






北京时间 9 月 13 日午夜,OpenAI 正式公开一系列全新 AI 大模型,旨在专门解决难题。这是一个重大突破,新模型可以实现复杂推理,一个通用模型解决比此前的科学、代码和数学模型能做到的更难的问题。OpenAI终于正式发布了传说中的“草莓”模型——o1。为什么人家向这个方向发展这么快呢,大家是不是依稀记得我提到过对人类思维的规律总结,他这个只是以纯粹数学编程的思路在做,有突破,但是大概率是不能突破人类极限的,所以人家的也不一定那么好,牛皮都可以吹吹,只讲数学竞赛,你多拍它几次马屁看看你是好心还是坏心,他就不一定对话得出来了,当然中国人还可以哈哈大笑,这是中国人的智慧,人家的工程和数学能力,其实是崇尚真理的能力真应该学学,拍马屁当文明发展到一定程度,就是今天这个状况

 比如说一年时间赶超CHATGTP,现在估计差更远了吧,看各个大厂从入门到放弃百度放弃通用大模型了,阿里的AI+就能行?
比如说一年时间赶超CHATGTP,现在估计差更远了吧,看各个大厂从入门到放弃百度放弃通用大模型了,阿里的AI+就能行?


传说中的“草莓”现身,9月12日晚间,OpenAI正式对外发布一款名为o1的新模型,这款模型为该公司下一代 “推理” 模型中的第一个,o为“Orion(猎户座)”,这款模型可以比人类更快地回答更复杂的问题。
与以前的模型相比,在编写代码和解决多步骤问题方面做得更好。但它也比此前发布的GPT-4o更贵,回答问题也更慢。OpenAI强调o1的这次发布为 “预览版”,还只是初始状态。此次同时发布的还有更小、更便宜的版本o1-mini 。对OpenAI来说,o1 代表着向其更广泛的类人人工智能目标迈出的一步。
ChatGPT Plus和团队用户即日起便可以访问o1预览版和o1-mini,而企业和教育用户将在下周初获得访问权限。OpenAI表示,它计划让ChatGPT的所有免费用户都能访问o1-mini,但尚未确定发布日期。
