




 本文详细介绍了MySQL中的存储过程,包括其定义、语法以及如何创建无参和有参的存储过程。针对业务需求,作者展示了如何使用存储过程处理员工调动信息,通过临时表优化大数据量下的插入操作。
本文详细介绍了MySQL中的存储过程,包括其定义、语法以及如何创建无参和有参的存储过程。针对业务需求,作者展示了如何使用存储过程处理员工调动信息,通过临时表优化大数据量下的插入操作。
目录
======= > 《MySQL和Navicat如何创建并调用存储过程》 <=======
数据库语句
CREATE TABLE employee_position (
ID INT AUTO_INCREMENT PRIMARY KEY,
employee_id INT,
position_time DATE COMMENT '任职时间',
position_location VARCHAR(100) COMMENT '任职地点'
);
CREATE TABLE employee_transfer (
ID INT AUTO_INCREMENT PRIMARY KEY,
employee_id INT COMMENT '员工id',
transfer_in_time DATE COMMENT '调动时间',
transfer_in_location VARCHAR(100) COMMENT '调入地点',
transfer_out_location VARCHAR(100) COMMENT '调出地点'
);
-- 插入员工任职表记录
INSERT INTO employee_position (employee_id, position_time, position_location)
VALUES
(1001, '2022-01-01', '上海'),
(1001, '2021-12-15', '北京'),
(1001, '2021-12-18', '北京'),
(1001, '2022-02-28', '广州'),
(1002, '2022-03-05', '深圳'),
(1002, '2022-04-10', '成都'),
(1002, '2022-03-06', '深圳'),
(1002, '2022-03-07', '深圳'),
(1003, '2022-05-20', '重庆'),
(1003, '2022-06-25', '重庆'),
(1003, '2022-07-08', '杭州'),
(1003, '2022-08-12', '武汉'),
(1003, '2022-09-30', '西安');
业务背景
记一次生产使用存储过程实现需求。
以下为需求:(就是记录每次调动的信息)
员工调动信息表是根据员工任职表产生数据的。
每新增一条员工任职表都会根据以下规则插入员工调动信息表
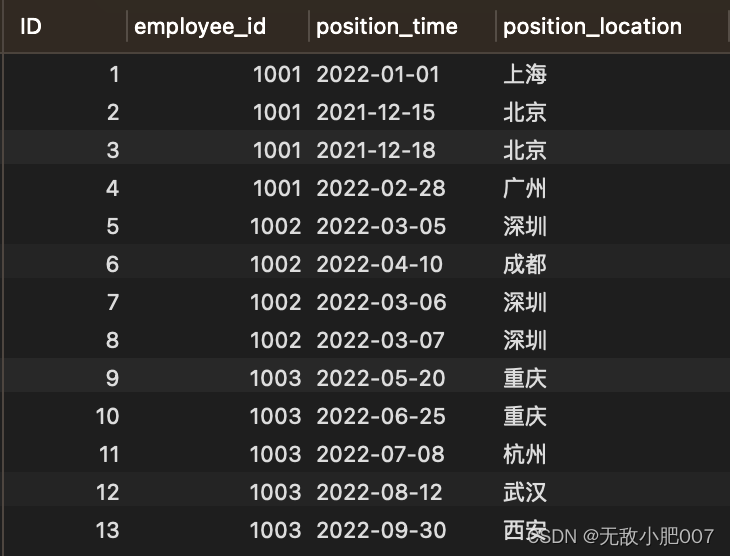
1、员工调动信息表不存在人员的调动信息时,员工任职表新增数据一条员工id为1001的任职信息(1001,2022-01-01,上海)后,
员工调动信息表插入(1001,2022-01-01,上海,上海)
2、员工调动信息表存在人员的调动信息时,员工任职表新增数据一条员工id为1001的任职信息(1001,2022-01-02,上海)后,需要判断最新的一条调动信息的调入地点,地点相同则忽略。
3、员工任职表新增数据一条员工id为1001的任职信息(1001,2022-01-03,北京)后,需要判断最新的一条调动信息的调入地点,地点不同则插入(1001,2022-01-03,北京,上海)。
4、需要遍历已存在的员工任职表去插入员工调动信息表。。。后续的数据使用定时任务或者插入时处理就行。
下图为员工任职表。
一、存储过程是什么?
