






 本文介绍了参与Datawhale OD项目时进行目标检测的模型训练过程,包括超参数设定、主函数编写、损失函数和优化器的设计。此外,详细阐述了后处理的两个关键步骤:目标框信息解码和NMS非极大值抑制算法。最后,讨论了评估目标检测性能的MAP指标,包括一级、二级和三级指标。
本文介绍了参与Datawhale OD项目时进行目标检测的模型训练过程,包括超参数设定、主函数编写、损失函数和优化器的设计。此外,详细阐述了后处理的两个关键步骤:目标框信息解码和NMS非极大值抑制算法。最后,讨论了评估目标检测性能的MAP指标,包括一级、二级和三级指标。
前言
一时兴起和好朋友一起组队参加了Datawhale的OD小项目,索性也算是第一次做CV的项目了,顺便练练pytorch和神经网络的内容。这是第四次任务的博客。
一、模型训练
目标检测网络的训练流程
首先设定超参数
import time import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
from model import tiny_detector, MultiBoxLoss
from datasets import PascalVOCDataset
from utils import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cudnn.benchmark = True
# Data parameters
data_folder = '../../../dataset/VOCdevkit' # data files root path
keep_difficult = True # use objects considered difficult to detect?
n_classes = len(label_map) # number of different types of objects
# Learning parameters
total_epochs = 230 # number of epochs to train
batch_size = 32 # batch size
workers = 4 # number of workers for loading data in the DataLoader
print_freq = 100 # print training status every __ batches
lr = 1e-3 # learning rate
decay_lr_at = [150, 190] # decay learning rate after these many epochs
decay_lr_to = 0.1 # decay learning rate to this fraction of the existing learning rate
momentum = 0.9 # momentum
weight_decay = 5e-4 # weight decay
然后编写主函数,主函数主要包含dataloader的导入,网络的导入,损失函数的导入,优化器的定义和数据遍历反向传播。
def main():
"""
Training.
"""
# 初始化模型和优化器
model = tiny_detector(n_classes=n_classes)
criterion = MultiBoxLoss(priors_cxcy=model.priors_cxcy)
optimizer = torch.optim.SGD(params=model.parameters(),
lr=lr,
momentum=momentum,
weight_decay=weight_decay)
# 使用GPU
model = model.to(device)
criterion = criterion.to(device)
# 导入dataloader
train_dataset = PascalVOCDataset(data_folder,
split='train',
keep_difficult=keep_difficult)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=train_dataset.collate_fn,
num_workers=workers,
pin_memory=True)
# 每一轮迭代
for epoch in range(total_epochs):
# Decay learning rate at particular epochs
if epoch in decay_lr_at:
adjust_learning_rate(optimizer, decay_lr_to)
# 训练
train(train_loader=train_loader,
model=model,
criterion=criterion,
optimizer=optimizer,
epoch=epoch)
# 保存模型
save_checkpoint(epoch, model, optimizer)
其中,模型训练的函数如下
def train(train_loader, model, criterion, optimizer, epoch):
"""
One epoch's training.
:param train_loader: DataLoader for training data
:param model: model
:param criterion: MultiBox loss
:param optimizer: optimizer
:param epoch: epoch number
"""
model.train() # training mode enables dropout
batch_time = AverageMeter() # forward prop. + back prop. time
data_time = AverageMeter() # data loading time
losses = AverageMeter() # loss
start = time.time()
# Batches
for i, (images, boxes, labels, _) in enumerate(train_loader):
data_time.update(time.time() - start)
# Move to default device
images = images.to(device) # (batch_size (N), 3, 224, 224)
boxes = [b.to(device) for b in boxes]
labels = [l.to(device) for l in labels]
# Forward prop.
predicted_locs, predicted_scores = model(images) # (N, 441, 4), (N, 441, n_classes)
