







过拟合与欠拟合的理解
一、什么是过拟合,欠拟合?
1.过拟合:学习器把训练样本学得"太好了",很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降,这就是过拟合。
换一种说法就是模型过度拟合,在训练集(training set)上表现好,但是在测试集上效果差,也就是说在已知的数据集合中非常好,但是在添加一些新的数据进来训练效果就会差很多,造成这样的原因是考虑影响因素太多,超出自变量的维度过于多了。
我们用一个图来对比看一下:
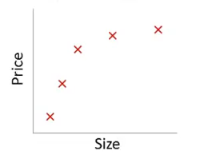
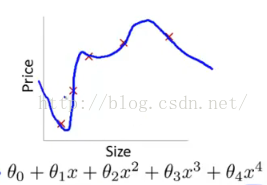
左图表示size和price的关系,而右图可以看出训练集拟合的太好了,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差。
2.欠拟合:就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
我们用图来看一下:
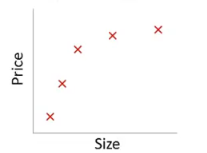
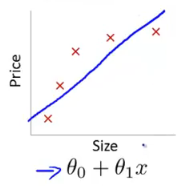
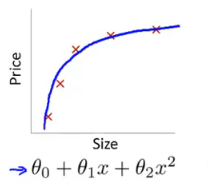
上面的图表示size和prize的关系,左下图就是表现除了欠拟合的现象,对于训练集特征学习的欠缺,所以不适于用其他数据集的判断,右下图就是可以很高的拟合上图的数据了。
从上面我们引出一个泛化能力的名词,解释一下
泛化能力:是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。通常期望经训练样本训练的网络具有较强的泛化能力,也就是对新输入给出合理响应的能力。应当指出并非训练的次数越多越能得到正确的输入输出映射关系。网络的性能主要用它的泛化能力来衡量。
为了方便更加直观的理解过拟合与欠拟合,做一个表格来看:
| 训练集上的表现 | 测试集上的表现 | 结论 |
|---|---|---|
| 不好 | 不好 | 欠拟合 |
| 好 | 不好 | 过拟合 |
| 好 | 好 | 适度拟合 |
二、过拟合产生的原因
-
训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
-
训练集和测试集特征分布不一致;
-
样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
-
权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了。而欠拟合则通常是由于学习能力低下而造成的。
三、处理过拟合
过拟合是无法彻底避免的,我们所能做的只是“缓解”。
-
重新清理数据
导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。 -
增大数据的训练量
还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。这是解决过拟合最有效的方法,只要给足够多的数据,让模型[训练到]尽可能多的[例外情况],它就会不断修正自己,从而得到更好的结果。
-
交叉检验
通过交叉检验得到较优的模型参数; -
正则化
正则化方法包括L0正则、L1正则和L2正则,而正则一般是在目标函数之后加上对于的范数。L0正则化的值是模型参数中非零参数的个数。
L1正则化表示各个参数绝对值之和。
L2正则化标识各个参数的平方的和的开方值。我们一把采用L1正则或L2正则。
我们先讨论一下:
- 实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据效果可能很差。另一个好处是参数变少可以使整个模型获得更好的可解释性。 - 参数越小值代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢?这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。
- 实现参数的稀疏有什么好处吗?
正则化的两种方式
1. L1正则化(Lasso)
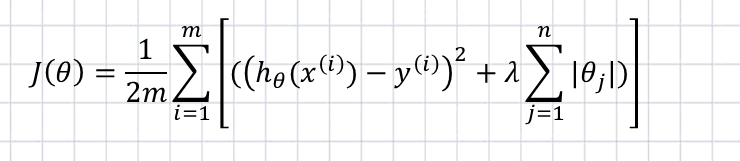
2. L2正则化(Ridge)
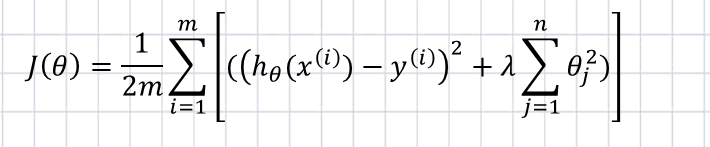
3.L1正则和L2正则的区别:
1.L1是模型的各个参数的绝对值之和
2.L2是模型各个参数的平方和的开方值
3.L1会趋向于产量少量的特征,而其他的特征都是0,因为最优的参数值很大概率会出现在坐标轴上,导致某一维的权重为0,产生稀疏权重矩阵.
