







程序:
程序是指编译好的二进制文件,存放在磁盘上不占用系统资源(cpu、内存),当程序在计算机上运行时,它就变成了一个进程,包括程序、数据和状态信息,程序是静态的,而进程是动态的。
进程:
-
进程是程序的实例,是资源分配的最小单位,当一个程序开始运行时,操作系统会为该程序分配一些计算机资源,例如内存、CPU 时间和输入/输出设备,并创建一个进程来管理这些资源。
-
一每个进程都有自己的进程 ID(PID)和内存空间,可以独立运行、暂停、终止等。
-
每个进程可以包含多个线程,每个线程可以执行不同的任务,但它们共享进程的资源。
-
总结:程序是进程的静态描述,进程是正在运行程序的实例。
举例:
- 使用一个计算器程序进行计算,计算器是是一个静态的可执行文件,包含一系列指令和数据。当你打开计算器程序并输入数字时,这个程序开始在计算机上运行,此时它就变成了一个进程。进程包括了程序、数据和状态信息,如当前的输入和计算结果等等。
进程的状态:
- 新建(New):进程刚被创建,但还没有被操作系统调度执行,在这个状态下,操作系统会为该进程分配必要的资源(如内存、I/O 设备等)
- 就绪(Ready):进程已经被创建并分配了所有必需的资源,正在等待分配CPU时间片。
- 运行(Running):CPU分配给进程,进程正在执行其指令,占用着 CPU 的时间片。
- 阻塞(Blocked):进程正在等待某个事件发生,比如等待IO(输入/输出操作)操作完成。
- 终止(Terminated):进程已经完成了它的任务,或者因为某些原因被操作系统终止。
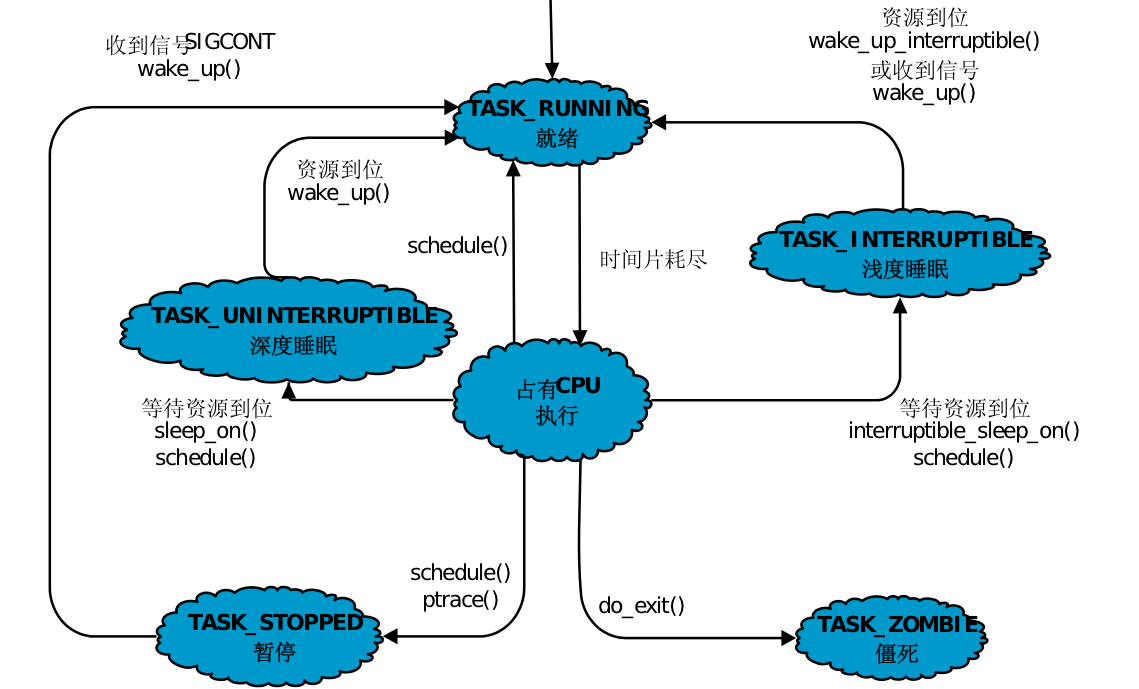
进程类型:
- 系统进程:在系统启动时就已经存在的进程,是系统运行的基础。
- 用户进程:由用户创建并运行的进程,通常是执行一些特定任务的应用程序。
- 守护进程:在后台运行并提供某种服务的进程,通常在系统启动时自动启动并运行,例如网络服务、系统监控服务等
- 临时进程:只在某些特定场景下出现的临时进程,例如用于复制文件或创建临时文件等
- 进程组:将多个相关联的进程组合在一起,方便管理和协同工作。
- 僵尸进程:当一个进程完成执行后,它会向父进程发送一个信号,告诉父进程它已经完成了。如果父进程没有及时处理这个信号,就会导致子进程成为一个僵尸进程,即该进程已经完成了它的任务,但是它的进程控制块(PCB)还存在,占用系统资源,但已经不能再进行任何操作。可以通过杀死僵尸进行使僵尸进程变成孤儿进程解决。
- 孤儿进程:当父进程退出后,它的子进程就变成了孤儿进程。孤儿进程将被系统进程init接管,它会成为init的子进程,并且由init负责清理它的资源。因此,孤儿进程不会成为系统资源的浪费,但是它可能会影响系统的稳定性,因为它没有父进程来管理它的行为。
僵尸进程和孤儿进程都是进程的一种状态,它们分别指的是子进程和父进程之间的关系。
多进程:
多进程指的是在同一个计算机系统中同时运行多个进程,每个进程都拥有自己的独立的内存空间、寄存器集合和其他系统资源,它们之间相互独立、互不干扰。多进程能够使得计算机系统能够同时处理多个任务,提高计算机系统的并发性和吞吐量。
优点:
- 多进程能够提高计算机系统的并发性和吞吐量,使得系统能够同时处理多个任务。
- 多进程之间相互独立,可以防止一个进程出现问题影响到其他进程的运行。
- 多进程能够更好地利用多核 CPU,提高系统的运行效率。
缺点:
- 多进程的创建和销毁需要占用系统资源,因此如果同时运行的进程过多,会对系统资源造成一定的压力。
- 多进程之间的通信和同步比较复杂,需要考虑进程间的同步、通信和资源管理等问题。
多进程与CPU:
如果进程数小于CPU数量,所有的线程都可以同时运行。
如果进程数大于CPU时并不是同时在执行,而是通过争夺CPU使用权,交替执行,不过时间较短在感觉上像是同时在执行。
- CPU会使用时间片轮转调度算法将不同的进程交替地放到处理器上执行,处理器会为每个进程分配一个时间片,当时间片用完时,处理器就会停止执行该进程,将处理器的控制权交给下一个进程,这样就实现了多进程的同时运行。在进程调度过程中,如果一个进程在运行时需要等待某些事件的发生,比如等待输入输出完成、等待锁等,那么它就会被挂起,直到事件发生后再继续执行。被挂起的进程会进入阻塞状态,等待事件发生的同时,不会消耗CPU时间片。一旦事件发生,操作系统会将该进程从阻塞状态转换为就绪状态,重新参与进程调度。
- 例:有三个进程 A、B、C,它们需要在单核处理器上运行。处理器会将三个进程分配到不同的时间片中。假设每个时间片的长度为 10ms,则处理器可能将进程 A 分配到前 10ms 的时间片中,将进程 B 分配到接下来的 10ms 时间片中,将进程 C 分配到再接下来的 10ms 时间片中。当处理器执行完最后一个时间片时,就会重新开始随机分配。
线程:
线程是程序执行流的最小单元,是进程中的一个实体。一个进程可以创建多个线程,每个线程都可以独立地执行不同的任务。与进程相比,线程的开销更小,切换速度更快,线程共享进程的内存空间,包括代码段、数据段和栈。这意味着多个线程可以访问相同的变量和数据结构,从而更容易实现并发编程。当一个线程修改共享内存时,其他线程也能够立即看到这些变化,因此在一些需要同时执行多个任务的场景中,多线程的应用非常广泛。
进程和线程的区别:
在于是否共享地址空间:进程(独居),线程(合租)
-
进程:最小分配资源单位,可看成是只有一个线程的进程
-
线程:最小的执行单位
线程同步:
在多线程编程中,多个线程可能同时访问共享资源,例如内存中的变量、文件等等。如果不进行同步,可能会出现多个线程同时修改同一资源的情况,导致数据不一致或者程序崩溃等问题。
线程同步是多线程编程中避免多个线程同时访问共享资源而导致数据不一致或者崩溃的一种机制,可以通过加锁、条件变量等方式实现。其目的是保证线程之间一致地访问共享资源,避免冲突和数据不一致的问题。
互斥锁:
互斥锁(Mutex)是一种常用的同步机制,用于防止多线程同时访问共享资源,保证同一时间只有一个线程访问共享资源。但互斥锁也称为建议锁,在操作系统中,加锁操作通常是由编程语言或库提供的,而不是由操作系统强制要求的,如果线程不按规矩办事,依然会造成数据混乱。
