







这里写自定义目录标题
- 一. 原理分析
- 二. 搭建HDFS高可用集群
- 1. 环境准备
- 2. 安装zookeeper
- 3. zookeeper 安装包下载
- 4.准备3个zk下创建数据存放目录
- 5.在每个数据文件夹中准备一个myid文件
- 6. 编辑每个data目录中myid
- 7. 将zk配置文件zoo.cfg创建在zkdata目录中
- 8.启动zk节点
- 8. 查看zk角色信息
- 9. 其他三台Hadoop机器
- 10.配置hadoop的core-site.xml 三个机器一致
- 11.配置hdfs-site.xml
- 12. 修改slaves文件指定哪些机器为DataNode
- 13.在任意一个namenode上执行如下命令
- 14.启动journalnode(分别在在hadoop12、hadoop13、hadoop14上执行)
- 15.在hadoop13上执行(NameNode active)节点执行
- 16.启动hdfs集群
- 17.在standby 的 NameNode节点上执行如下命令
- 18.停止Hadoop12正常NameNode进行测试
一. 原理分析
在故障自动转移的处理上,引入了监控Namenode状态的ZookeeperFailController(ZKFC)。ZKFC一般运行在Namenode的宿主机器上,与Zookeeper集群协作完成故障的自动转移。
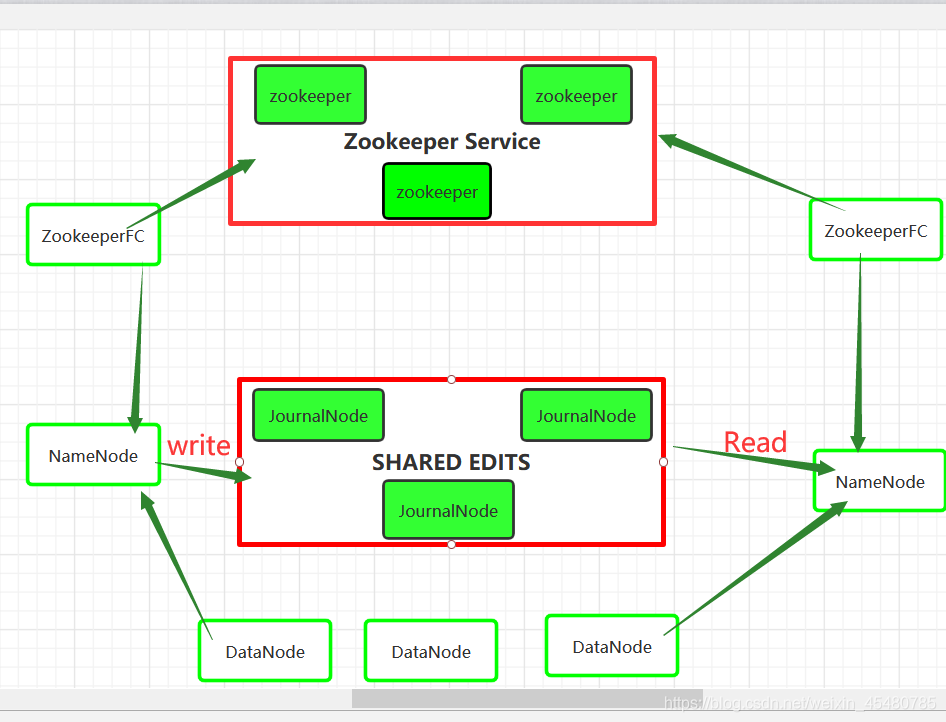
二. 搭建HDFS高可用集群
1. 环境准备
搭建HDFS环境前面有
zk1 192.168.153.9
zk2 192.168.153.10
zk3 192.168.153.11
hadoop12 192.168.153.12
hadoop13 192.168.153.13
hadoop14 192.168.153.14

2. 安装zookeeper

3. zookeeper 安装包下载
zookeeper 安装包下载
链接:https://pan.baidu.com/s/1TzzEDBNlxQxOMeleE0YHxw
