







【论文泛读】 Faster R-CNN:利用RPN实现实时目标检测
文章目录
论文链接: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (arxiv.org)
现在开始读目标检测的论文,我先总结了一下关于目标检测的相关论文和一些代码资源,都在我们的链接
红色的是目标检测必读的一些论文,今天我读的论文就是2015的何恺明大神的又一巨作Faster R-CNN

前言
R-CNN是目标检测领域中十分经典的方法,相比于传统的手工特征,R-CNN将卷积神经网络引入,用于提取深度特征,后接一个分类器判决搜索区域是否包含目标及其置信度,取得了较为准确的检测结果。Fast R-CNN和Faster R-CNN是R-CNN的升级版本,在准确率和实时性方面都得到了较大提升。
在Fast R-CNN中,首先需要使用Selective Search的方法提取图像的候选目标区域(Proposal)。而新提出的Faster R-CNN模型则引入了RPN网络(Region Proposal Network),将Proposal的提取部分嵌入到内部网络,实现了卷积层特征共享,Fast R-CNN则基于RPN提取的Proposal做进一步的分类判决和回归预测,因此,整个网络模型可以完成端到端的检测任务,而不需要先执行特定的候选框搜索算法,显著提升了算法模型的实时性。
Faster R-CNN是截止目前,RCNN系列算法的最杰出产物,two-stage中最为经典的物体检测算法。推理第一阶段先找出图片中待检测物体的anchor矩形框(对背景、待检测物体进行二分类),第二阶段对anchor框内待检测物体进行分类。
讲Faster R-CNN,就不得不讲讲R-CNN和Fast R-CNN的原理,这里只是粗略的讲一下,具体可以看论文
R-CNN(Region with CNN feature)可以分为4个步骤
- region proposal(Selective Search方法,具体可以去看他的论文,主要讲的就是生成1K ~ 2 K个候选框,用颜色等特征进行融合)
- feature extraction(Deep Net):用卷积神经网络对每个region提取特征(Alex-net),去掉了全连接层
- Classification(SVM):对proposal提取到的特征进行分类,用的方法是SVM,每一类都有一个SVM分类器
- rect refine(regression):使用回归器对propoposal进行修正。
同样的R-CNN有一些缺点
- 测试速度慢,每张图片需要 2 s
- 训练速度慢,过程极其繁琐
- 训练所需空间大,要数百GB的空间
Fast R-CNN用VGG-16作为backbone,比R-CNN训练时间快9倍,测试推理快213倍。
大概也是分为4个步骤
- region proposal(SS):与R-CNN相同
- feature extraction(Deep net):将图像输入网络得到相应的特征图,然后将SS算法生成的候选框投影到特征图上获得相应的特征矩阵。
- classification(Deep net):将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展评通过一系列全连接层得到预测结果。
- refine(Deep net)
注意:R-CNN存在着重复计算的问题(proposal的region有几千个,多数都是互相重叠,重叠部分会多次重复提取特征,浪费时间),作者借助SPP-net搞出了Fast-RCNN,跟R-CNN最大区别就是Fast-RCNN将proposal的region映射到CNN的最后一层feature map,这样一张图片只需要提取一次特征。而且把分类也在卷积神经网络一起解决了
摘要 Abstract