# Loss
loss = criterion(predicted_locs, predicted_scores, boxes, labels) # scalar
# Backward prop.
optimizer.zero_grad()
loss.backward()
# Update model
optimizer.step()
losses.update(loss.item(), images.size(0))
batch_time.update(time.time() - start)
start = time.time()
# Print status
if i % print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Batch Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data Time {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'.format(epoch,
i,
len(train_loader),
batch_time=batch_time,
data_time=data_time,
loss=losses))
del predicted_locs, predicted_scores, images, boxes, labels # free some memory since their histories may be stored
二、后处理
1. 目标框信息解码
之前我们的提到过,模型不是直接预测的目标框信息,而是预测的基于anchor的偏移,且经过了编码。因此后处理的第一步,就是对模型的回归头的输出进行解码,拿到真正意义上的目标框的预测结果。
2. NMS非极大值抑制
由于我们预设了大量的先验框,因此预测时在目标周围会形成大量高度重合的检测框,而我们目标检测的结果只希望保留一个足够准确的预测框,所以就需要使用某些算法对检测框去重。这个去重算法叫做NMS。
算法步骤如下
-
按照类别分组,依次遍历每个类别。
-
当前类别按分类置信度排序,并且设置一个最低置信度阈值如0.05,低于这个阈值的目标框直接舍弃。
-
当前概率最高的框作为候选框,其它所有与候选框的IOU高于一个阈值(自己设定,如0.5)的框认为需要被抑制,从剩余框数组中删除。
-
然后在剩余的框里寻找概率第二大的框,其它所有与第二大的框的IOU高于设定阈值的框被抑制。
-
依次类推重复这个过程,直至遍历完所有剩余框,所有没被抑制的框即为最终检测框。
来看看代码
def detect_objects(self, predicted_locs, predicted_scores, min_score, max_overlap, top_k):
"""
Decipher the 441 locations and class scores (output of the tiny_detector) to detect objects.
For each class, perform Non-Maximum Suppression (NMS) on boxes that are above a minimum threshold.
:param predicted_locs: predicted locations/boxes w.r.t the 441 prior boxes, a tensor of dimensions (N, 441, 4)
:param predicted_scores: class scores for each of the encoded locations/boxes, a tensor of dimensions (N, 441, n_classes)
:param min_score: minimum threshold for a box to be considered a match for a certain class
:param max_overlap: maximum overlap two boxes can have so that the one with the lower score is not suppressed via NMS
:param top_k: if there are a lot of resulting detection across all classes, keep only the top 'k'
:return: detections (boxes, labels, and scores), lists of length batch_size
"""
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
predicted_scores = F.softmax(predicted_scores, dim=2) # (N, 441, n_classes)
# Lists to store final predicted boxes, labels, and scores for all images in batch
all_images_boxes = list()
all_images_labels = list()
all_images_scores = list()
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
for i in range(batch_size):
# Decode object coordinates from the form we regressed predicted boxes to
decoded_locs = cxcy_to_xy(
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy)) # (441, 4), these are fractional pt. coordinates
# Lists to store boxes and scores for this image
image_boxes = list()
image_labels = list()
image_scores = list()
max_scores, best_label = predicted_scores[i].max(dim=1) # (441)
# Check for each class
for c in range(1, self.n_classes):
# Keep only predicted boxes and scores where scores for this class are above the minimum score
class_scores = predicted_scores[i][:, c] # (441)
score_above_min_score = class_scores > min_score # torch.uint8 (byte) tensor, for indexing
n_above_min_score = score_above_min_score.sum().item()
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score] # (n_qualified), n_min_score <= 441
class_decoded_locs = decoded_locs[score_above_min_score] # (n_qualified, 4)
# Sort predicted boxes and scores by scores
class_scores, sort_ind = class_scores.sort(dim=0, descending=True) # (n_qualified), (n_min_score)
class_decoded_locs = class_decoded_locs[sort_ind] # (n_min_score, 4)
# Find the overlap between predicted boxes
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs) # (n_qualified, n_min_score)
# Non-Maximum Suppression (NMS)
# A torch.uint8 (byte) tensor to keep track of which predicted boxes to suppress
# 1 implies suppress, 0 implies don't suppress
suppress = torch.zeros((n_above_min_score), dtype=torch.uint8).to(device) # (n_qualified)
# Consider each box in order of decreasing scores
for box in range(class_decoded_locs.size(0)):
# If this box is already marked for suppression
if suppress[box] == 1:
continue
# Suppress boxes whose overlaps (with current box) are greater than maximum overlap
# Find such boxes and update suppress indices
suppress = torch.max(suppress, (overlap[box] > max_overlap).to(torch.uint8))
# The max operation retains previously suppressed boxes, like an 'OR' operation
# Don't suppress this box, even though it has an overlap of 1 with itself
suppress[box] = 0
# Store only unsuppressed boxes for this class
image_boxes.append(class_decoded_locs[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
# If no object in any class is found, store a placeholder for 'background'
if len(image_boxes) == 0:
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.LongTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
# Concatenate into single tensors
image_boxes = torch.cat(image_boxes, dim=0) # (n_objects, 4)
image_labels = torch.cat(image_labels, dim=0) # (n_objects)
image_scores = torch.cat(image_scores, dim=0) # (n_objects)
n_objects = image_scores.size(0)
# Keep only the top k objects
if n_objects > top_k:
image_scores, sort_ind = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_ind][:top_k] # (top_k, 4)
image_labels = image_labels[sort_ind][:top_k] # (top_k)
# Append to lists that store predicted boxes and scores for all images
all_images_boxes.append(image_boxes)
all_images_labels.append(image_labels)
all_images_scores.append(image_scores)
return all_images_boxes, all_images_labels, all_images_scores # lists of length batch_size
当模型已经训练完成后,下面我们来看下如何对单张图片进行推理,得到目标检测结果。
首先我们需要导入必要的python包,然后加载训练好的模型权重。
随后我们需要定义预处理函数。为了达到最好的预测效果,测试环节的预处理方案需要和训练时保持一致,仅去除掉数据增强相关的变换即可。
因此,这里我们需要进行的预处理为:
- 将图片缩放为 224 * 224 的大小
- 转换为 Tensor 并除 255
- 进行减均值除方差的归一化
贴一下代码:
# Set detect transforms (It's important to be consistent with training)
resize = transforms.Resize((224, 224))
to_tensor = transforms.ToTensor()
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
接着我们就来进行推理,过程很简单,核心流程可以概括为:
- 读取一张图片
- 预处理
- 模型预测
- 对模型预测进行后处理
# Transform the image
image = normalize(to_tensor(resize(original_image)))
# Move to default device
image = image.to(device)