互斥锁的实现通常包括两种状态:加锁、解锁。当线程加锁时,其他线程进入阻塞状态,直到锁被释放,其它线程才能访问共享资源。为了保证互斥锁的正确使用,应该在对共享资源的访问结束后及时释放锁,避免长时间占用导致死锁。
互斥锁由标准库sync中的Mutex结构体类型表示,sync.Mutex类型只有两个公开的指针方法,Lock(加锁)和Unlock(解锁)。对资源操作完成后,一定要解锁,否则会出现流程执行异常,死锁等问题,通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁。
// 创建互斥锁,初始值 = 0(未加锁)
var mutex sync.Mutex
func printer(str string) {
// 当有goroutine进来时就加锁
mutex.Lock()
for _, ch := range str {
fmt.Printf("%c", ch)
// 加sleep是为了能清楚的看到整个打印效果
time.Sleep(time.Millisecond * 300)
}
mutex.Unlock() // 用完解锁
}
func person1() {
printer("hello")
}
func person2() {
printer("world")
}
func main() {
go person1()
go person2()
for {
}
}
读写锁:
互斥锁的本质是当一个goroutine访问的时候,其他goroutine都不能访问,这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行执行变成了串行执行。但是,当共享资源被频繁读取而很少被写入时,互斥锁的效率就不高了。因为在读取共享资源时,只需要保证其他goroutine不修改该资源,而不需要阻止其他goroutine进行读取操作。在这种情况下,如果使用互斥锁,那么只要有一个goroutine在读取资源,其他所有goroutine都会被阻塞。而读写锁可以解决这个问题。读写锁可以让多个读操作同时执行,但是对于写操作是完全互斥的。
读锁:共享锁,允许多个线程同时读操作
- 读优先型读写锁:允许多个读操作同时进行,写操作需等待所有读锁释放才能操作。A线程持有读锁,B线程获取写锁时会被阻塞,直到A线程释放读锁,B线程才能获取到写锁。同时,在A线程持有读锁的情况下,其他的读操作(例如C线程)可以继续获取读锁,因为读锁是共享的。如果读操作一直占用读锁,而写操作一直无法获取写锁,则写操作就会出现饥饿现象。
写锁:独占锁,必须等线程释放锁其它线程才能操作,当写锁和读锁同时争夺CPU执行权时,写锁优先级大于读锁。
- 写优先型读写锁:A线程持有写锁,B线程获取读锁时会被阻塞,直到A线程释放写锁。而如果C线程需要获取写锁,则B线程和其他正在等待读锁的线程都会被阻塞,直到C线程完成写操作并释放写锁。如果写操作一直占用写锁,而读操作一直无法获取读锁,则读操作就会出现饥饿现象。
饥饿现象(Starvation)是指某个进程或线程无法获得所需的资源,而导致一直无法执行或者执行受限的情况。在并发编程中,饥饿问题通常是由于某些资源被独占或者被占用时间过长而导致的。为了解决饥饿问题,可以采用一些优化策略,例如实现公平锁获取机制、设置超时时间、避免长时间持有锁等。此外,还可以根据具体的场景和需求来选择合适的锁类型和使用方式,以达到最佳的性能和资源利用效率。
GO中的读写锁由结构体类型sync.RWMutex表示
写锁定和写解锁:
func (*RWMutex)Lock()
func (*RWMutex)Unlock()
读锁定和读解锁:
func (*RWMutex)RLock()
func (*RWMutex)RUlock()
演示:
var rwMutex sync.RWMutex // 锁只有1把,但有两个属性
var value int // 模拟共享数据,代替channel
func main() {
// 播种随机数种子
rand.Seed(time.Now().UnixNano())
for i := 0; i < 5; i++ {
go TestRead(i + 1)
}
for i := 0; i < 5; i++ {
go TestWrite(i + 1)
}
for {
}
}
func TestRead(idx int) {
for {
rwMutex.RLock() // 读锁
num := value //从全局变量中读数据
fmt.Println("第", idx, "个go程读到了", num)
rwMutex.RUnlock() // 解锁
}
}
func TestWrite(idx int) {
for {
// 生成随机数
num := rand.Intn(1000)
rwMutex.Lock() // 写锁
value = num //写数据到全局变量中
fmt.Println("----第", idx, "个go程写入了", num)
time.Sleep(time.Second) // 为了放大实验现象
rwMutex.Unlock() // 解锁
}
}
输出:可以看到写锁是独占的,读锁是共享的
第 4 个go程读到了 0
----第 2 个go程写入了 645
第 1 个go程读到了 645
第 1 个go程读到了 645
第 1 个go程读到了 645
第 5 个go程读到了 645
第 3 个go程读到了 645
----第 2 个go程写入了 491
第 1 个go程读到了 491
第 1 个go程读到了 491
第 1 个go程读到了 491
第 1 个go程读到了 491
第 1 个go程读到了 491
----第 1 个go程写入了 79
第 4 个go程读到了 79
第 4 个go程读到了 79
第 4 个go程读到了 79
第 5 个go程读到了 79
第 1 个go程读到了 79
协程(Goroutine):
-
协程也叫轻量级线程,与线程相比,协程最大的优势在于
