







一、背景建模:帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同,该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。

帧差法非常简单,但是会引入噪音和空洞问题。
二、混合高斯模型
1、在进行前景检测前,先对背景进行训练,对图像中每个背景采用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应,然后在测试阶段,对新来的像素进行GMM匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。
由于整个过程GMM模型在不断更新学习中所以对动态背景有一定的鲁棒性(在下面的小插曲中会介绍),最后通过对一个有树枝摇摆的动态背景进行前景检测,取得了较好的效果。
在视频中对于像素点的变化情况应当是符合高斯分布:
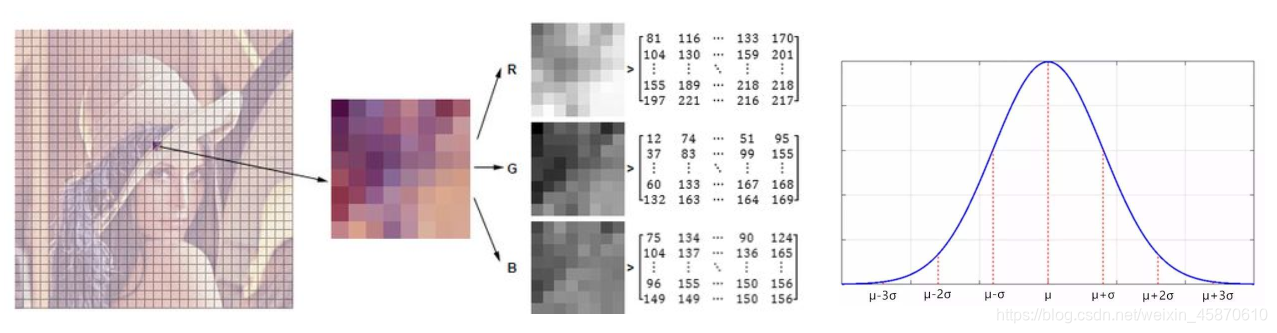
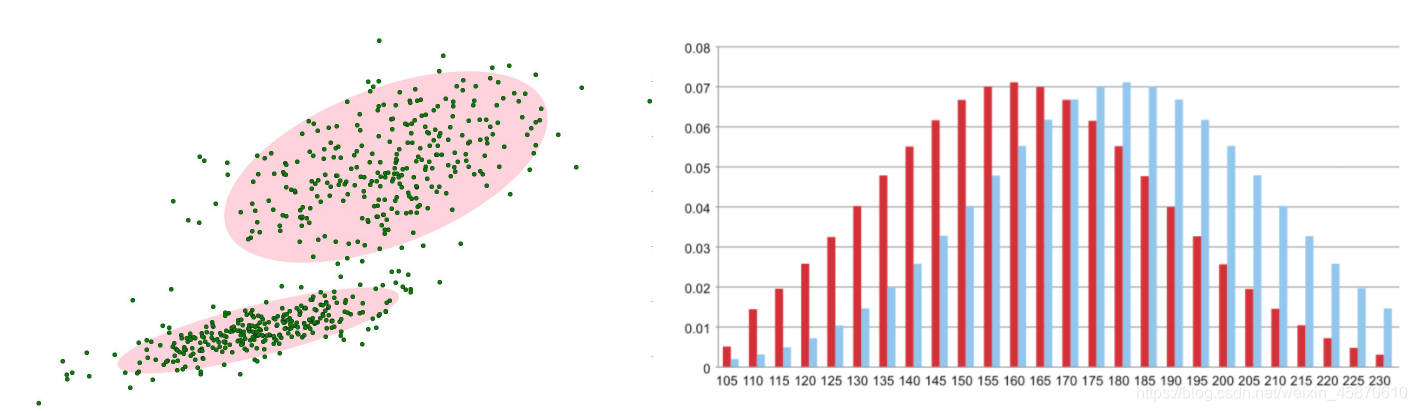
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
小插曲:
Huber从稳健统计的角度系统地给出了鲁棒性3个层面的概念:
1)是模型具有较高的精度或有效性,这也是对于机器学习中所有学习模型的基本要求;
2)是对于模型假设出现的较小偏差,只能对算法性能产生较小的影响; 主要是:噪声(noise)
3)是对于模型假设出现的较大偏差,不可对算法性能产生“灾难性”的影响。 主要是:离群点(outlier)

