







爬取笔趣阁小说(搜索+爬取)
首先看看最终效果(gif):
实现步骤:
1.探查网站“http://www.xbiquge.la/”,看看网站的实现原理。
2.编写搜索功能(获取每本书目录的URL)。
3.编写写入功能(按章节写入文件)。
4.完善代码(修修bug,建了文件夹)。
ps:所需模块 :
import requests
import bs4 # 爬网站必备两个模块不解释
import os # 用来创建文件夹的
import sys # 没啥用单纯为了好看
import time
import random # 使用随机数设置延时
一、网站搜索原理,并用Python实现。
我本以为这个网站和一般网站一样,通过修改URL来进行搜索,结果并不然。
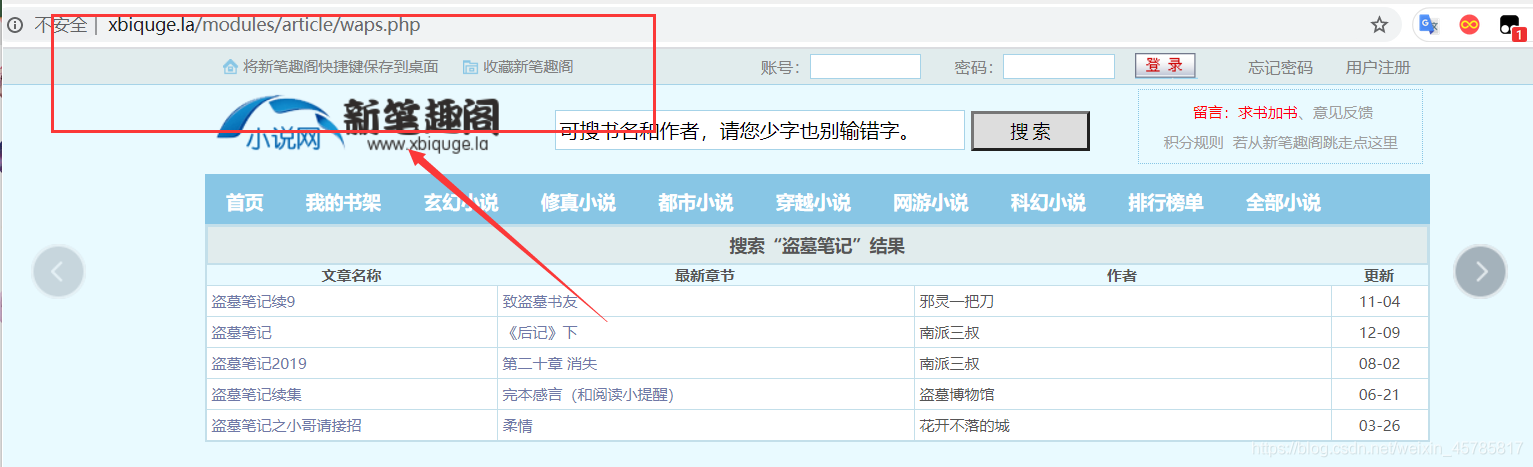
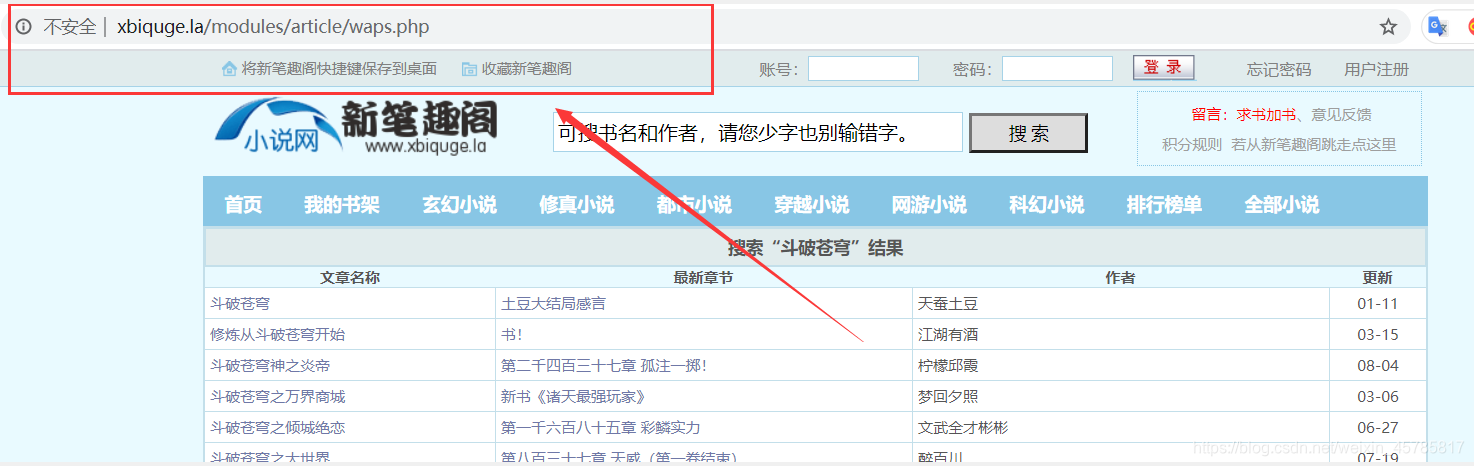
