









https://agibot-world.com/blog/agibot_go1.pdf
参考链接 2 微信公众号
AgiBot World Colosseo: Large-scale Manipulation Platform
for Scalable and Intelligent Embodied Systems
https://agibot-world.com/colosseo-contributors
human-in-the-loop 方法: 收集 一小组 演示,训练一个策略,部署得到的策略来评估数据可用性 的迭代循环。
〔 这里把 逆运动学(Inverse Kinematics) 和 逆动力学(Inverse Dynamics)混用了。〕
- 逆运动学(Inverse Kinematics)〔 生成轨迹(“去哪里”) 〕:解决机器人末端执行器(如机械臂的手爪)的位置和姿态规划问题。已知目标位置,计算各关节应达到的角度或位移。
- 逆动力学(Inverse Dynamics)〔 实现轨迹(“如何高效、稳定地到达”)〕:已知机器人的运动轨迹(位置、速度、加速度),计算各关节所需的力矩或力,以实现动态控制。
- 例如,工业机器人抓取零件时,逆运动学负责确定关节角度以到达抓取点;若抓取后需要高速运动或调整抓握力,则需逆动力学计算关节力矩以防止抖动或滑脱。
摘要
Abstract—We explore how scalable robot data can address real-world challenges for generalized robotic manipulation.
我们探索可扩展的机器人数据如何解决通用机器人操作的现实挑战。
Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets.
引入 AgiBot World,一个大型平台,包含 5 个部署场景,217 个任务中的超过 100 万条轨迹,与现有数据集相比,我们实现了数据规模的数量级增长。
Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution.
通过 human-in-the-loop 验证 的标准化的收集 pipeline 加速,AgiBot World 保证了高质量且多样化的数据分布。
It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition.
它可以从夹持器扩展到灵巧手和 用于精细技能学习的 visuo-tactile 传感器。
Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume.
建立在数据之上,我们介绍 Genie Operator-1 (GO-1),一种新的通才策略,它利用潜在动作表示来最大化数据利用率,并随着数据量的增加展示了可预测的性能扩展。
Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios.
在我们的数据集上预训练的策略比在 Open X-Embodiment 上训练的策略在域内和分布外场景下的平均性能提高了 30%。
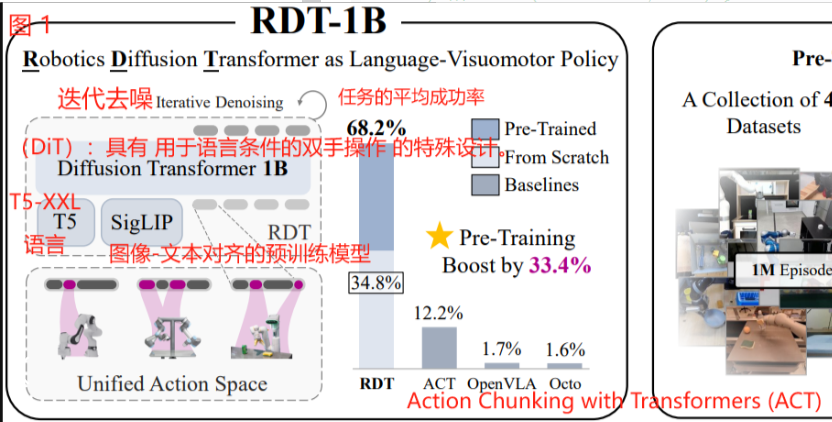
GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%.
GO-1 在现实世界的灵巧且 long-horizon 任务中表现出卓越的能力,在复杂任务中实现 超 60% 的成功率 〔 平均性能为 0.78。按照本文指标计算方式,只完成部分也会给一个 分数,和 0-1 制不一样。感觉完成部分这个不好量化,主观性较大 〕,比 之前的 RDT 方法 高出 32%。〔 ✅ RDT 方法 的局限性是?面向的任务类型是?RDT 拟解决可泛化双手操作中数据稀缺性和操作复杂性增加的挑战, 论文中并未提及 long-horizon 相关内容,RDT 限制 32 ≤ episodes 长度 ≤ 2048 〕
By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
通过开源数据集、工具和模型,我们旨在普及大规模、高质量机器人数据,推进对可扩展和通用智能的追求。
1. 引言
Manipulation is a cornerstone task in robotics, enabling the agent to interact with and adapt to the physical world.
操作是机器人技术的基石任务,使 agent 能够与物理世界互动并适应物理世界。
While significant progress has been made in general-purpose foundational models for natural language processing [1] and computer vision [2], robotics lags behind due to the difficulty of (high-quality) data collection.
虽然在自然语言处理[1]和计算机视觉[2]的通用基础模型方面取得了重大进展,但由于(高质量)数据收集的困难,机器人技术发展滞后。
In the controlled lab setting, simple tasks such as pick-and-place have been well studied [3], [4].
在受控的实验室环境中,简单的任务,如拾取并放置,已经得到了很好的研究。
Yet for the open-set real-world setting, tasks spanning from fine-grained object interaction, mobile manipulation to collaborative tasks, remains a formidable challenge [5].
然而,对于开集的现实世界环境,从细粒度对象交互、移动操作到协作任务的任务仍然是一个巨大的挑战。
These tasks require not only physical dexterity but also the ability to generalize across diverse environment and scenarios, a merit beyond the reach of current robotic systems.
这些任务不仅需要身体的灵活性,还需要可以泛化到不同的环境和场景的能力,这是目前机器人系统无法达到的优点。
The widely accepted reason is the lack of high-quality data—unlike images and text, which are abundant and standardized, robotic datasets suffer from fragmented clips due to heterogeneous hardware and unstandardized collection procedure, leading to low-quality and inconsistent outcome.
广泛接受的原因是缺乏高质量的数据 —— 与图像和文本不同,图像和文本是丰富且标准化的,机器人数据集由于异构的硬件和非标准化的收集过程而遭受碎片化,导致低质量和不一致的结果。
In this work we ask, how could we resolve the real-world complexity effectively by scaling up real-world robot data?
在这项工作中,我们问,我们如何通过扩展真实世界的机器人数据来有效地解决现实世界的复杂性?
Recent efforts, such as Open X-Embodiment (OXE) [6], have addressed by aggregating and standardizing existing datasets.
最近的一些努力,如 Open X-Embodiment (OXE)[6],通过聚集和标准化现有的数据集来解决问题。
Despite advancements on large-scale cross-embodiment learning, the resulting policy is constrained within naive, short-horizon tasks and can weakly generalize to out-of-domain scenarios [4].
尽管在大规模跨具身实例学习方面取得了进展,但所得到的策略受限于 naive, short-horizon 任务,仅能弱泛化到域外场景[4]。
DROID [7] collected expert data through crowd-sourcing from diverse real-life scenes.
DROID[7] 通过众包从各种真实生活场景中收集专家数据。
The absence of data quality assurance (with human feedback) and the reliance on a constrained hardware setup (i.e., featuring fixed, single-arm robots), limit its real-world applicability and broader effectiveness.
缺乏数据质量保证(带人类反馈)和依赖受限的硬件设置(即,以固定的单臂机器人为特点),限制了其在现实世界中的适用性和更广泛的有效性。
More recently, Lin et al. [8] explored scaling laws governing generalizability across intra-category objects and environments, albeit limited to a few simple, single-step tasks.
最近,Lin 等人探索了影响 各 类内物体和环境的可泛化性的 scaling laws,尽管仅限于一些简单的单步任务。
These efforts represent a notable advancement toward developing generalist policies, moving beyond the traditional focus on single-task learning within narrow domains [9], [3].
这些努力代表了开发通才策略的显著进步,超越了传统的专注于狭窄领域内的单一任务学习[9],[3]。
Nevertheless, existing robot learning datasets remain constrained by their reliance on short-horizon tasks in highly controlled laboratory environments, failing to adequately capture the complexity and diversity inherent in real-world manipulation tasks.
然而,现有的机器人学习数据集仍然受限于它们对 高度可控的实验室环境中 short-horizon 任务的依赖,未能充分捕捉现实世界操作任务中固有的复杂性和多样性。
To achieve general-purpose robotic intelligence, it is essential to develop datasets that scale in size and diversity while capturing real-world variability, supported by general-purpose humanoid robots for robust skill acquisition, a standardized data collection pipeline with assured quality, and carefully curated tasks reflecting real-world challenges.
为了实现通用机器人智能,至关重要的是开发 大小和多样性均扩展,同时捕获现实世界的可变性的数据集,由通用类人机器人提供稳健的技能获取支持,保证质量的标准化的数据收集 pipeline,以及反映现实世界挑战的精心策划的任务。
As depicted in Fig. 1, we introduce AgiBot World Colosseo, a full-stack large-scale robot learning platform curated for advancing bimanual manipulation in scalable and intelligent embodied systems.
如图 1 所示,我们介绍 agbot World Colosseo,一个全栈大型机器人学习平台,旨在推进可扩展且智能的具身系统中的双手操作。
A full-scale 4000-square-meter facility is constructed to represent five major domains-domestic, retail, industrial, restaurant, and office environment—all dedicated to high-fidelity data collection in authentic everyday scenarios.
一个 4000 平方米的全面设施,代表了 5 个主要领域 —— 家庭、零售、工业、餐厅和办公环境 —— 所有这些都致力于在真实的日常场景中高保真的数据收集。
With over 1 million trajectories collected from 100 real robots, AgiBot World offers unprecedented diversity and complexity.