轻量级。可以在程序中创建成百上千个协程,并发地执行多个任务。 -
一个线程中可以有任意多个协程,但某一时刻只能有一个协程在运行,多个协程分享该线程分配到的计算机资源。
-
协程之间可以通过通道(Channel)进行通信,从而实现协程之间的数据交换和同步操作。
协程对比进程的优点:
- 更轻量级:协程的创建和切换开销很小,可以同时创建成千上万个协程。执行Goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩。
- 灵活性高:协程可以手动控制调度,可以在协程之间自由切换,适合处理IO密集型任务,如网络通信、文件读写等。
- 更易于实现并发:协程之间可以通过通道进行通信和同步操作,更加方便实现并发编程。
- 更加灵活:协程可以根据需要调整自身的数量和大小,以适应不同的并发场景。
- 无需锁:协程的调度不需要加锁,因为同一时间只有一个协程在执行,不会出现线程安全问题。
创建Goroutine只需在函数调⽤语句前添加go关键字即可,开发⼈员无需了解任何执⾏细节,调度器会自动将其安排到合适的系统线程上执行。
func main() {
go Test()
fmt.Println("main fun Runtime")
}
func Test() {
fmt.Println("Test01 fun Runtime")
}
输出:和预期先打印Test fun Runtime,再打印main fun Runtime不符。
main fun Runtime
原因是 main() 是一个主协程(main Goroutine),Test函数被作为一个新的Goroutine启动(子协程),而main函数继续执行它的后续代码,main函数的Println语句会立即被执行,而Test函数的Println语句可能在main函数的Println语句之前或之后执行。因为Test函数的Println语句还没来得及执行,而main函数已经执行结束了,整个程序会立即退出,所以Test函数中的输出没有机会被打印出来。
总结:主Goroutine退出后,其它Goroutine也会自动退出
可以使用sleep解决,main函数输出一行文字后调用time.Sleep函数等待一秒钟。在这段等待时间内,Test函数有足够的时间执行并输出结果。在等待时间结束后,程序会继续执行并退出。输出结果可能会因为并发执行的顺序而有所不同,但Test函数的输出一定会被打印出来。
func main() {
go Test()
fmt.Println("main fun Runtime")
time.Sleep(1 * time.Second)
}
func Test() {
fmt.Println("Test01 fun Runtime")
}
输出:
main fun Runtime
Test01 fun Runtime
channel:
- channel:管道/队列,是一种引用数据类型,默认值为nil,主要用来解决协程的同步、数据共享的问题。
- channel默认是双向的,但也可以指定为单向,双向通道可以同时发送和接收数据。
- channel可以建立goroutine之间的通信连接,channel的特点是:先进先出、线程安全不需要加锁
- goroutine运行在同一个线程中,因此访问共享内存必须做好同步。
goroutine奉行通过通信来共享内存,而不是共享内存来通信。- 传统的 goroutine 使用加锁的方式来保证并发访问的安全性,锁是加在共享内存上的。而 channel 的实现原理是基于 CSP(Communicating Sequential Processes)模型,它是一种基于通信而非共享内存的并发模型,通过channel同一时间只有一个协程可以访问数据,所以不会出现抢占CPU,从而确保并发安全。
无缓冲channel:
无缓冲的channel是指在接收前没有能力保存任何值的通道,这种类型的通道要求发送goroutine和接收goroutine同时准备好,才能完成发送和接收操作,就好像两个人打电话一样,必须有人打,同时有人接,否则通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
**阻塞:**由于某种原因数据没有到达,当前协程持续处于等待状态,直到条件满足,才接触阻塞。
**同步:**在两个或多个协程(线程)间,保持数据内容一致性的机制。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SeAjlMoR-1678620655204)(/Users/itzhuzhu/Library/Application Support/typora-user-images/image-20230309004902644.png)]
无缓冲channel执行流程:
-
两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收数据。
-
左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成才解锁。
-
右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成才解锁。
-
4和5模拟了发送端将数据发出,接收端接收到数据。
-
两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。
创建channel:
ch := make(chan int) // 创建一个int类型的channel,默认长度为0
var ch chan int
发送数据到channel:
ch <- 100 // 向channel发送int类型的数值100
从channel接收数据:
c := <- ch // 从channel中接收数据,并赋值给变量c
<- ch //从从channel中接收数据,忽略结果
关闭channel:
close(ch) // 关闭channel,只能是写端关闭,且关闭后只能读数据不能写数据
