







这是一篇关于Deep Q-learning from Demonstrations DQFD的笔记文
原文链接:DQFD
一、主要问题:how to 加速agent的学习过程,避免前期的cold start
- 一方面,搞控制的都知道,工业场景不可能让你直接验证算法性能,或者RL与工业环境直接的”试错交互“学习,一般都需要在软件上建立数值模型simulator作为模拟环境去和RL算法interact
但是有的工业过程很难建立这类模型去解析求解,亦或者所建立的大多模型仅仅与现实环境近似而已(忽略了许多非线性变量的强耦合信息,以及大多都加入了理想条件)。
而Agent与environment交互过程中,需要大量的数据,慢且表现差,(训练过程=炼丹过程)可能最终结果都不如一些传统的方法,但这对simulator器来说是可以接受的。因此simulator学出来的RL模型最终在真实环境中难以评估,且得到很好的得分效果。
- 另一方面,simulator直接限制了RL算法在某些真实任务的适用性,比如:Agent必须在真实的环境中学习,并且训练得越快越准越好。
因此,这篇文章DQFD在PDD-DQN的基础上为解决data-efficiency问题上做了很多工作。
二、创新点
DQFD主要将时间差分TD与supervised loss结合在一起
文章主要有六个亮点:
- Demonstrations: 提供一组演示数据,并永久存放在经验回放池中(俗称专家知识),可以用于限制策略空间,初始化约束的作用。
- Pre-training: Agent与environment交互前的预训练,即引入模仿学习imitation learning的思想,对已有的Demonstrations做imitate,在online-training process 前,将不是单独去学习action,而是去学对应的Q function。
- Supervised loss:利用监督学习的特性,从Demonstrations抽样来对于神经网络的Q function随机梯度下降计算
- L2 Regularization LOSS: 在网络权值上增加了L2正则项,防止过拟合
- N-step TD losses: 采用1步与N步返回的目标混合更新Q网络,有助于将专家的轨迹值传递到更早的状态,从而实现更好的预训练
- Demonstration priority bonus: 将experience priority replay 的思想引入Deminstration中,提高网络相关性的采用频率。
三、损失函数(四合一)
DQFD适用于Agent直接与真实环境交互的任务,即在与真实环境交互前,采用专家经验数据集进行预训练(这个过程采用优先经验回放,来提高某些相关性较强的知识的采用频率)。并且用Value function 模拟专家(即示范者)
包含了四个损失函数,监督损失用于演示器动作的分类,而Q学习损失确保了网络满足贝尔曼方程,并可作为TD学习的起点。
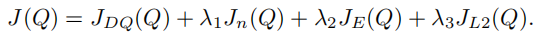
- JDQ(Q)、JnQ(Q):1步Q-learning损失以及n步Q-learning损失, 均用于保证这个value function网络满足Bellman方程;
- JE(Q): 监督学习的大间距分类损失,用于示范动作的分类;
- JL2(Q):L2正则项
其中,监督学习的大间距分类损失
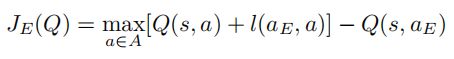
文章中重点提到supervised large margin classification loss
实际上Demonstration中有一个小问题,即专家数据只包含了一小部分的状态-动作空间,许多状态-动作根本就没有数据。但是如果只是用Q-learning update的方式更新,网络会朝着那些ungrounded variables的方向更新,并且受到bootstrap的影响,这将传播到其他state,这样pre-training就学了个寂寞
The supervised loss is critical for the pre-training to have any effect. Since the demonstration data is necessarily covering a narrow part of the state space and not taking all possible actions, many state-actions have never been taken and have no data to ground them to realistic values. If we were to pre-train the network with only Q-learning updates towards the max value of the next state, the network would update towards the highest of these ungrounded variables and the network would propagate these values throughout the Q function. We add a large margin classification loss (Piot, Geist, and Pietquin 2014a):

其中aE是表示expert示范动作,即Demonstration中的action;l(aE,a)是一个边界函数;当a=aE时l(aE,a)为0,否则为正。
加入JE(Q)损失的优点在于1. 能够使看不见的行为价值增加到合理的价值中。2. 限制连续状态之间的值和q网络满足贝尔曼方程(与传统的imitation learning的思想不同,这里学的是action的Q值,而不是单纯的模仿action。)
四、N步累计奖励
Adding n-step returns (with n = 10) helps propagate the values of the expert’s trajectory to all the earlier states, leading to better pre-training. The n-step return is:
添加n步返回(使用n=10)有助于将专家的轨迹值传递到更早的状态,从而实现更好的预训练pre-training。n步的返回步骤是:
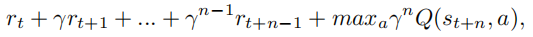
五、Algorithm Pseudo-code
监督学习的imitaion learning,没有与环境的交互

六、Conclusion
使用Demonstration来做supervised loss其实有利有弊,因为对于真实环境来说,Demonstration data实际上不可能包含所有的状态-动作空间。但是如果只是用Q-learning update的方式更新,网络会朝着那些ungrounded variables的方向更新,并且受到bootstrap的影响,这将传播到其他state,这样pre-training就学了个寂寞。
因此,将Demonstration可以看成一个软的初始化约束。














 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