提取码:ngkp
复制这段内容后打开百度网盘手机App,操作更方便哦
4.准备3个zk下创建数据存放目录
mkdir -p /root/zkdata

5.在每个数据文件夹中准备一个myid文件
touch /root/zkdata/myid
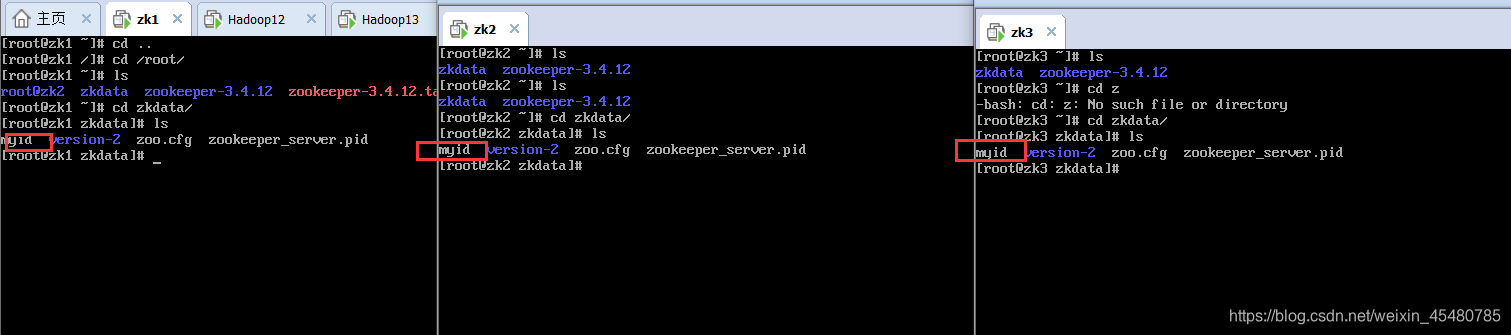
6. 编辑每个data目录中myid
vim /root/zkdata/myid 分别在zk的myid输入 1 2 3

7. 将zk配置文件zoo.cfg创建在zkdata目录中
添加配置文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata
clientPort=3001
server.1=zk1:3002:3003
server.2=zk2:4002:4003
server.3=zk3:5002:5003
三台zk的配置文件
vim /root/zkdata/zoo.cfg

8.启动zk节点