查看channel的长度和容量:
func main() {
ch := make(chan int)
fmt.Println("channel中未读取数据的长度:", len(ch), "channel的容量:", cap(ch))
}
写端关闭后不能继续再写,但读端可以继续读,无缓冲的channel读到的是channel类型默认值
func main() {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch <- i
}
// 写完数据就关闭,否则会死锁,没有写端在写,但是读端会一直等
close(ch)
}()
for {
// 写端没关闭channel就返回true,读端可以读到数据
num, ok := <-ch
if ok == true {
fmt.Println("主go程读到数据:", num)
} else {
// 写端关闭就返回false,读端可以继续读,但读到的是channel数据类型默认值
n := <-ch
fmt.Println("关闭后读到的数据:", n)
break
}
}
}
输出:
主go程读到数据: 0
主go程读到数据: 1
主go程读到数据: 2
主go程读到数据: 3
主go程读到数据: 4
关闭后读到的数据: 0
除了使用if判断外,还可以使用range读数据
for num := range ch {
fmt.Println("读到数据:", num)
}
有缓冲channel:
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道,这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收,属于异步操作。
-
通道中没有要接收的值时,接收会阻塞。
-
通道没有可用缓冲区存储时,发送会阻塞。
创建channel:
ch := make(chan int , 2) // 创建一个int类型的channel,设置长度为2
写端关闭后,有缓冲的channel先从缓冲读完数据,再读就是channel的默认值。
func main() {
ch := make(chan int, 3)
go func() {
for i := 0; i < 5; i++ {
fmt.Println("子go程写入数据:", i)
// 缓冲区满时,发送会阻塞
ch <- i
// time.Sleep(time.Second) // 加上sleep解决打印顺序问题
}
close(ch)
}()
for {
// 写端没关闭channel就返回true,读端可以读到数据
num, ok := <-ch
if ok == true {
fmt.Println("主go程读到数据:", num)
} else {
// 写端关闭就返回false,读端可以继续读,但读到的是channel数据类型默认值
n := <-ch
fmt.Println("关闭后读到的数据:", n)
break
}
}
}
输出:可以看到创建的channel容量是3,但是写端写了5次,其实是打印结果有顺序问题,当子go程写完3次后,CPU被主go程抢走,但主go程只是把channel的值保存到了num中,还没来得及打印CPU又被子go程抢走了,这就会造成打印延迟,但其实已经读走了数据。打印需要调用电脑屏幕,而这种IO操作比较耗时,因为很多进程都在用屏幕嘛,加个sleep就没问题了
子go程写入: 0
子go程写入: 1
子go程写入: 2
子go程写入: 3
子go程写入: 4
主go程读到: 0
主go程读到: 1
主go程读到: 2
主go程读到: 3
主go程读到: 4
子go程写入: 5
子go程写入: 6
子go程写入: 7
子go程写入: 8
子go程写入: 9
主go程读到: 5
主go程读到: 6
主go程读到: 7
主go程读到: 8
主go程读到: 9
单向channel:
使用单向 Channel 可以增加代码的可读性和安全性,因为它可以限制对数据的访问,避免多个 Goroutine 之间产生不必要的竞争条件。
单向 Channel 只允许对数据进行发送或接收操作,而不允许同时进行。可以将一个双向 Channel 转换为单向channel,但单向不能转换为双向。
创建单向channel:
var ch1 chan int // 双向channel,可读可写
var ch2 chan<- int // 单向写channel
var ch3 <-chan int // 单向读channel
模拟生产者消费者:
生产者消费者模型是一种常见的并发编程模型,其中生产者生成数据并将其放入共享的缓冲区,而消费者则从缓冲区中取出数据并进行处理。在这个模型中,生产者和消费者是独立的线程或进程,通过缓冲区进行通信和同步。其目的是解决生产者和消费者在访问共享资源时可能会出现的竞争和冲突问题,也可以降低内部耦合度,从而提高程序的效率和并发性。
func main() {
// 先定义一个双向channel
ch := make(chan int, 3)
var s chan<- int = ch // 定义为写channel
var r <-chan int = ch // 定义为读channel
go send(s) // 子go程写,模拟生产者
rece(r) // 主go程读,模拟消费者
}
func send(s chan<- int) {
defer close(s)
for i := 0; i < 5; i++ {
// 如果读端不读就会阻塞
s <- i
fmt.Println("写了数据:", i)
}
}
func rece(c <-chan int) {
for num := range c {
fmt.Println("读到数据:", num)
}
}
死锁:
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称为系统处于死锁状态或系统产生了死锁,channel至少要在2个goroutine通信,否则会出现死锁的情况。
死锁报错:
fatal error: all goroutines are asleep - deadlock!
单Goroutine导致死锁
func main() {
c := make(chan int)
// 将789写到channel之后,因为读端没有接收,写端就会阻塞在这里,将读和写使用两个goroutine就可以解决
c <- 789 // 写端是main函数,阻塞后main就释放了CPU执行权,整个main函数结束
num := <-c // 不会走到这一步了
fmt.Println(num)
}
Goroutine之间channel访问顺序导致死锁
func main() {
ch := make(chan int)
// 这里是先去读数据,但是还没有写端开始写,所以读端阻塞,读端是main函数,阻塞后main就释放了CPU执行权,整个main函数结束
num := <-ch // 把这个拿到匿名goroutine下面就可以解决
fmt.Println(num) // 走不到这里了
go func() {
ch <- 0
}()
}
多Goroutine多channel交叉死锁
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
for {
select {
// 如果读到ch1有数据,就往ch2里写同样的数据
case num := <-ch1:
ch2 <- num
}
}
}()
for {
select {
// 如果读到ch2有数据,就往ch1里写同样的数据
case num := <-ch2:
ch1 <- num
}
}
}
互斥锁和channel混用会发生死锁现象,但不报错,算是隐式死锁,解决方式就是不要混用或使用条件变量解决
// 要求先拿锁再共享数据,发生隐式死锁
var rwMutex sync.RWMutex
func main() {
// 播种随机数种子
rand.Seed(time.Now().UnixNano())
// 用于传递数据的channel
ch := make(chan int)
for i := 0; i < 5; i++ {
go TestRead(ch, i+1)
}
for i := 0; i < 5; i++ {
go TestWrite(ch, i+1)
}
for {
}
}
func TestRead(ch <-chan int, idx int) {
for {
rwMutex.RLock() // 读锁,在这里开始阻塞,因为channel要求两端同时在线,当读模式加锁后没有释放,写端是无法加锁开始写数据的
num := <-ch
fmt.Println("第", idx, "个go程读到了", num)
rwMutex.RUnlock() // 解锁
}
}
func TestWrite(ch chan<- int, idx int) {
for {
// 生成随机数
num := rand.Intn(1000)
// 加写锁
rwMutex.Lock()
ch <- num
fmt.Println("第", idx, "个go程写入了", num)
time.Sleep(time.Second) // 为了放大实验现象
rwMutex.Unlock() // 解锁
}
}
定时器:
time.Timer是Go语言标准库中提供的一个定时器,它可以在指定的时间间隔后触发一个事件。这个事件可以是一个函数或者一个 channel,这样就不需要在程序中使用繁琐的睡眠和轮询等方式来等待时间间隔的到来了。
源码:
type Timer struct {
C <-chan Time // 写channel,定时结束后操作系统会往C里面写当前时间
r runtimeTimer
}
创建:
time.NewTimer(d) // d是时间间隔,表示多长时间后触发定时器,
<-timer.C // 等待定时器触发,如果没到时间将会阻塞,当定时器触发后,程序将会执行定时器触发后的操作。
演示:
func main() {
fmt.Println("定时前时间:", time.Now())
timer := time.NewTimer(time.Second * 2)
nowTime := <-timer.C
fmt.Println("定时结束时间:", nowTime)
}
输出:
定时前时间: 2022-03-09 22:55:57.150022 +0800 CST m=+0.000191710
定时结束时间: 2022-03-09 22:55:59.15143 +0800 CST m=+2.001609835
time.After:直接返回了timer.C,和time.NewTimer效果是一样的,也可以实现定时效果
func main() {
fmt.Println("定时前时间:", time.Now())
after := <-time.After(time.Second * 2)
fmt.Println("定时结束时间:", after)
}
输出:
定时前时间: 2022-03-09 23:01:56.826234 +0800 CST m=+0.000194251
定时结束时间: 2022-03-09 23:01:58.827544 +0800 CST m=+2.001514585
停止定时器:
time.Stop():停止 time.Timer 计时器的方法,取消未执行的定时任务,防止定时器在不需要时浪费系统资源,如果在定时器到期之前调用 time.Stop() 方法,则会取消该计时器。如果定时器已经到期并且任务已经执行,调用 time.Stop() 方法不会有任何影响。
func main() {
timer := time.NewTimer(time.Second * 2)
go func() {
<-timer.C
fmt.Println("定时结束")
}()
timer.Stop() // 设置定时器停止,相当于NewTimer的参数是0了
// 这里会出现死锁,写端是系统往channel里写当前时间,写完以后没有close,读端还会一直去读