可以看出这个网站不会因搜索内容改变而改变URL。
那还有一种可能:通过POST请求,来更新页面。让我们打开Network验证一下。

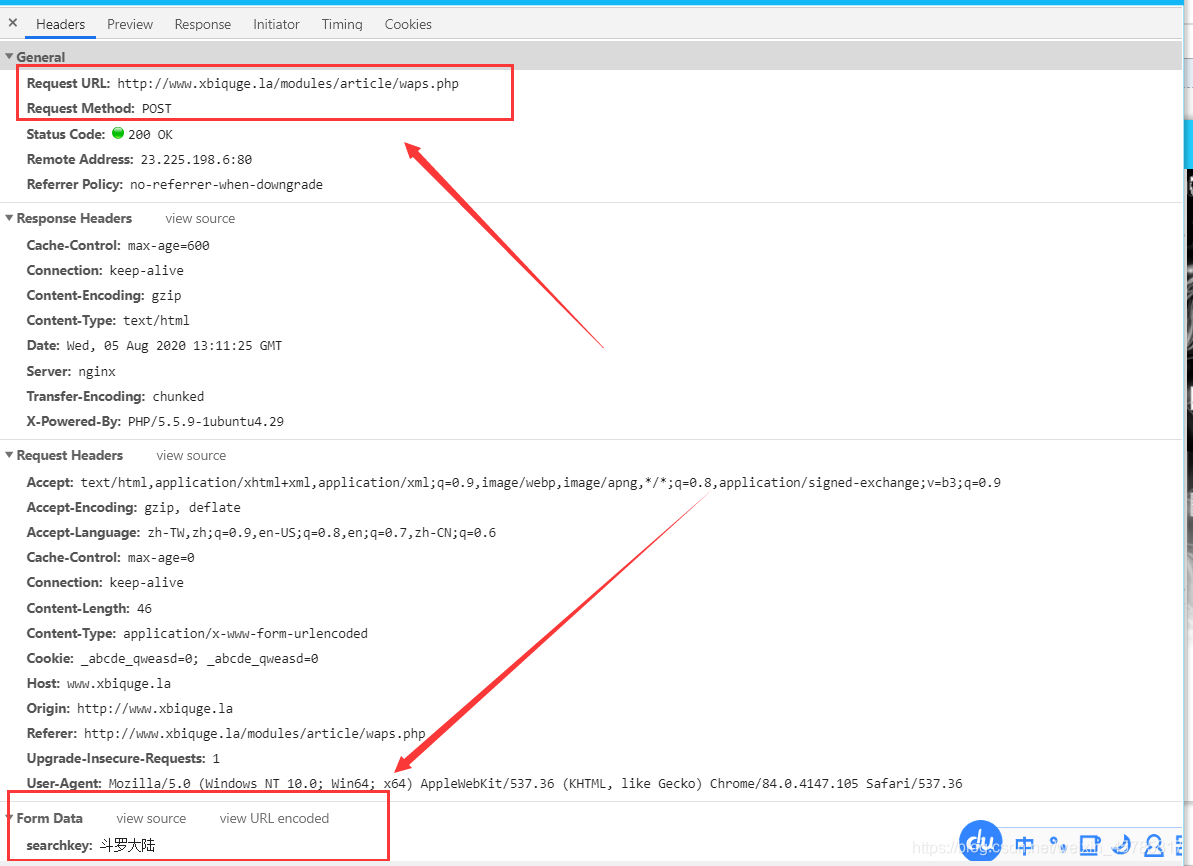
我的猜想是对的。接下来开始模拟。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36",
"Cookie": "_abcde_qweasd=0; Hm_lvt_169609146ffe5972484b0957bd1b46d6=1583122664; bdshare_firstime=1583122664212; Hm_lpvt_169609146ffe5972484b0957bd1b46d6=1583145548",
"Host": "www.xbiquge.la"} # 设置头尽量多一点 以防万一
