







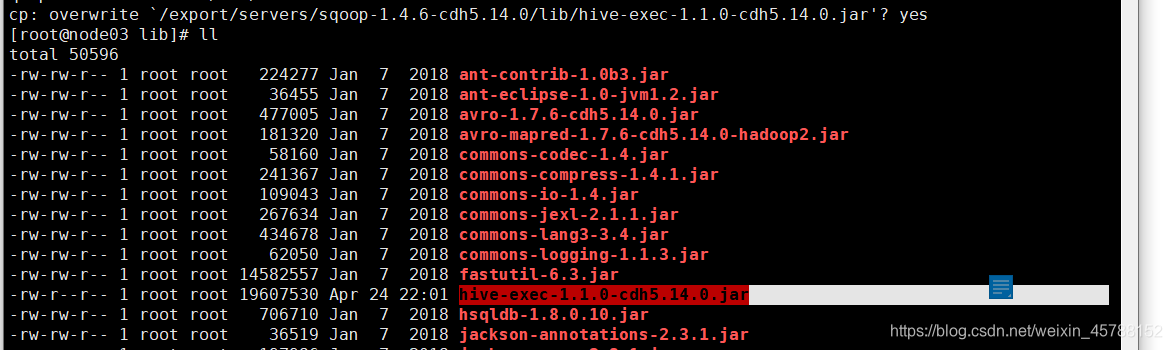
第一步:拷贝jar包
将我们mysql表当中的数据直接导入到hive表中的话,我们需要将hive的一个叫做hive-exec-1.1.0-cdh5.14.0.jar的jar包拷贝到sqoop的lib目录下
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/hive-exec-1.1.0-cdh5.14.0.jar /export/servers/sqoop-1.4.6-cdh5.14.0/lib/
第二步:准备hive数据库与表
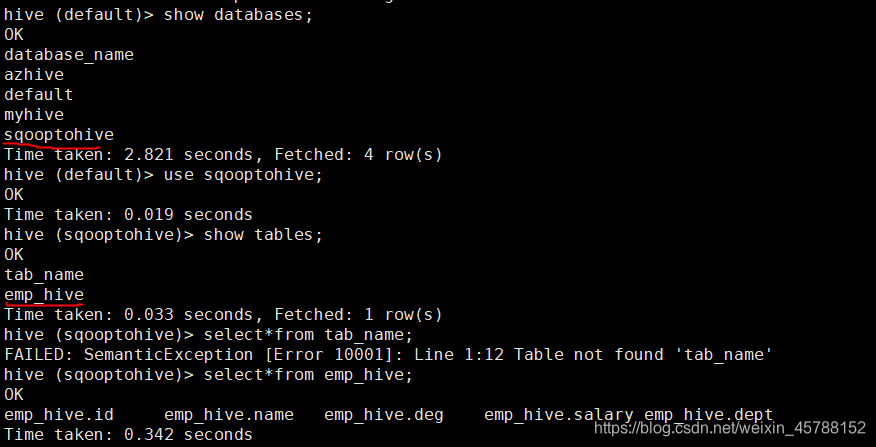
将我们mysql当中的数据导入到hive表当中来
hive (default)> create database sqooptohive;
hive (default)> use sqooptohive;
hive (sqooptohive)> create external table emp_hive(id int,name string,deg string,salary int ,dept string) row format delimited fields terminated by ‘\001’;
第三步:开始导入
bin/sqoop import --connect jdbc:mysql://192.168.2.169/userdb --username root --password 123456 --table emp --fields-terminated-by ‘\001’ --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --delete-target-dir --m 1
[root@node03 sqoop-1.4.6-cdh5.14.0]# bin/sqoop import --connect jdbc:mysql://192.168.2.169/userdb --username root --password 123456 --table emp --fields-terminated-by '\001' --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --delete-target-dir --m 1
Warning: /export/servers/sqoop-1.4.6-cdh5.14.0/bin/../../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /export/servers/sqoop-1.4.6-cdh5.14.0/bin/../../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /export/servers/sqoop-1.4.6-cdh5.14.0/bin/../../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
20/04/24 22:06:50 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.14.0
20/04/24 22:06:50 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
20/04/24 22:06:50 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
20/04/24 22:06:50 INFO tool.CodeGenTool: Beginning code generation
20/04/24 22:06:51 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
20/04/24 22:06:51 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
20/04/24 22:06:51 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /export/servers/hadoop-2.6.0-cdh5.14.0
Note: /tmp/sqoop-root/compile/46dba8b72f286bb1019f26093dcdcbda/emp.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
20/04/24 22:06:52 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/46dba8b72f286bb1019f26093dcdcbda/emp.jar
20/04/24 22:06:53 INFO tool.ImportTool: Destination directory emp deleted.
20/04/24 22:06:53 WARN manager.MySQLManager: It looks like you are importing from mysql.