./zkServer.sh start /root/zkdata/zoo.cfg
启动三台zk机器的zk结点

8. 查看zk角色信息
[root@zk3 bin]# ./zkServer.sh status /root/zkdata/zoo.cfg
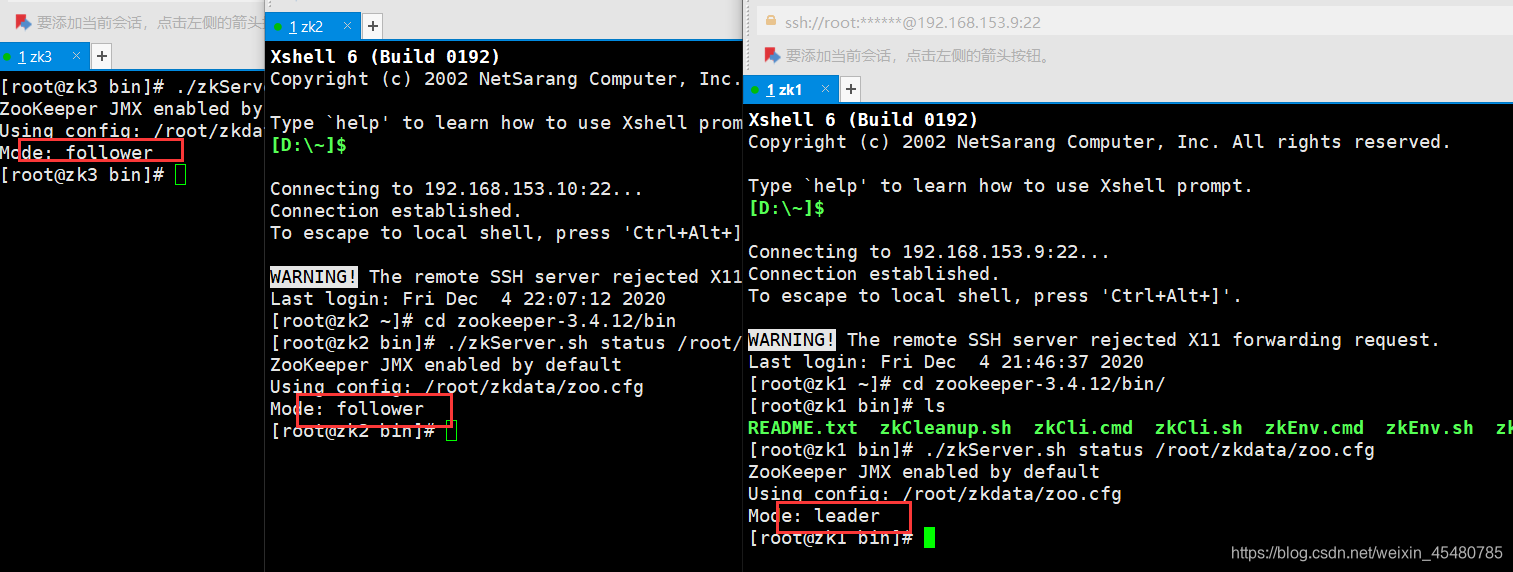
9. 其他三台Hadoop机器
hadoop12 192.168.153.12 --- namenode(active) & datanode & DFSZKFailoverController(zkfc)
hadoop13 192.168.153.13 --- datanode & namenode(standby) & DFSZKFailoverController(zkfc)
hadoop14 192.168.153.14 --- datanode
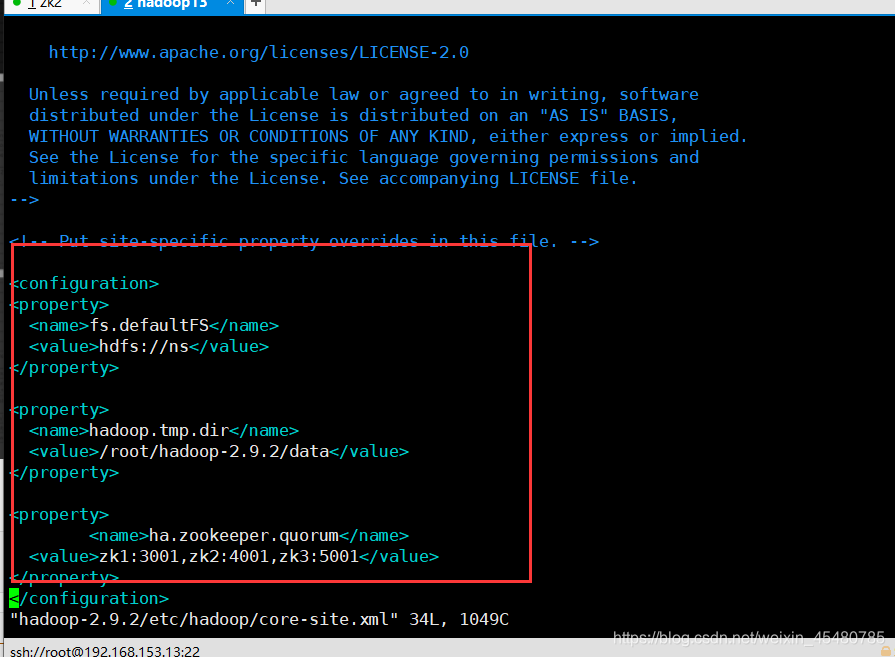
10.配置hadoop的core-site.xml 三个机器一致