x = str(input("输入书名或作者名:")) # 通过变量来控制我们要搜索的内容
data = {
'searchkey': x}
url = 'http://www.xbiquge.la/modules/article/waps.php'
r = requests.post(url, data=data, headers=headers)
soup = bs4.BeautifulSoup(r.text.encode('utf-8'), "html.parser") # 用BeautifulSoup方法方便我们提取网页内容网页
可是如果现在我printf(soup)后发现里面的中文全为乱码!
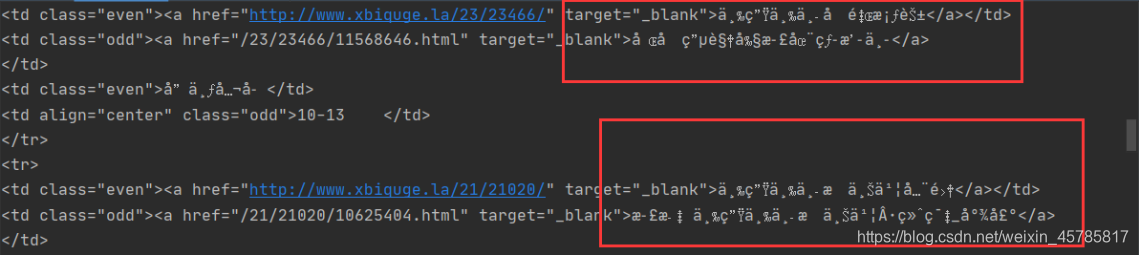
这不难看出是编码格式不对,但我们可以用encoding方法来获取编码方式。