2、混合高斯模型学习方法:
(1)首先初始化每个高斯模型矩阵参数。
(2)取视频中T帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布。
(3)当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新。
(4)如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。
3、混合高斯模型测试方法:
在测试阶段,对新来像素点的值与混合高斯模型中的每一个均值进行比较,如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。这样就形成了一副前景二值图。

三、代码实现
(我会在代码注释那里简单介绍每一部分的作用,是为了实现什么,具体的代码理解在代码呈现的下一步)
import numpy as np
import cv2
#打开目标测试视频
cap = cv2.VideoCapture('C:/Users/xiaoyan/opencv-picture/test.avi') #注意视频的文件类型,右击属性那里查看
#形态学操作需要使用
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
#创建混合高斯模型用于背景建模
fgbg = cv2.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
#形态学开运算去噪点
fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)
#寻找视频中的轮廓
ret,contours, hierarchy = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
#计算各轮廓的周长
perimeter = cv2.arcLength(c,True)
if perimeter > 188:
#找到一个直矩形(不会旋转)
x,y,w,h = cv2.boundingRect(c)
#画出这个矩形
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
cv2.imshow('fgmask', fgmask)
k = cv2.waitKey(10) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
1、cap = cv2.VideoCapture(‘C:/Users/xiaoyan/opencv-picture/test.avi’)
1)VideoCapture()中参数是视频文件路径则打开视频,如上.
2)参数是0,表示打开笔记本的内置摄像头.如下:
#打开摄像头
camera = cv2.VideoCapture(0)
2、kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3))
1)cv2.getStructuringElement这个函数的第一个参数表示内核的形状,有三种形状可以选择:
矩形:MORPH_RECT;
交叉形:MORPH_CROSS;
椭圆形:MORPH_ELLIPSE;
第二和第三个参数分别是内核的尺寸以及锚点的位置,
一般在调用erode以及dilate函数之前,先定义一个Mat类型的变量来获得getStructuringElement函数的返回值。
对于锚点的位置,有默认值Point(-1,-1),表示锚点位于中心点。element形状唯一依赖锚点位置,其他情况下,锚点只是影响了形态学运算结果的偏移。
2)定义结构元素:
形态学处理的核心就是定义结构元素,在OpenCV-Python中,可以使用其自带的getStructuringElement函数,也可以直接使用NumPy的ndarray来定义一个结构元素。

3、BackgroundSubtractorMOG2
1)这是以高斯混合模型为基础的背景/前景分割算法,这个算法的一个特点是它为每 一个像素选择一个合适数目的高斯分布,
这样就会对由于亮度等发生变化引起的场景变化产生更好的适应
2)我们需要创建一个背景对象。但在这里我们我们可以选择是否检测阴影。如果 detectShadows = True(默认值),它就会检测并将影子标记出来,但是这样做会降低处理速度。影子会被标记为灰色。
BackgroundSubtractorMOG2算法相对于BackgroundSubtractorMOG的两个改进点 :
a.阴影检测
b.速度快了一倍
想要了解BackgroundSubtractorMOG的朋友可以参考链接https://cloud.tencent.com/developer/article/1459471
4、ret,frame = cap.read()
cap.read()按帧读取视频,ret,frame是获cap.read()方法的两个返回值。
其中ret是布尔值,如果读取帧是正确的则返回True,如果文件读取到结尾,它的返回值就为False。frame就是每一帧的图像,是个三维矩阵。
5、k = cv2.waitKey(10) & 0xff
1)cv2.waitKey(1),waitKey()方法本身表示等待键盘输入,
参数是1,表示延时1ms切换到下一帧图像,对于视频而言;
参数为0,如cv2.waitKey(0)只显示当前帧图像,相当于视频暂停;
参数过大如cv2.waitKey(1000),会因为延时过久而卡顿感觉到卡顿。
2)cv2.waitkey(delaytime)------->returnvalue
在delaytime时间内,按键盘, 返回所按键的ASCII值;若未在delaytime时间内按任何键, 返回-1;其中,dalaytime: 单位ms;
当delaytime为0时,表示forever,永不退回, 当按esc键时,因为esc键ASCII值为27,所有returnvalue的值为27, 一般用这个机制实现在delaytime内正常退出。
如果播放的是一段视频,那么视频会在经过dalaytime后停止播放。
0xff:0xff是一个位掩码,十六进制常数,二进制值为11111111, 它将左边的24位设置为0,把返回值限制在在0和255之间
6、cap.release()
调用release()释放摄像头
7、cv2.destroyAllWindows()
调用destroyAllWindows()关闭所有图像窗口

















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











