




 博客围绕MySQL面试相关问题展开,包含联赛信息统计、寻找面试候选人、没有广告的剧集、寻找正收入客户以及每天最大交易等题目,涉及足球比赛积分、连续数据处理、行转列等内容。
博客围绕MySQL面试相关问题展开,包含联赛信息统计、寻找面试候选人、没有广告的剧集、寻找正收入客户以及每天最大交易等题目,涉及足球比赛积分、连续数据处理、行转列等内容。
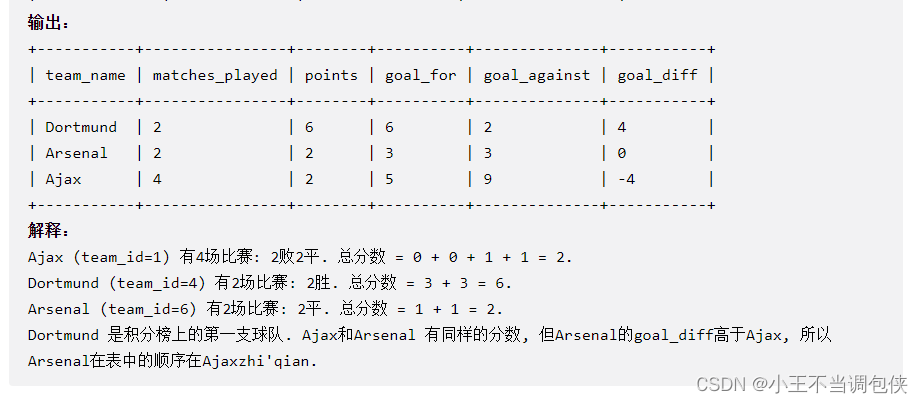
1841. 联赛信息统计[足球比赛积分问题]


# Write your MySQL query statement below
select team_name, count(*) matches_played ,sum(yingle*3+pingle) points,
sum(goal) goal_for ,sum(dis_goal) goal_against,
sum(goal-dis_goal) goal_diff
from(
select home_team_id id,
#算积分
sum(if(home_team_goals > away_team_goals,1,0)) yingle,
sum(if(home_team_goals < away_team_goals,1,0)) shule,
sum(if(home_team_goals = away_team_goals,1,0)) pingle,
#算进球失球数
sum(home_team_goals) goal,
sum(away_team_goals) dis_goal
from matches group by home_team_id ,away_team_id
union all
select away_team_id id,
sum(if(home_team_goals < away_team_goals,1,0)) yingle,
sum(if(home_team_goals > away_team_goals,1,0)) shule,
sum(if(home_team_goals = away_team_goals,1,0)) pingle,
sum(away_team_goals) goal,
sum(home_team_goals) dis_goal
from matches group by away_team_id , home_team_id)new_table,teams T
where T.team_id = new_table.id
group by id
order by points desc, goal_diff desc ,team_name
1811. 寻找面试候选人(求连续+行转列)
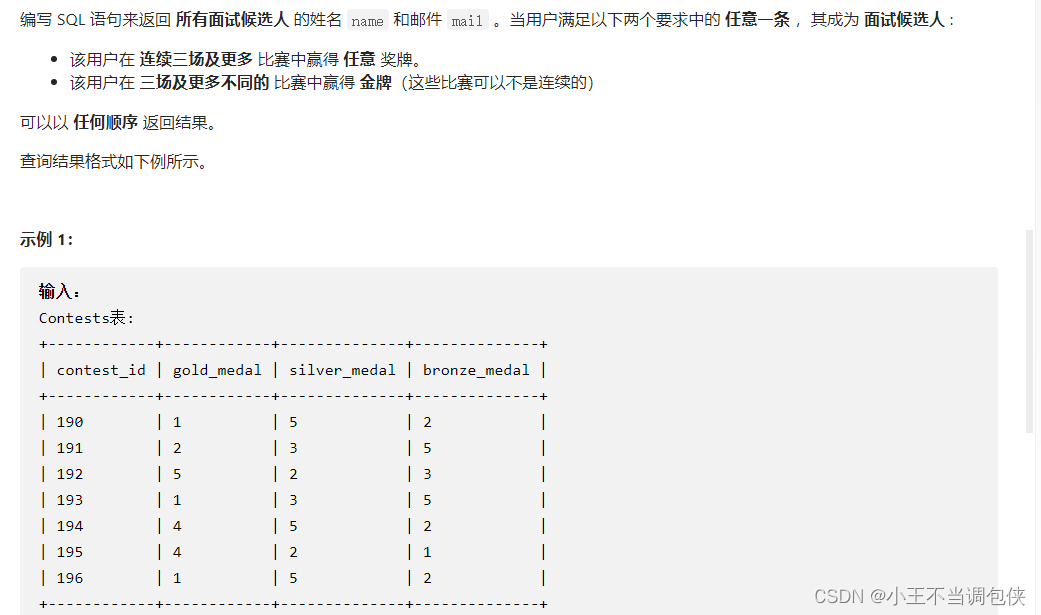

