







Linear Regression
简介
线性回归是一种回归学习方法,一般用于处理连续性变量,算是机器学习的入门算法。虽然线性模型的形式很简单,但是线性模型的思想是很重要的,许多非线性模型都是在线性模型的基础上通过引入高维映射而得。
- 优点
- 建模速度快,不需要复杂计算
- 可解释性好
- 缺点
- 不适用与非线性数据
- 可能出现过拟合
基本原理
- 基本形式
给定数据集 D = { ( x 1 , y 1 ) , . . . , ( x m , y m } D=\{(x_1,y_1), ..., (x_m, y_m\} D={(x1,y1),...,(xm,ym},其中 x i = ( x i 1 , . . . , x i d ) x_i=(x_{i1}, ..., x_{id}) xi=(xi1,...,xid),线性回归模型试图学习到 y ^ = w T x + b \hat y=w^Tx+b y^=wTx+b,使得 y ^ \hat y y^近似等于 y y y。
- 损失函数Loss Function
一般选用均方误差(mean square error, MSE),采用**最小二乘法(least square method)**求解,简单来说就是找到一条直线,使所有样本到直线上的欧氏距离之和最小。
均方误差即 L = 1 2 m Σ i = 1 m ( y ^ − y ) 2 L=\frac1{2m}\Sigma_{i=1}^m(\hat y-y)^2 L=2m1Σi=1m(y^−y)2,这里乘了 1 2 \frac12 21是为了使后面的计算式更为简洁。
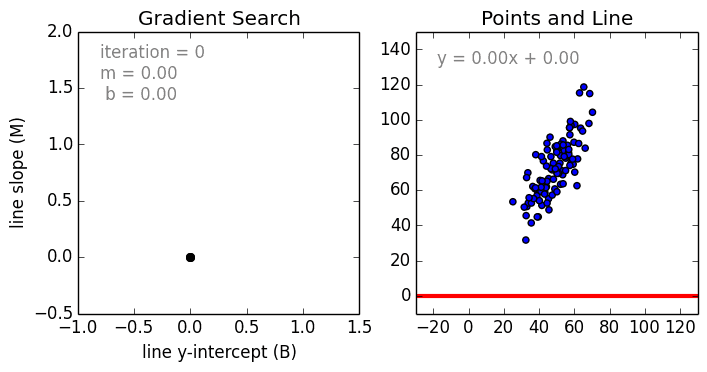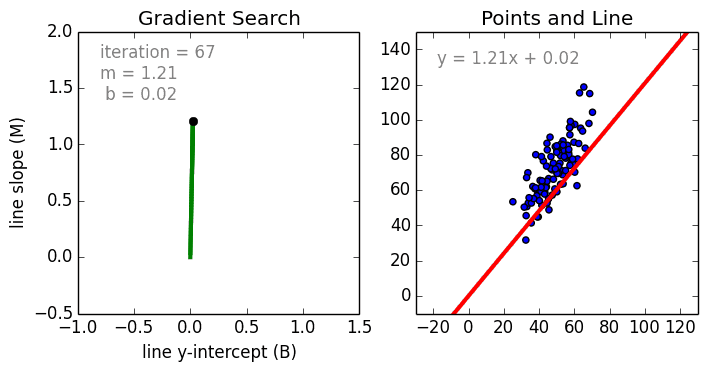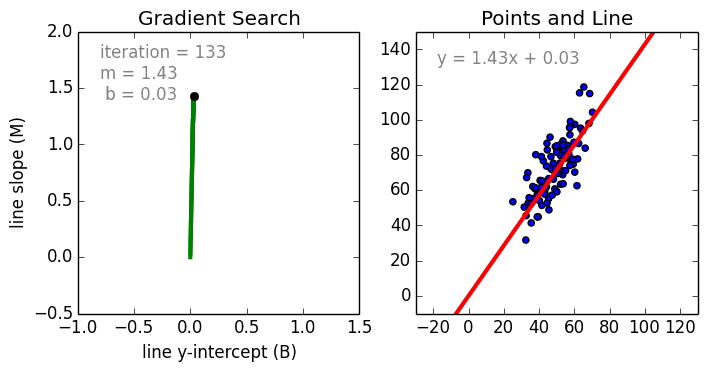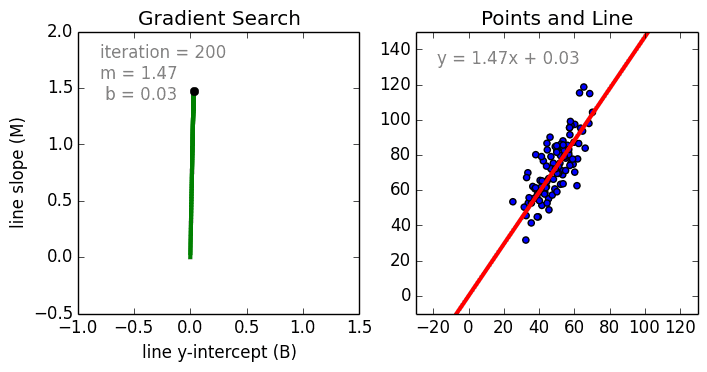
- 梯度下降Gradient Decent
基本思路:首先赋予 w w w、 b b b初始值,用链式法则求出梯度,沿着梯度的反方向不断更新参数,使损失函数不断减小至收敛。具体求法为:
∂ L ∂ w = ∂ L ∂ y ^ ∂ y ^ ∂ w = 1 m Σ i = 0 m ( y ^ i − y i ) x i \frac{\partial L}{\partial w}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial w}=\frac 1m\Sigma_{i=0}^m(\hat y_i-y_i)x_i ∂w∂L=∂y^∂L∂w∂y^=m1Σi=0m(y^i−yi)xi