对开发者来说,访问o1的成本比之前要高出很多:通过API使用o1预览版,输入每百万token要收费15美元,输出每百万收费60美元。相比之下,GPT-4o的百万token输入收费只有5美元,输出为15美元。
OpenAI 的研究负责人杰里・特沃雷克(Jerry Tworek)向媒体透露,o1 “是使用一种全新的优化算法和专门为其定制的新训练数据集进行训练的”,它设置了奖励和惩罚机制,通过强化学习的技术训练模型自行解决问题,它利用类似人类通过逐步解决问题方式的“思维链”处理问题。这种新的训练方法,使得模型更加准确。“我们注意到这个模型的幻觉更少了,” 特沃雷克说,但这个问题仍然存在,“我们不能说我们解决了幻觉问题。”
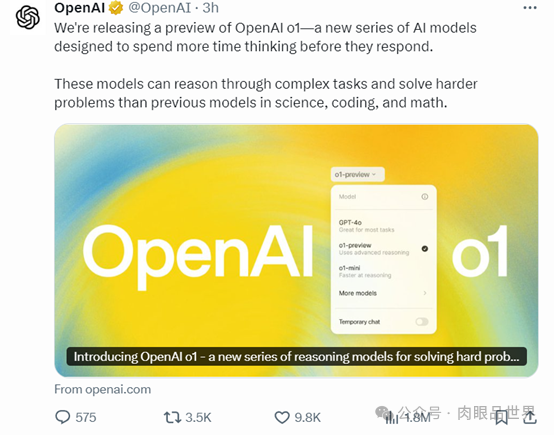
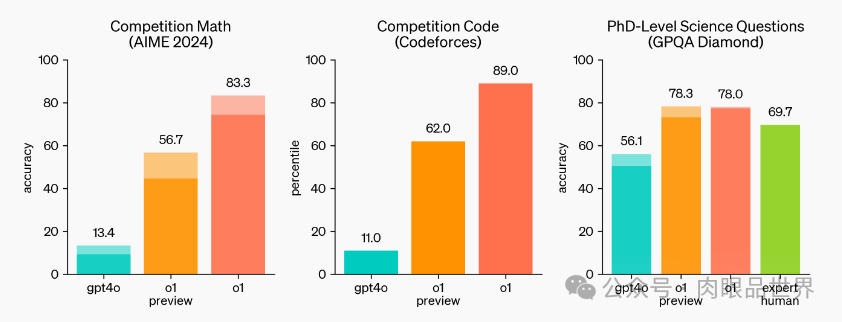
根据OpenAI的说法,这个新模型与GPT-4o的主要区别在于它能够比其前身更好地解决复杂问题,如编码和数学,同时还能解释其推理过程。OpenAI还对o1进行了国际数学奥林匹克资格考试的测试,虽然 GPT-4o只正确解决了13%的问题,但o1得分达到了83%。
在被称为Codeforces竞赛的在线编程比赛中,这个新模型达到了参与者的89%的百分位,OpenAI声称这个模型的下一次更新将在具有挑战性的物理、化学和生物学基准任务中表现得 “类似于博士生”。
o1 模型一举创造了很多历史记录。
首先,o1 就是此前 OpenAI 从山姆・奥特曼到科学家们一直在「高调宣传」的草莓大模型。它拥有真正的通用推理能力。在一系列高难基准测试中展现出了超强实力,相比 GPT-4o 有巨大提升,让大模型的上限从「没法看」直接上升到优秀水平,不专门训练直接数学奥赛金牌,甚至能在博士级别的科学问答环节上超越人类专家。
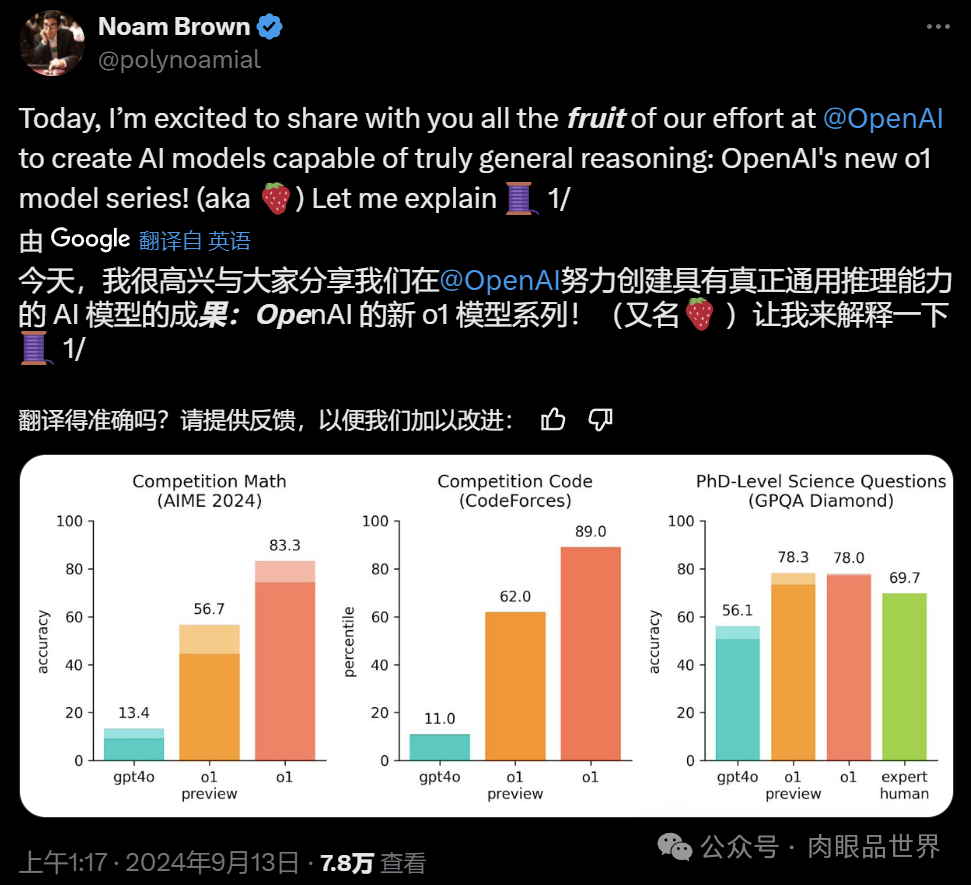
奥特曼表示,虽然 o1 的表现仍然存在缺陷,不过你在第一次使用它的时候仍然会感到震撼。