最新的检测网络都依赖区域推荐算法来推测物体位置。像SPPnet[和Fast R-CNN已经大幅削减了检测网络的时间开销,但区域推荐的计算却变成了瓶颈。本论文将引入一个区域推荐网络(RPN)和检测网络共享全图像卷积特征,使得区域推荐的开销几近为0。一个RPN是一个全卷积网络技能预测物体的边框,同时也能对该位置进行物体打分。RPN通过端到端的训练可以产生高质量的推荐区域,然后再用Fast R-CNN进行检测。通过共享卷积特征,我们进一步整合RPN和Fast R-CNN到一个网络,用近期流行的“术语”说,就是一种“注意力”机制。RPN组件会告诉整合网络去看哪个部分。对于非常深的VGG-16模型[3]。我们的检测系统在GPU上达到了5fps的检测帧率(包括所有步骤),同时也在PASCAL VOC2007,2012和MS COCO数据集上达到了最好的物体检测精度,而对每张图片只推荐了300个区域。在ILSVRC和COCO 2015竞赛中,Faster R-CNN和RPN是多个赛道都赢得冠军的基础。
介绍 Introduction
区域推荐方法和基于区域的卷积神经网络(RCNNs)的成功推动了物体检测水平的进步。但是推荐显然是最先进检测系统的瓶颈。区域推荐仍然是目标检测的主要耗时阶段。
在这篇论文中,展示一个算法上的改变——使用深度卷积神经网络计算推荐区域——将引出一个优雅而高效的解决方案,在给定检测网络完成的计算的基础上,让区域的计算近乎为0。提出了一个新型的区域推荐网络(Region Proposal Networks,RPNs),它和当今世界最棒的检测网络(当时是VGG16和ZFnet)共享卷积层。通过在测试阶段共享卷积,让计算推荐区域的边际成本变得很低。(大约每张图片10ms)
RPNs被设计用来高效地预测各种尺度和宽高比的区域推荐,这里提出了一个“Anchor(锚点)”,使用“锚点”盒(“anchor” boxes)作为不同尺度和宽高比的参照物。我们的模式可以看做是一个回归参照物的金字塔,这避免了穷举各种尺度和宽高比的图像或过滤器。这个模型在单一尺度图像的训练和测试时表现优异,因而运行速度大为受益。
为了统一RPNs和Fast R-CNN物体检测网络,我们提出一种介于区域推荐任务调优和之后的物体检测调优之间的训练方法,同时还能保证固定的推荐。这个方法可以很快收敛,并产生一个统一的网络,该网络在两个任务上共享卷积特征。
在ILSVRC和COCO 2015竞赛中,Faster R-CNN和RPN是多项分赛长的第一名,包括ImageNet 检测,ImageNet定位,COCO检测和COCO分割。RPNs从数据中完全学会了推荐区域,而且使用更深或更有表达力的特征(比如101层的Resnet)效果会更好。Faster R-CNN和RPN也用于多个其他领先名词的团队所使用。这些结果都说明我们的方法不仅实用省时,而且有效精准。
相关工作 Related Work
这里略微提一下
首先是物体推荐,物体推荐算法大部分有几种,广泛使用的有基于grouping super-pixels(如Selective Search, CPMC等算法),还有就是基于滑动窗口的,比如EdgeBox。
其次就是深度神经网络在目标检测上的影响,R-CNN是一个端到端的模型,它利用CNNs进行分类物体类别和背景。还有一些模型比如OverFeat、MultiBox 方法,这些可能得去看相关的论文。
总结起来,这种卷积计算的共享,越来越受关注,OverFeat中针对分类、定位、检测时会只从一个图像金字塔计算卷积特征。尺寸自适应的SPP也是建立在共享卷积特征图智商的,在基于区域的物体检测[1][30]和语义分割上很有效。Fast R-CNN使得端到端的检测器训练全部建立在共享卷积特征之上,表现出了有引人注目的精度和速度。
Faster R-CNN
Faster R-CNN有两个模块组成,整个网络是一个单一、通以的目标检测网络。
- 第一个模块是深度卷积网络用于生成推荐区域
- 第二个模块是Fast R-CNN用来推荐的区域的检测器
其实又可以细分为四个部分,Conv Layer,Region Proposal Network(RPN),RoI Pooling,Classification and Regression,就如下面论文中的图一样
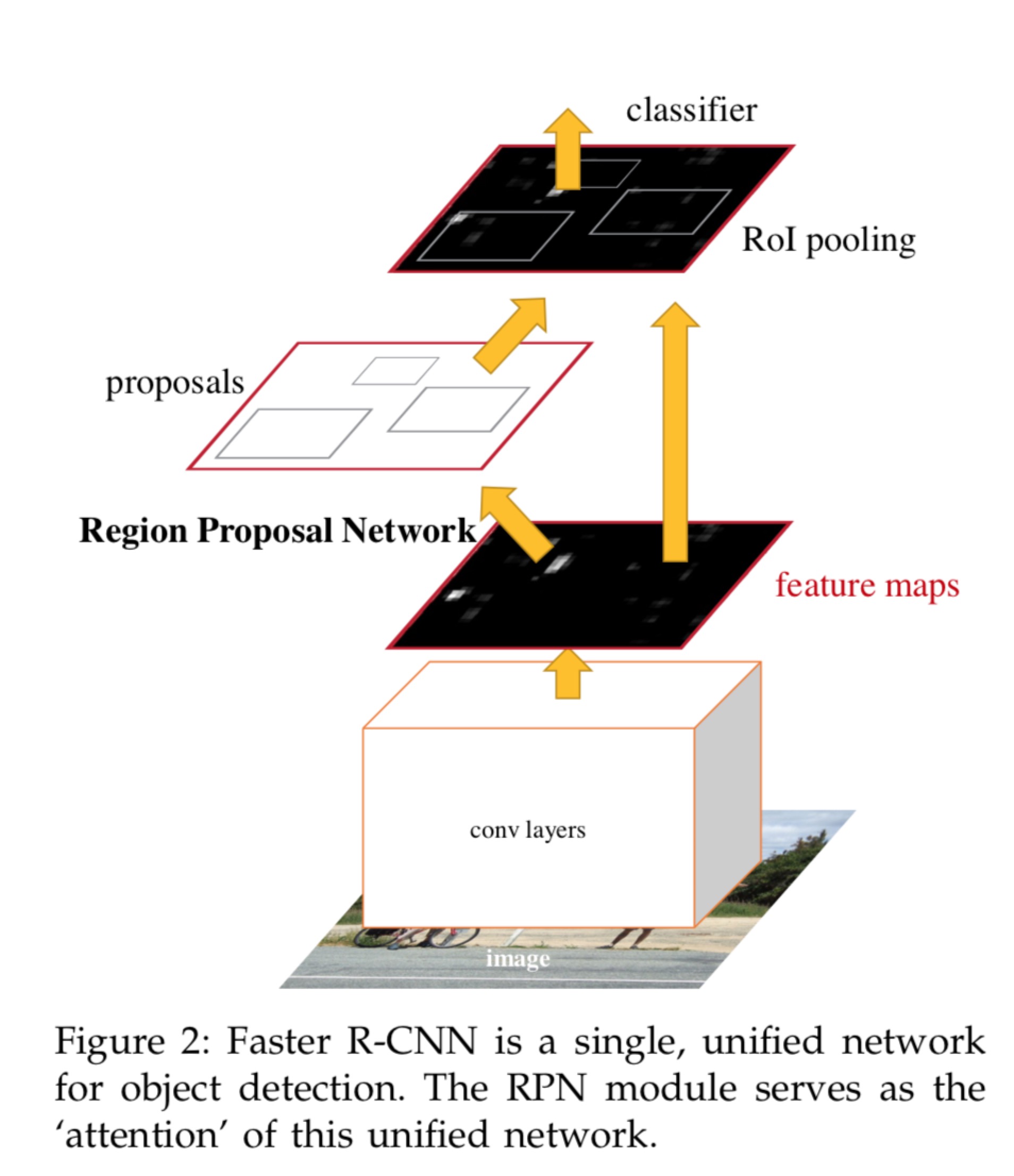
-
Conv layers:卷积层包括一系列卷积(Conv + Relu)和池化(Pooling)操作,用于提取图像的特征(feature maps),一般直接使用现有的经典网络模型ZF或者VGG16,而且卷积层的权值参数为RPN和Fast RCNN所共享,这也是能够加快训练过程、提升模型实时性的关键所在。