∂ L ∂ b = ∂ L ∂ y ^ ∂ y ^ ∂ b = 1 m Σ i = 0 m ( y ^ i − y i ) \frac{\partial L}{\partial b}=\frac{\partial L}{\partial \hat y}\frac{\partial \hat y}{\partial b}=\frac 1m\Sigma_{i=0}^m(\hat y_i-y_i) ∂b∂L=∂y^∂L∂b∂y^=m1Σi=0m(y^i−yi)
参数更新:
w j ← w j + α ( y − y ^ ) x j w_j←w_j+α(y−\hat y)x_j wj←wj+α(y−y^)xj
b ← b + α ( y − y ^ ) b←b+α(y−\hat y) b←b+α(y−y^)
其中 α \alpha α称为学习率(learning rate)。
sklearn实现
- 代码
from sklearn import linear_model, datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, r2_score
if __name__ == '__main__':
#load data
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Use only one feature
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes_y[:-20]
diabetes_y_test = diabetes_y[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
print('Coefficients: \n', regr.coef_)
# The mean squared error
print('Mean squared error: %.2f'
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# The coefficient of determination: 1 is perfect prediction
print('Coefficient of determination: %.2f'
% r2_score(diabetes_y_test, diabetes_y_pred))
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='blue', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
- Out:
Coefficients:
[938.23786125]
Mean squared error: 2548.07
Coefficient of determination: 0.47
- 可视化:
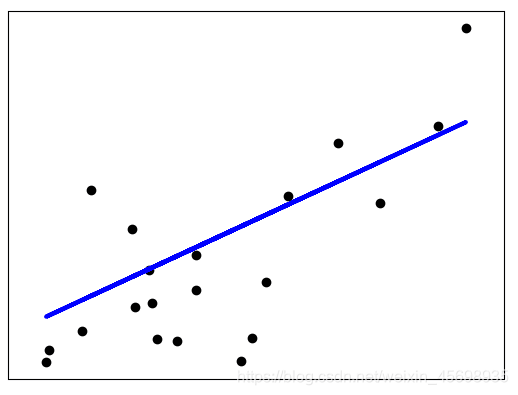
reference:














 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