其次,o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。
也就是从方法上,o1 大模型首次证明了语言模型可以进行真正的强化学习。
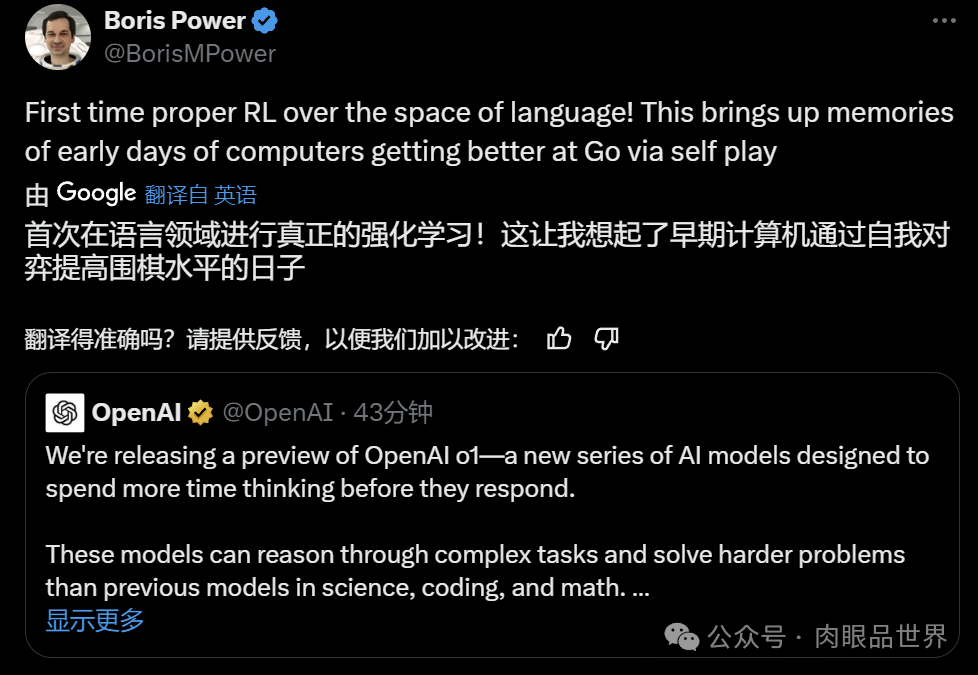
开发出首个 AI 软件工程师 Devin 的 Cognition AI 表示,过去几周一直与 OpenAI 密切合作,使用 Devin 评估 o1 的推理能力。结果发现, 与 GPT-4o 相比,o1 系列模型对于处理代码的智能体系统来说是一个重大进步。
最后在实践中,o1 上线之后,现在 ChatGPT 可以在回答问题前先仔细思考,而不是立即脱口而出答案。就像人类大脑的系统 1 和系统 2,ChatGPT 已经从仅使用系统 1(快速、自动、直观、易出错)进化到了可使用系统 2 思维(缓慢、深思熟虑、有意识、可靠)。这让它能够解决以前无法解决的问题。
从今天 ChatGPT 的用户体验来看,这是向前迈进一小步。在简单的 Prompt 下,用户可能不会注意到太大的差异,但如果问一些棘手的数学或者代码问题,区别就开始明显了。更重要的是,未来发展的道路已经开始显现。
总而言之,今晚 OpenAI 丢出的这个重磅炸弹,已经让整个 AI 社区震撼,纷纷表示 tql、睡不着觉,深夜已经开始抓紧学习。接下来,就让我们看下 OpenAI o1 大模型的技术细节。
OpenAI o1 工作原理
在技术博客《Learning to Reason with LLMs》中,OpenAI 对 o1 系列语言模型做了详细的技术介绍。
OpenAI o1 是经过强化学习训练来执行复杂推理任务的新型语言模型。特点就是,o1 在回答之前会思考 —— 它可以在响应用户之前产生一个很长的内部思维链。
也就是该模型在作出反应之前,需要像人类一样,花更多时间思考问题。通过训练,它们学会完善自己的思维过程,尝试不同的策略,并认识到自己的错误。
