



一、下载原画视频
使用的应用软件:
Grabcube
下载视频方式:
打开B站视频,复制网址
粘贴到软件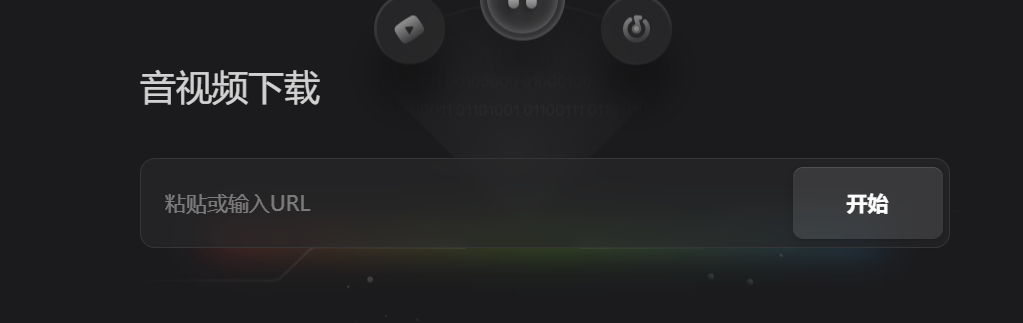
选择文件夹保存即可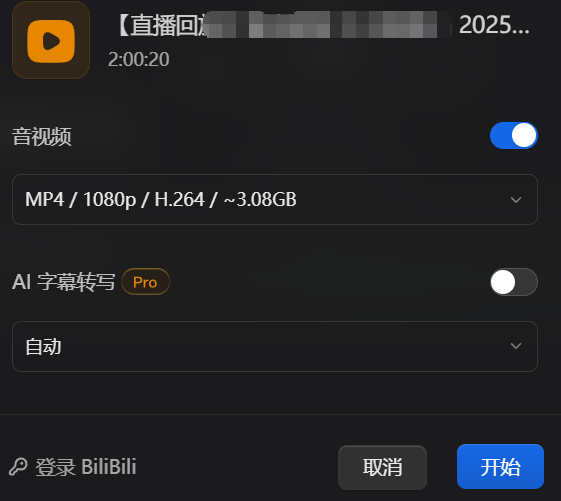
二、获取弹幕及弹幕时间分布信息
PS:B站有一系列工具可以使用,如https://bibz.me/可快速获取视频弹幕及时间等信息,但尝试后发现对于分P视频无法很好适用,即使切换链接的不同P后也仅显示P1视频中的弹幕,于是换以下方式获取弹幕相关信息。
(上文链接中方式仅-适用于非分P视频,后续可导出为JSON或CSV格式文件进行进一步处理)
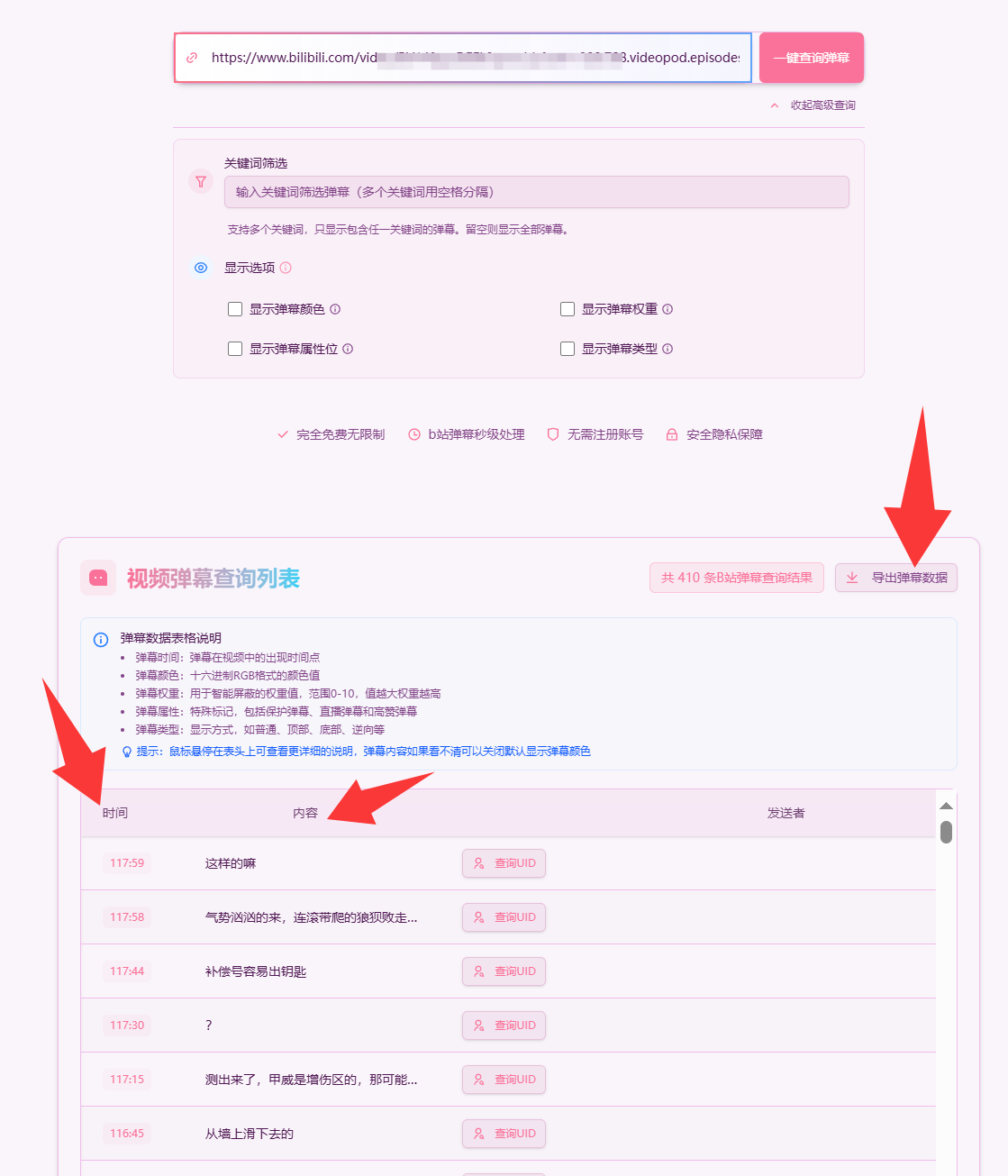
我们选择的获取分P视频的弹幕方式:
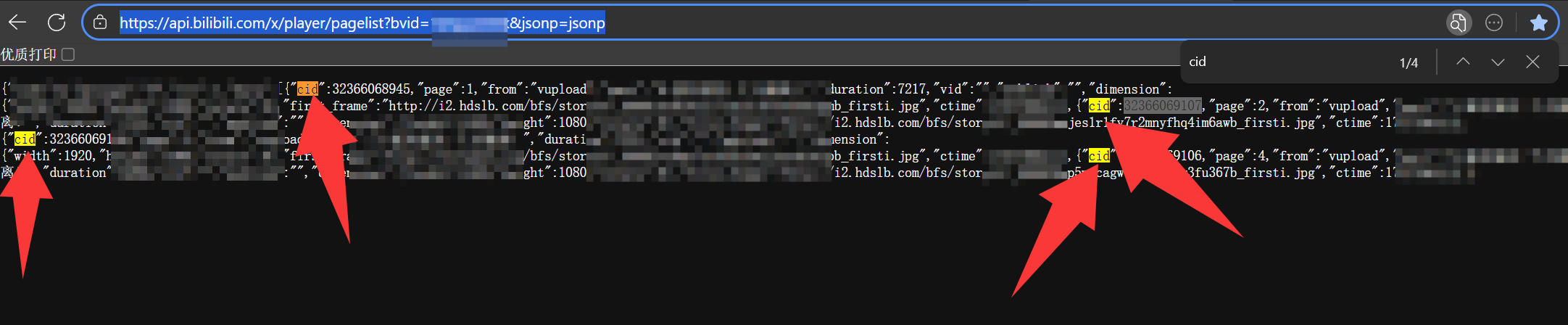
进入https://api.bilibili.com/x/player/pagelist?bvid={666}&jsonp=jsonp页面
其中{666}这五个符号用视频的bv号替换(bv号可在原B站视频的网址上看出来)
获取其中“CID”数字,这个数字每个分P都会有一个,以此来强制区分不同分P页的视频
获取后进入https://comment.bilibili.com/{888}.xml网页
其中{888}这五个符号用视频的bv号替换
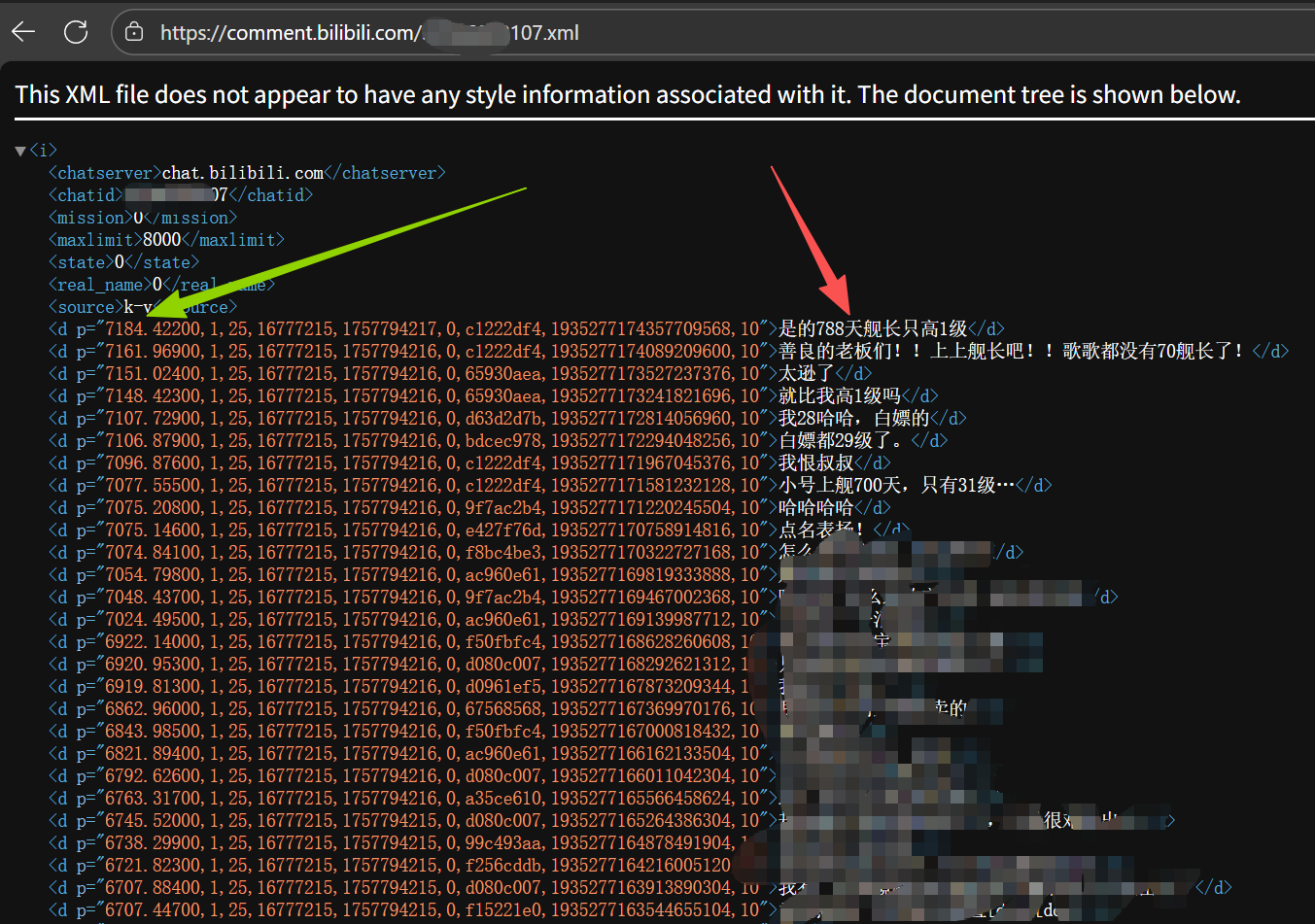
获取全部弹幕,其中,红色箭头指向弹幕,绿色箭头指向的是第一个数字,如7184.42200,是指的本分P视频中该弹幕出现的时刻
右键该页面即可选择另存为xml文件
至此,分P弹幕视频页的全体弹幕获取完毕
三、分析弹幕密度和热点出现情况
使用python脚本
import xml.etree.ElementTree as ET
import numpy as np
import matplotlib.pyplot as plt
