







读取数据
data=pd.read_csv('train_set.csv',sep='\t')
data.head()
数据格式如下:

标签为数字,文字内容为单词转化为数字的映射。
描述分析
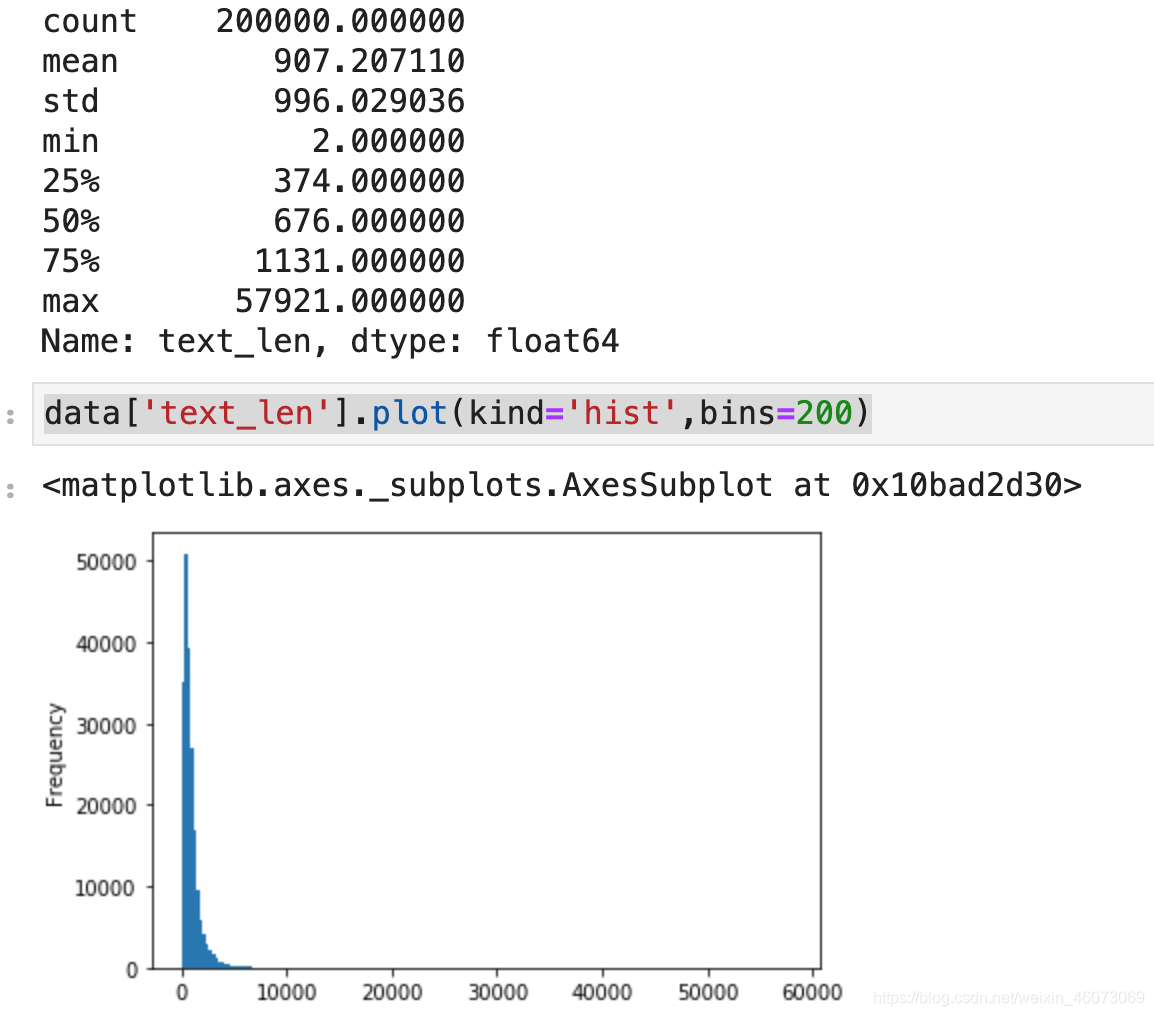
# 统计每个样本所包含的单词数量
data['text_len']=data['text'].apply(lambda x:len(x.split()))
print(data['text_len'].describe()) # 描述统计
data['text_len'].plot(kind='hist',bins=200)
from collections import Counter
all_text=' '.join(list(data['text'])) #将所有样本连接
word_count=Counter(all_text.split(' ')) #拆分成单词 统计词频
word_count=sorted(word_count.items(),key=lambda x: x[1],reverse=True) #词频排序
print(len(word_count),word_count[0],word_count[-1],sep='\n')
#result
#6869
#('3750', 7482224)
#('3133', 1)
#统计每个样本中出现过的词的集合(去重)
data['text_unique']=data['text'].apply(lambda x:' '.join(list(set(x.split()))))
all_lines=' '.join(list(data['text_unique']))
word_count=Counter(all_lines.split())
word_count=sorted(word_count.items(),key=lambda x: x[1],reverse=True)
print([word_count[i] for i in [0,1,2]])
#result
#[('3750', 197997), ('900', 197653), ('648', 191975)]
其中字符3750,字符900和字符648在20w新闻的覆盖率接近99%,很有可能是标点符号。
练习题
- 假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
- 统计每类新闻中出现次数最多的字符
# 统计句子数量
p=['3750','900','648']
def ct_sts(x):
l=x.split()
return len(list(filter(lambda w: w in p,l)))+1
data['sentences']=data['text'].apply(ct_sts)
print(data['sentences'].describe())
#result
'''
count 200000.000000
mean 79.348290
std 85.519746
min 1.000000
25% 28.000000
50% 56.000000
75% 102.000000
max 3418.000000
'''
每个样本中句子的平均数量为79.348
def get_most(x):
d=data.query('label=={}'.format(x))
all_=' '.join(list(d['text']))
wc=Counter(list(filter(lambda w: w not in p,all_.split())))
return sorted(wc.items(),key=lambda x:x[1],reverse=True)[0]
for i in set(data['label']):
print('label {}: {}'.format(i,get_most(i)))
'''
label 0: ('3370', 503768)
label 1: ('3370', 626708)
label 2: ('7399', 351894)
label 3: ('6122', 187933)
label 4: ('4411', 120442)
label 5: ('6122', 159125)
label 6: ('6248', 193757)
label 7: ('3370', 159156)
label 8: ('6122', 57345)
label 9: ('7328', 46477)
label 10: ('3370', 67780)
label 11: ('4939', 18591)
label 12: ('4464', 51426)
label 13: ('4939', 9651)
'''
小结
- 词频统计先对样本进行合并,再拆分成单词,最后可用collections工具包中Counter实现词频统计(如果不用软件包可以用循环添加字典的方式);
- 需要去除标点符号。














 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









