 Netty解码器详解
Netty解码器详解




文章目录
Netty 解码器介绍
Netty中最重要的就是处理器,类似链表的结构,有一个执行器链,分为入栈执行器链和出栈执行器链,
入栈的执行器都直接或间接的实现了ChannelInboundHandler,就比如解码器,出栈的处理器都实现了ChannelOutboundHandler
执行器在链中的顺序在ChannelInitializer中定义
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LDqGlimO-1620799496876)(C:\Users\62601\AppData\Roaming\Typora\typora-user-images\image-20210512095450358.png)]
一般来说这里先写入栈的,再写出栈的,请求来的时候执行器从上到下,入栈入栈Handler1先处理,在交给入栈Handler2处理,发现下面哪个是出栈处理器就直接跳过,直接到自定义的处理器
出栈同理,不会被入栈处理器处理,
场景一般就是编码器,编码和解码的编码器都配置了,但是不会同时解码又编码
Netty提供的解码器介绍
DelimiterBasedFrameDecoder 分隔符解码器
使用方法:
/**
* 参数说明
* 1024: 最大帧长,一个消息的最大字节长度
* true: 丢弃调消息分割符 比如完整的消息是ABC$_ 这里解码完成后就返回ABC
* 为false就返回ABC$_,通常情况下我们是不需要分隔符的
* true: 表示读取消息的时候,是一发现消息长度超出了就报错,还是读着读着发现超出了再报错
* byteBuf: 分隔符
*/
pipeline.addLast(new DelimiterBasedFrameDecoder(1024,true,true,byteBuf));
这里解码之后会返回一个byteBuf,可以直接再自定义处理器里面把byteBuf里面的东西读取出来,也可以再自定义一个解码器,把他转成自己的业务对象
解码器这么定义,客户端只需要再发送消息的时候再最后面输出两个字节的$_
LineBasedFrameDecoder 换行符解码器
使用方法:
/**
* 参数说明
* 1024: 最大帧长,一个消息的最大字节长度
* true: 丢弃调消息换行符 比如完整的消息是ABC\r\n 这里解码完成后就返回ABC
* 为false就返回ABC\r\n ,通常情况下我们是不需要换行符的
* true: 表示读取消息的时候,是一发现消息长度超出了就报错,还是读着读着发现超出了再报错
*/
pipeline.addLast(new LineBasedFrameDecoder(1024,true,false));
这个类似于分隔符,只不过分隔的符号是换号符,再分隔符解码器的decode其实也有判断,如果定义的DelimiterBasedFrameDecoder 用的符号是"\r\n"或者""真实调用的其实也是LineBasedFrameDecoder
FixedLengthFrameDecoder 定长解码器
这个是最简单的,基本不会用到,读取固定长度的消息,底层是直接调用bytebuf的readRetainedSlice(frameLength);
pipeline.addLast(new FixedLengthFrameDecoder(1024);
自定义解码器
自定义可以选择集成两个类,ByteToMessageDecoder或者MessageToMessageDecoder,基本没有什么区别,代码贴上
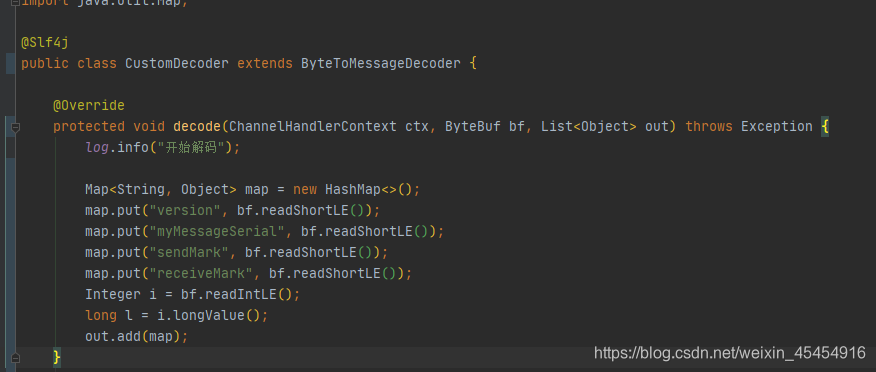
ByteToMessageDecoder
MessageToMessageDecoder
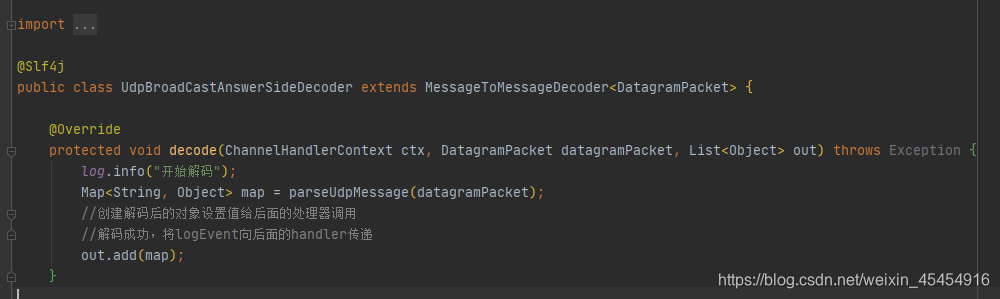
这两个区别在于udp接收的数据用MessageToMessageDecoder,继承之后需要写一个泛型,在DatagramPacket里面可以获取到发送者的地址,可以用来响应
tcp获取的数据因为是保持的长连接,在连接成功的时候就知道是哪个客户端了,所以这里不需要获取
相同点: 解码完成之后都需要把处理完的数据放到list里面,交给下一个处理器去处理
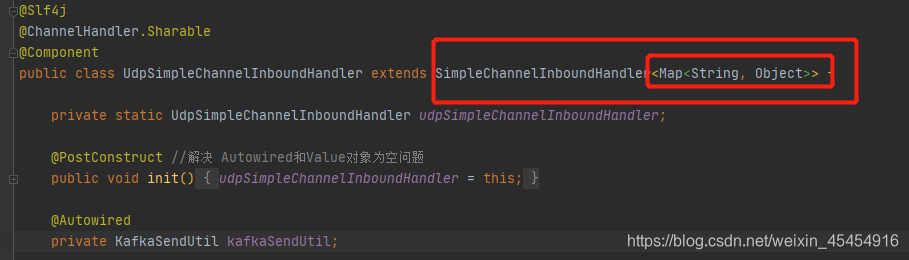
注意点:自定义处理器的泛型,和这里list.add()进去的数据类型必须保持一致

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