在 OpenAI 的测试中,该系列后续更新的模型在物理、化学和生物学这些具有挑战性的基准任务上的表现与博士生相似。OpenAI 还发现它在数学和编码方面表现出色。
在国际数学奥林匹克(IMO)资格考试中,GPT-4o 仅正确解答了 13% 的问题,而 o1 模型正确解答了 83% 的问题。
模型的编码能力也在比赛中得到了评估,在 Codeforces 比赛中排名 89%。
OpenAI 表示,作为早期模型,它还不具备 ChatGPT 的许多实用功能,例如浏览网页获取信息以及上传文件和图片。
但对于复杂的推理任务来说,这是一个重大进步,代表了人工智能能力的新水平。鉴于此,OpenAI 将计数器重置为 1,并将该系列模型命名为 OpenAI o1。
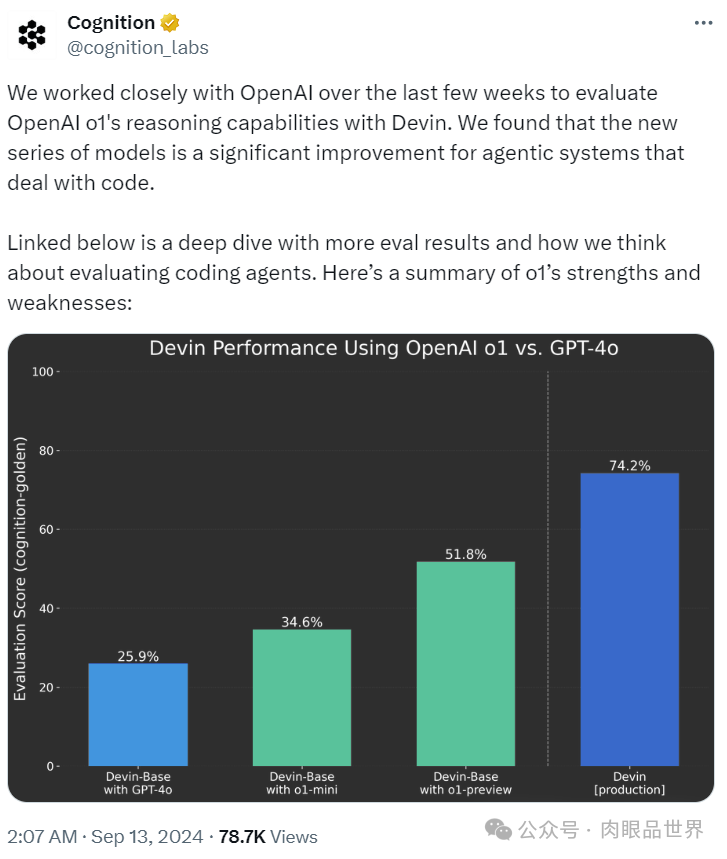
重点在于,OpenAI 的大规模强化学习算法,教会模型如何在数据高度有效的训练过程中利用其思想链进行高效思考。换言之,类似于强化学习的 Scaling Law。
OpenAI 发现,随着更多的强化学习(训练时计算)和更多的思考时间(测试时计算),o1 的性能持续提高。而且扩展这种方法的限制与大模型预训练的限制有很大不同,OpenAI 也还在继续研究。
评估
为了突出相对于 GPT-4o 的推理性能改进,OpenAI 在一系列不同的人类考试和机器学习基准测试中测试了 o1 模型。实验结果表明,在绝大多数推理任务中,o1 的表现明显优于 GPT-4o。
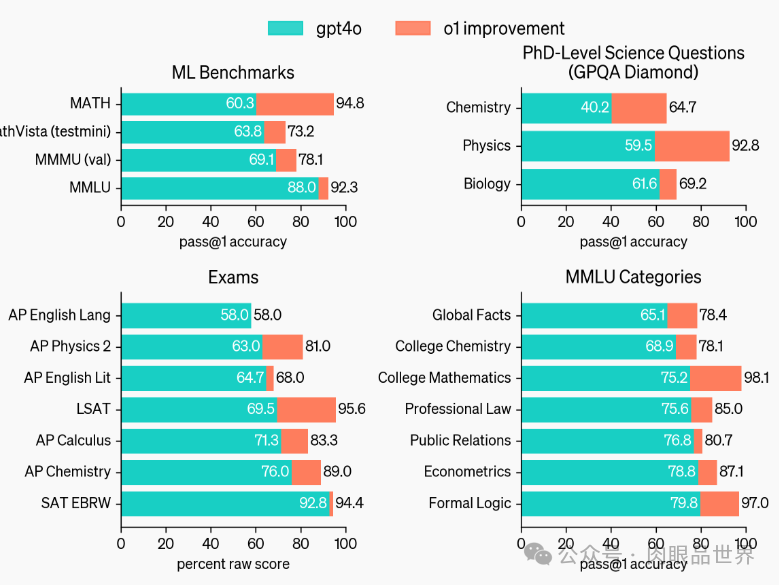
在许多推理密集型基准测试中,o1 的表现可与人类专家相媲美。最近的前沿模型在 MATH 和 GSM8K 上表现得非常好,以至于这些基准测试在区分模型方面不再有效。因此,OpenAI 在 AIME 上评估了数学成绩,这是一项旨在测试美国最聪明高中数学学生的考试。
在一个官方演示中,o1-preview 解答了一个非常困难的推理问题:当公主的年龄是王子的两倍时,公主的年龄与王子一样大,而公主的年龄是他们现在年龄总和的一半。王子和公主的年龄是多少?提供这个问题的所有解。