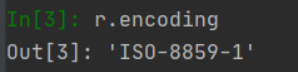
改完编码后就可以正常提取了,并且和浏览器显示的一致,都是我们搜索的内容。
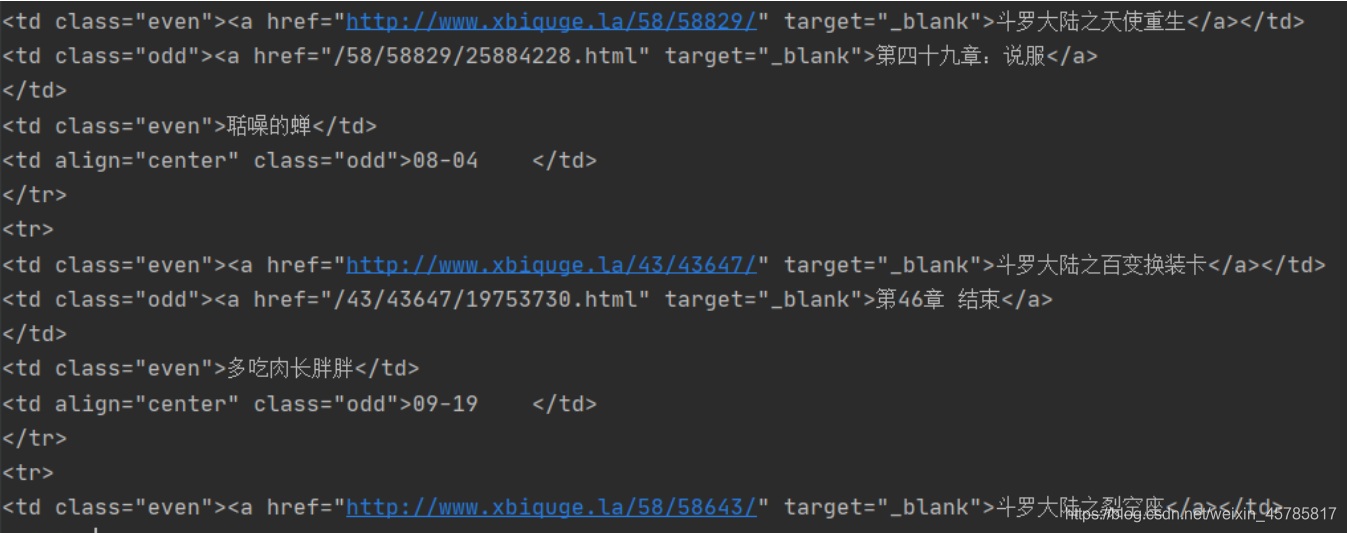
二、接下来我们就来在这一堆代码里找到我们想要的内容了(书名,作者,目录URL)
通过元素审查我们很容易就可以定位到它们所在位置。
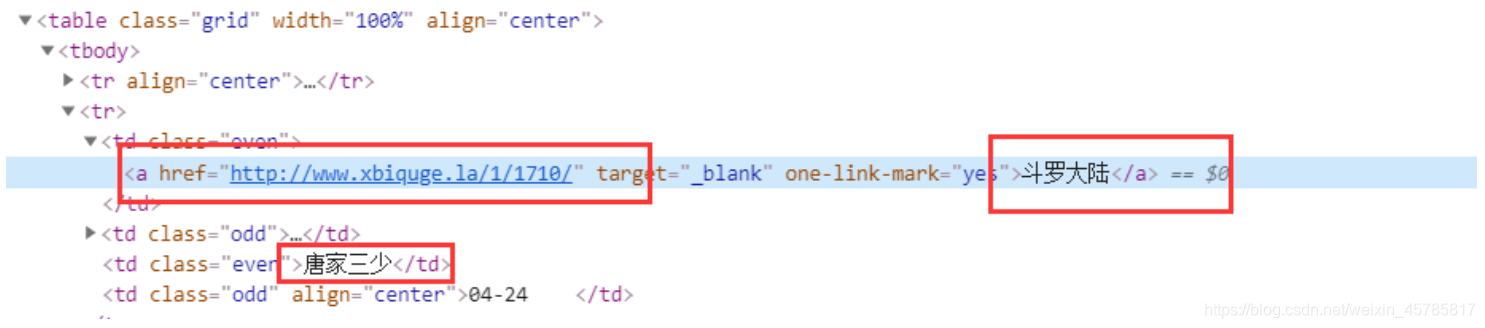
链接和书名在"td class even"< a> 标签里,作者在"td class=even"里。
什么!标签重名了!怎么办!管他三七二十一!先把"td class=even"全打印出来看看。
book_author = soup.find_all("td", class_="even")
for each in book_author:
print(each)
可以发现每个each分为两层。