for {
}
}
重置定时器:
time.Reset():重置定时器的时间,并开始新的计时,如果定时器已经在计时,则会停止当前计时,并按照重置后的时间开始新的计时。如果定时器已经被停止,则不会有任何效果。
func main() {
timer := time.NewTimer(time.Second * 10)
timer.Reset(time.Second * 1) // 重置定时时间
go func() {
t := <-timer.C
fmt.Println("定时完毕", t)
}()
time.Sleep(time.Second * 2)
}
周期定时器:
time.Ticker()是 Go 语言标准库中提供的一种定时触发机制,用于在指定的时间间隔内重复执行一个任务。
它会返回一个 Ticker 类型的值,Ticker 类型是一个结构体,其中包含一个 channel 和一个 time.Duration 类型的值,用于表示定时器的时间间隔。当我们通过 Ticker.C 属性读取 Ticker 结构体中的 channel 时,会每隔指定时间间隔向其中写入一个时间值。因此,我们可以通过对 Ticker.C 进行监听来实现定时触发任务的目的。
func main() {
// 创建一个bool类型的channel用于结束ticker
quit := make(chan bool)
// 创建定时器,每隔2秒给channel发送一次当前时间
ticker := time.NewTicker(time.Second * 2)
i := 0
// 启动一个goroutine,用于接收ticker的事件
go func() {
for {
i++
c := <-ticker.C
fmt.Println("读到数据:", c)
if i == 3 {
//ticker.Stop()
//runtime.Gosched()
quit <- true
}
}
}()
// 主函数阻塞在这里等着读数据,读到数据后继续往下走就终止了整个程序
fmt.Println(<-quit)
}
或使用range:
func main() {
ticker := time.NewTicker(time.Second * 2)
go func() {
for t := range ticker.C {
fmt.Println("读到数据:", t)
}
}()
time.Sleep(time.Second * 3)
}
select:
select 是 Go 语言的一种控制结构,它类似于 switch 语句,不同之处在每个case语句里必须是一个IO操作。select 可以用于在多个通道中等待可读或可写的操作,一旦其中一个通道准备好了,就会执行相应的代码块。如果多个通道都准备好了,select 会随机选择其中一个进行操作,如果都没准备好,就会阻塞等待。
default语句通常用于避免select语句的阻塞。当所有的case语句都没有满足条件时,就会执行default,如果没有default语句,select语句就会一直阻塞,直到某个case满足条件或者有case语句执行了超时操作。
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- 1:
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
演示:
func main() {
c1 := make(chan int)
c2 := make(chan int)
c3 := make(chan bool)
go func() {
c1 <- 0
time.Sleep(time.Second * 2)
}()
go func() {
c2 <- 1
time.Sleep(time.Second * 2)
}()
go func() {
for {
select {
case message1 := <-c1:
fmt.Println("message1读到数据:", message1)
case message2 := <-c2:
fmt.Println("message2读到数据:", message2)
// 如果2秒内一直没有case满足就退出
case <-time.After(time.Second * 2):
c3 <- true
break
}
}
}()
<-c3
}
斐波那契数:
func main() {
ch := make(chan int)
quit := make(chan bool)
// 子go程负责打印
go count(ch, quit)
// 先定义前两个数
x, y := 1, 1
// 循环用于确定计算多少个斐波那契数
for i := 0; i < 20; i++ {
ch <- x
// 循环交换x、y的值
x, y = y, x+y
}
quit <- true
}
func count(ch <-chan int, quit <-chan bool) {
for {
select {
case num := <-ch:
fmt.Print(num, ",")
case <-quit:
runtime.Gosched()
}
}
}
条件变量:
条件变量是一种线程同步的机制,它允许一个或多个线程等待另一个线程的某些操作完成,然后再继续执行。条件变量不是锁,在并发中不能达到同步的目的,因此条件变量总是与锁一块使用。
如果不使用条件变量完成生产者消费者模型是这样的。
func main() {
rand.Seed(time.Now().UnixNano()) // 设置随机数种子
ch := make(chan int, 3) // channel模拟共享资源
for i := 0; i < 5; i++ {
go Producer(ch, i+1)
}
for i := 0; i < 5; i++ {
go Consumer(ch, i+1)
}
time.Sleep(time.Second)
close(ch)
}
func Consumer(ch chan int, i int) {