存储过程(Stored Procedures)是一组在数据库中预先定义的SQL语句集合,经过编译并存储在数据库中,可以通过一个单独的调用来执行。存储过程通常由数据库管理系统提供支持,其好处和坏处如下:
1.1 利:
- 提高性能:存储在数据库中的存储过程可以减少网络通信开销,提高执行效率。
- 安全性:存储过程可以减少对表的直接访问,可以通过存储过程来进行访问权限的控制,提高数据的安全性。
- 代码重用:存储过程可以被多个应用程序调用,从而提高了代码的复用性和可维护性。
- 简化复杂的操作:存储过程能够封装复杂的业务逻辑,提供简单接口给应用程序调用。
- 减少数据传输:存储过程将计算和数据操作移至数据库,可以减少客户端和服务器之间的数据传输量。
1.2 弊:
- 学习成本高:需要学习存储过程的语法和使用方式,对于一些开发人员来说可能需要一定的时间来适应。
- 调试困难:存储过程中的错误可能较难调试,需要较高的技能和专业知识。
- 依赖数据库平台:存储过程的语法和特性可能在不同的数据库平台上有所不同,使得代码难以移植。
- 维护困难:存储过程的维护和版本控制可能比较困难,尤其在大型系统中。
二、语法
2.1 结构 — 类似创建一个方法。。。。
2.1.1 无参
DELIMITER //
CREATE PROCEDURE no_parameters_procedure_name()
BEGIN
-- 代码块
select '测试无参存储过程';
END //
DELIMITER ;
--调用
call no_parameters_procedure_name();
2.1.2 有参
DELIMITER //
CREATE DEFINER=`root`@`%` PROCEDURE `parameters_procedure_name`(IN name_in VARCHAR(255),OUT name_out VARCHAR(255))
BEGIN
SET name_in = CONCAT('-', name_in);
SET name_out = CONCAT('入参', name_in);
END //
DELIMITER ;
-- 调用
CALL parameters_procedure_name('刘德华', @output_value);
SELECT @output_value;
2.2 变量 — 类似创建变量。。。。
2.2.1 声明变量
declare var_name type(容量);
-- 例子
declare studentName VARCHAR(256);
2.3 流程控制 (IF语句和CASE语句差不多)
IF 语句
IF 条件 THEN
语句
ELSEIF 条件 THEN
语句
end IF
2.4 循环语句
CREATE DEFINER=`root`@`%` PROCEDURE `no_parameters_procedure_name`()
BEGIN
declare i int DEFAULT 0;
LOOP_LABLE:loop
set i = i + 1;
if i >=5 then
SELECT i;
leave LOOP_LABLE;
end if;
end loop;
END
2.5 游标 — 类似对象fori中的i 可以根据i拿到结果集i下标对应的数据
--声明
DECLARE cursor_name CURSOR FOR 查询的语句
--打开
OPEN cursor_name;
--取值
FETCH cursor_name into 新建变量对象字段的值,...