# Forward prop.
predicted_locs, predicted_scores = model(image.unsqueeze(0))
# Post process, get the final detect objects from our tiny detector output
det_boxes, det_labels, det_scores = model.detect_objects(predicted_locs, predicted_scores, min_score=min_score, max_overlap=max_overlap, top_k=top_k)
三、MAP指标
1. 一级指标
1)真实值是positive,模型认为是positive的数量(True Positive=TP)
2)真实值是positive,模型认为是negative的数量(False Negative = FN):这就是统计学上的第二类错误(Type II Error)
3)真实值是negative,模型认为是positive的数量(False Positive = FP):这就是统计学上的第一类错误(Type I Error)
4)真实值是negative,模型认为是negative的数量(True Negative = TN)
2. 二级指标
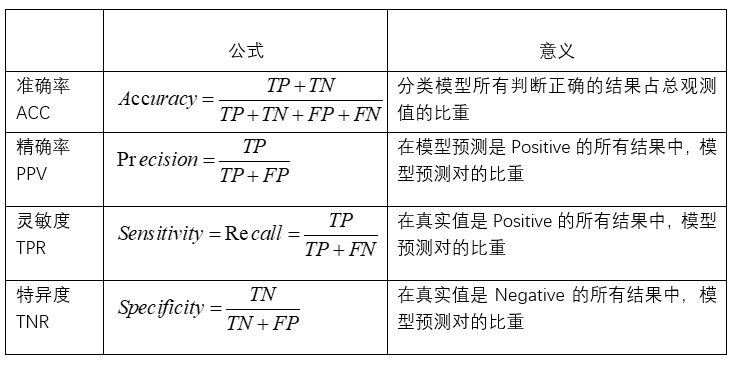
1)准确率(Accuracy)-----针对整个模型
2)精确率(Precision)
3)灵敏度(Sensitivity):就是召回率(Recall)
4)特异度(Specificity)
3. 三级指标
F 1 = 2 P R P + R F1 = \frac{2PR}{P+R} F1=P+R2PR
在目标检测场景如何计算AP呢,这里需要引出P-R曲线,即以precision和recall作为纵、横轴坐标的二维曲线。通过选取不同阈值时对应的精度和召回率画出,如下图所示:
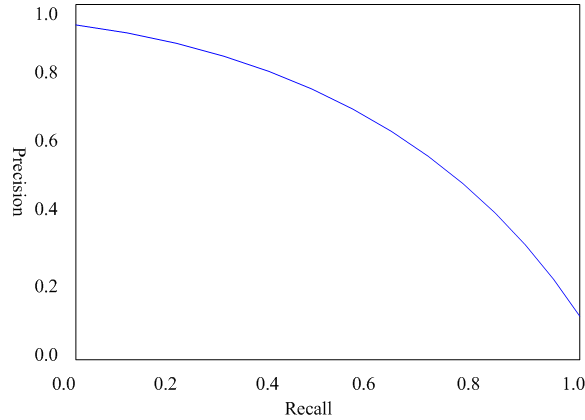
P-R曲线的总体趋势是,精度越高,召回越低,当召回到达1时,对应概率分数最低的正样本,这个时候正样本数量除以所有大于等于该阈值的样本数量就是最低的精度值。 另外,P-R曲线围起来的面积就是AP值,通常来说一个越好的分类器,AP值越高。
总结:在目标检测中,每一类都可以根据recall和precision绘制P-R曲线,AP就是该曲线下的面积,mAP就是所有类的AP的平均值。(这里说的是VOC数据集的mAP指标的计算方法,COCO数据集的计算方法略有差异)















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









