









Bert 中文模型下载
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
Bert 安装
pip install bert-serving-client
pip install bert-serving-server
Bert 使用
- 服务端启动
bert-serving-start -model_dir [/tmp/chinese_L-12_H-768_A-12] -max_seq_len 100 -num_worker 4-
"[ ]"内为自己的模型解压地址,命令中不包含"[ ]"。 -
-max_seq_len- 表示所处理的一个句子的最大长度,如果原句超过设定值,从设定长度的右侧开始删去。处理长度越长时间越慢,根据处理语料的实际情况设置
- 默认长度为25
- 该参数设为
NONE后,动态处理序列长度,但该模型中最长序列max_seq_length为512,也就是512长度后的文本处理不到,长度小于512的文本根据实际长度处理。长度越短,训练成本越低
-
-num_worker- 加载数据的线程数目
- 默认值为1
-
运行成功:

-
- 客户端
from bert_serving.client import BertClient bc = BertClient() bc.encode(['我爱中国','中国加油'])-
运行结果:

-
得到的词向量的shape为(1,768)
-
若将多个句向量转化为列表,可用
.tolist(),.append(),注意维度变化,转化为list后,会多出一个维度,可用.tolist[0] -
处理较多句子时,服务器端可以看到运行进展,如下图
"#"后的数值,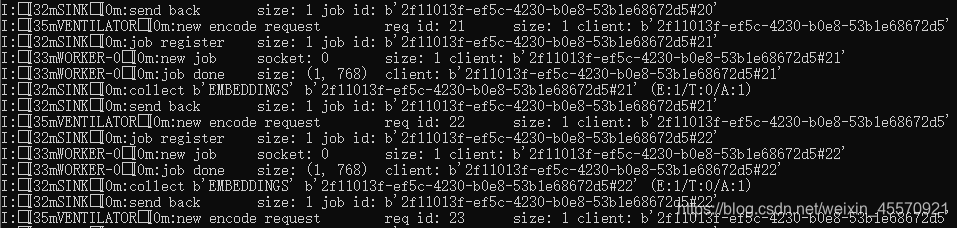
-
或者用下面的代码观察进度(个人用tqdm进度条库总会出错,不稳定)
for i in range(len(X)): #不换行,且从该行开头打印 print(f"\r增强进度:{(float(i/len(X))): 8.2%} {i} / {len(X)}",end=' ')
-
注意
-
tensorflow安装版本
- tensorflow2.1.0版本运行结果:
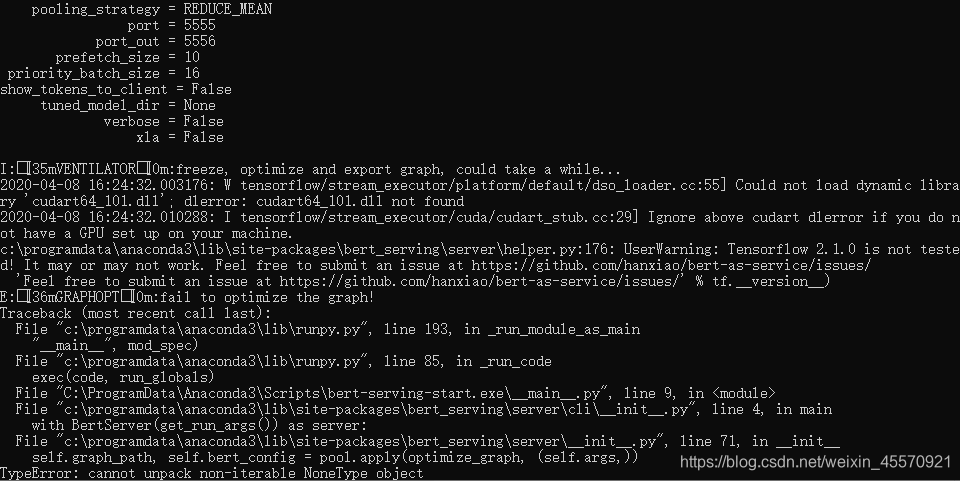
- 需要安装较低版本的tensorflow
- tensorflow1.14.0版本安装:
pip install --index-url https://mirrors.aliyun.com/pypi/simple/ tensorflow==1.14.0 - tensorflow版本查看:
import tensorflow as tf tf.__version__
- tensorflow2.1.0版本运行结果:
参考链接:https://bert-as-service.readthedocs.io/en/latest/source/server.html
更新:TensorFlow2.0版本也可以运行bert了














 3808
3808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