for num := range ch {
fmt.Println("第", i, "个消费者,消费了数据:", num)
}
}
func Producer(ch chan int, i int) {
for {
// 判断缓冲区是否已满
if len(ch) == 3 {
continue
}
// 不满就生成随机数并写数据到channel
num := rand.Intn(1000)
ch <- num
fmt.Println("----第", i, "个生产者,生产了数据:", num)
}
}
输出:可以看到结果是生产者生产完以后消费者并没有按照顺序去消费,还是因为读数据和打印分开执行了,读到数据刚要打印CPU执行权就被抢走了,如果是用这些数据进行计算,那么就会发生数据混乱
----第 2 个生产者,生产了数据: 633
第 3 个消费者,消费了数据: 843
第 3 个消费者,消费了数据: 752
第 3 个消费者,消费了数据: 633
第 3 个消费者,消费了数据: 180
第 3 个消费者,消费了数据: 223
第 3 个消费者,消费了数据: 680
第 2 个消费者,消费了数据: 163
第 4 个消费者,消费了数据: 604
第 5 个消费者,消费了数据: 22
----第 4 个生产者,生产了数据: 223
----第 4 个生产者,生产了数据: 478
----第 4 个生产者,生产了数据: 606
----第 4 个生产者,生产了数据: 67
----第 4 个生产者,生产了数据: 111
第 1 个消费者,消费了数据: 146
第 1 个消费者,消费了数据: 423
另外一个问题,如果消费者比生产者多,仓库中就会出现没有数据的情况。我们需要不断的通过循环来判断仓库中是否有数据,这样会造成cpu的浪费。反之,如果生产者比较多,仓库很容易满,满了就不能继续添加数据,也需要循环判断仓库满这一事件,同样也会造成CPU的浪费。
我们希望当仓库满时,生产者停止生产,等待消费者消费;同理,如果仓库空了,我们希望消费者停下来等待生产者生产。为了达到这个目的,这里引入条件变量。
| 方法 | 作用 |
|---|---|
| func (c *Cond) Wait() | 1、阻塞等待条件变量满足 2、释放已掌握的互斥锁相当于cond.L.Unlock()。 注意:1和2两步为一个原子操作(不会被线程调度机制打断的操作) 3、广播通知,给正在等待(阻塞)在该条件变量上的所有goroutine发送通知。 |
| func (c *Cond) Signal() | 单发通知,给一个正等待(阻塞)在该条件变量上的goroutine发送通知 |
| func (c *Cond) Broadcast() | 广播通知,给正在等待(阻塞)在该条件变量上的所有goroutine发送通知 |
演示:
// 创建全局变量
var cond sync.Cond
func main() {
rand.Seed(time.Now().UnixNano()) // 设置随机数种子
ch := make(chan int, 3) // channel模拟共享资源
// 创建互斥锁和条件变量 ,cond.L:给公共区加锁
cond.L = new(sync.Mutex)
for i := 0; i < 5; i++ {
go Producer(ch, i+1)
}
for i := 0; i < 5; i++ {
go Consumer(ch, i+1)
}
// 加上死循环,可以看到终端已经不打印了,隐式死锁出现了
for {
}
}
func Consumer(ch chan int, i int) {
for {
// 先加锁
cond.L.Lock()
// 判断缓冲区是否为空
if len(ch) == 0 {
cond.Wait()
}
num := <-ch
fmt.Println("第", i, "个消费者,消费了数据:", num)
// 访问公共区结束,并打印结束再解锁
cond.L.Unlock()
// 唤醒阻塞在条件变量上的对端
cond.Signal()
cond.Broadcast()
}
}
func Producer(ch chan int, i int) {
for {
// 先加锁
cond.L.Lock()
// 判断缓冲区是否已满
if len(ch) == 3 {
cond.Wait()
}
// 不满就生成随机数并写数据到channel
num := rand.Intn(1000)
ch <- num
fmt.Println("----第", i, "个生产者,生产了数据:", num)
// 访问公共区结束,并打印结束再解锁,否则会有几率出现,刚把num写到了channel,正准备Println时CPU使用权被抢
cond.L.Unlock()
// 唤醒阻塞在条件变量上的对端
cond.Signal()
}
}
在这段代码中,可能会出现生产者和消费者同时处于等待条件变量的状态,导致死锁。因为在生产者或消费者获取锁之后,仅仅通过 Wait() 来等待条件变量的唤醒。但当所有生产者和消费者都在等待时,没有任何一个可以对条件变量进行操作,这会导致所有goroutine一直处于等待状态,无法继续执行。
为了避免这种情况,我们需要更改 Wait() 的使用方式。在 Wait() 之前,需要用 for 循环判断条件变量的状态,避免虚假唤醒。当一个goroutine被唤醒时,需要重新检查条件变量的状态,如果不符合要求,则需要再次等待条件变量的唤醒。
// 创建全局变量
var cond sync.Cond
func main() {
rand.Seed(time.Now().UnixNano()) // 设置随机数种子
ch := make(chan int, 3) // channel模拟共享资源
// 创建互斥锁和条件变量 ,cond.L:给公共区加锁
cond.L = new(sync.Mutex)
for i := 0; i < 5; i++ {
go Producer(ch, i+1)
}
