






16. MySQL数据库
16.1 什么是数据库?
数据库是按照数据结构来组织、存储和管理数据的仓库。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。数据库是以一定的方式存储在一起、能与多个用户共享、具有尽可能小的冗余度、与应用层序彼此独立的数据集合,可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行增删改查等操作。
16.2 数据库的分类以及其含义?常见的数据库有哪些?
数据库分为两大类,关系型数据库和非关系型数据库。
关系数据库,是建立在关系数据库模型基础上的数据库,借助于集合代数等概念和方法来处理数据库中的数据,同时也是一个被组织成一组拥有正式描述性的表格,该形式的表格作用的实质是装载着数据项的特殊收集体,这些表格中的数据能以许多不同的方式被存取或重新召集而不需要重新组织数据库表格。关系数据库的定义造成元数据的一张表格或造成表格、列、范围和约束的正式描述。每个表格(有时被称为一个关系)包含用列表示的一个或更多的数据种类。 每行包含一个唯一的数据实体,这些数据是被列定义的种类。当创造一个关系数据库的时候,你能定义数据列的可能值的范围和可能应用于那个数据值的进一步约束。而SQL语言是标准用户和应用程序到关系数据库的接口。其优势是容易扩充,且在最初的数据库创造之后,一个新的数据种类能被添加而不需要修改所有的现有应用软件。
主流的关系型数据库有oracle、db2、Mysql、sqlserver、sybase等。
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL( Structured QueryLanguage,结构化查询语言),是由Carlo Storzzi最早开发的一个轻量、开源、不兼容SQL 功能的关系型数据库,2009 年,在一次分布式开源数据库的讨论会上,再次提出了NOSQL 的概念,此时NOSQL主要是指I非关系型、分布式、不提供ACID (数据库事务处理的四个本要素)的数据库设计模式。同年,在亚特兰大举行的“NO:SQL(east)”讨论会上,对NOSQL 最普遍的定义是“非关联型的”,强调Key-Value 存储和文档数据库的优点,而不是单纯地反对RDBMS,至此,NoSQL 开始正式出现在世人面前。
常见的非关系型数据库有redis、mongoDB、CouchDB等。
16.3 MySQL数据库服务器、数据库和表之间的关系?
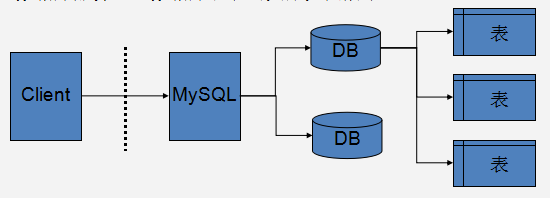
数据库服务器就是在机器上安装的数据库管理程序,服务器、数据库与表之间的关系是通常情况下是一个机器上面可以有多个数据库,一个应用程序对应一个数据库,在数据库中可以有多个表,用来存放数据。关系如图所示:
16.4 MySQL服务器下载和安装?
下载地址:https://downloads.mysql.com/archives/community/
安装过程中的配置就不详细写了,基本上都是一些默认的配置,需要将配置中的用户名以及密码记清楚。
在安装过程中会遇到最后一步时点击finish后无响应,针对这个问题有以下解决方案:
这种情况一般是你以前安装过MySQL数据库服务项被占用了。
解决方法:
1. 卸载MySQL
2. 删除安装目录及数据存放目录
3. 在注册表(regedit)查询mysql,全部删除
注意的是注册表 cmd -> regedit
1.HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\Eventlog\Application\MySQL 目录
2.HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\Eventlog\Application\MySQL 目录
3.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application\MySQL 目录
4.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControl001\Services\MYSQL 目录
5.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControl002\Services\MYSQL 目录
6.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\MYSQL 目录
4. 在c盘查询MySQL,全部删除 ;一般是在ProgramData文件夹下(该文件是隐藏的,需要设置为显示隐藏文件)和winbdows文件夹下
5. 重新安装就好了
16.5 SQL语言
a. 基本数据库操作语言
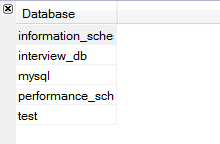
查看数据库服务器上的所有数据库:show databases
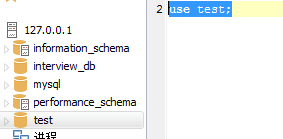
选中自己需要使用的数据库: use database
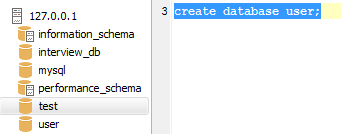
创建数据库: create database [if not exist] db_name
数据库的修改: alter database db_name
(修改了数据库的编码集)
数据库的删除: drop database db_name
b. MySQL常用数据类型
字符串型 VARCHAR、CHAR
大数据类型 BLOB、TEXT
数值型 TINYINT 、SMALLINT、INT、BIGINT、FLOAT、DOUBLE
逻辑性 BIT
日期型 DATE、TIME、DATETIME、TIMESTAMP
c. MySQL中数据库表的基本操作语句和定义表的字段的约束
创建表: create table tb_name
(
field1 datatype,
field2 datatype,
field3 datatype
);

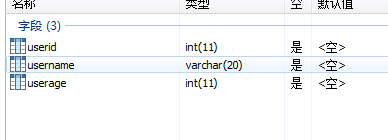
注意:1.创建表前,要先使用use db语句使用库。
2.创建表时,要根据需保存的数据创建相应的列,并根据数据的类型定义相应的列类型
定义单表字段的约束:
定义主键约束-----primary key:不允许为空,不允许重复
删除主键-----alter table tb_name drop primary key
主键自动增长-----auto_increment
定义唯一约束-----unique
定义非空约束-----not null

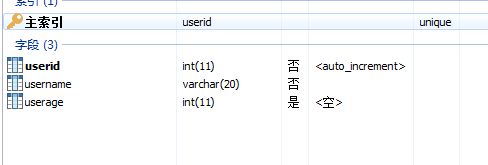
表的结构修改:alter table tb_name


查看表结构: show tables
删除表: drop table tb_name
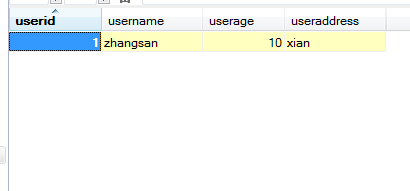
d. insert语句向表中加数据
insert语句结构:INSERT INTO table [(column [, column...])] VALUES (value [, value...]);
1.插入的数据应与字段的数据类型相同。
2.数据的大小应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中。
3.在values中列出的数据位置必须与被加入的列的排列位置相对应。
4.字符和日期型数据应包含在单引号中。
5.插入空值:不指定或insert into table value(null)
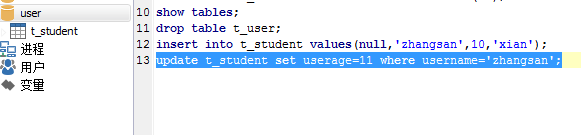
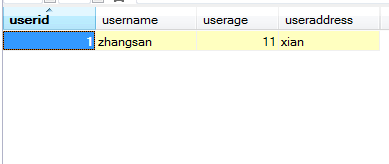
e. update语句修改表中数据
语句结构:
UPDATE tbl_name
SET col_name1=expr1 [, col_name2=expr2 ...]
