







一、什么是正则表达式
正则表达式( Regular expression)是一组由字母和符号组成的特殊文本, 它可以用来从文本中找出满足你想要的格式的句子。
比如我们在网站中看到对用户名规则做出了如下限制:只能包含小写字母、数字、下划线和连字符,并且限制用户名长度在3~15个字符之间,如何验证一个用户名是否符合规
则呢 ?我们使用以下正则表达式:

以上的正则表达式可以接受john_doe、jo-hn_doe、john12_as,但不能匹配A1,因为它包含了大写字母而且长度不到3个字符。
二、简单的模式:字符匹配
元字符

反斜杠后面跟普通字符实现特殊功能

2.1 元字符练习
# 提取字符串a中所有的数字,返回结果:[‘7’, ‘6’, ‘3’, ‘6’]
import re
a = '孙悟空7猪八戒6沙和尚3唐僧6白龙马'
r = re.findall('[0-9]',a)
print(r)
#提取字符串a中所有非数字,返回:[‘孙’, ‘悟’, ‘空’, ‘猪’, ‘八’, ‘戒’, ‘沙’, ‘和’, ‘尚’, ‘唐’, ‘僧’, ‘白’, ‘龙’, ‘马’]
import re
a = '孙悟空7猪八戒6沙和尚3唐僧6白龙马'
r = re.findall('[^0-9]',a)
print(r)
# 找到字符串中间字母是d或e的单词,返回:[‘xdz’, ‘xez’]
import re
a = 'xyz,xcz,xfz,xdz,xaz,xez'
r = re.findall('x[de]z',a)
print(r)
# 找到字符串中间字母不是d或e的单词,返回:[‘xyz’, ‘xcz’, ‘xfz’, ‘xaz’]
import re
a = 'xyz,xcz,xfz,xdz,xaz,xez'
r = re.findall('x[^de]z',a)
print(r)
# 找到字符串中间字母是d或e或f的单词,返回:[‘xfz’, ‘xdz’, ‘xez’]
import re
a = 'xyz,xcz,xfz,xdz,xaz,xez'
r = re.findall('x[d-f]z',a)
print(r)
2.2 概括字符集
# 提取字符串a中所有的数字
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\d',a)
print(r)
# 提取字符串a中所有非数字
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\D',a)
print(r)
# \w 可以提取中文,英文,数字和下划线,不能提取特殊字符
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\w',a)
print(r)
# \W 提取特殊字符、空格、\n、\t等
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\W',a)
print(r)
2.3 数量词
# 提取大小写字母混合的单词
import re
a = 'Excel 12345Word23456PPT12Lr'
r = re.findall('[a-zA-Z]{3,5}',a)
print(r)
{3,5}表示提取3到5个字符
#贪婪 与 非贪婪 【Python默认使用贪婪模式】
贪婪:’[a-zA-Z]{3,5}’
先找三个连续的字母,最多找到5个连续的字母后停止。在3个以后且5个以内发现了不是子母的也停止。
非贪婪:’[a-zA-Z]{3,5}?’ 或 ‘[a-zA-Z]{3}’
建议使用后者,不要使用?号,否则你会与下面的?号混淆
匹配0次或无限多次 *号,*号前面的字符出现0次或无限次
import re
a = 'exce0excell3excel3'
r = re.findall('excel*',a)
print(r)
# 匹配1次或者无限多次 +号,+号前面的字符至少出现1次
import re
a = 'exce0excell3excel3'
r = re.findall('excel+',a)
print(r)
# 匹配0次或1次 ?号,?号经常用来去重复
import re
a = 'exce0excell3excel3'
r = re.findall('excel?',a)
print(r)
2.4 边界匹配 ^和$

# 限制电话号码的位置必需是8-11位才能提取
import re
tel = '13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
2.5 组 ( )
# 将abc打成一个组,{2}指的是重复几次,匹配abcabc
import re
a = 'abcabcabcxyzabcabcxyzabc'
r = re.findall('(abc){2}',a)
print(r)
可以加入很多个组
2.6 匹配模式参数
# findall第三参数 re.I忽略大小写
import re
a = 'abcFBIabcCIAabc'
r = re.findall('fbi',a,re.I)
print(r)
# 多个模式之间用 | 连接在一起
import re
a = 'abcFBI\nabcCIAabc'
r = re.findall('fbi.{1}',a,re.I | re.S) # 匹配fbi然后匹配任意一个字符包括\n
print(r)
注:.句号,不匹配\n,但是使用re.S之后,匹配所有字符包括换行符