在 2024 年 AIME 考试中,GPT-4o 平均只解决了 12% (1.8/15) 的问题,而 o1 在每个问题只有一个样本的情况下平均为 74% (11.1/15),在 64 个样本之间达成一致的情况下为 83% (12.5/15),在使用学习的评分函数对 1000 个样本重新排序时为 93% (13.9/15)。13.9 分可以跻身全美前 500 名,并且高于美国数学奥林匹克竞赛分数线。
OpenAI 还在 GPQA Diamond 基准上评估了 o1,这是一个困难的智力基准,用于测试化学、物理和生物学方面的专业知识。为了将模型与人类进行比较,OpenAI 聘请了拥有博士学位的专家来回答 GPQA Diamond 基准问题。
实验结果表明:o1 超越了人类专家的表现,成为第一个在该基准测试中做到这一点的模型。
这些结果并不意味着 o1 在所有方面都比博士更有能力 —— 只是该模型更擅长解决一些博士应该解决的问题。在其他几个 ML 基准测试中,o1 实现了新的 SOTA。
启用视觉感知能力后,o1 在 MMMU 基准上得分为 78.2%,成为第一个与人类专家相当的模型。o1 还在 57 个 MMLU 子类别中的 54 个上优于 GPT-4o。
思维链(CoT)
与人类在回答难题之前会长时间思考类似,o1 在尝试解决问题时会使用思维链。通过强化学习,o1 学会磨练其思维链并改进其使用的策略。o1 学会了识别和纠正错误,并可以将棘手的步骤分解为更简单的步骤。o1 还学会了在当前方法不起作用时尝试不同的方法。这个过程极大地提高了模型的推理能力。
编程能力
基于 o1 进行了初始化并进一步训练了其编程技能后,OpenAI 训练得到了一个非常强大的编程模型(o1-ioi)。该模型在 2024 年国际信息学奥林匹克竞赛(IOI)赛题上得到了 213 分,达到了排名前 49% 的水平。并且该模型参与竞赛的条件与 2024 IOI 的人类参赛者一样:需要在 10 个小时内解答 6 个高难度算法问题,并且每个问题仅能提交 50 次答案。