import os
import tkinter as tk
from tkinter import filedialog
# 设置中文字体,确保图表中文正常显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
def format_seconds(seconds):
"""将秒数格式化为 HH:MM:SS 格式"""
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
seconds = int(seconds % 60)
if hours > 0:
return f"{hours}:{minutes:02d}:{seconds:02d}"
else:
return f"{minutes:02d}:{seconds:02d}"
def analyze_danmaku_xml(xml_file):
"""分析XML格式的弹幕数据并生成可视化图表"""
try:
# 解析XML文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 提取所有弹幕的时间信息(假设时间在'dm'标签的'p'属性中,且是第一个值)
# B站XML弹幕格式通常为:<d p="1234.567,1,25,16777215,1620000000,0,abcd1234,567890123">弹幕内容</d>
# 其中第一个数值就是以秒为单位的时间
times = []
for danmaku in root.iter('d'): # 查找所有d标签
p_attr = danmaku.get('p')
if p_attr:
# 分割p属性,第一个值为时间(秒)
parts = p_attr.split(',')
if parts:
try:
# 转换为浮点数(秒)
time_seconds = float(parts[0])
times.append(time_seconds)
except ValueError:
continue
if not times:
print("未找到有效的弹幕时间数据")
return
# 转换为numpy数组便于处理
times_array = np.array(times)
# 获取视频总时长(最大时间+1分钟缓冲)
max_time = times_array.max()
video_duration = max_time + 60 # 加60秒作为缓冲
# 设置时间间隔(秒),控制图表精度
interval = 10 # 每10秒一个区间
time_bins = np.arange(0, video_duration, interval)
# 计算每个时间区间的弹幕数量
danmaku_counts, _ = np.histogram(times_array, bins=time_bins)
# 计算弹幕峰值
peak_count = np.max(danmaku_counts)
peak_time_idx = np.argmax(danmaku_counts)
peak_time = time_bins[peak_time_idx]
# 创建图表
fig, ax = plt.subplots(figsize=(15, 8))
# 绘制弹幕密度曲线
ax.plot(time_bins[:-1], danmaku_counts, color='b', alpha=0.7, label='弹幕密度')
# 填充曲线下方区域
ax.fill_between(time_bins[:-1], danmaku_counts, color='b', alpha=0.3)
# 标记峰值点
ax.annotate(
f'峰值: {peak_count}条/{interval}秒\n时间: {format_seconds(peak_time)}',
xy=(peak_time, peak_count),
xytext=(peak_time + 100, peak_count * 0.8),