# Write your MySQL query statement below
with new_table as(
select contest_id ,gold_medal id from Contests
union all
select contest_id ,silver_medal from Contests
union all
select contest_id ,bronze_medal from Contests
)
select name,mail
from Users
where user_id in(
select id
from(
select *,
contest_id - rank()over(partition by id order by contest_id) paiming
from new_table)new_new_table
group by id ,paiming
having count(*) > 2
union
select gold_medal
from Contests
group by gold_medal
having count(*)> 2
)
1809. 没有广告的剧集


# Write your MySQL query statement below
select
distinct session_id
from
Playback p left join Ads a
on
p.customer_id = a.customer_id and a.timestamp between p.start_time and p.end_time
where
ad_id is null;
1821. 寻找今年具有正收入的客户

select customer_id
from Customers
where year = '2021' and revenue >0
1831. 每天的最大交易
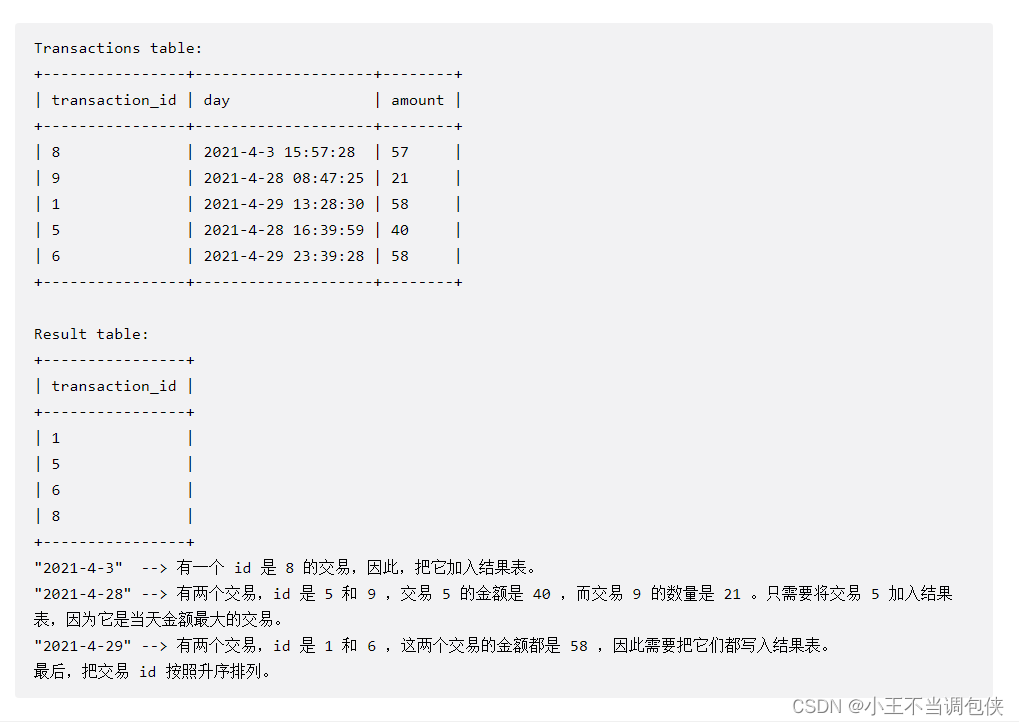
# Write your MySQL query statement below
select transaction_id
from (
select transaction_id,
rank()over(partition by date_format(day,'%Y-%m-%d') order by amount desc) paiming
from Transactions)new_table
where paiming = 1
order by transaction_id asc





















 到【灌水乐园】发言
到【灌水乐园】发言