[root@hadoop13 ~]# vim hadoop-2.9.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.9.2/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:3001,zk2:4001,zk3:5001</value>
</property>
</configuration>
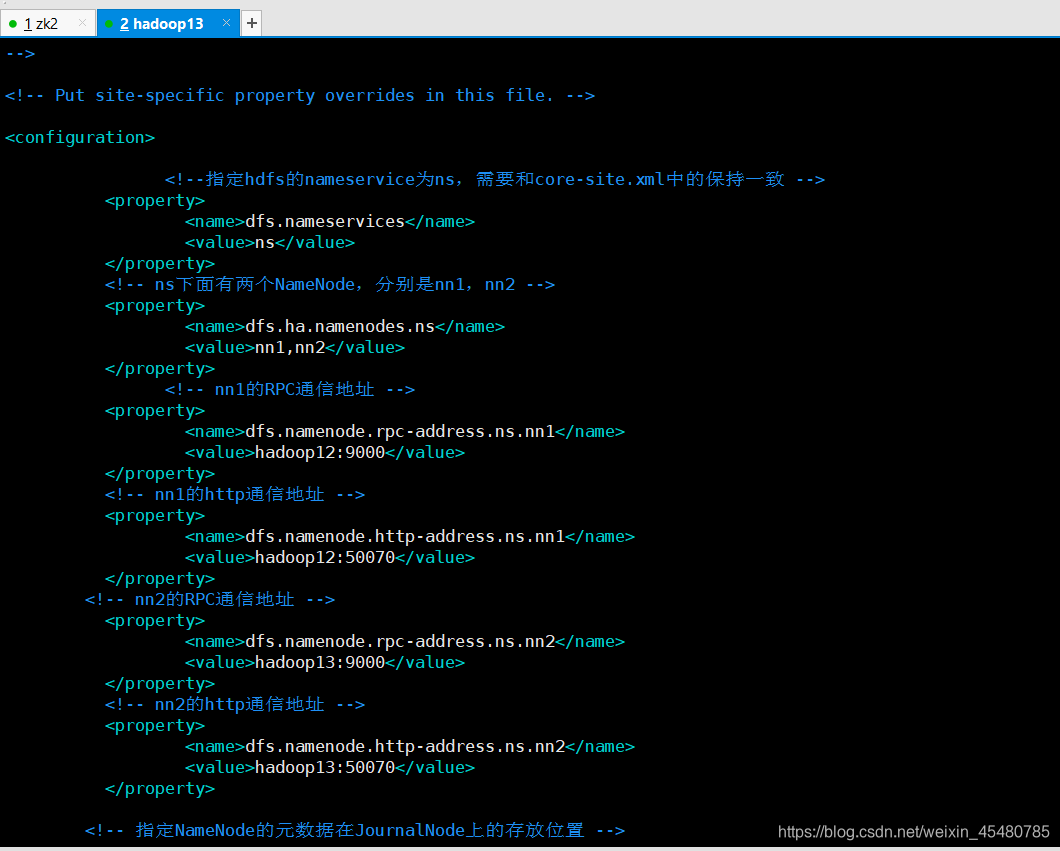
11.配置hdfs-site.xml
vim hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop12:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop12:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop13:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop13:50070</value>
