






1、substr函数:提取指定位置的字符
根据身份证号计算年龄:
# 读入数据
id_number <- readxl::read_excel("D:/身份证.xlsx",sheet="Sheet1")
# 提取出生年份
year1 <- substr(id_number$身份证号,7,10)
# year2 <- substring(id_number$身份证号,7,10) 也是一样的

# 计算年龄
year <- format(Sys.time(),"%Y") #若是输入的日期,可以使用as.Date函数将输入的日期转变为日期型,在提取出生日期
age <- as.numeric(year)-as.numeric(year1)
age

2、str_extract函数:提取首个匹配模式的字符
# 因为身份证号有规律,可以通过指定字符串中的字符位置提取规定的值;若不知道字符串的位置,可通过stringr包中的str_extract函数提取,可使用正则表达式匹配。
str_extract(id_number$身份证号,"110101")

3、str_detect:检测字符是否存在某些指定模式
str_detect(id_number$身份证号,"110101")

配合sum函数可计算满足条件的字符串个数。
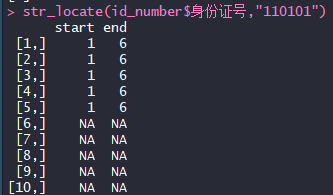
4、str_locate:返回首个匹配模式的字符的位置
str_locate(id_number$身份证号,"110101")
5、str_sub:提取指定位置的字符
#可与str_locate函数配合使用,这里达到与str_extract函数函数的效果
str_sub(id_number$身份证号,str_locate(id_number$身份证号,"110101"))















 2421
2421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