1).re.I(re.IGNORECASE): 忽略大小写
2).re.M(MULTILINE): 多行模式,改变’^’和’$’的行为
3).re.S(DOTALL): 点任意匹配模式,改变’.’的行为
4).re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
5).re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
6).re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
2.7 re.sub替换字符串
# 把FBI替换成BBQ
import re
a = 'abcFBIabcCIAabc'
r = re.sub('FBI','BBQ',a)
print(r)
# 把FBI替换成BBQ,第4参数写1,证明只替换第一次,默认是0(无限替换)
import re
a = 'abcFBIabcFBIaFBICIAabc'
r = re.sub('FBI','BBQ',a,1)
print(r)
注意:虽然字符串的内置方法 字符串.replace 也可以进行替换,但是正则表达式更强大
# 拓展知识
import re
a = 'abcFBIabcFBIaFBICIAabc'
def 函数名(形参):
pass
r = re.sub('FBI',函数名,a,1)
print(r)
分析:如果找到了FBI这个子串,会将FBI当成参数传到形参中,pass是什么都没返回,所以FBI被空字符串代替了。
# 把函数当参数传到sub的列表里,实现把业务交给函数去处理,例如将FBI替换成$FBI$
import re
a = 'abcFBIabcFBIaFBICIAabc'
def 函数名(形参):
分段获取 = 形参.group() # group()在正则表达式中用于获取分段截获的字符串,获取到FBI
return '$' + 分段获取 + '$'
r = re.sub('FBI',函数名,a)
print(r)
2.8 把函数做为参数传递
# 将字符串中大于等于5的替换成9,小于5的替换成0
import re
a = 'C52730A52730D52730'
def 函数名(形参):
分段获取 = 形参.group()
if int(分段获取) >= 5:
return '9'
else:
return '0'
r = re.sub('\d',函数名,a)
print(r)
2.9 group分组
import re
a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
- 正则表达式中的三组括号把匹配结果分成三组
group() 同group(0)就是匹配正则表达式整体结果
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。 - 没有匹配成功的,re.search()返回None
- 当然正则表达式中没有括号,group(1)肯定不对了。
import re
a = 'life is short,i use python'
r = re.search('life(.*)python',a)
print(r.group(1))
等同于
import re
a = 'life is short,i use python'
r = re.findall('life(.*)python',a)
print(r)
# 拓展知识
import re
a = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',a)
print(r.group(0)) # 完整正则匹配
print(r.group(1)) # 第1个分组之间的取值
print(r.group(2)) # 第2个分组之间的取值
print(r.group(0,1,2)) # 以元组形式返回3个结果取值
print(r.groups()) # 返回就是group(1)和group(2)
三、常用函数
3.1 re.compile
compile:re.compile是将正则表达式转换为模式对象,这样可以更有效率匹配。使用compile转换一次之后,以后每次使用模式时就不用进行转换
pattern:写正则表达式
flags:匹配模式
从compile()函数的定义中,可以看出返回的是一个匹配对象,它单独使用就没有任何意义,需要和findall(), search(), match()搭配使用。
compile()与findall()一起使用,返回一个列表。
# compile配合findall
import re
a = '0355-67796666'
b = re.compile(r'\d+-\d{8}')
r = re.findall(b,a)
print(r)
import re
a = '0355-67796666'
b = re.compile(r'\d+-\d{8}')
r = b.findall(a)
print(r)
# 直接使用findall
import re
a = '0355-67796666'
r = re.findall(r'\d+-\d{8}',a)
print(r)
# compile配合search
import re
a = '0355-67796666'
正则 = re.compile(r'\d+-\d{8}')
r = re.search(正则,a)