arrowprops=dict(facecolor='red', shrink=0.05),
fontsize=12,
bbox=dict(boxstyle="round,pad=0.3", edgecolor="black", facecolor="white")
)
# 设置图表属性
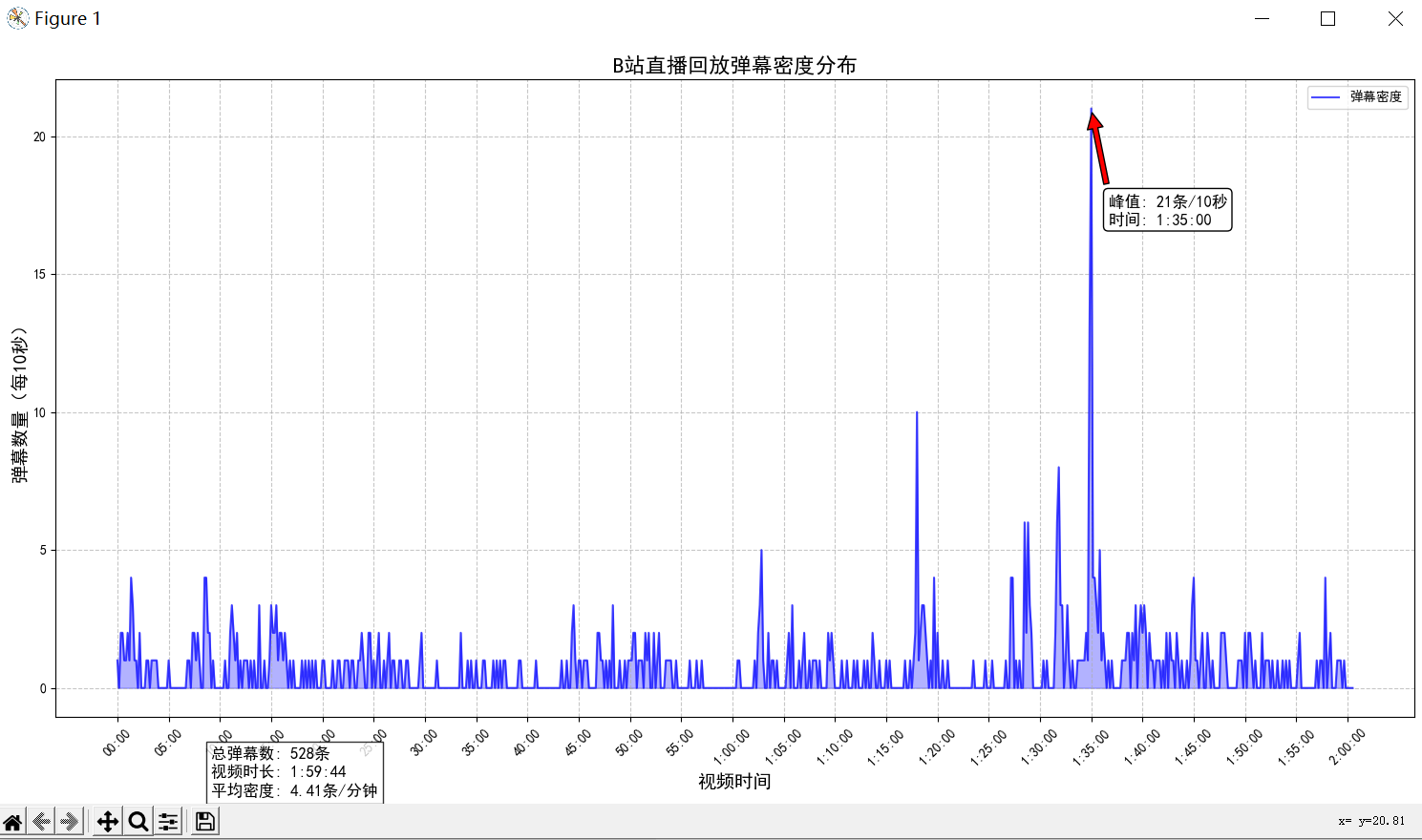
ax.set_title('B站直播回放弹幕密度分布', fontsize=16)
ax.set_xlabel('视频时间', fontsize=14)
ax.set_ylabel(f'弹幕数量(每{interval}秒)', fontsize=14)
# 设置x轴刻度格式(每5分钟一个刻度)
max_tick = int(video_duration // 300) * 300
ax.set_xticks(np.arange(0, max_tick + 300, 300))
ax.set_xticklabels([format_seconds(t) for t in np.arange(0, max_tick + 300, 300)], rotation=45)
ax.grid(True, linestyle='--', alpha=0.7)
ax.legend()
# 添加统计信息
total_danmaku = len(times_array)
avg_density = total_danmaku / (max_time / 60) # 每分钟平均弹幕数
stats_text = f"总弹幕数: {total_danmaku}条\n视频时长: {format_seconds(max_time)}\n平均密度: {avg_density:.2f}条/分钟"
plt.figtext(0.15, 0.01, stats_text, fontsize=12, bbox=dict(facecolor='white', alpha=0.8))
plt.tight_layout()