那我们可以奇偶循环来分别处理这两层。(因为如果不分层处理的话第一层要用的方法(each.a.get(“href”)在第二层会报错,好像try也可以处理这个错,没试)
并且用创建两个三个列表来储存三个值。
books = [] # 书名
authors = [] # 作者名
directory = [] # 目录链接
tem = 1
for each in book_author:
if tem == 1:
books.append(each.text)
tem -= 1
directory.append(each.a.get("href"))
else:
authors.append(each.text)
tem += 1
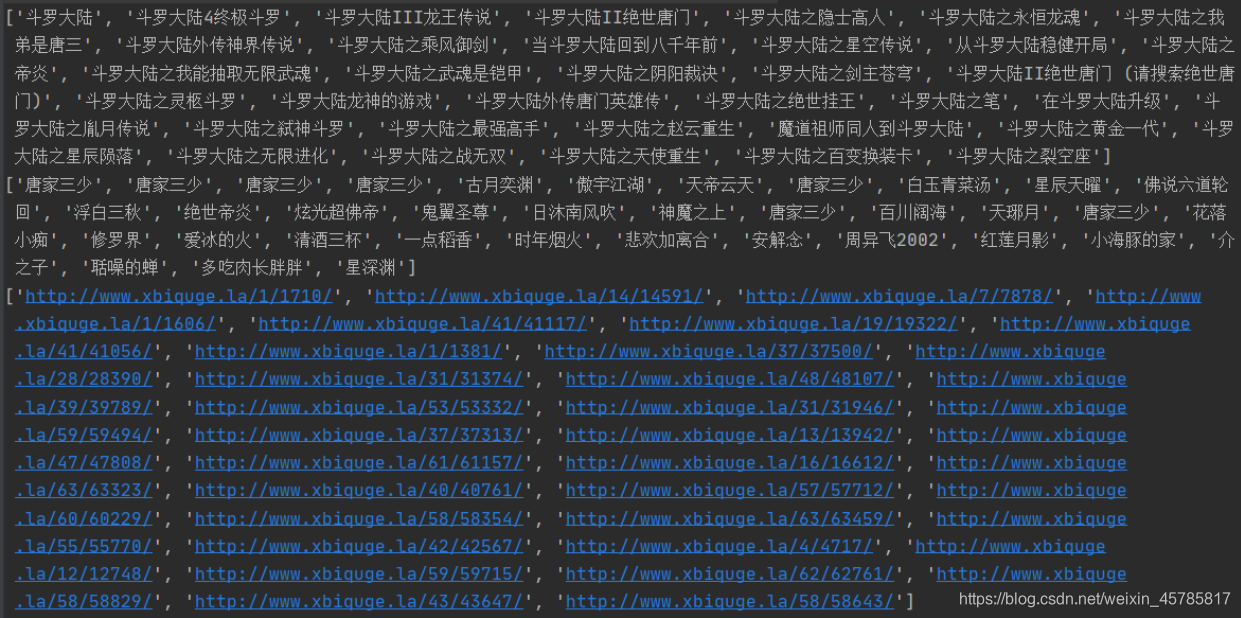
成功!三个列表全部一样对应!
那么要如何实现选择一个序号,来让Python获得一个目录链接呢?