[WHERE where_definition]
1.UPDATE语法可以用新值更新原有表行中的各列。
2.SET子句指示要修改哪些列和要给予哪些值。
3.WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。
f. delete语句删除表中数据
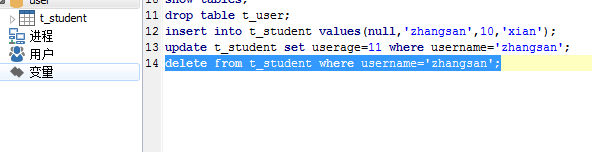
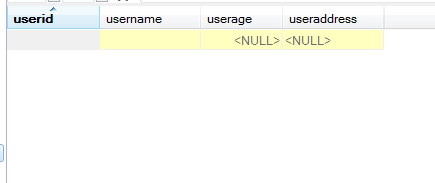
语句结构:delete from tbl_name [WHERE where_definition]
1.如果不使用where子句,将删除表中所有数据。
2.Delete语句不能删除某一列的值(可使用update)
3.使用delete语句仅删除记录,不删除表本身。如要删除表,使用drop table语句。
4.同insert和update一样,从一个表中删除记录将引起其它表的参照完整性问题,在修改数据库数据时,头脑中应该始终不要忘记这个潜在的问题。
16.6 select语句
a. 基本select语句
语句结构:SELECT [DISTINCT] *|{column1, column2. column3..} FROM table;
1.select 指定查询哪些列的数据。
2.column指定列名。
3.*号代表查询所有列。
4.from指定查询哪张表。
5.DISTINCT可选,指显示结果时,是否剔除重复数据
b. select语句中使用表达式对查询的列进行运算
语句结构:SELECT *|{column1|expression, column2|expression,..} FROM table;
例如:
统计每个学生的总分
SELECT * ,(chinese+math+english) AS 总分 FROM exam;
c. select语句中使用as语句
语句结构:SELECT column as 别名 from 表名;
例如:
使用别名表示学生分数
SELECT id,NAME 名字, chinese 语文,math 数学, english 英语 FROM exam;
d. 使用where添加查询条件
在where子句中经常使用的运算符
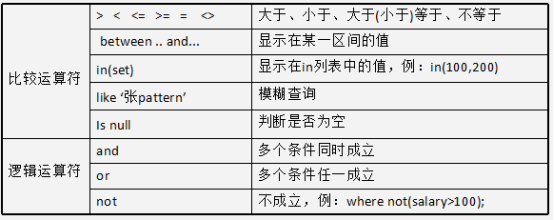
注意:Like语句中,% 代表零个或多个任意字符,_ 代表一个字符,例first_name like ‘_a%’;
e. 使用order by子句排序查询结果
语句结构:SELECT column1, column2. column3.. FROM table order by column asc|desc;
1.Order by 指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的列名。
2.Asc 升序、Desc 降序
3.ORDER BY 子句应位于SELECT语句的结尾。
f. SQL聚合函数
1.Count(列名)返回某一列,行的总数
语句结构:Select count(*)|count(列名) from tablename [WHERE where_definition]
2.Sum函数返回满足where条件的行的和
语句结构:Select sum(列名){,sum(列名)…} from tablename [WHERE where_definition]
3.AVG函数返回满足where条件的一列的平均值
语句结构:Select avg(列名){,avg(列名)…} from tablename [WHERE where_definition]
4.Max/min函数返回满足where条件的一列的最大/最小值
语句结构:Select max(列名)/min(列名) from tablename [WHERE where_definition]
g. 分页查询
语句结构:Select [*/col] from tablename limit 参数1 , 参数
参数1---每页数据的起始值 (当前页码 - 1)* 每页记录数
参数2--每页记录数
h. 多表查询
外键约束的定义
语句结构:foreign key(ordersid) references orders(id)
表与表之间的关系
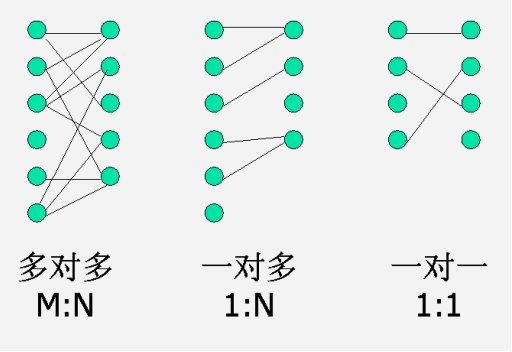
一对一主键关联设计
--创建用户信息表
create table t_user(
u_id int primary key auto_increment,
u_name varchar(20),
u_age int,
u_sex bit,
u_address varchar(30),
foreign key t_user(u_id) references t_card(c_id)
);
--创建用户省份证信息表
create table t_card(
c_id int primary key auto_increment,