针对每个问题,这个经过专门训练的 o1 模型会采样许多候选答案,然后基于一个测试时选取策略提交其中 50 个答案。选取标准包括在 IOI 公共测试案例、模型生成的测试案例以及一个学习得到的评分函数上的性能。
研究表明,这个策略是有效的。因为如果直接随机提交一个答案,则平均得分仅有 156。这说明在该竞赛条件下,这个策略至少值 60 分。
OpenAI 发现,如果放宽提交限制条件,则模型性能更是能大幅提升。如果每个问题允许提交 1 万次答案,即使不使用上述测试时选取策略,该模型也能得到 362.14 分——可以得金牌了。
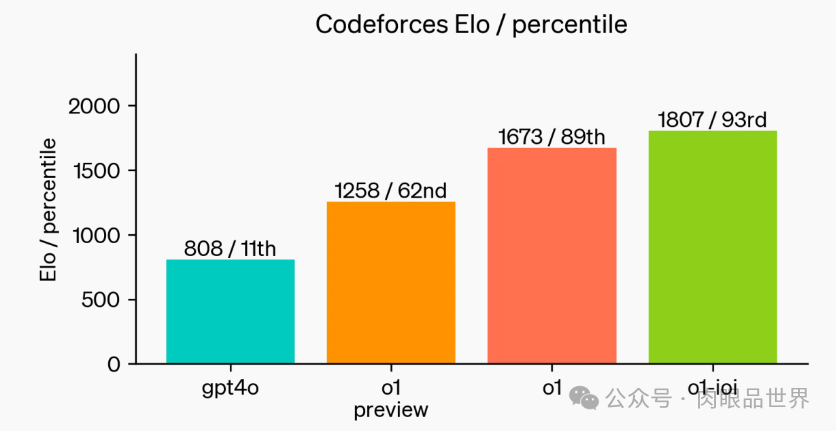
最后,OpenAI 模拟了 Codeforces 主办的竞争性编程竞赛,以展示该模型的编码技能。采用的评估与竞赛规则非常接近,允许提交 10 份代码。GPT-4o 的 Elo 评分为 808,在人类竞争对手中处于前 11% 的水平。该模型远远超过了 GPT-4o 和 o1——它的 Elo 评分为 1807,表现优于 93% 的竞争对手。
下面这个官方示例直观地展示了 o1-preview 的编程能力:一段提示词就让其写出了一个完整可运行的游戏。

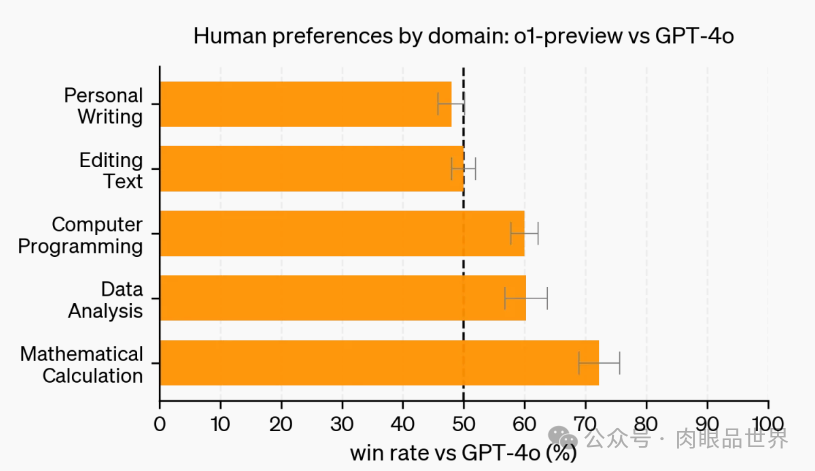
人类偏好评估
除了考试和学术基准之外,OpenAI 还在更多领域的具有挑战性的开放式提示上评估了人类对 o1-preview 和 GPT-4o 的偏好。
在这次评估中,人类训练者对 o1-preview 和 GPT-4o 的提示进行匿名回答,并投票选出他们更喜欢的回答。在数据分析、编程和数学等推理能力较强的类别中,o1-preview 的受欢迎程度远远高于 GPT-4o。然而,o1-preview 在某些自然语言任务上并不受欢迎,这表明它并不适合所有用例。