AgiBot World 从 100 个真实机器人中收集了超过 100 万条轨迹,提供了前所未有的多样性和复杂性。
It spans over 100 real-world scenarios, addressing challenging tasks such as fine-grained manipulation, tool usage, and multi-robot synergistic collaboration.
它跨越了 100 多个现实场景,解决了诸如细粒度操作、工具使用和多机器人协同合作等具有挑战性的任务。
Unlike prior datasets, AgiBot World dataset collection is carried out with a fully standardized pipeline, ensuring high data quality and scalability, while incorporating human-in-the-loop verification to guarantee reliability.
与之前的数据集不同,AgiBot World 数据集的收集是通过完全标准化的 pipeline 进行的,确保了高数据质量和可扩展性,同时结合了 human-in-the-loop 验证 以确保可靠性。
Our hardware setup includes mobile base humanoid robots with whole-body control, dexterous hands, and visuo-tactile sensors, enabling rich, multimodal data collection.
我们的硬件设置包括移动基础人形机器人,具有全身控制,灵巧的手和 visuo-tactile 传感器,实现丰富的多模态数据收集。
Each episode is meticulously designed, featuring multiple camera views, depth information, camera calibration, and language annotations for both the overall task and each individual sub-steps.
每一个回合都是精心设计的,具有多个摄像机视图,深度信息,摄像机校准和整体任务和每个单独子步骤的语言标注。
This well-rounded hardware setup, combined with various long-horizon, real-world tasks, opens new avenues for developing next-generation generalist policies and fosters diverse future research in robotics.
这种全面的硬件设置,结合各种 long-horizon、现实世界的任务,为开发下一代通才策略开辟了新的途径,并促进了机器人技术的多样化未来研究。
—————— 补充 Start
—————— 补充 End
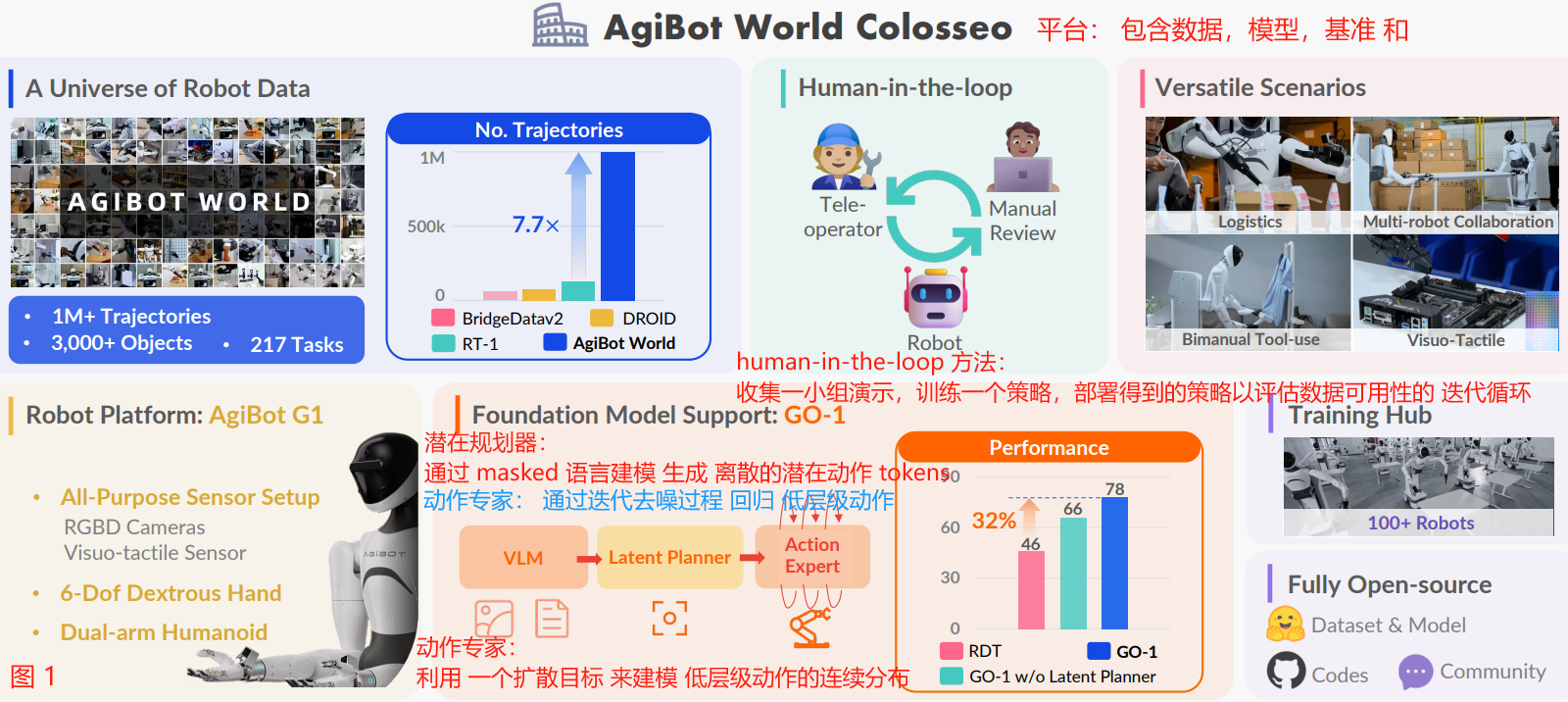
Fig. 1: Introducing AgiBot World Colosseo, an open-sourced large-scale manipulation platform comprising data, models, benchmarks and ecosystem.
图 1:介绍 AgiBot World Colosseo,一个开源的大规模操作平台,包括数据、模型、基准和生态系统。
AgiBot World stands out for its unparalleled scale and diversity compared to prior counterparts.
与之前的同类工作相比,AgiBot World 以其无与伦比的规模和多样性脱颖而出。
A suite of 100 dual-arm humanoid robots, namely AgiBot G1, is deployed to capture multimodal mobile manipulation demonstrations.
一套由 100 个双臂人形机器人组成的套件,即 AgiBot G1,用于捕获多模态移动操作演示。
Data quality is guaranteed by proficient teleoperators and the rigorous human-in-the-loop verification.
通过熟练的远程操作员和严格的 human-in-the-loop 验证 确保数据质量。
We further propose a generalist policy, Genie Operator-1 (GO-1), with the latent action planner.
我们进一步提出了一个具有潜在动作规划器的通才策略,Genie Operator-1 (GO-1)。
It achieves unified training across diverse data corpus with an impressive scalable performance of 32% gain compared to prior arts.
它实现了跨不同数据语料库的统一训练,与现有技术相比,具有令人印象深刻的 32% 的 scalable 性能增益。
〔 scalable performance 是啥指标? 图 5(b) 中的平均性能 0.78 (GO-1) - 0.46 (TRD) = 0.32 〕
〔 拗口的 scalable performance of 32% gain 〕
Our experimental results highlight the transformative potential of the AgiBot World dataset.
我们的实验结果突出了 AgiBot World 数据集的变革潜力。
Policies pre-trained on our dataset achieve an average success rate improvement of 30% compared to those trained on the prior large-scale robot dataset OXE [6].
与在先前的大规模机器人数据集 OXE[6] 上预训练的策略相比,在我们的数据集上预训练的策略平均成功率提高了 30%。
Notably, even when utilizing only a fraction of our dataset—equivalent to 1/10 of the data volume in hours compared to OXE—the generalizability of pretrained policies is elevated by 18%.
值得注意的是,即使只利用我们数据的一小部分(相当于与 OXE 相比,以小时计算的数据量的 1/10),预训练策略的泛化性也提高了 18%。
〔 ✅ 泛化性的量化指标是什么?图 7(b) 中为 针对 Wipe Table 任务使用的微调数据集是否有 human-in-the-loop 的消融实验结果,使用 引入 human-in-the-loop 的微调数据集 习得的策略 任务完成度提高了 18%。按照本文的指标计算方式,应该是 在 Wipe Table 任务的场景下试运行 10 次计算平均完成度。图 7(b) 中 0.59 - 0.41 = 0.18 〕
These findings underscore the dataset’s efficacy in bridging the gap between controlled laboratory environments and real-world robotic applications.
这些发现强调了数据集在弥合可控实验室环境和现实世界机器人应用之间差距的有效性。
Following our dataset, to address the limitations of previous robot foundation models that heavily rely on in-domain robot datasets, we present Genie Operator-1 (GO-1), a novel generalist policy that utilizes latent action representations to enable learning from heterogeneous data and efficiently bridges general-purpose vision-language models (VLMs) with robotic sequential decision-making.
根据我们的数据集,为了解决以前的机器人基础模型严重依赖于领域内机器人数据集的局限性,我们提出了 Genie Operator-1 (GO-1),一种新的通才策略,它利用潜在动作表示来实现从异质数据中学习,并有效地弥合通用视觉-语言模型 (VLMs) 与 机器人序列决策。
Through unified pre-training on web-scale data, spanning human videos to our high-quality robot dataset, GO-1 achieves superior generalization and dexterity, outperforming prior generalist policies such as RDT [10] and our variant without latent action planner.
通过对从人类视频到我们的高质量机器人数据集的网络规模数据的统一预训练,GO-1 实现了卓越的泛化和灵巧性,优于之前的通才策略,如 RDT[10] 和 没有潜在动作规划器的我们模型的变体。
Moreover, we demonstrate that GO-1’s performance exhibits robust scalability with increasing dataset size, underscoring its potential for sustained advancement as larger datasets become available.
此外,我们证明 GO-1 的性能随着数据集大小的增加而表现出强大的可扩展性,强调了它在更大数据集可用时持续发展的潜力。
Beyond its immediate impact, AgiBot World lays a strong foundation for future research in robotic manipulation.