20/04/24 22:06:53 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
20/04/24 22:06:53 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
20/04/24 22:06:53 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
20/04/24 22:06:53 INFO mapreduce.ImportJobBase: Beginning import of emp
20/04/24 22:06:53 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
20/04/24 22:06:53 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
20/04/24 22:06:53 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.247.101:8032
20/04/24 22:06:55 INFO db.DBInputFormat: Using read commited transaction isolation
20/04/24 22:06:55 INFO mapreduce.JobSubmitter: number of splits:1
20/04/24 22:06:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1587695816383_0007
20/04/24 22:06:55 INFO impl.YarnClientImpl: Submitted application application_1587695816383_0007
20/04/24 22:06:55 INFO mapreduce.Job: The url to track the job: http://node01:8088/proxy/application_1587695816383_0007/
20/04/24 22:06:55 INFO mapreduce.Job: Running job: job_1587695816383_0007
20/04/24 22:07:02 INFO mapreduce.Job: Job job_1587695816383_0007 running in uber mode : true
20/04/24 22:07:02 INFO mapreduce.Job: map 0% reduce 0%
20/04/24 22:07:04 INFO mapreduce.Job: map 100% reduce 0%
20/04/24 22:07:04 INFO mapreduce.Job: Job job_1587695816383_0007 completed successfully
20/04/24 22:07:04 INFO mapreduce.Job: Counters: 32
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=0
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=100
HDFS: Number of bytes written=181103
HDFS: Number of read operations=128
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=0
TOTAL_LAUNCHED_UBERTASKS=1
NUM_UBER_SUBMAPS=1
Total time spent by all map tasks (ms)=1570
Total vcore-milliseconds taken by all map tasks=0
Total megabyte-milliseconds taken by all map tasks=0
Map-Reduce Framework
Map input records=5
Map output records=5
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
CPU time spent (ms)=1100
Physical memory (bytes) snapshot=368181248
Virtual memory (bytes) snapshot=3088977920
Total committed heap usage (bytes)=275251200
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=396
20/04/24 22:07:04 INFO mapreduce.ImportJobBase: Transferred 176.8584 KB in 11.8624 seconds (14.9091 KB/sec)
20/04/24 22:07:04 INFO mapreduce.ImportJobBase: Retrieved 5 records.
20/04/24 22:07:04 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1
20/04/24 22:07:04 WARN hive.TableDefWriter: Column create_time had to be cast to a less precise type in Hive
20/04/24 22:07:04 WARN hive.TableDefWriter: Column update_time had to be cast to a less precise type in Hive
20/04/24 22:07:04 INFO hive.HiveImport: Loading uploaded data into Hive
20/04/24 22:07:05 ERROR tool.ImportTool: Import failed: java.io.IOException: Cannot run program "hive": error=2, No such file or directory
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at java.lang.Runtime.exec(Runtime.java:620)
at java.lang.Runtime.exec(Runtime.java:528)
at org.apache.sqoop.util.Executor.exec(Executor.java:76)
at org.apache.sqoop.hive.HiveImport.executeExternalHiveScript(HiveImport.java:382)
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:337)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:530)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:621)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
Caused by: java.io.IOException: error=2, No such file or directory
at java.lang.UNIXProcess.forkAndExec(Native Method)
at java.lang.UNIXProcess.<init>(UNIXProcess.java:247)
at java.lang.ProcessImpl.start(ProcessImpl.java:134)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1029)
... 14 more
You have new mail in /var/spool/mail/root
[root@node03 sqoop-1.4.6-cdh5.14.0]#
出错点
20/04/24 22:07:05 ERROR tool.ImportTool: Import failed: java.io.IOException: Cannot run program “hive”: error=2, No such file or directory
可是刚才已经创建了emp_hive,为什么会出错?
解决方:
为sqoop配置你使用的hive环境
具体步骤如下:
1、找到/export/servers/sqoop-1.4.6-cdh5.14.0/conf/
的sqoop-env-template.sh 文件,将这个文件重命名为sqoop-env.sh ;
2、编辑sqoop-env.sh 文件,将你的hive的安装目录配上就OK。
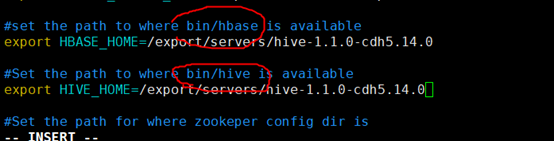
此前hive目录搭配到hbase,所以错了
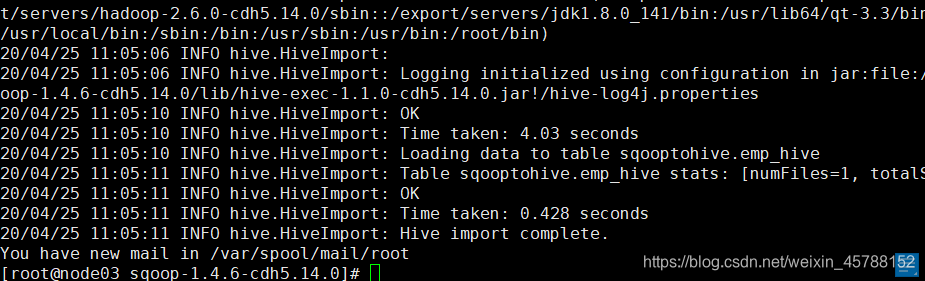
修改过后,成功运行














 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