我们可以这样:
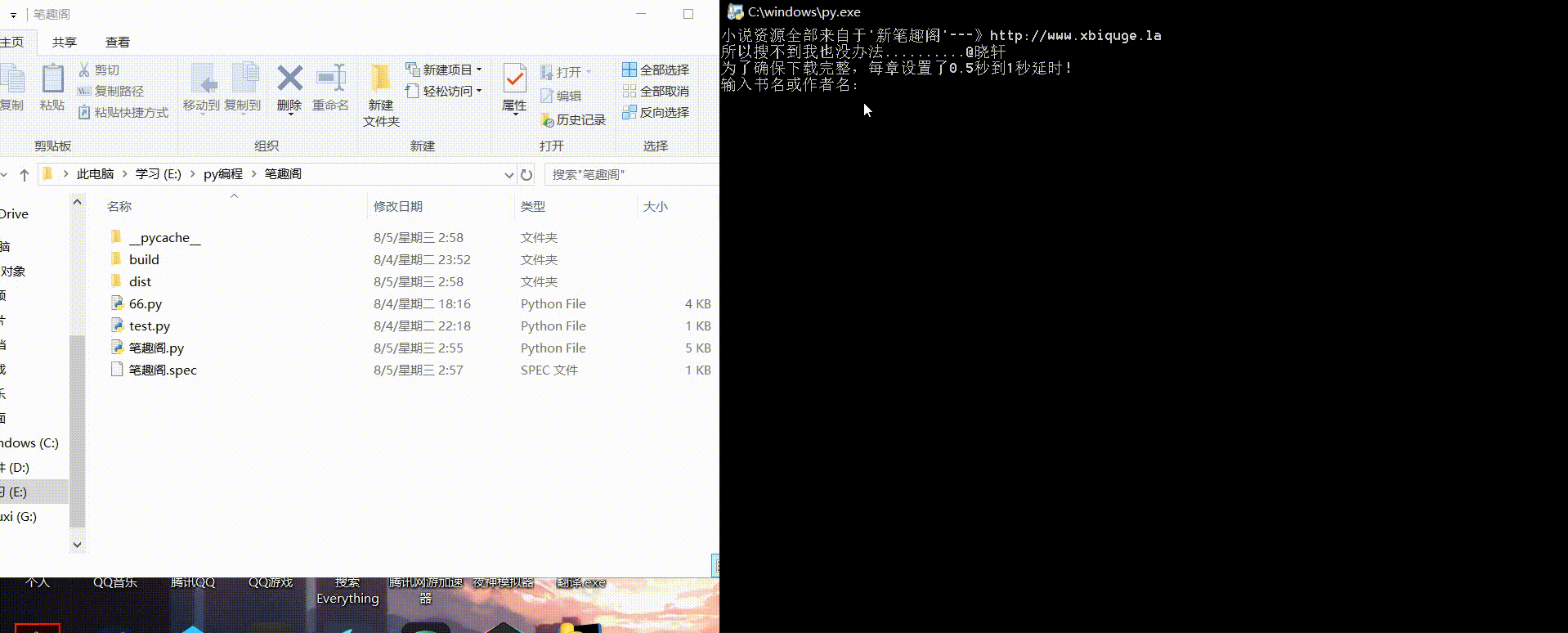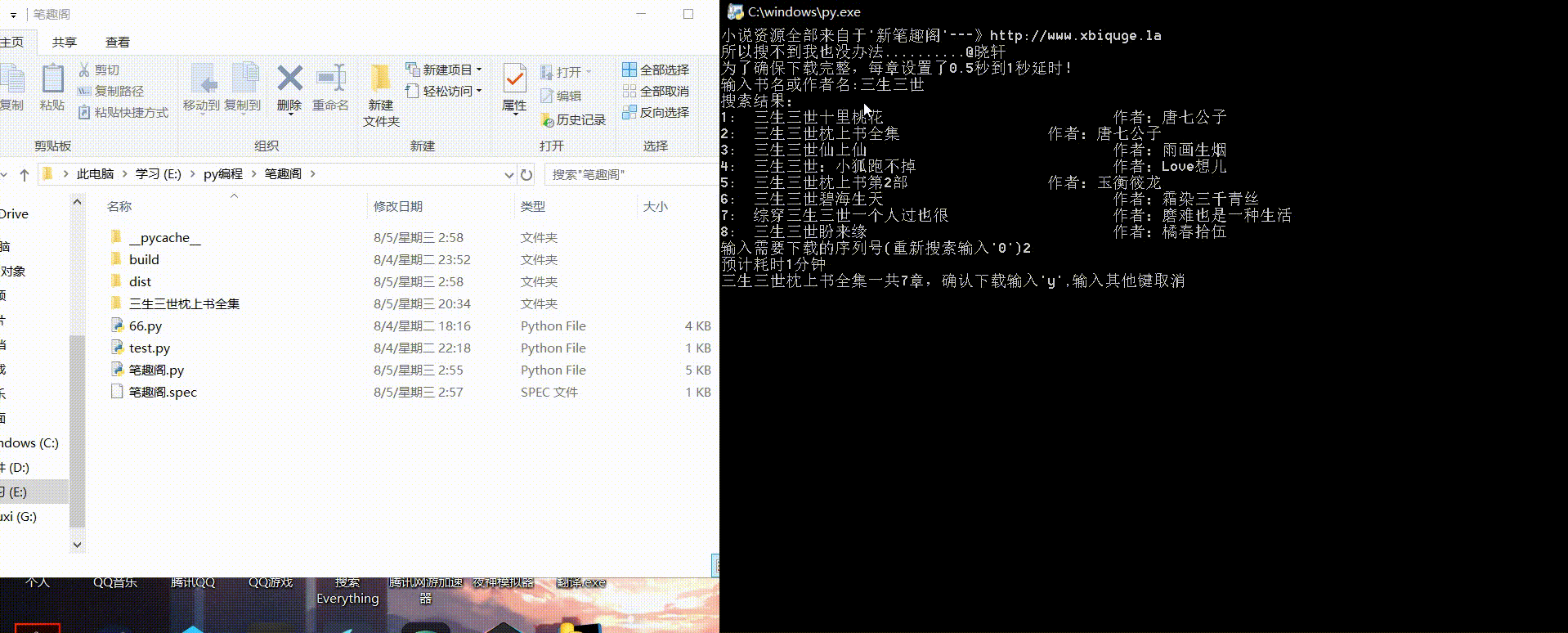