除了它的直接影响,AgiBot World 为机器人操作的未来研究奠定了坚实的基础。
By open-sourcing the dataset, toolchain, and pre-trained models, we aim to foster community-wide innovation, enabling researchers to explore more authentic and diverse applications from household assistant to industrial automation.
通过开源数据集、工具链和预训练模型,我们的目标是促进社区范围内的创新,使研究人员能够探索从家庭助理到工业自动化的更真实和多样化的应用。
AgiBot World is more than yet another dataset; it is a step toward scalable, general-purpose robotic intelligence, empowering robots to tackle the complexities of the real world.
AgiBot World 不仅仅是另一个数据集;这是向可扩展的、通用的机器人智能迈出的一步,使机器人能够处理现实世界的复杂性。
Contribution. 1) We construct AgiBot World dataset, a multifarious robot learning dataset accompanied by open-source tools to advance research on policy learning at scale.
贡献:1) 我们构建了 AgiBot World 数据集,一个多种机器人学习数据集,伴随着开源工具,以推进大规模策略学习的研究。
As a pioneering initiative, AgiBot World employs an inclusive optimized pipeline, from scene configuration, task design, data collection, to human-in-the-loop verification, which ensures unparalleled data quality.
作为一项开创性的举措,AgiBot World 采用了一个包容性的优化 pipeline,从场景配置、任务设计、数据收集到 human-in-the-loop 验证,确保了无与伦比的数据质量。
2) We propose GO-1, a robot foundation policy using latent action representations to unlock web-scale pre-training on heterogeneous data.
我们提出了GO-1,一个机器人基础策略,使用潜在动作表示来解锁异质数据上的网络规模预训练。
Empowered by AgiBot World dataset, it outperforms prior generalist policies in generalization and dexterity, with performance scaling predictably with dataset size.
在 AgiBot World 数据集的支持下,它在泛化和灵活性方面优于先前的通才策略,性能随数据集大小可预测地扩展。
Limitation. All evaluations are conducted in real-world scenarios.
所有的评估都是在现实世界的场景中进行的。
We are currently developing the simulation environment, aligning with the real-world setup and aiming to reflect real-world policy deployment outcome.
我们目前正在开发模拟环境,与现实世界的设置保持一致,旨在反映真实世界的策略部署结果。
It would thereby facilitate fast and reproducible evaluation.
它将因此促进快速且可重复的评价。〔 局限性:在现实世界中进行的评估难以复现 〕
II. 相关工作
Data scaling in robotics.
Robot learning datasets from automated scripts or human teleoperation have enabled policy learning, with early efforts like RoboTurk [19] and BridgeData [12] offering small-scale datasets with 2.1k and7.2k trajectories, respectively.
来自自动化脚本或人类远程操作的机器人学习数据集已经实现了策略学习,早期的努力,如 RoboTurk[19] 和 BridgeData[12],分别提供了 2.1k 和 7.2k 轨迹的小规模数据集。
Larger datasets, such as RT-1 [14] (130k trajectories), expand scopes yet remain limited to few environments and skills.
更大的数据集,如 RT-1 [14] (130k 条轨迹),扩大了范围,但仍然局限于少数环境和技能。
Open X-Embodiment [6] aggregates various datasets into a unified format, growing to more than 2.4 million trajectories, as a consequence it suffers from significant variability in embodiments, observation perspectives, and inconsistent data quality, limiting its overall effectiveness.
Open X-Embodiment[6] 将各种数据集聚合为统一格式,增长到超过 240 万条轨迹,因此它受到 具身实例、观察视角和不一致的数据质量的显著差异的影响,限制了其总体有效性。
More recently, DROID [7] moves towards scaling up scenes for greater diversity by crowd-sourcing demonstrations yet falls short in data scale and quality control.
最近,DROID[7] 通过众包演示来扩大场景的多样性,但在数据规模和质量控制方面存在不足。
Prior datasets above generally face limitations in data scale, task practicality, and scenario naturalness, compounded by inadequate quality assurance and hardware restrictions, which impedes generalist policy training.
上述数据集在数据规模、任务实用性和场景自然性方面普遍存在局限性,再加上质量保证不足和硬件限制,阻碍了通才策略的训练。
As shown in Tab. I, our dataset addresses these gap adequately.
We build a data collection facility spanning five scenarios to reconstruct real-world diversity and authenticity.
如 Tab. 1 所示,我们的数据集充分解决了这些差距。我们建立了一个跨越五个场景的数据收集设施,以重建现实世界的多样性和真实性。
With over 1 million trajectories gathered by skilled teleoperators through rigorous verification protocols, AgiBot World utilizes humanoid robots equipped with visuo-tactile sensors and dexterous hands to enable multimodal demonstrations, setting it apart from previous efforts.
通过严格的验证协议,熟练的远程操作员收集了超过 100 万个轨迹,AgiBot World 利用配备 visuo-tactile 传感器和灵巧手的人形机器人来实现多模态演示,使其与以前的研究不同。
Unlike Pumacay et al. [20], which serves as a simulation benchmark for evaluating generalization, what we propose is a full-stack platform with data, models, benchmarks, and ecosystem.
与作为评估泛化的模拟基准的 Pumacay 等人的[20]不同,我们提出的是一个包含数据、模型、基准和生态系统的全栈平台。

TABLE I: Comparison to existing datasets.
表 1:与现有数据集的比较。
AgiBot World features the largest number of trajectories to date.
AgiBot World 拥有迄今为止最多数量的轨迹。
We replicate real-world environment at a 1:1 scale for the industrial and retail scenarios, which are barely present before.
我们以 1:1 的比例为工业和零售场景复制了现实世界的环境,这在以前几乎不存在。
Extensive human annotations are offered, including item, scene, skill (sub-task segmented), and task-level annotations.
提供了广泛的人类标注,包括物品、场景、技能(子任务分段)和任务级标注。
Notably, to expand data applicability and potential, we include imperfect data (i.e., failure recovery data with annotated error states) and tasks with dexterous hands.
值得注意的是,为了扩展数据的适用性和潜力,我们包含了不完美的数据(即带有标注错误状态的故障恢复数据)和灵巧手任务。〔 故障恢复用的示例数据,可能无法处理未见过的故障。这样看好像语音修正好些,即使投入现实使用了,仍可以随时修正。把遇到的故障丢进 共享的故障修正库 估计也有益处 〕
To ensure data quality, we adopt a human-in-the-loop philosophy: the policy learning is performed on collected demonstrations.
为了确保数据质量,我们采用了 human-in-the-loop 的理念:在收集的演示上执行策略学习。〔✅ ???额,这有啥特别的吗?——> 这里的解释过于简略了,后面提及 human-in-the-loop 方法是 收集一小组演示,训练一个策略,部署得到的策略来评估数据可用性 的迭代循环 〕
The deployment results are adopted as feedback to improve the collection protocol.
将部署结果作为反馈以改进收集协议。
Policy learning at scale.
Robotic foundation models often co-evolve with the development of dataset scale, equipping robots with escalating general-purpose capabilities through diverse, large-scale training.
机器人基础模型通常会随着数据集规模的发展而共同进化,通过多样化的大规模训练,为机器人配备不断升级的通用能力。
Several prior arts use web-scale video only to facilitate policy learning given the limited scale of action-labeled robot datasets [21], [22], [23].
鉴于动作标记的机器人数据集[21],[22],[23]的有限规模,一些现有技术仅使用网络规模的视频来促进策略学习。
Another line of work lies in the use of large, end-to-end models trained on robot trajectories with robotics data scaling up [4], [24], [14], [25].
另一条工作路线是使用 在随机器人数据比例扩大的机器人轨迹上训练的大型端到端模型[4],[24],[14],[25]。
For instance, RDT [10] employs Diffusion Transformers, initially pre-trained on heterogeneous multirobot datasets and fine-tuned on over 6k dual-arm trajectories, showcasing the benefits of pre-training on diverse sources.
例如,RDT[10] 采用 Diffusion Transformers,最初在异质多机器人数据集上进行预训练,并基于超过 6k 条双臂轨迹进行微调,展示了在多种来源上进行预训练的好处。
π 0 \pi_0 π0 [26] uses a pre-trained VLM backbone and a flow-based action expert, advancing dexterous manipulation for complex tasks like laundry.
π 0 \pi_0 π0[26] 使用预训练的 VLM backbone 和基于流的动作专家,为洗衣等复杂任务推进灵巧的操作。〔 ✅ π 0 \pi_0 π0 (20241031) 和 RDT(20241010v1) 相比哪个更好?
只有 π 0 \pi_0 π0 叠 T恤 (机器人平台 Bimanual ARX ( 该装置使用两个 6 自由度手臂,支持 ARX 手臂,具有三个摄像头(两个在腕部和一个在基座)和 14 维配置和动作空间。)。感觉 难一些,zero-shot 成功率接近 100% )
RDT 叠短裤 ( 把短裤水平对折。1-shot learning, 68%。硬件配置:Cobot Mobile ALOHA —— 配备了两个腕部摄像头、一个前置摄像头、一台笔记本电脑和一个机载系统设计(Fu et al., 2024),由 agilex.ai 制造。) 任务类型稍微接近,可以比比 😂
本文的 GO-1 在人形机器人平台部署, Fold Shorts 任务 10 次试运行的进度完成率平均为 0.66。
硬件平台不同不好比较 〕
LAPA [27] introduces the use of latent actions as pre-training targets; however, its latent planning capability is not preserved for downstream tasks.
