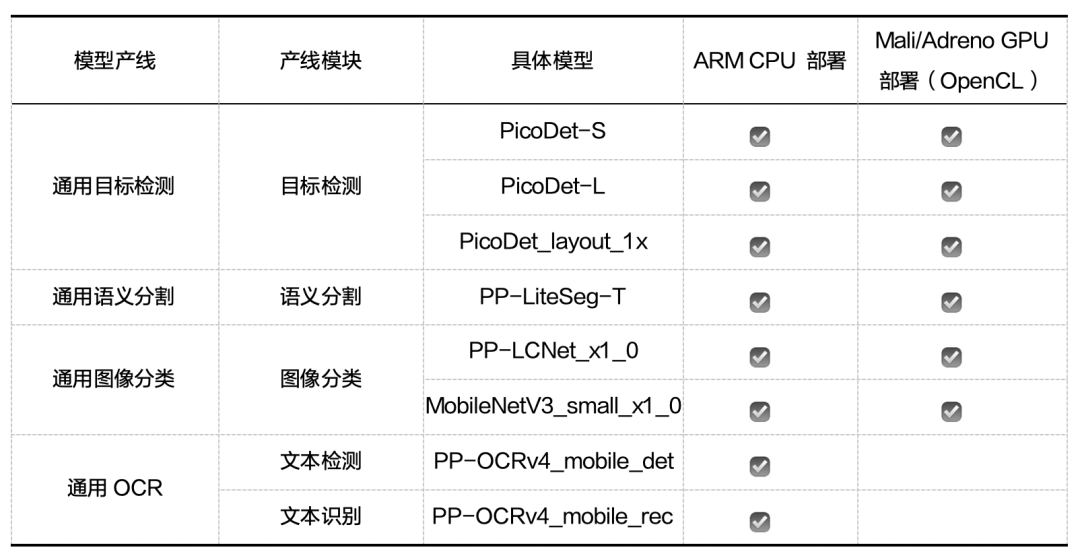

使用方法
用户在 Windows、Mac 或 Linux 系统的设备上连接 Android 手机后,仅需三步即可完成端侧部署。以通用OCR产线为例:
1. 克隆 Paddle-Lite-Demo 仓库的 feature/paddle-x 分支到 PaddleX-Lite-Deploy 目录。
git clone -b feature/paddle-x https://github.com/PaddlePaddle/Paddle-Lite-Demo.git PaddleX-Lite-Deploy2. 下载压缩包,将压缩包放到指定解压目录,切换到指定解压目录后执行解压命令。
# 1. 切换到指定解压目录
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
# 2. 执行解压命令
unzip ocr.zip3. 执行部署步骤
# 1. 下载需要的 Paddle Lite 预测库
cd PaddleX-Lite-Deploy/libs
sh download.sh
# 2. 下载 paddle_lite_opt 工具优化后的模型文件
cd ../ocr/assets
sh download.sh PP-OCRv4_mobile
# 3. 完成可执行文件的编译
cd ../android/shell/ppocr_demo
sh build.sh
# 4. 预测
sh run.sh PP-OCRv4_mobile执行完上述三个步骤后,可以得到文本检测结果和文本识别结果。
文本检测结果:

文本识别结果:
The detection visualized image saved in ./test_img_result.jpg
0 纯臻营养护发素 0.993706
1 产品信息/参数 0.991224
2 (45元/每公斤,100公斤起订) 0.938893
3 每瓶22元,1000瓶起订) 0.988353
4 【品牌】:代加工方式/OEMODM 0.97557
5 【品名】:纯臻营养护发素 0.986914
6 ODMOEM 0.929891
7 【产品编号】:YM-X-3011 0.964156
8 【净含量】:220ml 0.976404
9 【适用人群】:适合所有肤质 0.987942
10 【主要成分】:鲸蜡硬脂醇、燕麦β-葡聚 0.968315
11 糖、椰油酰胺丙基甜菜碱、泛醒 0.941537
12 (成品包材) 0.974796
13 【主要功能】:可紧致头发磷层,从而达到 0.988799
14 即时持久改善头发光泽的效果,给干燥的头 0.989547
15 发足够的滋养 0.998413若想进一步了解端侧部署,如代码介绍,代码讲解,以及如何更新模型、预测库等,请参考 PaddleX 端侧部署文档:
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/docs/pipeline_deploy/edge_deploy.md

精彩课程预告
为了帮助您迅速且深入地了解飞桨低代码开发工具PaddleX 3.0-beta1最新版本的部署能力,并熟练掌握模型产线部署技巧,百度研发工程师将于11月7日(周四)19:00,为您深度解析PaddleX 3.0-beta1在部署方面的功能、优势与技巧。此外,我们还将陆续开设针对高性能推理、服务化部署、端侧部署的产业场景实战营,手把手带您体验从数据准备、数据校验、模型训练、性能优化到模型部署的完整开发流程。机会难得,立即扫描下方二维码预约吧!





关注【飞桨PaddlePaddle】公众号
获取更多技术内容~


















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