--关闭
CLOSE cursor_name
二、解决上述需求
基本常用到的语法已经提到。
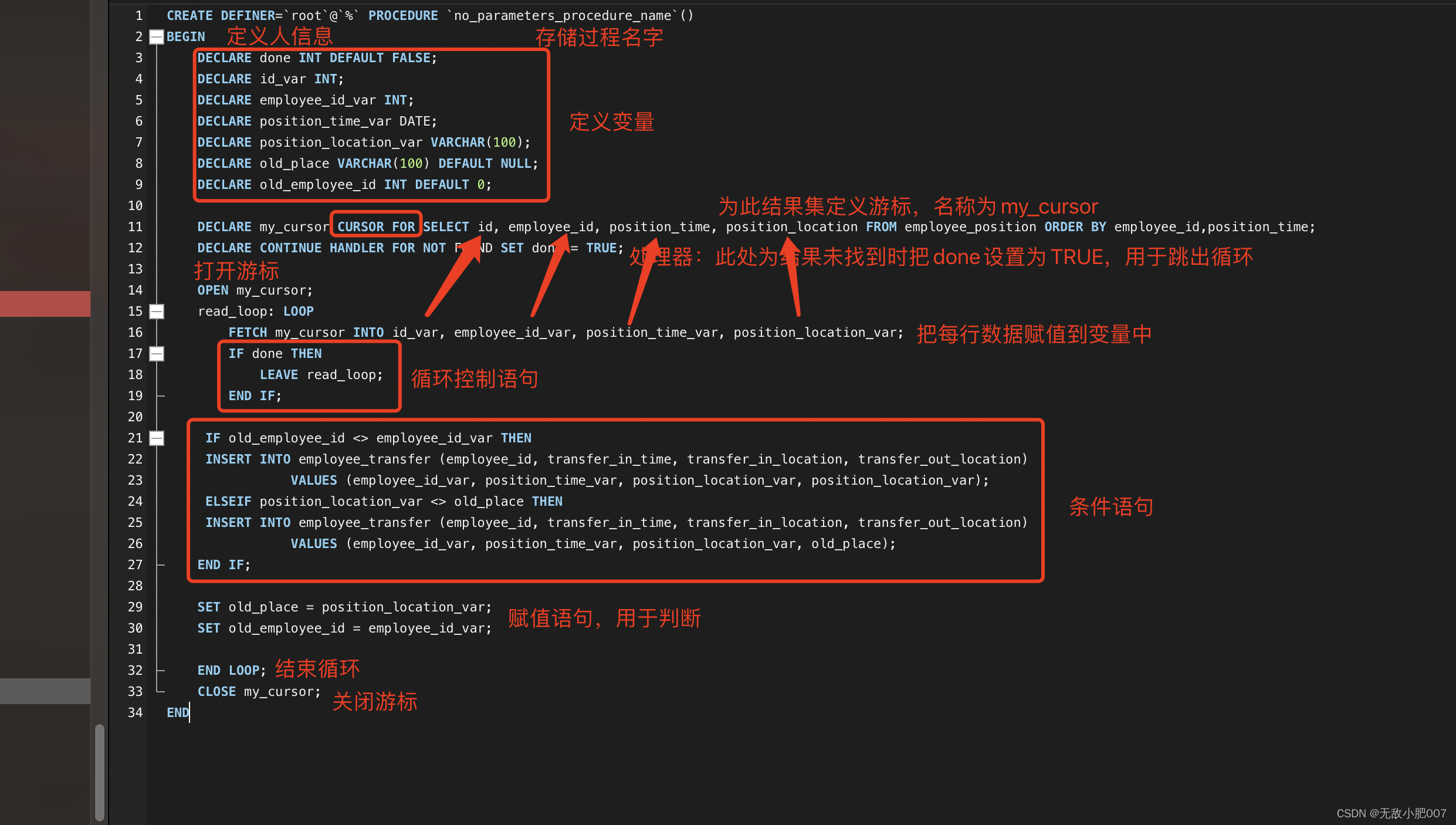
以下是具体sql:
DELIMITER $$
CREATE DEFINER=`root`@`%` PROCEDURE `sync_employee_transfer_data`()
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE id_var INT;
DECLARE employee_id_var INT;
DECLARE position_time_var DATE;
DECLARE position_location_var VARCHAR(100);
DECLARE old_place VARCHAR(100) DEFAULT NULL;
DECLARE old_employee_id INT DEFAULT 0;
DECLARE my_cursor CURSOR FOR SELECT id, employee_id, position_time, position_location FROM employee_position ORDER BY employee_id,position_time;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
OPEN my_cursor;
read_loop: LOOP
FETCH my_cursor INTO id_var, employee_id_var, position_time_var, position_location_var;
IF done THEN
LEAVE read_loop;
END IF;
IF old_employee_id <> employee_id_var THEN
INSERT INTO employee_transfer (employee_id, transfer_in_time, transfer_in_location, transfer_out_location)
VALUES (employee_id_var, position_time_var, position_location_var, position_location_var);
ELSEIF position_location_var <> old_place THEN
INSERT INTO employee_transfer (employee_id, transfer_in_time, transfer_in_location, transfer_out_location)
VALUES (employee_id_var, position_time_var, position_location_var, old_place);
END IF;
SET old_place = position_location_var;
SET old_employee_id = employee_id_var;
END LOOP;
CLOSE my_cursor;
END$$
DELIMITER ;
-- 调用
CALL sync_employee_transfer_data();
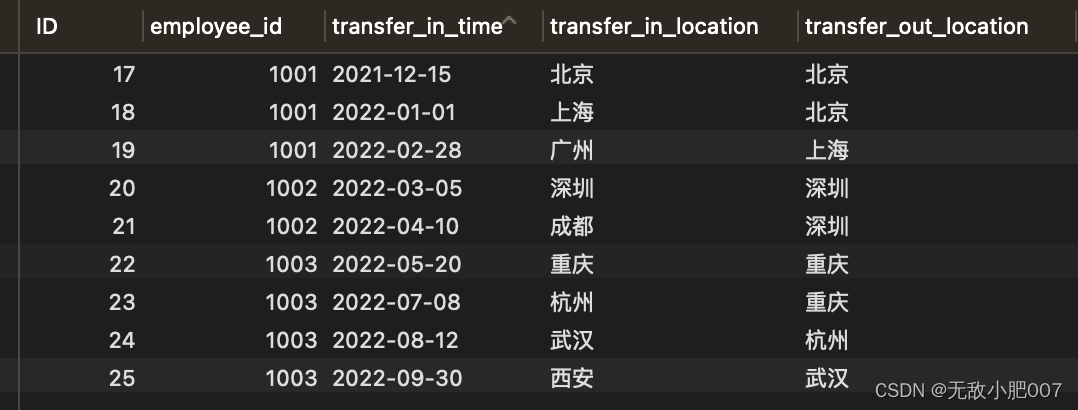
刚发布完,才意识到 逐条插入对数据库极不友好。
故引入临时表和批量插入。推荐大家使用这种,对数据量大的情况很友好。
sql如下:
DELIMITER $$
CREATE DEFINER=`root`@`%` PROCEDURE `sync_employee_transfer_data`()