LAPA[27]引入了潜在动作作为预训练目标的使用;然而,其潜在的规划能力无法用于下游任务。
Building on a variety of innovative ideas from recent research, we advance the field by transferring web-scale knowledge to robotic control through the adaptation of vision-language models (VLMs) with latent actions, leveraging both human videos and robot data for scalable training.
基于最近研究的各种创新思想,我们通过使用 具有潜在动作的视觉-语言模型(VLMs) 将网络规模的知识迁移到机器人控制中,利用人类视频和机器人数据进行可扩展的训练,以推进该领域的发展。
Our work demonstrates how the integration of a latent action planner enhances long-horizon task execution and enables more efficient policy learning, significantly improving upon existing generalist policies.
我们的工作展示了潜在动作规划器的整合如何增强 long-horizon 任务执行,并实现更有效的策略学习,显著改善现有的通才策略。
—————— 补充Start
—————— 补充End
III. AgiBot World: 平台 和 数据
AgiBot World is a full-stack and open-source embodied intelligence ecosystem.
AgiBot World 是一个全栈且开源的具身智能生态系统。
Based on the hardware platform developed by us, AgiBot G1, we construct AgiBot World —— an open-source robot manipulation dataset collected by more than 100 homogeneous robots, providing high-quality data for challenging tasks spanning a wide spectrum of real-life scenarios.
基于我们开发的硬件平台 AgiBot G1,我们构建了一个开源的机器人操作数据集 AgiBot World,该数据集由 100 多个同构机器人收集,为跨越广泛的真实生活场景的挑战性任务提供高质量的数据。
The latest version contains 1,001,552 trajectories, with a total duration of 2976.4 hours, covering 217 specific tasks, 87 skills, and 106 scenes.
最新版本包含 1,001,552 条轨迹,总时长 2976.4 小时,涵盖 217 个特定任务,87 种技能和 106 个场景。
We go beyond basic tabletop tasks such as pick-and-place in lab environments; instead, concentrate on real-world scenarios involving dual-arm manipulation, dexterous hands, and collaborative tasks.
我们超越了基本的桌面任务,如在实验室环境中拾取并放置;相比之下,专注于现实世界的场景,包括双臂操作、灵巧手和协作任务。
AgiBot World aims to provide an inclusive benchmark to drive the future development of advanced and robust algorithms.
AgiBot World 旨在提供一个包容性的基准,以推动先进和稳健算法的未来发展。
We plan to release all resources to enable the community to build upon AgiBot World.
我们计划发布所有资源,使社区能够基于 AgiBot World 发展。
The dataset is available under the CC BY-NC-SA 4.0 license, along with the model checkpoints, code for data processing and policy training.
数据集在 CC BY-NC-SA 4.0 许可下可用,以及模型检查点,数据处理代码和策略训练。
A. 硬件:一个多功能的人形机器人
The hardware platform is the cornerstone of AgiBot World, determining the lower limit of its quality.
硬件平台是 AgiBot World 的基石,决定了 AgiBot World 质量的下限。
The standardization of hardware is also the key to streamlining distributed data collection and ensuring reproducible results.
硬件的标准化也是简化分布式数据收集和确保可复现结果的关键。
We meticulously develop a novel hardware platform for AgiBot World, distinguished by visuo-tactile sensors, durable 6-DoF dexterous hands with humanoid configuration.
我们为 AgiBot World 精心开发了一个全新的硬件平台,以 visuo-tactile 传感器,耐用的六自由度灵巧的人形手为特色。
As illustrated in Fig. 1, our robotic platform features dual 7-DoF arms, a mobile chassis, and an adjustable waist.
如图 1 所示,我们的机器人平台具有 7 自由度的双臂,移动底盘和可调节腰部。
The end effectors are modular, allowing for the use of either a standard gripper or a 6-DoF dexterous hand, depending on task requirements.
末端执行器是模块化的,允许使用标准夹持器或 6 自由度灵巧手,取决于任务要求。
For tasks necessitating tactile feedback, a gripper equipped with visuo-tactile sensors is utilized.
对于需要触觉反馈的任务,使用配有 visuo-tactile 传感器的夹持器。
The robot is outfitted with eight cameras: an RGB-D camera and three fisheye cameras for the front view, RGB-D or fisheye cameras mounted on each end-effector, and two fisheye cameras positioned at the rear.
机器人配备有 8 个摄像头:一个 RGB-D 摄像头和 3 个鱼眼摄像头用于前视图,RGB-D 或鱼眼摄像头安装在每个末端执行器上,两个鱼眼摄像头位于背部。
Image observations and proprioceptive states, including joint and end-effector positions, are recorded at a control frequency of 30 Hz.
图像观测和本体感知状态,包括关节和末端执行器的位置,以 30 Hz 的控制频率记录。
We employ two teleoperation systems: VR headset control and whole-body motion capture control.
我们采用两种远程操作系统:VR 头显控制和全身动作捕捉控制。
The VR controller maps the hand gesture to the end-effector translation and rotation, which is subsequently converted to joint angles through inverse kinematics.
VR 控制器将手势映射到末端执行器的平移和旋转,随后通过逆运动学转换为关节角度。〔 inverse kinematics 逆运动学:已知机器人末端的位姿,计算机器人对应位置的全部关节变量。 〕
The thumbsticks and buttons on the controller enable robot base and body movement, while the trigger buttons control end-effector actuation.
控制器上的拇指摇杆和按钮使机器人基座和身体运动,而触发按钮控制末端执行器的驱动。
However, the VR controller restricts the dexterous hand to only a few predefined gestures.
然而,VR 控制器将灵巧的手限制在几个预定义的手势上。
To extensively unlock our robot’s capabilities, we adapt a motion capture system which records the data of human joints, including the fingers, and maps them to robot posture, enabling more nuanced control, including individual finger movements, torso pose, and head orientation.
为了广泛地解锁我们的机器人的能力,我们采用了一个动作捕捉系统来记录包括手指在内的人类关节的数据,并将它们映射到机器人的姿态,实现更细致的控制,包括单个手指的运动、躯干姿态和头部方向。
This system provides posture flexibility and execution precision that are required in achieving more complex manipulation tasks.
该系统提供了实现更复杂的操作任务所需的姿态灵活性和执行精度。
B. 数据收集: 协议和质量
The data collection session, as shown in Fig. 2, can be broadly divided into three phases.
如图 2 所示,数据收集过程大致可分为 3 个阶段。
(1) Before formally commencing data collection, we first conduct preliminary data acquisition to validate the feasibility of each task and establish corresponding collection standards.
在正式开始数据采集之前,我们首先进行初步的数据采集,验证每项任务的可行性,并建立相应的采集标准。
(2) After feasibility validation and review of the collection standards, skilled teleoperators arrange the initial scene and formally begin data collection according to the established standards.
在对采集标准进行可行性验证和审查后,熟练的远程操作人员安排初始场景,并根据制定的标准正式开始数据采集。
All data undergoes an initial validity verification locally, such as verifying the absence of missing frames.
所有数据都要经过本地的初始有效性验证,例如验证是否缺少帧。
Once the data is confirmed to be complete, it is uploaded to the cloud for the next phase.
一旦确认数据是完整的,它就会被上传到云端进行下一阶段的工作。
(3) During post-processing, the data annotators will verify whether each episode meets the collection standards established in phase 1 and provide language annotations.
在后处理期间,数据标注者将验证每个回合是否符合第一阶段建立的收集标准,并提供语言标注。
Failure recovery.
During data collection, teleoperators may occasionally commit errors, such as inadvertently dropping objects while manipulating the robotic arms.
在数据收集期间,远程操作员可能偶尔会犯错误,例如在操作机械臂时无意中掉落物体。
However, they are often able to recover from these errors and successfully complete the task without requiring a full reconfiguration of the setup.
但是,他们通常能够从这些错误中恢复并成功完成任务,而无需完全重置装置。
Rather than discarding such trajectories, we retain them and manually annotate each with corresponding failure reasons and timestamps.
相比于丢弃这样的轨迹,我们保留它们,并用相应的故障原因和时间戳手动标注每个轨迹。
These trajectories, referred to as failure recovery data, constitute approximately one percent of the dataset.
这些轨迹被称为故障恢复数据,约占数据集的 1%。
We consider them invaluable for achieving policy alignment [28] and failure reflection [29], essential for advancing the next generation of robot foundation models.
我们认为它们对于实现策略对齐[28]和故障反思[29]是无价的,这对于推进下一代机器人基础模型至关重要。
Human-in-the-loop.
Concurrent with feedback collection from data annotators, we adopt a human-in-the-loop approach to assess and refine data quality.
在收集来自数据标注者的反馈的同时,我们采用 human-in-the-loop 方法来评估和改进数据质量。
This process involves an iterative cycle of collecting a small set of demonstrations, training a policy, and deploying the resulting policy to evaluate data availability.
此过程涉及 收集一小组演示,训练一个策略,部署得到的策略以评估数据可用性的 迭代循环。【 human-in-the-loop 方法 】
Based on the policy’s performance, we iteratively refine the data collection pipeline to address identified gaps or inefficiencies.
根据策略的性能,我们迭代地改进数据收集 pipeline,以解决已确定的差距或效率低下的问题。
For instance, during real-world deployment, the model exhibits prolonged pauses at the onset of actions, aligning with data annotator feedback highlighting inconsistent transitions and excessive idle time in the collected data.
例如,在现实世界部署期间,模型在动作开始时显示出长时间的暂停,与数据标注者反馈一致,突出了收集的数据中不一致的转换和过多的空闲时间。
In response, we revise the data collection protocols and introduce a post-processing step to eliminate idle frames, thereby enhancing the dataset’s overall utility for policy learning.