</property>
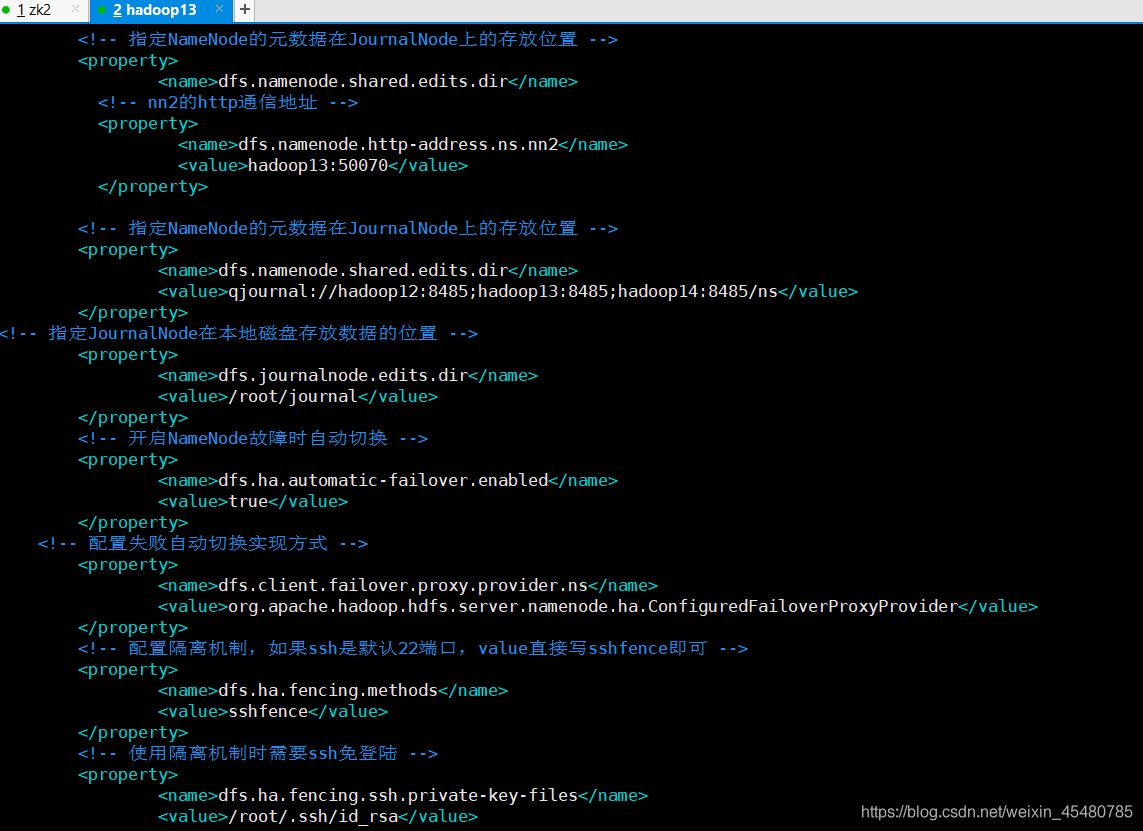
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop12:8485;hadoop13:8485;hadoop14:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
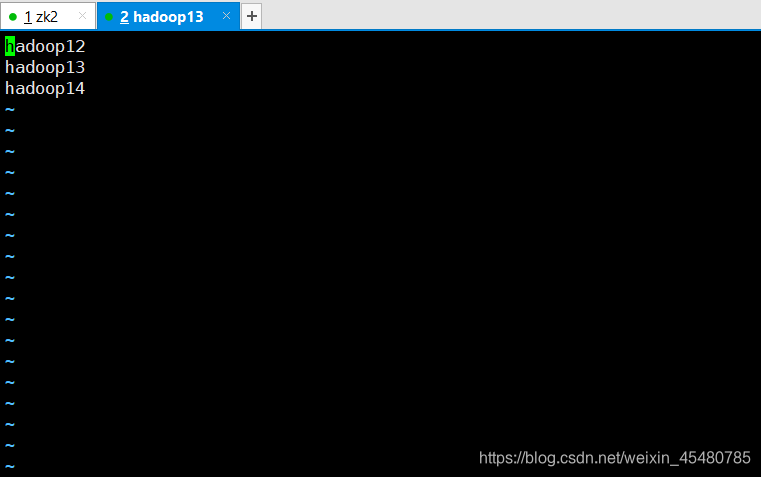
12. 修改slaves文件指定哪些机器为DataNode
vim hadoop-2.9.2/etc/hadoop/slaves
三台hadoop都是一样的配置
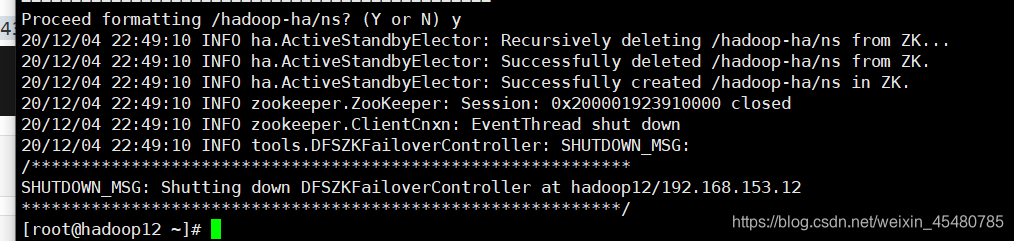
13.在任意一个namenode上执行如下命令
[root@hadoop12 ~]# hdfs zkfc -formatZK