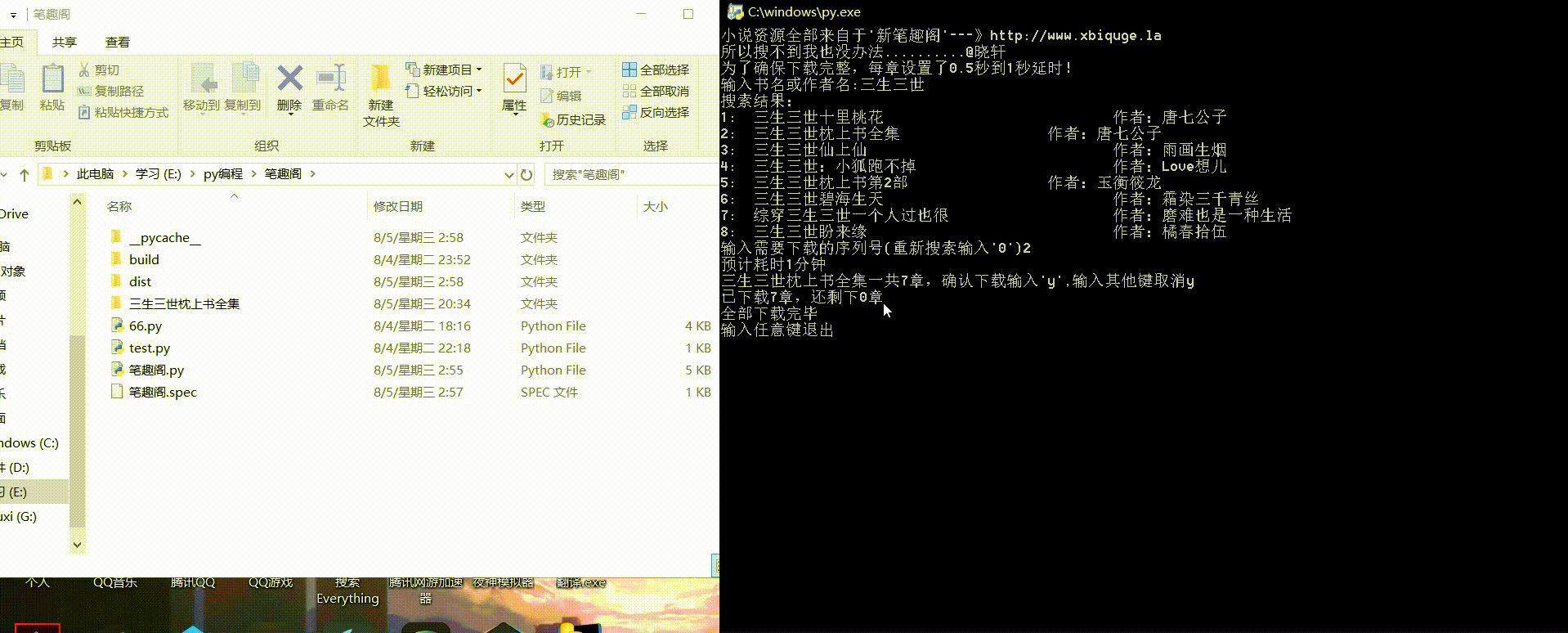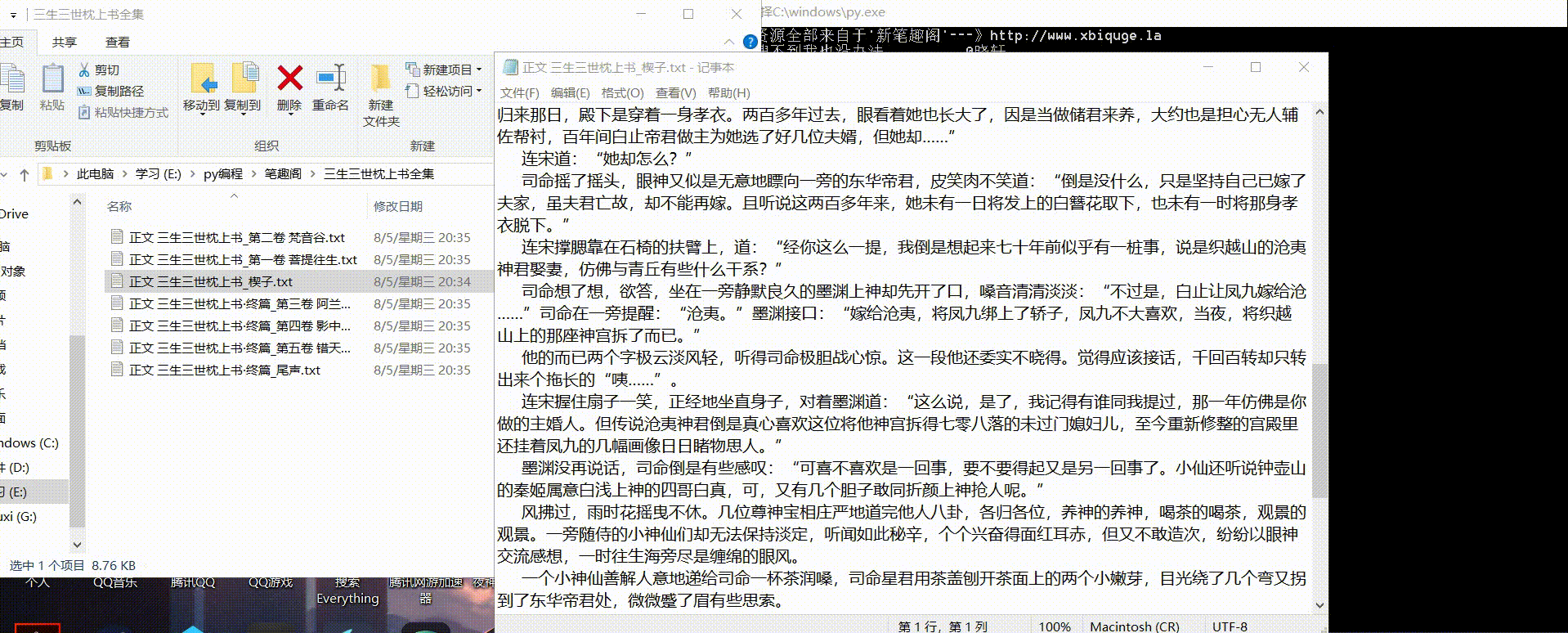
print('搜索结果:')
for num,book, author in zip(range(1, len(books)+1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