c_number varchar(18),
c_arg varchar(10),
c_year int
);
--向用户省份证信息表中添加测试数据
insert into t_card values(null,'123456789012345678','陕西.西安',10);
insert into t_card values(null,'098765432112345678','陕西.铜川',10);
--向用户信息表中添加测试数据
insert into t_user values(null,'zhangsan',23,true,'长安县');
insert into t_user values(null,'lisi',24,false,'雁塔区');一对一外键关联设计
--创建用户信息表
create table t_user(
u_id int primary key auto_increment,
u_name varchar(20),
u_age int,
u_sex bit,
u_address varchar(30),
card_id int unique,
foreign key t_user(card_id) references t_card(c_id)
);
--创建用户省份证信息表
create table t_card(
c_id int primary key auto_increment,
c_number varchar(18),
c_arg varchar(10),
c_year int
);
--向用户省份证信息表中添加测试数据
insert into t_card values(null,'123456789012345678','陕西.西安',10);
insert into t_card values(null,'098765432112345678','陕西.铜川',10);
--向用户信息表中添加测试数据
insert into t_user values(null,'zhangsan',23,true,'长安县',1);
insert into t_user values(null,'lisi',24,false,'雁塔区',2);一对多关联设计
--注意:外键要设计在多方维护
--创建一个班级表
create table t_class(
c_id int primary key auto_increment,
c_number varchar(10),
c_name varchar(10)
);
--向班级表添加测试数据
insert into t_class values(null,'J20180903','javaEE');
insert into t_class values(null,'A20181010','Android');
insert into t_class values(null,'I20181111','IOS');
--创建学生表
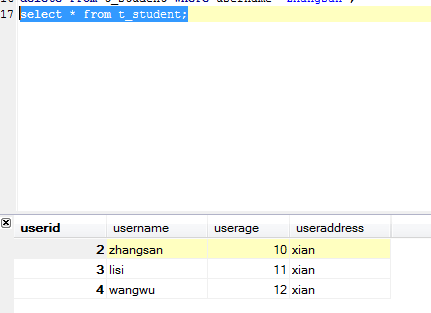
create table t_student(
s_id int primary key auto_increment,
s_name varchar(20),
s_age int,
s_sex bit,
s_address varchar(30),
class_id int,
foreign key t_student(class_id) references t_class(c_id)
);
--向学生表添加测试数据
insert into t_student values(null,'zhangsan',23,true,'西安',1);
insert into t_student values(null,'lisi',24,false,'北京',2);
insert into t_student values(null,'wangwu',25,true,'上海',3);
insert into t_student values(null,'zhangsansan',26,true,'西安南',1);
insert into t_student values(null,'lisisi',27,false,'北京北',2);
insert into t_student values(null,'wangwuwu',28,true,'上海东',3);多对多关联设计
--注意:需要有一个中间表来维护关联关系,保存的是不同表的主键
--创建角色表
create table t_role(
r_id int primary key auto_increment,
r_name varchar(10),
r_desc varchar(30)
);
--创建项目组表
create table t_group(
g_id int primary key auto_increment,
g_name varchar(20),
