






爬虫是什么?
“网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。”(就是获取信息)
xPath的常用路径表达式
-
nodename(节点名称):表示选择该节点的所有子节点
-
“/”:表示选择根节点
-
“//”:表示选择任意位置的某个节点
-
“@”: 表示选择某个属性
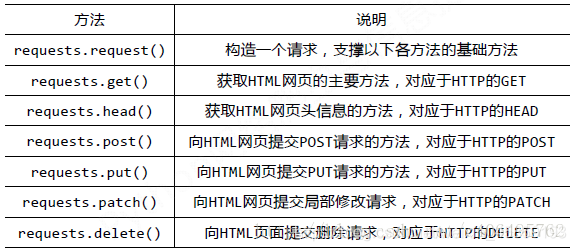
requests库常用方法
爬虫的步骤
1.目标url 网站
2.发送请求
3.解析数据
4.保存数据
所以把步骤搞明白那么爬虫就不会那么的复杂了

import requests
from lxml import etree
url='https://movie.douban.com/chart'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
#发送请求
data = requests.get(url,headers=headers).content.decode()
#解析数据
html=etree.HTML(data)
n=1
#获取图片地址
novel_url_list=html.xpath('//div[@id="content"]//a[@class="nbg"]/img/@src')
#保存图片
for novel_url in novel_url_list:
response = requests.get(novel_url,headers=headers)
print('第%d个图片打印成功'%n)
n=n+1
#保存的名字
file_name = novel_url.split('/')[-1]
with open(file_name,'wb')as f:
f.write(response.content)

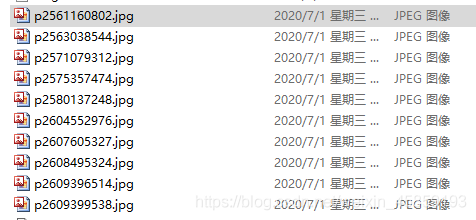
总结
不忘初心,方得始终.努力一定能成功,多敲多练才是真理.














 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