作为回应,我们修改了数据收集协议,并引入了一个后处理步骤来消除空闲帧,从而增强了数据集在策略学习方面的整体效用。
This feedback-driven methodology ensures continuous improvement in data quality.
这种反馈驱动的方法确保了数据质量的持续改进。
C. 数据集统计和分析: Beyond Scale
AgiBot World is developed through a large-scale data collection facility, which spans over 4,000 square meters.
AgiBot World 是通过占地 4000 多平方米的大型数据收集设施开发的。
This extensive environment contains over 3,000 unique objects in a variety of scenes, meticulously designed to reflect realworld settings.
这个广阔的环境在各种场景中包含超过 3000 个独特的对象,精心设计以反映现实世界的环境。
The dataset covers a wide range of scenarios and scene setups, ensuring both scale and diversity in the pursuit of generalizable robot policy.
该数据集涵盖了广泛的场景和场景设置,确保了在追求一般化机器人策略时的规模和多样性。
Reconstructing the diversity of the real world.
重建现实世界的多样性。
Key statistics of our dataset are presented in Fig. 3.
我们数据集的关键统计数据如图 3 所示。
AgiBot World provides extensive coverage across five key domains: domestic, retail, industrial, restaurant, and office environments.
AgiBot World 提供了五个关键领域的广泛覆盖:家庭、零售、工业、餐厅和办公环境。
Within each domain, we further define specific scene categories.
在每个域中,我们进一步定义特定的场景类别。
For instance, the domestic domain includes detailed environments such as bedrooms, kitchens, living rooms, and balconies, while the retail domain features distinct areas like shelving units and fresh produce sections.
例如,家庭领域包括卧室、厨房、客厅和阳台等详细的环境,而零售领域则以货架单元和新鲜农产品区等独特区域为特点。
Our dataset also features over 3,000 distinct objects, systematically categorized across various scenes.
我们的数据集还包含超过 3000 个不同的对象,系统地分类在不同的场景中。
These objects span a wide range of everyday items, including food, furniture, clothing, electronic devices, and more.
这些物品涵盖了广泛的日常用品,包括食品、家具、服装、电子设备等等。
The distribution of object categories, as illustrated in Fig. 3(a), highlights the relative frequency of different object types within each scene.
物体类别的分布如图 3(a) 所示,突出了每个场景中不同物体类型的相对频率。
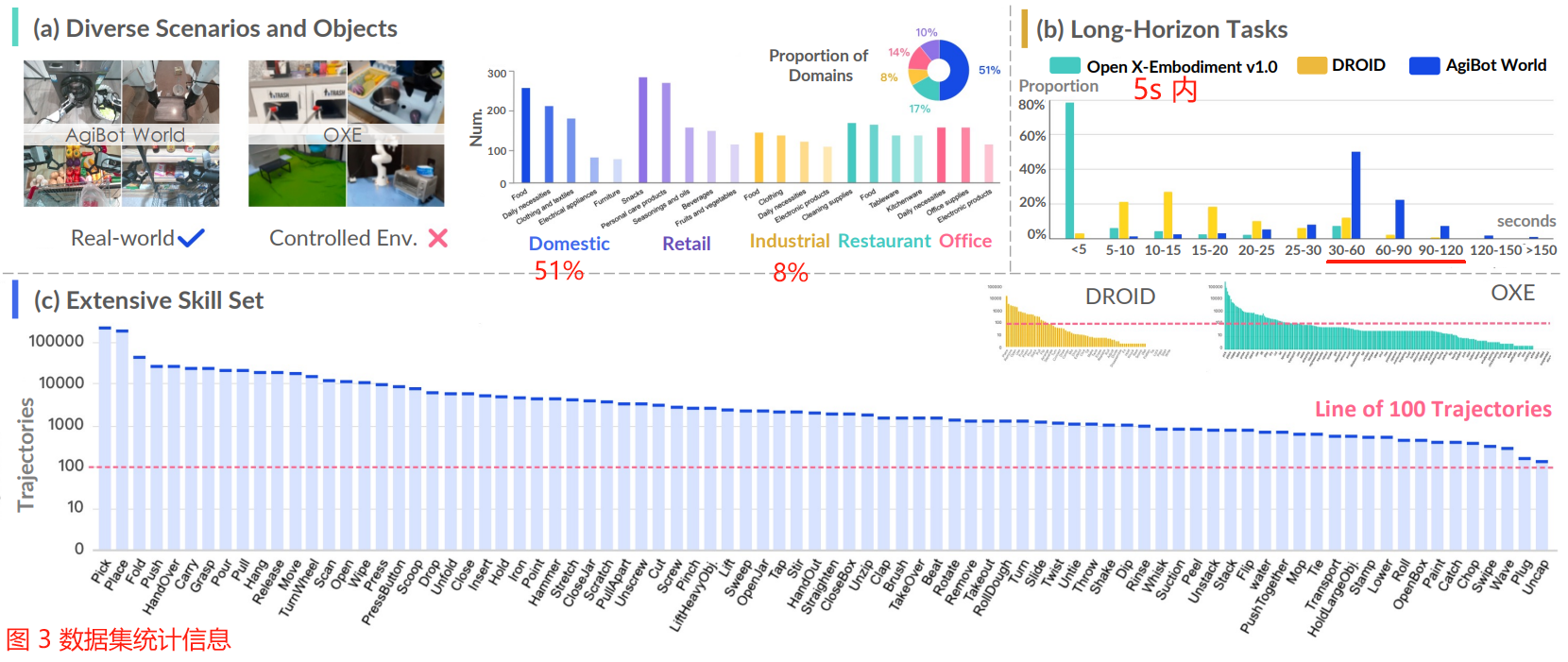
Fig. 3: Dataset Statistics.
图 3:数据集统计。
a) AgiBot World dataset covers the vast majority of robotic application scenarios, as well as a wide range of interactive objects.
AgiBot World 数据集涵盖了绝大多数机器人应用场景,以及广泛的交互式对象。
b) Our dataset features long-horizon tasks, with the majority of trajectories ranging from 30s to 60s.
我们的数据集突出 long-horizon 任务,大多数轨迹范围从 30 到 60 秒。
In contrast, widely used datasets, such as DROID, primarily consist of trajectories ranging from 5s to 20s, while OXE v1.0 predominantly contains trajectories within 5s.
相比之下,广泛使用的数据集,如 DROID,主要由 5s 到 20s 的轨迹组成,而 OXE v1.0 主要包含 5s 以内的轨迹。
c) AgiBot World dataset focuses on valuable atomic skills, spanning a wide spectrum of skills, each supported by a minimum of 100 trajectories (red dashed line above).
AgiBot World 数据集侧重于有价值的 atomic 技能,涵盖了广泛的技能,每个技能都有至少 100 条轨迹(上面的红色虚线)。
Long-horizon manipulation.
长视界操作
A distinguishing feature of the AgiBot World dataset is its emphasis on long-horizon manipulation.
AgiBot World 数据集的一个显著特征是它强调 long-horizon 操作。
As shown in Fig. 3(b), prior datasets predominantly focus on tasks involving single atomic skills, with most trajectories lasting no more than 5 seconds.
如图 3(b) 所示,先前的数据集主要集中在涉及单个 atomic 技能的任务上,大多数轨迹持续时间不超过 5 秒。
In contrast, AgiBot World is built upon continuous and complete tasks composed by multiple atomic skills, like “make a coffee”.
相比之下, AgiBot World 则是基于由多个 atomic 技能组成的连续且完整的任务,如“煮咖啡”。
Trajectories in our dataset typically span approximately 30 seconds, some of which last over 2 minutes.
我们数据集中的轨迹通常持续约 30 秒,其中一些持续超过 2 分钟。
We also provide key-frame and instruction annotation for each sub-step to facilitate policy learning in such challenging scenarios.
我们还为每个子步骤提供了关键帧和指令标注,以方便在这些具有挑战性的场景中进行策略学习。
Comprehensive skill coverage.
全面的技能覆盖。
In terms of task design, while generic atomic skills, such as “pick-and-place”, dominate the majority of tasks, we have intentionally incorporated tasks that emphasize less frequently used but highly valuable skills, such as "chop” and “plug” (as shown in Fig. 3( c)).
在任务设计方面,虽然通用的 atomic 技能,如“拾取和放置”,主导了大多数任务,但我们有意合并了一些任务,强调较少使用但非常有价值的技能,如“剁”和“插”(如图 3 ( c) 所示)。
This ensures that our dataset adequately represents a broad spectrum of skills, providing sufficient data for each to support robust policy learning.
这确保了我们的数据集充分代表了广泛的技能,为每个技能提供足够的数据来支持稳健的策略学习。
IV. AgiBot World: 模型
To effectively utilize our high-quality AgiBot World dataset and enhance the policy’s generalizability, we propose a hierarchical
Vision-Language-Latent-Action (ViLLA)framework with three training stages, as depicted in Fig. 4.