g_desc varchar(30)
);
--创建中间表维护关联关系
create table t_rolegroup(
z_id int primary key auto_increment,
role_id int,
group_id int
);
--通过修改表结构的方式添加外键
alter table t_rolegroup add constraint fk1 foreign key (role_id) references t_role(r_id);
alter table t_rolegroup add constraint fk2 foreign key (group_id) references t_group(g_id);
--向角色表中添加测试数据
insert into t_role values(null,'java程序员','负责开发java程序');
insert into t_role values(null,'测试员','负责测试程序');
--向项目组表中添加测试数据
insert into t_group values(null,'CRM组','负责开发CRM系统');
insert into t_group values(null,'ERP组','负责开发ERP系统');
--向中间表中添加测试数据
insert into t_rolegroup values(null,1,1);
insert into t_rolegroup values(null,1,2);
insert into t_rolegroup values(null,2,1);
insert into t_rolegroup values(null,2,2);子查询
就是将一个查询语句包含在另一个查询语句中,那么这个被包含的查询语句就是子查询语句。
1.单行子查询(> < >= <= = <>)
查询出高于10号部门的平均工资的员工信息
SELECT * FROM emp WHERE sal >(SELECT AVG(sal) FROM emp WHERE deptno=10 );
2.多行子查询(in not in any all)
查询出比10号部门任何员工薪资高的员工信息
SELECT * FROM emp WHERE sal > ANY(SELECT sal FROM emp WHERE deptno=10) AND deptno!=10;
3.多列子查询(实际使用较少)
和10号部门同名同工作的员工信息
SELECT * FROM emp WHERE (ename,job)IN(SELECT ename,job FROM emp WHERE deptno=10) AND deptno!=10;
4.select 后面接子查询
获取员工的名字和部门的名字
SELECT p.ename,d.dname FROM emp p,dept d WHERE p.deptno=d.deptno;
5.from 后面接子查询
查询emp表中经理信息
SELECT * FROM emp e,(SELECT DISTINCT mgr FROM emp) AS jingli WHERE e.empno=jingli.mgr;
6.where 后面接子查询
薪资高于10号部门平均工资的所有员工信息
SELECT * FROM emp WHERE sal>(SELECT AVG(sal) FROM emp WHERE deptno=10);
7. group by 后面接子查询
有哪些部门的平均工资高于30号部门的平均工资
SELECT deptno, AVG(sal) AS bumen FROM emp GROUP BY deptno HAVING bumen > (SELECT AVG(sal) FROM emp WHERE deptno=30);
16.7 联合查询
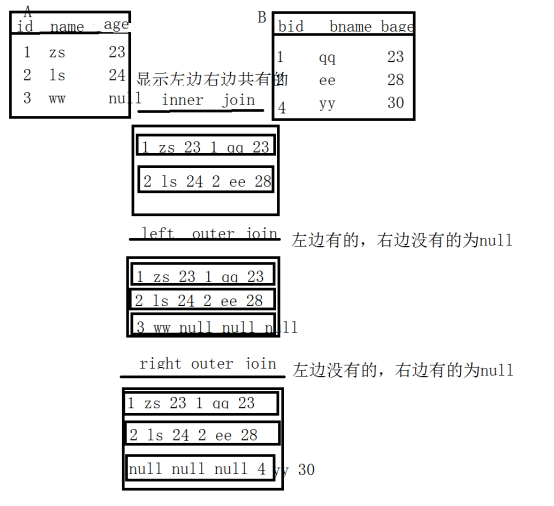
内连接查询 【inner join】
左连接查询 【left join】 左外连接查询 【left outer join】
右连接查询 【right join】 右外连接查询 【right outer join】
内连接与左连接和右连接查询的区别
--内连接:显示左边右边共有的
--左连接:左边有的,右边没有的为null
--右连接:右边有的,左边没有的为null
语句结构:
select [col1,col2...coln来自多张表【最好使用别名】]
from table1
inner join/
left outer join/left join/
right outer join/right join
table2
on table1.col = table2.col
where 查询条件














 7501
7501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