print(r.group())
# compile配合match
import re
a = '0355-67796666'
正则 = re.compile(r'\d+-\d{8}')
r = re.match(正则,a)
print(r.group
3.2 re.match
match 从字符串的第一个字符开始匹配,如果未匹配到返回None,匹配到则返回一个对象
match判断正则表达式是否从开始处(首字母)匹配一个字符串,例如第一个不是\d(数字),返回None
import re
a = 'A83C72D1D8E67'
r = re.match('\d',a)
print(r) # 返回对象所在位置
print(r.group()) # 返回找到的结果,例如8
print(r.span()) # 返回一个元组表示匹配位置(开始,结束)
3.3 re.search
Search与match有些类似,只是搜索整个字符串然后第一个匹配到指定的字符则返回值,未匹配到则返回None。获取值得方
法也需要通过group()
从字符串开始往后匹配,一匹配到则返回一个对象。需要通过group来获取匹配到的值。
search 遍历字符串,找到正则表达式匹配的第一个位置
import re
a = 'A83C72D1D8E67'
r = re.search('\d',a)
print(r)
print(r.group())
3.4 re.findall
Findall是匹配出字符串中所有跟指定值有关的值,并且以列表的形式返回。未匹配到则返回一个空的列表。匹配出指定字符的所有值,并以列表返回值。
import re
text = “you’re just not for him in the rain.Never put your happiness in someone else’s hands.Sometimes you have to give up on someone in order to respect yourself”
print(re.findall(r’to’,text))
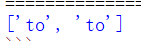
四、 正则使用搭配
4.1正则基础语法
^ 指出一个字符串的开始
$ 指出一个字符串的结束
\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符
^abc 匹配所有以 "abc" 开始的字符串 (例如:"abc","abccba")
abc$ 匹配所有以"abc" 结尾的字符串 (例如:"gggabc","reddcba")
^abc$ 匹配开始和结尾都为"abc"的字符串 (例如:"abc")
abc 没有任何字符,匹配任何包含"abc"的字符串 (例如:"aaaabccc","abc123")
n 匹配n "\n":匹配换行符 "\/"这里是 \ he / 连在一起写,匹配 " / " 字符
匹配前面的子表达式零次或多次
+ 匹配前面的子表达式一次或多次
? 匹配前面的子表达式零次或一次
ac* 匹配字符串其中一个a后面跟着零个或若干个c (例如:"accc","abbb")
ac+ 匹配字符串其中一个a后面跟着至少一个c或者多个 (例如:"ac","acccccccc")
ac? 匹配字符串其中一个a后面跟着零个或者一个c (例如:"a","ac")
a?c+$ 匹配字符串的末尾有零个或一个a跟着一个或多个c (例如:"ac","acccccc",''c'',"ccccccc")
{n} n为非负整数,匹配n次
{n,} n为非负整数,匹配至少n次
{n,m} n,m为非负整数,最少匹配n次 最多匹配m次
ab{3} 表示一个字符串有一个a后面跟随2个b (例如:"abb","abbbbb")
ab{3,} 表示一个字符串有一个a后面跟随至少2个b (例如:"abb","abbb")
ab{3,6} 表示一个字符串有一个a后面跟随3到6个b (例如:"abbb","abbbb","abbbb")
表示"或"
. 表示任何字符
a|b 表示一个字符串里有 a 或者 b (例如:"a","b","ab","abc")
a. 表示一个字符串有一个 a 后面跟着一个任意字符 (例如:"a1","a456","avv")
4.2使用"^"表示不希望出现的字符
[abc] 表示字符集合,表示一个字符串有一个"a"或"b"或"c" 等价于 [z|b|c]
[^abc] 表示一个字符串中不应该出现abc,即是匹配未包含改集合的任意字符
[a-z] 表示一个字符串中存在一个a和z之间的所有字母
[0-9] 表示一个字符串中存在一个0和9之间的所有数字
[^a-z] 表示一个字符串中不应该出现a到z之间的任意一个字母
^[a-zA-Z] 表示一个字符串中以字母开头
[0-9]% 表示一个百分号前有一个的数字;
4.3由字符’'和另一个字符组成特殊含义
\d 匹配一个数字字符,等价[0-9]
\D 匹配一个非数字字符,等价[^0-9]
\f 匹配一个换页符,等价\x0c和\cL
\n 匹配一个换行符。等价于\x0a和\cJ
\r 匹配一个回车符。等价于\x0d和\cM
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]
\S 匹配任何非空白字符。等价于[^ \f\n\r\t\v]
\t 匹配一个制表符。等价于\x09和\cI
\v 匹配一个垂直制表符。等价于\x0b和\cK
\w 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”