for i := 0; i < 5; i++ {
go Consumer(ch, i+1)
}
time.Sleep(time.Second)
close(ch)
}
func Consumer(ch chan int, i int) {
for {
// 先加锁
cond.L.Lock()
// 判断缓冲区是否为空
for len(ch) == 0 {
cond.Wait()
}
num := <-ch
fmt.Println("第", i, "个消费者,消费了数据:", num)
// 访问公共区结束,并打印结束再解锁
cond.L.Unlock()
// 唤醒阻塞在条件变量上的对端
cond.Signal()
cond.Broadcast()
}
}
func Producer(ch chan int, i int) {
for {
// 先加锁
cond.L.Lock()
// 判断缓冲区是否已满
for len(ch) == 3 {
cond.Wait()
}
// 不满就生成随机数并写数据到channel
num := rand.Intn(1000)
ch <- num
fmt.Println("----第", i, "个生产者,生产了数据:", num)
// 访问公共区结束,并打印结束再解锁,否则会有几率出现,刚把num写到了channel,正准备Println时CPU使用权被抢
cond.L.Unlock()
// 唤醒阻塞在条件变量上的对端
cond.Signal()
}
}
输出:
----第 4 个生产者,生产了数据: 412
----第 4 个生产者,生产了数据: 797
----第 4 个生产者,生产了数据: 188
第 4 个消费者,消费了数据: 412
第 4 个消费者,消费了数据: 797
第 4 个消费者,消费了数据: 188
----第 4 个生产者,生产了数据: 722
----第 4 个生产者,生产了数据: 899
----第 4 个生产者,生产了数据: 467
第 4 个消费者,消费了数据: 722
第 4 个消费者,消费了数据: 899
第 4 个消费者,消费了数据: 467
----第 4 个生产者,生产了数据: 11
----第 4 个生产者,生产了数据: 752
----第 4 个生产者,生产了数据: 216
第 4 个消费者,消费了数据: 11
第 4 个消费者,消费了数据: 752
第 4 个消费者,消费了数据: 216
runtime包:
Gosched():
用于让当前的Go协程暂停,让出 CPU 时间片给其他协程执行的函数。它的作用是协程调度,避免某些协程长时间占用 CPU 资源,导致其他协程无法得到执行的机会。并在下次再获得cpu时间轮片的时候,从该出让cpu的位置恢复执行。
下面的程序执行结果是,main和test交替执行,基本上打印数量是差不多的
func main() {
go Test()
// 循环次数太少main抢到CPU一口气就打印完了,要多一点才能看到效果
for i := 0; i < 500; i++ {
fmt.Println("main fun Runtime")
}
}
func Test() {
for i := 0; i < 500; i++ {
fmt.Println("Test fun Runtime")
}
}
使用runtime.Gosched后可以看到Test协程打印的非常少了。如果循环次数太低,main执行完毕Test就不会被执行了,直接终止程序了
func main() {
go Test()
for i := 0; i < 500; i++ {
fmt.Println("main fun Runtime")
}
}
func Test() {
for i := 0; i < 500; i++ {
/*
流程:
1. 调用Test()
2. 遇到Gosched(),开始让出时间片,不向下继续执行l,此时main开始拿到执行权
3. 直到main函数失去CPU执行权,Test和main协程开始抢占CPU执行权
4. 假设Test抢到,接着让出时间片的位置继续执行代码,打印Test fun Runtime,下一次循环碰到Gosched又让出时间片
*/
runtime.Gosched()
fmt.Println("Test fun Runtime")
}
}
Goexit:
当 Goexit() 函数被调用时,该协程中正在执行的函数将立即停止执行,任何延迟函数将被忽略,并且该协程将从调用 Go() 函数启动的堆栈中返回。如果该协程是在 main() 函数中创建的,则整个程序将终止。这个函数通常用于在协程中发现错误或完成任务时,用于优雅地终止协程并释放相关资源,避免出现意外的行为。
func main() {
fmt.Println("A")
go func() {
defer fmt.Println("B")
runtime.Goexit() // 在这直接跳出匿名函数了,下面的通通不执行,即使是defer
defer fmt.Println("C") // 不会被执行
}()
fmt.Println("D")
for {
}
}
输出:
A
D
B
GOMAXPROCS:
用来设置可以并行计算的CPU核数的最大值,并返回上一次设置的核心数。
func main() {
// 设置为单核,可以看到go程抢占CPU的效果
num := runtime.GOMAXPROCS(1)
fmt.Println("上一次设置CPU核数", num)
for i := 0; i < 20; i++ {
time.Sleep(time.Second)
// 主go程和子go程抢占CPU执行权,可以看到熬01交替效果
go fmt.Print(0)
fmt.Print(1)
}
}
输出:
上一次设置CPU核数 10
101010101010101010101010101010101010101
















 7650
7650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