# 保存图表
output_file = os.path.splitext(xml_file)[0] + '_弹幕分析.png'
plt.savefig(output_file, dpi=300, bbox_inches='tight')
print(f"分析完成,图表已保存至: {output_file}")
# 显示图表
plt.show()
except Exception as e:
print(f"分析过程出错: {str(e)}")
def select_file_and_analyze():
"""选择文件并进行分析"""
root = tk.Tk()
root.withdraw() # 隐藏主窗口
print("请选择B站直播回放的弹幕XML文件...")
xml_file = filedialog.askopenfilename(
title="选择弹幕XML文件",
filetypes=[("XML文件", "*.xml"), ("所有文件", "*.*")]
)
if xml_file:
print(f"已选择文件: {xml_file}")
analyze_danmaku_xml(xml_file)
else:
print("未选择任何文件")
if __name__ == "__main__":
print("B站直播弹幕XML分析工具")
print("=" * 30)
select_file_and_analyze()
使用方法:
直接运行代码,会弹出文件选择窗口
选择你的弹幕 XML 文件
程序会自动分析并生成图表,同时保存为同名 PNG 文件
脚本特点:
专门处理 B 站 XML 格式弹幕文件,支持以秒为单位的时间格式
自动识别弹幕时间(通常在d标签的p属性中)
生成弹幕密度分布曲线,清晰展示弹幕高峰时段
标记弹幕峰值点及对应时间
计算总弹幕数、视频时长和平均弹幕密度等统计信息


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