14.启动journalnode(分别在在hadoop12、hadoop13、hadoop14上执行)
[root@hadoop12 ~]# hadoop-daemon.sh start journalnode
[root@hadoop13 ~]# hadoop-daemon.sh start journalnode
[root@hadoop14 ~]# hadoop-daemon.sh start journalnode
三台机器jps都是这个
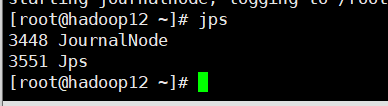
15.在hadoop13上执行(NameNode active)节点执行
[root@hadoop13 ~]# hdfs namenode -format ns

16.启动hdfs集群
[root@hadoop13 ~]# start-dfs.sh
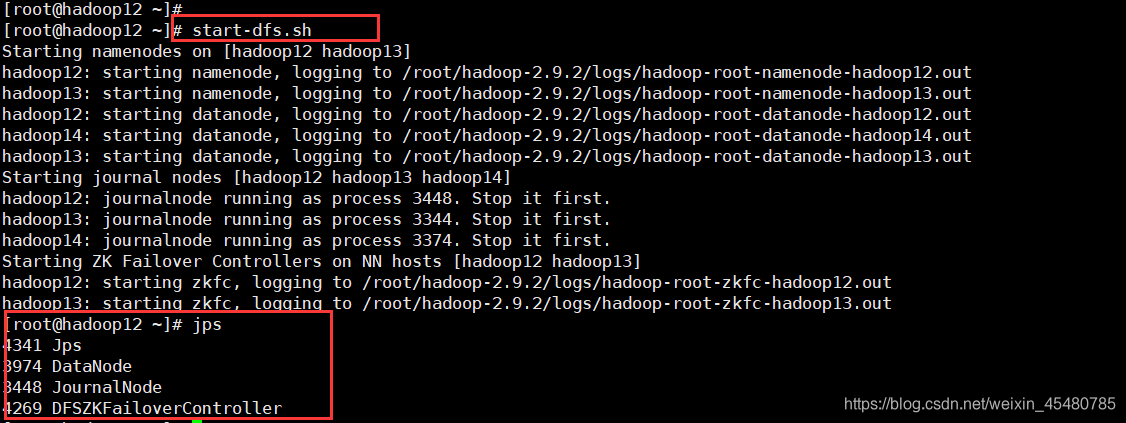
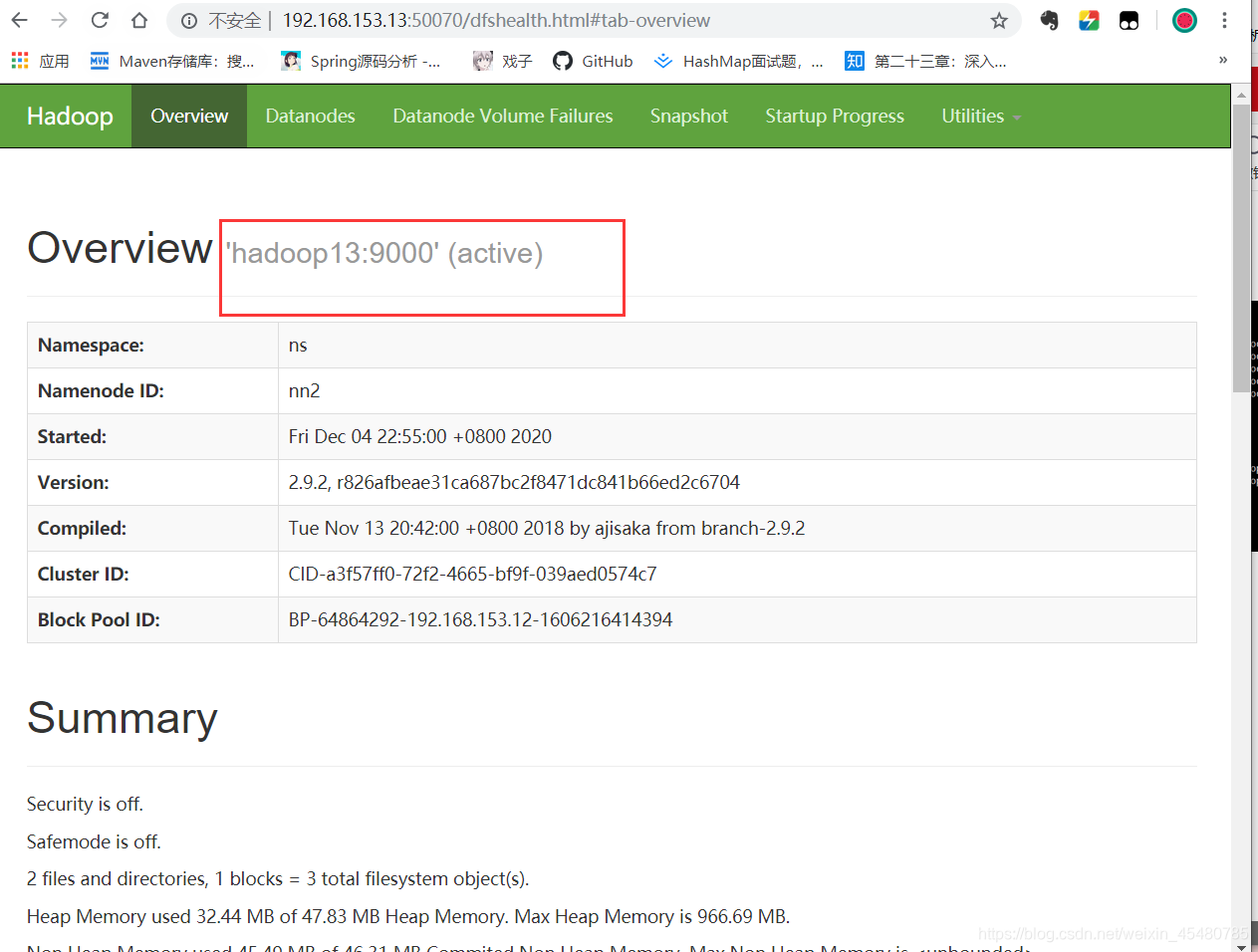