如何使用 OpenAI o1?
ChatGPT Plus 和 Team(个人付费版与团队版)用户马上就可以在该公司的聊天机器人产品 ChatGPT 中开始使用 o1 模型了。你可以手动选取使用 o1-preview 或 o1-mini。不过,用户的使用量有限。
目前,每位用户每周仅能给 o1-preview 发送 30 条消息,给 o1-mini 发送 50 条消息。
是的,很少!不过 OpenAI 表示正在努力提升用户的可使用次数,并让 ChatGPT 能自动针对给定提示词选择使用合适的模型。
至于企业版和教育版用户,要到下周才能开始使用这两个模型。
至于通过 API 访问的用户,OpenAI 表示达到了 5 级 API 使用量的开发者可以即刻开始使用这两个模型开始开发应用原型,但同样也被限了速:20 RPM。什么是 5 级 API 使用量?简单来说,就是已经消费了 1000 美元以上并且已经是超过 1 个月的付费用户。请看下图:
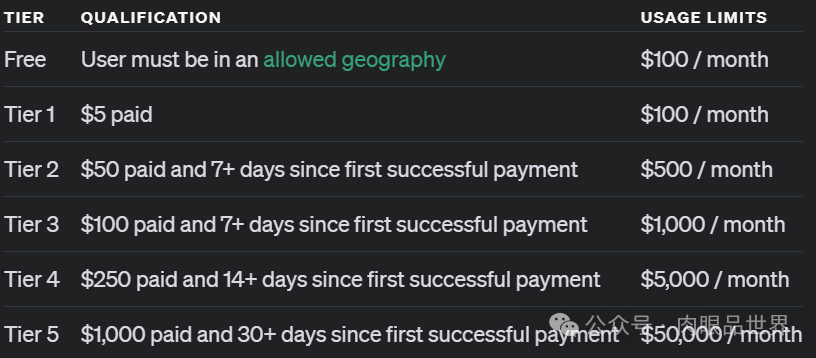
OpenAI 表示对这两个模型的 API 调用并不包含函数调用、流式传输(streaming)、系统支持消息等功能。同样,OpenAI 表示正在努力提升这些限制。
推荐阅读:
ChatGPT 4o 国内直接用 (新)!!!
世界的真实格局分析,地球人类社会底层运行原理
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)
长沙最大(中国领先)的创业俱乐部成立
腾讯XX集团数据湖项目建设方案(附下载)
论数字化转型——转什么,如何转?
华为干部与人才发展手册(附PPT)
【中台实践】华为大数据中台架构分享.pdf
华为的数字化转型方法论
华为如何实施数字化转型(附PPT)
华为大数据解决方案(PPT)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