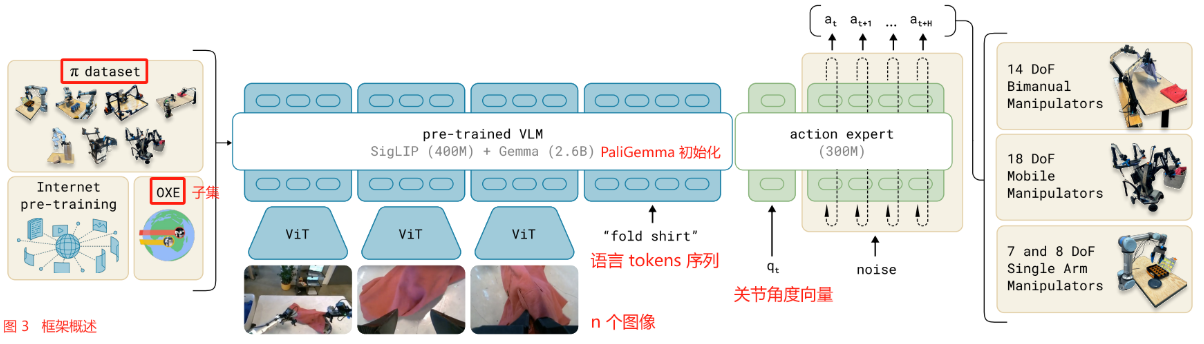
为了有效地利用我们的高质量 AgiBot World 数据集并增强策略的泛化性,我们提出了一个分层的 视觉-语言-潜在-动作(ViLLA) 框架,该框架具有 3 个训练阶段,如图 4 所示。
Compared to Vision-Language-Action (VLA) model where action is vision-language conditioned, the ViLLA model predicts latent action tokens, conditioned on the generation of subsequent robot control actions.
与 动作是视觉-语言条件的 视觉-语言-动作(VLA)模型相比,ViLLA 模型以 后续机器人控制动作的生成 为条件,预测潜在动作 tokens。〔 逆向推演 〕
In Stage 1, we project consecutive images into a latent action space by training an encoder-decoder latent action model (LAM) on internet-scale heterogeneous data.
在第一阶段,我们通过在互联网规模的异质数据上训练编码器-解码器潜在动作模型(LAM),将连续图像投影到潜在动作空间中。
This allows the latent action to serve as an intermediate representation, bridging the gap between general image-text inputs and robotic actions.
这使得潜在动作作为中间表示,弥合一般图像-文本输入和机器人动作之间的差距。
In Stage 2, these latent actions act as pseudo-labels for the latent planner, facilitating embodiment-agnostic long-horizon planning and leveraging the generalizability of the pre-trained VLM.
在阶段 2 中,这些潜在动作充当潜在规划器的伪标签,促进 embodiment-agnostic long-horizon 规划,并利用预训练的 VLM 的泛化性。
Finally, in Stage 3, we introduce the action expert and jointly train it with the latent planner to support the learning of dexterous manipulation.
最后,在阶段 3,我们引入动作专家并与潜在规划器联合训练,以支持灵巧操作的学习。
A. 潜在动作模型
Despite considerable advancements in gathering diverse robot demonstrations, the volume of action-labeled robot data remains limited relative to web-scale datasets.
尽管在收集各种机器人演示方面取得了相当大的进步,但相对于网络规模的数据集,动作标记的机器人数据的数量仍然有限。
To broaden the data pool by incorporating internet-scale human videos lacking action labels and cross-embodiment robot data, we employ latent actions [30] in Stage 1 to model the inverse dynamics of consecutive frames.
为了通过整合缺乏动作标签的互联网规模的人类视频和跨具身实例的机器人数据来扩大数据池,我们在第一阶段使用潜在动作[30]来模拟连续帧的 inverse dynamics。
This approach enables the transfer of real-world dynamics from heterogeneous data sources into universal manipulation knowledge.
这种方法可以将 来自异质数据源的真实世界的动力学 转换为通用的操作知识。
为了从视频帧 { I t , I t + H } \{ I_t,I_{t+H}\} {It,It+H} 中提取潜在动作,潜在动作模型围绕基于 inverse dynamics model 的编码器 I ( z t ∣ I t , I t + H ) {\bf I}(z_t|I_t,I_{t+H}) I(zt∣It,It+H) 和基于 forward dynamics model 的解码器 F ( I t + H ∣ I t , z t ) {\bf F}(I_{t+H}|I_t, z_t) F(It+H∣It,zt)构建。
编码器采用了一个 spatial-temporal transformer[31],其因果时序掩码遵循 Bruce 等人 [30],而解码器是一个 spatial transformer,它以初始帧和离散的潜在动作 tokens z t = [ z t 0 , ⋯ , z t k − 1 ] z_t=[z_t^0,\cdots,z_t^{k-1}] zt=[zt0,⋯,ztk−1] 作为输入,k 设为 4。
使用 VQ-VAE 目标[32]对潜在动作 tokens 进行量化,并使用大小为 ∣ C ∣ |C| ∣C∣ 的码本。
B. 潜在规划器 Latent Planner
With the aim of establishing a solid foundation for scene and object understanding and general reasoning ability, the ViLLA model harnesses a VLM pre-trained on web-scale vision-language data and incorporates a latent planner for embodiment-agnostic planning within the latent action space.
为了 为场景和对象理解以及通用推理能力建立坚实的基础,ViLLA 模型利用了一个在网络规模的视觉-语言数据上预训练的 VLM,并在潜在动作空间中整合了一个用于实现 embodiment-agnostic 规划的潜在规划器。
We use InternVL2.5-2B [33] as the VLM backbone due to its strong transfer learning capabilities.
由于其强大的迁移学习能力,我们使用 InternVL2.5-2B [33] 作为 VLM backbone。
The two-billion parameter scale has proven effective for robotic tasks in our preliminary experiments, as well as in prior studies [10], [26].
在我们的初步实验以及之前的研究 [10],[26] 中,20 亿 参数范围已经被证明对机器人任务是有效的。
Multiview image observations are first encoded using InternViT before being projected into the language space.
在投影到语言空间之前,首先使用 InternViT 对多视图观测进行编码。
The latent planner consists of 24 transformer layers, which enable layer-by-layer conditioning from the VLM backbone with full bidirectional attention.
潜在规划器由 24 个 transformer 层组成,这使得 VLM backbone 网能够以完全双向注意的方式逐层调节。 〔 完全双向注意 真的有助于这个模型获得更优化的行为策略吗?在机器人控制这个特殊场景中,真的比自回归型 (由左到右 (正运动学) 单向注意) VLM 或 由右到左(逆运动学) 单向注意 VLM 更好吗?
情形: 完全双向注意;由左到右 (正运动学) 单向注意;由右到左(逆运动学) 单向注意;由左到右 (正运动学) 单向注意 + 由右到左(逆运动学) 单向注意 整合;
如果真的有影响,将理解推理 和 动作生成 分层似乎是必行之路。感觉 机器人动作序列的 因果性 比 文本 强很多 〕
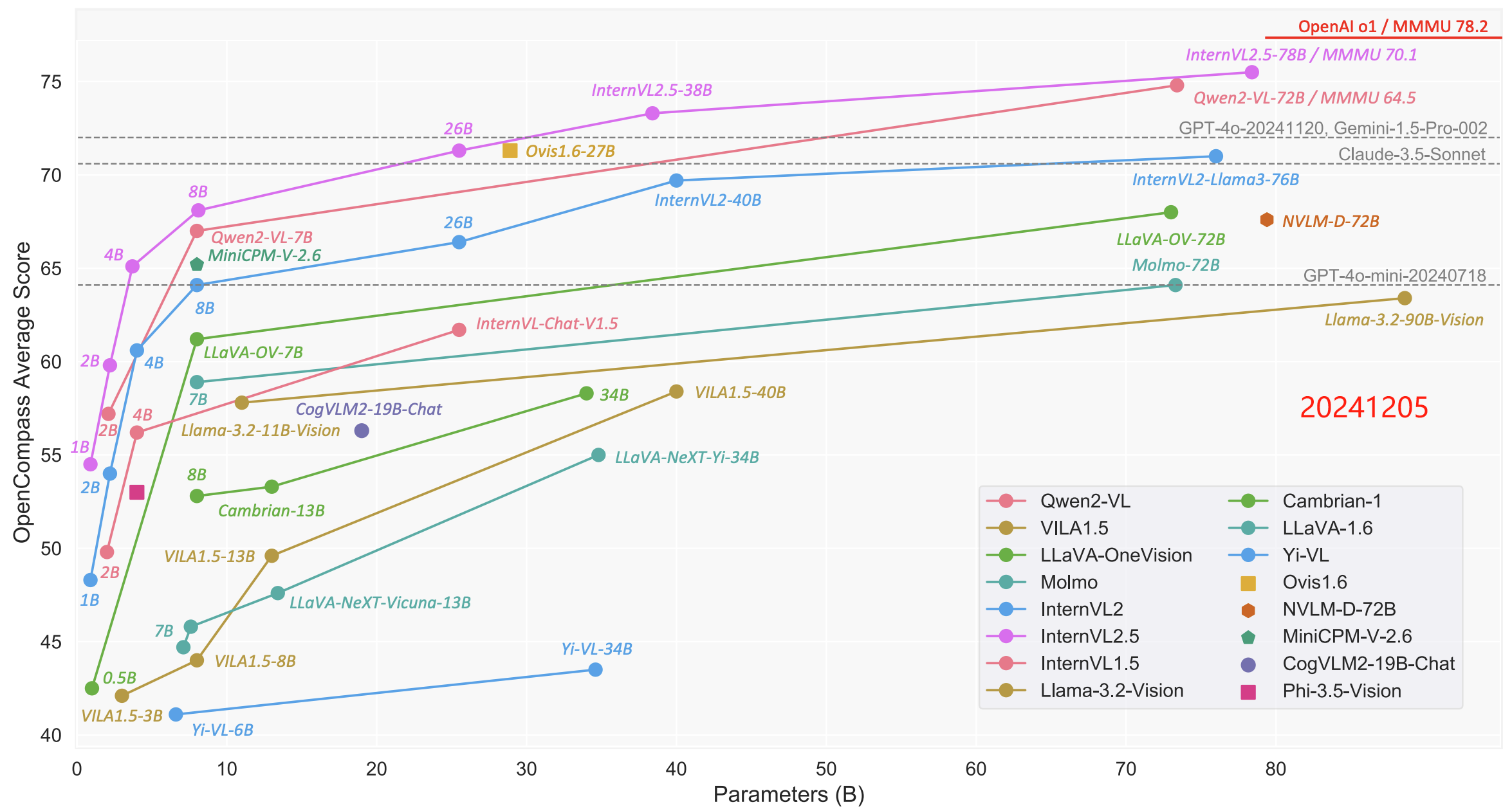
〔 DeepSeek 的 VL 如何?↓ 〕
具体来说,给定时间步 t t t 的多视图输入图像 ( I t h , I t l , I t r ) (I_t^h,I_t^l,I_t^r) (Ith,Itl,Itr)(通常来自头部,左手腕和右手腕),以及描述正在进行的任务的语言指令 l l l,潜在规划器预测潜在动作 token: P ( z t ∣ I t h , I t l , I t r , l ) {\bf P}(z_t| I_t^h,I_t^l,I_t^r,l) P(zt∣Ith,Itl,Itr,l),并由 LAM 编码器基于头部视图产生监督: z t : = I ( I t h , I t + H h ) z_t:={\bf I}(I_t^h,I_{t+H}^h) zt:=I(Ith,It+Hh)。(, with supervision produced by the LAM encoder based on the head view: z t : = I ( I t h , I t + H h ) z_t:={\bf I}(I_t^h,I_{t+H}^h) zt:=I(Ith,It+Hh). )
由于潜在动作空间比 OpenVLA[4] 中使用的离散低层级动作小几个数量级,因此该方法还有助于将通用 VLMs 高效地适配到机器人策略。
C. 动作专家
To achieve high-frequency and dexterous manipulation, Stage 3 integrates an action expert that utilizes a diffusion objective to model the continuous distribution of low-level actions [34].