17.在standby 的 NameNode节点上执行如下命令
[root@hadoop12 ~]# hdfs namenode -bootstrapStandby
[root@hadoop12 ~]# hadoop-daemon.sh start namenode
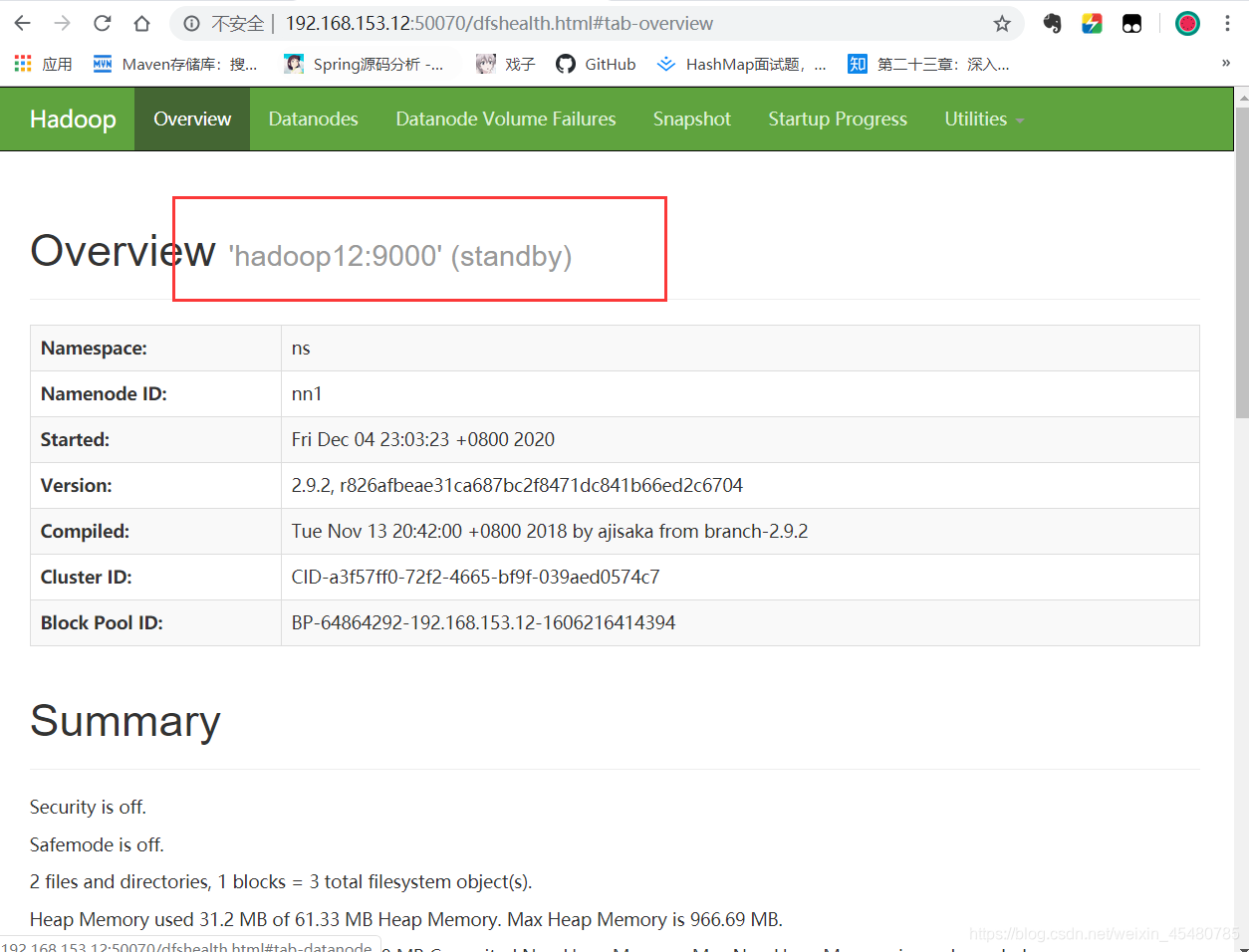
三台机器的jps
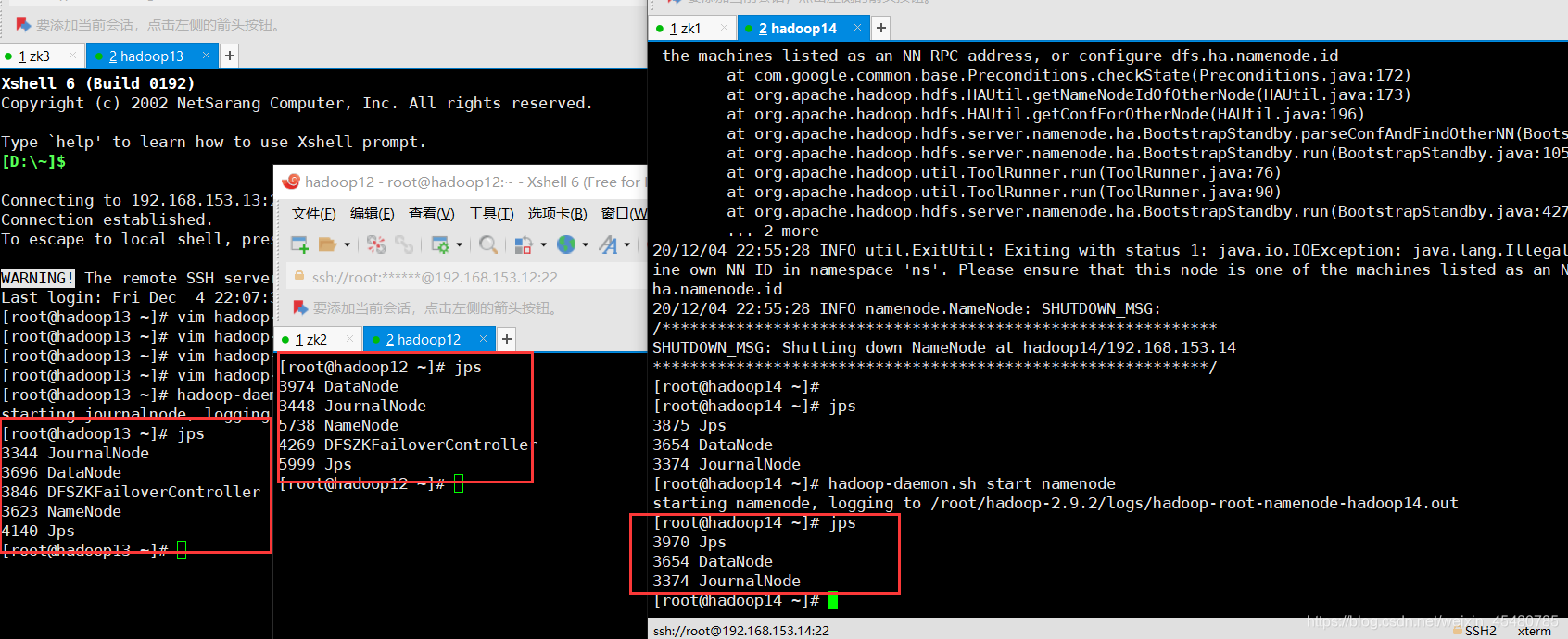
18.停止Hadoop12正常NameNode进行测试
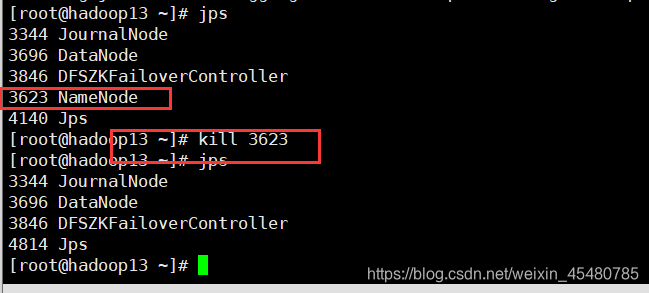
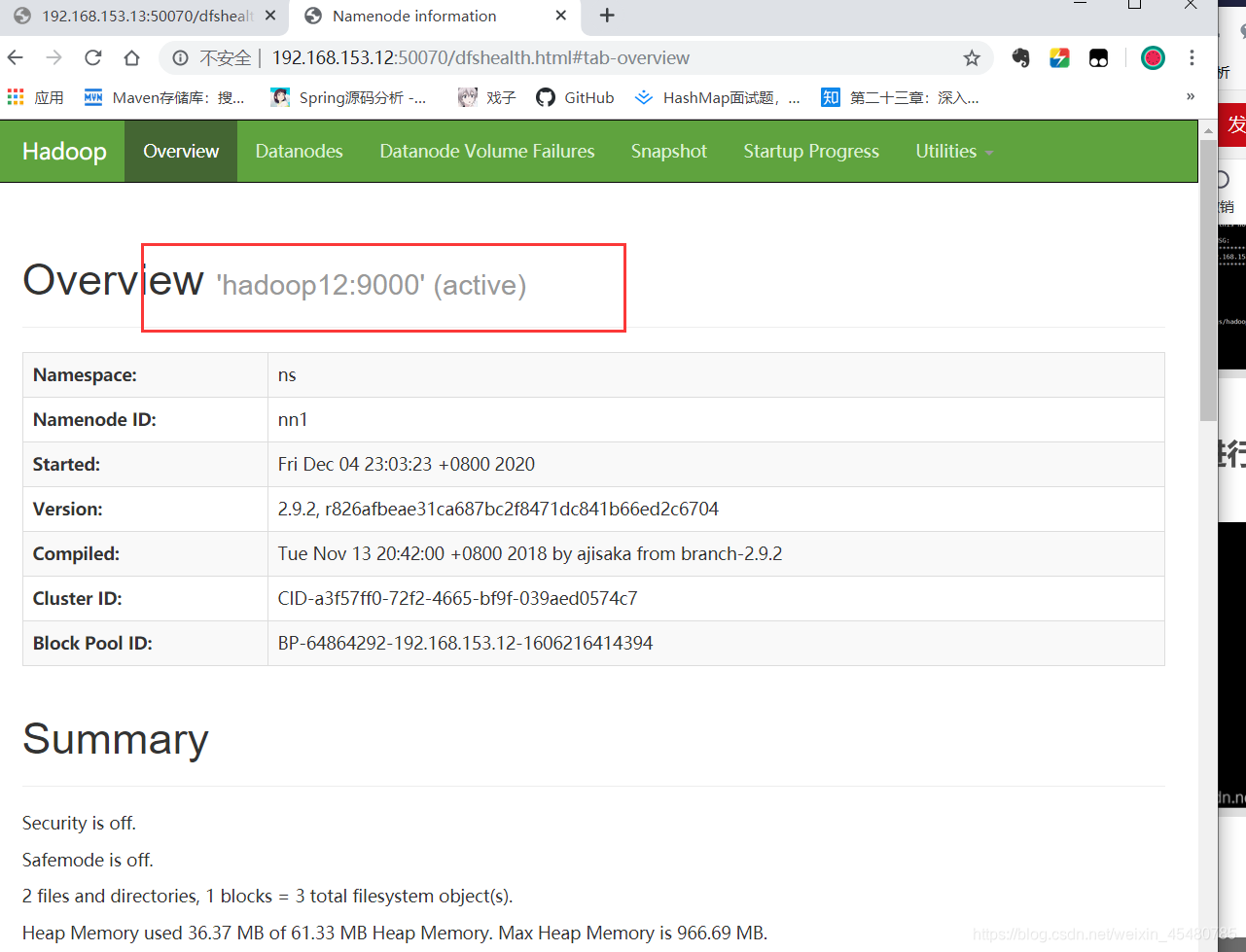
Hadoop12由standby变成active














 7397
7397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