-
Region Proposal Networks:RPN层是faster-rcnn最大的亮点,RPN网络用于生成region proposcals.基于网络模型引入的多尺度Anchor,通过Softmax对anchors属于目标(foreground)还是背景(background)进行分类判决,并使用Bounding Box Regression对anchors进行回归预测,获取Proposal的精确位置,并用于后续的目标识别与检测。
-
Roi Pooling:综合卷积层特征feature maps和候选框proposal的信息,将propopal在输入图像中的坐标映射到最后一层feature map(conv5-3)中,对feature map中的对应区域进行池化操作,得到固定大小(7×77×7)输出的池化结果,并与后面的全连接层相连。
-
Classification and Regression: 全连接层后接两个子连接层——分类层(cls)和回归层(reg),分类层用于判断Proposal的类别,回归层则通过bounding box regression预测Proposal的准确位置。
Region Proposal Networks 区域推荐网络
RPN网络用于生成区域候选框Proposal,基于网络模型引入的多尺度Anchor,通过Softmax对anchors属于目标(foreground)还是背景(background)进行分类判决,并使用Bounding Box Regression对anchors进行回归预测,获取Proposal的精确位置,并用于后续的目标识别与检测。
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如RCNN使用SS(Selective Search)方法生成检测框。
而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster RCNN的巨大优势,能极大提升检测框的生成速度。
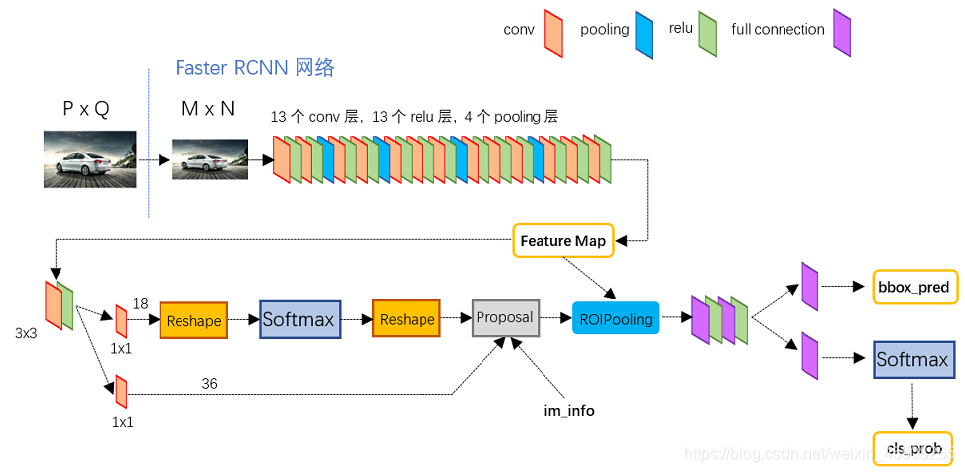
上图中展示了RPN网络的具体结构,可以看到,feature map 经过一个3×3卷积核卷积后分成了两条线,上面一条通过softmax对anchors分类获得foreground和background(检测目标是foregrounnd),因为是2分类,所以它的维度是2k scores。
下面那条线是用于计算anchors的bounding box regression的偏移量,以获得精确的proposal。它的维度是4k coordinates。
而最后的proposcal层则负责综合foreground anchors和bounding box regression偏移量获取proposal,同时剔除太小和超出边界的propocals,其实网络到这个Proposal Layer这里,就完成了目标定位的功能
锚点 Anchor
Anchor是RPN网络中一个较为重要的概念,传统的检测方法中为了能够得到多尺度的检测框,需要通过建立图像金字塔的方式,对图像或者滤波器(滑动窗口)进行多尺度采样。RPN网络则是使用一个3×3的卷积核,在最后一个特征图(conv5-3)上滑动,将卷积核中心对应位置映射回输入图像,生成3种尺度(scale){ 12 8 2 , 25 6 2 , 51 2 2 128^2,256^2,512^2 1282,2562,5122}和3种长宽比(aspect ratio){1:1,1:2,2:1}共9种Anchor。

平移不变性锚点
在我们的目标检测中,我们有一个平移不变性,如果我们用K-means生成800个锚点,是不满足平移不变的,就算是用MultiBox也不能保证,但是作者的方法用卷积输出层有平移不变性,并且可以降低模型的参数,大约有降低了两个数量级,并且在小数据集中也有更低的过拟合的风险。
损失函数 Loss Function
在训练RPN时,我们对每个锚点设置两个标签(物体 or 背景)。并且我们将锚点设为正样本如果它是两种情况之一。