\W 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”
五、正则表达式实战
/^[0-9]{1,20}$/
表示字符串全部由数字组成,即是匹配当前字符串是否是由全数字组成
[0-9] 表示字符的范围是0到9
{1,20}表示字符串长度至少为1,最多为20,字符串出现次数的范围
/^[a-zA-Z]{1}([a-zA-Z0-9._]){5,15}$/
可以用来验证登录名,首字母为字母,长度为至少6最多16
^[a-zA-Z]{1} 表示最开始的第一个首字母为字母
([a-zA-Z0-9._]){5,15} 这是首字母后面的即是从第二个字母开始要求至少再有5个最多15个由字母数字以及指定特殊字符组成的字符串
/^[1][3|4|5|8][0-9]\d{8}$/
可以用来验证手机号码,首字母为1,长度11,首尾都是数字
^[1] 第一个数字为1
[3|4|5|8] 第二个数字为 3或者4或者5或者8
[0-9]\d{8} 匹配一个数字范围是0-9,匹配8次,所以至少要有8个数字。加起来就是11个
/^(\w){6,20}$/
验证密码
\w 匹配任何非单词字符 等价于“[^A-Za-z0-9_]”
(\w){6,20} 匹配任何非单词字符,最少6个最多20个
六、RegExp 对象的属性和方法
下面我们来研究如何使用
//构造一个正则对象,并填写表达式
var re = new RegExp("\[0-9]*");
var re = /[0-9]*/;
//注意:当使用构造函数(new RegExp)创造正则对象时,需要常规的字符转义规则(在前面加反斜杠 \)
test() 方法:正则表达式方法。
test() 方法用于检测一个字符串是否匹配某个模式,如果字符串中含有匹配的文本,则返回 true,否则返回 false。
var re = /[0-9]*/;
re.test("abc") //返回false
re.test("1234") //返回true
exec() 方法:一个正则表达式方法。
exec() 方法用于检索字符串中的正则表达式的匹配。
该函数返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
var re = /[0-9]*/;
re.exec("abc") //返回 null
re.exec("1234") //返回1234
七、常用正则表达式
7.1校验数字的表达式
数字 ^[0-9]$
n位的数字 ^\d{n}$
至少n位的数字 ^\d{n,}$
m-n位的数字 ^\d{m,n}$
零和非零开头的数字 ^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字 ^([1-9][0-9]*)+(.[0-9]{1,2})?$
带1-2位小数的正数或负数 ^(\-)?\d+(\.\d{1,2})?$
正数、负数、和小数 ^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数 ^[0-9]+(.[0-9]{2})?$
有1~3位小数的正实数 ^[0-9]+(.[0-9]{1,3})?$
非零的正整数 ^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数 ^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数 ^\d+$ 或 ^[1-9]\d*|0$
非正整数 ^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数 ^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数 ^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数 ^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数 ^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
7.2校验字符的表达式
汉字 ^[\u4e00-\u9fa5]{0,}$
英文和数字 ^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符 ^.{3,20}$
由26个英文字母组成的字符串 ^[A-Za-z]+$
由26个大写英文字母组成的字符串 ^[A-Z]+$
由26个小写英文字母组成的字符串 ^[a-z]+$
由数字和26个英文字母组成的字符串 ^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串 ^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线 ^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号 ^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符 [^%&',;=?$\x22]+
禁止输入含有~的字符 [^~\x22]+















 4325
4325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