为了实现高频且灵巧的操作,阶段 3 加入了一个动作专家,其利用 一个扩散目标 来建模 低层级动作的连续分布 [34]。
Although the action expert shares the same architectural framework as the latent planner, their objectives diverge: the latent planner generates discretized latent action tokens through masked language modeling, while the action expert regresses low-level actions via an iterative denoising process.
尽管动作专家与潜在规划器共享相同的架构框架,但它们的目标不同:潜在规划器通过 masked 语言建模 生成 离散的潜在动作 tokens,而动作专家则通过迭代去噪过程 回归 低层级动作。
Both expert modules are conditioned hierarchically on preceding modules, including the action expert itself, ensuring coherent integration and information flow within the dual-expert system.
两个专家模块都以 前一个模块为条件,包括动作专家本身,确保双专家系统内的连贯集成和信息流。
The action expert decodes low-level action chunks, denoted by A t = [ a t , a t + 1 , ⋯ , a t + H ] A_t=[a_t,a_{t+1},\cdots,a_{t+H}] At=[at,at+1,⋯,at+H] with H = 30 H= 30 H=30, using proprioceptive state p t p_t pt over an interval of H H H timesteps: A ( A t ∣ I t h , I t l , I t r , p t , l ) {\bf A} (A_t|I_t^h,I_t^l,I_t^r,p_t,l) A(At∣Ith,Itl,Itr,pt,l).
动作专家 解码 低层级动作块,表示为 A t = [ A t , a t + 1 , ⋯ , a t + H ] A_t=[A_t,a_{t+1},\cdots,a_{t+H}] At=[At,at+1,⋯,at+H],其中 H = 30 H= 30 H=30,在 H H H 时间步长间隔内使用本体感知状态 p t p_t pt: A ( A t ∣ I t H , I t l , I t r , p t , l ) {\bf A} (A_t|I_t^ H,I_t^l,I_t^r,p_t,l) A(At∣ItH,Itl,Itr,pt,l)。
During inference, the VLM, latent planner, and action expert are synergistically combined within the generalist policy GO-1, which initially predicts k k k latent action tokens and subsequently conditions the denoising process to produce the final control signals.
在推理期间,VLM、潜在规划器和动作专家在通才策略 GO-1 中协同结合,该策略最初 预测 k k k 个潜在动作 tokens,随后调节 去噪过程 以产生 最终的控制信号。
V. 实验和分析
We evaluate the real-world performance of policies pretrained on different data sources including the AgiBot World dataset, demonstrating the effectiveness credited from the GO-1 model in policy learning.
我们评估了在不同数据源(包括 AgiBot World 数据集)上预训练的策略在现实世界中的性能,证明了 GO-1 模型在策略学习中的有效性。
A. 实验设置
1 ) Evaluation Tasks
Here we choose a comprehensive set of tasks that span various dimensions of policy capabilities from AgiBot World for evaluation, including tool-usage (Wipe Table), deformable objects manipulation (Fold Shorts), human-robot interaction (Handover Bottle), language-following (Restock Beverage), etc.
这里我们从 AgiBot World 中选择了一组全面的任务来进行评估,这些任务跨越了策略能力的各个维度,包括工具使用(擦桌子),可变形对象操作(折叠短裤),人机交互(移交瓶子),语言遵循(补充饮料)等。
Moreover, we design 2 unseen scenarios for each task, covering position generalization, visual distractors, and language generalization, delivering thorough generalization evaluations for policies.
此外,我们为每个任务设计了 2 个没见过的场景,包括位置泛化、视觉干扰和语言泛化,为策略提供了全面的泛化评估。
The evaluated tasks, also partially shown in Fig. 5, are: 1) “Restock Bag”: Pick up the snack from the cart and place it on the supermarket shelf; 2) “Table Bussing”: Clear tabletop debris into the trash can; 3) “Pour Water”: Grasp the kettle handle, lift the kettle and pour water into the cup; 4) “Restock Beverage”: Pick up the bottled beverage from the cart and place it on the supermarket shelf;5) “Fold Shorts”: Fold the shorts laid flat on the table in half twice; 6) “Wipe Table”: Clean water spills using the sponge.
评估的任务的一部分如图 5 所示:
1 ) “Restock Bag”:把零食从购物车里拿出来,放在超市的货架上;
2 ) “收拾桌子”:清理桌面垃圾,倒入垃圾桶;
3 )“倒水”:抓住水壶把手,提起水壶,将水倒入杯中;
4 )“补货饮料”:从购物车中取出瓶装饮料,放在超市货架上;
5 ) “对折短裤”:把平放在桌上的短裤对折两次;
6 ) “擦桌子”:用海绵清理溢出的水。
Scoring rubrics. 评分准则
The evaluation metric employs a normalized score, computed as the average across 10 rollouts per task, scenario, and method.
评估指标采用归一化分数,计算为每个任务、场景和方法的 10 次试运行的平均值。
Each episode scores 1.0 for full success, with fractional scores for partial success, enabling a nuanced performance assessment.
每一回合完全成功得分为 1.0,部分成功得分为分数,从而实现了细致入微的性能评估。
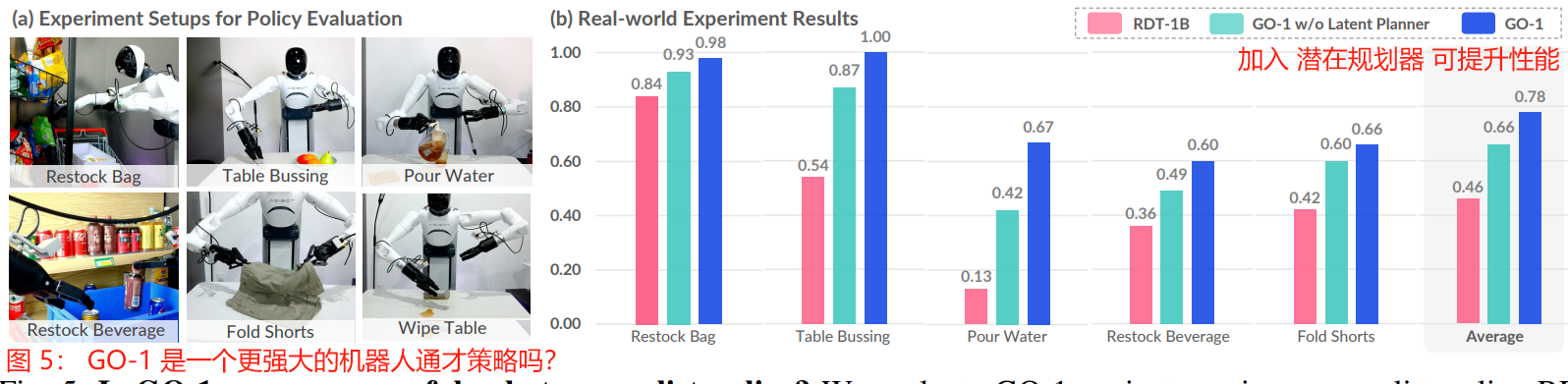
Fig. 5: Is GO-1 a more powerful robot generalist policy?
图 5: GO-1 是一个更强大的机器人通才策略吗?
We evaluate GO-1 against previous generalist policy RDT-1B and our baseline without the latent planner, with all policies pre-trained on AgiBot World beta.
我们根据之前的通才策略 RDT-1B 和我们没有潜在规划器的基线评估 GO-1,所有策略都在 AgiBot World beta 上预训练。
Across all tasks and comparisons, GO-1 outperforms baselines by a large margin.
在所有任务和比较中,GO-1 的性能都大大优于基线。
The incorporation of latent planner boosts performance on complex tasks such as “Fold Shorts” and improves generalizability in task “Restock Beverage” in great extent.