- 具有与实际边界框的重叠最高交并比(IoU)的锚点
- 具有与实际边界框的重叠超过0.7 IoU的锚点
通常是用第二个条件来确定正样本,但是还是会用第一个条件,因为在极少数的情况下,第二个条件找不到正样本。如果一个锚点的IoU比率低于0.3,我们给非正面的锚点分配一个负标签。既不正面也不负面的锚点不会有助于训练目标函数。
根据Fast R-CNN中的损失函数,Faster R-CNN的损失函数类似定义为
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
\begin{aligned} L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right) &=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right) \\+\lambda & \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right) \end{aligned}
L({pi},{ti})+λ=Ncls1i∑Lcls(pi,pi∗)Nreg1i∑pi∗Lreg(ti,ti∗)
上述公式中,i表示anchors index,pi表示foreground softmax predict概率,
p
i
∗
p_i∗
pi∗代表对应的GT predict概率(即当第i个anchors与GT间IoU>0.7,认为该anchor是foreground,
p
i
∗
p_i∗
pi∗=1,反之IOU<0.3时,认为该anchors是background,
p
i
∗
p_i∗
pi∗=0);
至于那些0.3小于IOU<0.7的anchors则不参与训练,一般一张图片取256个anchors,一般bg和fg=1;1
t代表predict bounding box,
t
∗
t∗
t∗代表对应的foreground anchors对应的GT box。
在损失函数中,回归损失是利用Smooth L1函数
S
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
,
∣
x
∣
≤
1
∣
x
∣
−
0.5
,
o
t
h
e
r
w
i
s
e
Smooth_{L1}(x)=\begin{cases} 0.5x^2,|x| \leq 1 \\\ |x|-0.5,otherwise\end{cases}
SmoothL1(x)={0.5x2,∣x∣≤1 ∣x∣−0.5,otherwise
L r e g = S m o o t h L 1 ( t − t ∗ ) L_{reg}=Smooth_{L1}(t-t^{\ast}) Lreg=SmoothL1(t−t∗)
相比于L2损失函数,L1对离群点或异常值不敏感,可控制梯度的量级使训练更易收敛。
对于bounding box regression,我们有以下公式
t
x
=
(
x
−
x
a
)
/
w
a
,
t
y
=
(
y
−
y
a
)
/
h
a
,
t
w
=
log
(
w
/
w
a
)
,
t
h
=
log
(
h
/
h
a
)
t
x
∗
=
(
−
x
a
)
/
w
a
,
t
y
∗
=
(
y
∗
−
y
a
)
/
h
a
,
t
w
∗
=
log
(
w
∗
/
w
a
)
,
t
h
∗
=
log
(
h
∗
/
h
a
)
\begin{aligned} t_{\mathrm{x}}=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, & t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}}, \quad t_{\mathrm{w}}=\log \left(w / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right) \\ t_{\mathrm{x}}^{*}=\left(-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, & t_{\mathrm{y}}^{*}=\left(y^{*}-y_{\mathrm{a}}\right) / h_{\mathrm{a}}, \quad t_{\mathrm{w}}^{*}=\log \left(w^{*} / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}^{*}=\log \left(h^{*} / h_{\mathrm{a}}\right) \end{aligned}