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE id_var INT;
DECLARE employee_id_var INT;
DECLARE position_time_var DATE;
DECLARE position_location_var VARCHAR(100);
DECLARE old_place VARCHAR(100) DEFAULT NULL;
DECLARE old_employee_id INT DEFAULT 0;
DECLARE my_cursor CURSOR FOR SELECT id, employee_id, position_time, position_location FROM employee_position ORDER BY employee_id,position_time;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- 新建临时表
CREATE TEMPORARY TABLE employee_transfer_temp (
ID INT ,
employee_id INT,
transfer_in_time DATE,
transfer_in_location VARCHAR(100),
transfer_out_location VARCHAR(100)
);
OPEN my_cursor;
read_loop: LOOP
FETCH my_cursor INTO id_var, employee_id_var, position_time_var, position_location_var;
IF done THEN
LEAVE read_loop;
END IF;
IF old_employee_id <> employee_id_var THEN
INSERT INTO employee_transfer_temp (employee_id, transfer_in_time, transfer_in_location, transfer_out_location)
VALUES (employee_id_var, position_time_var, position_location_var, position_location_var);
ELSEIF position_location_var <> old_place THEN
INSERT INTO employee_transfer_temp (employee_id, transfer_in_time, transfer_in_location, transfer_out_location)
VALUES (employee_id_var, position_time_var, position_location_var, old_place);
END IF;
SET old_place = position_location_var;
SET old_employee_id = employee_id_var;
END LOOP;
CLOSE my_cursor;
-- 批量插入
INSERT INTO employee_transfer SELECT * FROM employee_transfer_temp;
-- 删除临时表
DROP TEMPORARY TABLE IF EXISTS employee_transfer_temp;
END$$
DELIMITER ;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