潜在规划器的加入提高了“叠短裤”等复杂任务的表现,并在很大程度上提高了“补充饮料”任务的泛化性。
2 ) Implementation Details 实现细节
The AgiBot World alpha represents the partial subset of our dataset, constituting approximately 14% of the full-version, AgiBot World beta (a.k.a. last row in Tab. I).
AgiBot World alpha 代表了我们数据集的部分子集,大约占完整版本 AgiBot World beta(也就是 Tab. I 中的最后一行 ) 的 14%。
Following the completion of the third-stage pre-training, the pre-trained GO-1 exhibits basic competency in task completion.
在完成第三阶段的预训练后,预训练的 GO-1 表现出基本的任务完成能力。
Unless otherwise specified, we further enhance the model by fine-tuning it using high-quality, task-specific demonstrations, enabling adaptation to new tasks for evaluation.
除非另有说明,否则我们将使用高质量的、特定于任务的演示对模型进行微调,从而进一步增强模型,使其能够适应 用于评估的新任务。
For GO-1, fine-tuning is conducted with a learning rate of 2 e − 5 e^{-5} e−5, a batch size of 768, and 30,000 optimization steps.
对于 GO-1,进行微调的学习率为 2 e − 5 e^{-5} e−5,批大小为 768,优化步数为 30,000。
B. Does AgiBot World boost policy learning at scale?
We choose the open-source RDT [10] model to study how much the AgiBot World dataset can help policy learning.
我们选择开源的 RDT[10] 模型来研究 AgiBot World 数据集对策略学习的帮助有多大。
The task completion scores for three tasks are detailed in Fig. 6.
三个任务的任务完成得分详见图 6。
Models pre-trained on the AgiBot World dataset demonstrate a significant improvement in the “Table Bussing” task, nearly tripling performance.
在 AgiBot World 数据集上预训练的模型在“Table Bussing”任务上有了显著的改进,性能几乎提高了三倍。
On average, the completion score increases by 0.30 and 0.29 for in-distribution and out-of-distribution setups, respectively.
平均而言,分布内和分布外设置的完成分数分别增加 0.30 和 0.29。
Notably, the AgiBot World alpha dataset, despite having a significantly smaller data volume than OXE (e.g., 236h compared to ~2000h), achieves a higher success rate, underscoring the exceptional data quality of our dataset.
值得注意的是,尽管 AgiBot World alpha 数据集的数据量明显小于OXE(例如,236h 与 ~2000h 相比),但成功率更高,强调了我们数据集卓越的数据质量。
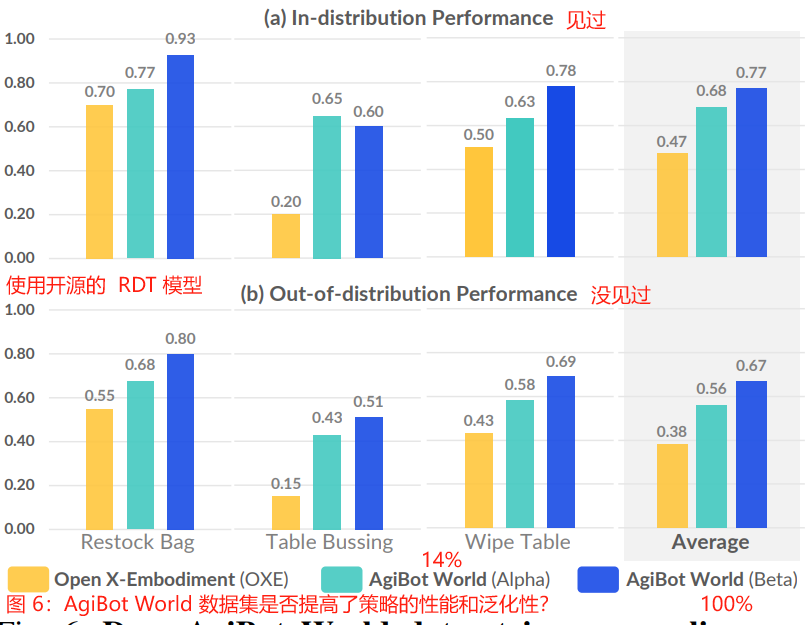
Fig. 6: Does AgiBot World dataset improve policy performance and generalizability?
图 6:AgiBot World 数据集是否提高了策略的性能和泛化性?
Policies pre-trained on our dataset outperform those trained on OXE in both seen (0.77 v.s. 0.47) and out-of-distribution scenarios (0.67 v.s. 0.38).
在我们的数据集上预训练的策略在见过(0.77 vs . 0.47)和分布外场景(0.67 vs . 0.38)上都优于在 OXE 上预训练的策略。
C. Is GO-1 a more capable generalist policy?
We evaluate GO-1 on five tasks of varying complexity, categorized by their visual richness and task horizon.
我们在 5 种不同复杂程度的任务中评估 GO-1,根据它们的视觉丰富性和任务视界进行分类。
The results, as shown in Fig. 5, are averaged over 30 trials per task, with 10 trials conducted in a seen setup and 20 trials under variations or distractions.
结果如图 5 所示,每个任务平均超过 30 次试验,其中 10 次试验在见过的设置下进行,20 次试验在变化或干扰下进行。
GO-1 significantly outperforms RDT, particularly in tasks such as "Pour Water”, which demands robustness to object positions, and “Restock Beverage”, which requires visual robustness and instruction-following capabilities.
GO-1 的表现明显优于 RDT,特别是在“倒水”和“补充饮料”等任务中,前者需要对物体位置的稳健性,后者需要视觉稳健性和指令遵循能力。
The inclusion of the latent planner in the ViLLA model further improves performance, resulting in an average improvement of 0.12 task completion score.
在 ViLLA 模型中加入潜在规划器进一步提高了性能,平均提高了 0.12 的任务完成得分。
D. Does GO-1’s ability scale with data size? GO-1 的能力随着数据增加而提升吗?
To investigate whether a power-law scaling relationship exists between the size of pre-training data and policy capability, we conduct an analysis using 10% subsets of the alpha, 100% alpha, and beta dataset, where the number of training trajectories are ranged from 9.2k to 1M.
为了研究预训练数据的大小 与 策略能力之间是否存在 power-law scaling 关系,我们使用 alpha 的 10% 子集、100% alpha 和 beta 数据集进行了分析,其中训练轨迹的数量从 9.2k 到 1M 不等。
We evaluate the out-of-the-box performance of resulting policies on four seen tasks in pre-training.
我们在预训练的四个见过的任务上评估了得到的策略的开箱即用性能。
As shown in Fig. 7(a), the policy’s performance exhibits a predictable power-law scaling relationship with the number of trajectories, supported by a Pearson correlation coefficient of r = 0.97.
如图 7(a) 所示,策略性能与轨迹数量呈可预测的 power-law scaling 关系,Pearson 相关系数 r = 0.97。
E. How does data quality impact policy learning?
We explore the impact of quality checks introduced in our human-in-the-loop data collection on policy learning.
我们探讨了在 human-in-the-loop 数据收集中引入的质量检查 对 策略学习的影响。
Specifically, we provide an ablation study by fine-tuning an RDT model pre-trained on the alpha dataset using both verified (528 trajectories) and unverified (482 trajectories) data from the “Wipe Table” task.
具体来说,我们使用来自“擦桌子”任务的验证(528 条轨迹)和未验证(482 条轨迹)数据,通过微调在 alpha 数据集上预训练的 RDT 模型,提供了一项消融研究。
As shown in Fig. 7(b), being larger in quantity does not necessarily translate to improved performance, while a smaller set of human-verified data yields a 0.18 boost in the completion score, underscoring the importance of high-quality data for policy learning.
如图 7(b) 所示,数量越大并不一定意味着性能的提高,而较少的人类验证数据集则会使完成分数提高 0.18,这凸显了高质量数据对策略学习的重要性。

VI. 结论
We introduce AgiBot World, an open-source ecosystem aimed at democratizing access to large-scale, high-quality robot learning datasets.
我们介绍 AgiBot World,一个开源生态系统,旨在使大规模、高质量的机器人学习数据集的访问民主化。
It is complete with toolchains and foundation models to advance embodied general intelligence through community collaboration.
它完成了工具链和基础模型,通过社区协作来推进具身通用智能。
Our dataset distinguishes itself through unparalleled scale, diversity, and quality, under-pinned by carefully crafted tasks.
我们的数据集以无与伦比的规模、多样性和质量脱颖而出,并以精心设计的任务为基础。
Policy learning evaluations confirm AgiBot World’s value in enhancing performance and generalizability.
策略学习评估证实了 AgiBot World 在提高性能和泛化方面的价值。
To further explore its impact, we develop GO-1, a generalist policy utilizing latent actions for web-scale pre-training.
为了进一步探索其影响,我们开发了 GO-1,一种利用潜在动作进行网络规模预训练的通才策略。
GO-1 excels in real-world complex tasks, outperforming existing generalist policies and demonstrating scalable performance with increased data volume.
GO-1 在现实世界的复杂任务中表现出色,超越了现有的通才策略,并在数据量增加的情况下展示了可扩展的性能。
We invite the broader community to collaborate in fostering an ecosystem and maximizing the potential of our extensive dataset.
我们邀请更广泛的社区合作,以培育一个生态系统,并最大限度地发挥我们广泛数据集的潜力。
参考文献
—————— 补充
〔 ✅ Diffusion Policy 和 Latent actions 的区别和联系是? 〕



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