tx=(x−xa)/wa,tx∗=(−xa)/wa,ty=(y−ya)/ha,tw=log(w/wa),th=log(h/ha)ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha)
其中x, y, w, h 对应两组框的中心点的坐标和它的宽和高。变量x,
x
a
,
x
∗
x_a,x∗
xa,x∗分别对应predicted box , anchor box 和 ground-truth box的中心点横坐标(同理x,y , w , h)我们可以这么认为bounding box regression就是把anchor box 拟合到ground-truth box。在我们的公式中,用于回归的特征是相同空间大小的在feature maps。
训练RPNs
论文中是利用SGD算法,并且以图片为中心,如果利用所有的锚点去计算损失函数,可能会计算冗余,所以一般来说会随机选择256个锚点,正样本和负样本的比例大约是1:1,也就是各为128个,如果不够,会填补,然后初始化是利用均值为0.01的高斯分布。
Faster R-CNN的训练
Faster R-CNN的训练方式有三种
- 使用交替优化算法训练
- 近似联合训练
- 联合训练
对于提取proposals的RPN,以及分类回归的Fast R-CNN,如何将这两个网络嵌入到同一个网络结构中,训练一个共享卷积层参数的多任务(Multi-task)网络模型。
这里先介绍交替训练的方法。
- 训练RPN网络,用ImageNet模型M0初始化,训练得到模型M1
- 利用第一步训练的RPN网络模型M1,生成Proposal P1
- 使用上一步生成的Proposal,训练Fast R-CNN网络,同样用ImageNet模型初始化,训练得到模型M2
- 训练RPN网络,用Fast R-CNN网络M2初始化,且固定卷积层参数,只微调RPN网络独有的层,训练得到模型M3
- 利用上一步训练的RPN网络模型M3,生成Proposal P2
- 训练Fast R-CNN网络,用RPN网络模型M3初始化,且卷积层参数和RPN参数不变,只微调Fast R-CNN独有的网络层,得到最终模型M4
由训练流程可知,第4步训练RPN网络和第6步训练Fast R-CNN网络实现了卷积层参数共享。总体上看,训练过程只循环了2次,但每一步训练(M1,M2,M3,M4)都迭代了多次。对于固定卷积层参数,只需将学习率(learning rate)设置为0即可。并且本论文也是用这种交替优化算法进行训练的。
实验细节
- 首先过滤掉超出图像边界的anchors
- 对每个标定的ground truth,与其重叠比例IoU最大的anchor记为正样本,这样可以保证每个ground truth至少对应一个正样本anchor
- 对每个anchors,如果其与某个ground truth的重叠比例IoU大于0.7,则记为正样本(目标);如果小于0.3,则记为负样本(背景)
- 再从已经得到的正负样本中随机选取256个anchors组成一个minibatch用于训练,而且正负样本的比例为1:1,;如果正样本不够,则补充一些负样本以满足256个anchors用于训练
总结
该论文提出了RPN来生成高效,准确的区域推荐。通过与下游检测网络共享卷积特征,区域推荐步骤几乎是零成本的。我们的方法使统一的,基于深度学习的目标检测系统能够以接近实时的帧率运行。学习到的RPN也提高了区域提议的质量,从而提高了整体的目标检测精度。















 2505
2505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