4.L2会选择更多的特征,这些特征都会接近于0,最优的参数值很小概率出现在坐标轴上,因此每一维都不会是0,最小化||W||时,就会使每一次趋近于0.
范数
1. 范数的定义
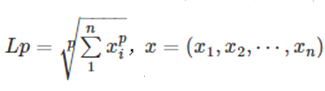
2.三种范数的不同
L0范数是指向量中非零元素的个数。
如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0即让参数W是稀疏的。
L1范数是指向量中各个元素绝对值之和
L1范数也叫“稀疏矩阵算子”。为什么L1范数会使权值稀疏?可以说是:它是L0范数的最优凸近似。
为什么L0和L1都可以实现稀疏,但常用的为L1?
因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。
所以综上来看,L1范数和L0范数可以实现稀疏,但是L1因具有比L0更好的优化求解特性而被广泛应用。
L2范数是指向量元素绝对是的平方和再开平方
它有两个美称,在回归里面,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减”(weight decay)。 weight decay还有一个好处,它使得目标函数变为凸函数,梯度下降法和L-BFGS都能收敛到全局最优解。
我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。
四、深度理解过拟合和欠拟合
偏差是指我们忽略了多少数据,而方差是指我们的模型对数据的依赖程度。
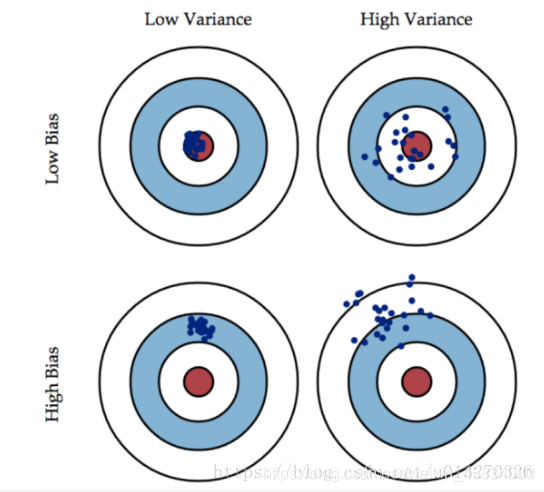
- bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。
过拟合模型表现为在训练集上具有高方差和低偏差(对应右上图)。它使得模型变得复杂,增加了模型的参数,比较容易过拟合。 - varience描述的是样本上训练出来的模型在测试集上的表现,也就是看在测试集上表现的好不好。
高偏差和低方差的情况(对应左下图)。这种情况要简化模型,减少模型的参数,这样容易出现欠拟合。
过拟合模型表现为在训练集上具有高方差和低偏差。
方差是模型响应训练数据而变化的程度。
偏差是方差的另一面,因为它代表了我们对数据做出的假设的强度。
总结到目前为止:偏差是指我们忽略了多少数据,而方差是指我们的模型对数据的依赖程度。在任何建模中,总是会在偏差和方差之间进行权衡,当我们建立模型时,我们会尝试达到最佳平衡。偏差与方差适用于任何模型,从最简单到最复杂,是数据科学家理解的关键概念!
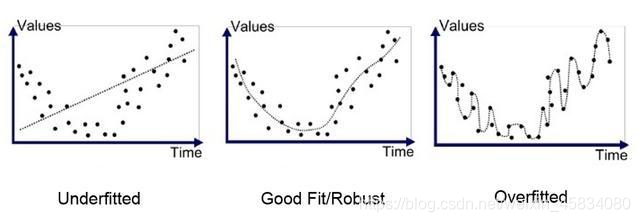
欠拟合(高偏差,低方差)与过拟合(低偏差,高方差)的图
总结一下:
- 过拟合:过分依赖训练数据
- 欠拟合:未能学习训练数据中的关系
- 高方差:模型根据训练数据显著变化
- 高偏差:对模型的假设不够导致忽略训练数据
- 过拟合和欠拟合导致测试集的泛化性差
- 一个验证集模型校正可以防止过拟合














 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









