










时间树图:进化树的静态可视化
期刊: IEEE Trans. Vis. Comput. Graph.(发表日期: 2019)
作者: Wiebke Köpp; Tino Weinkauf
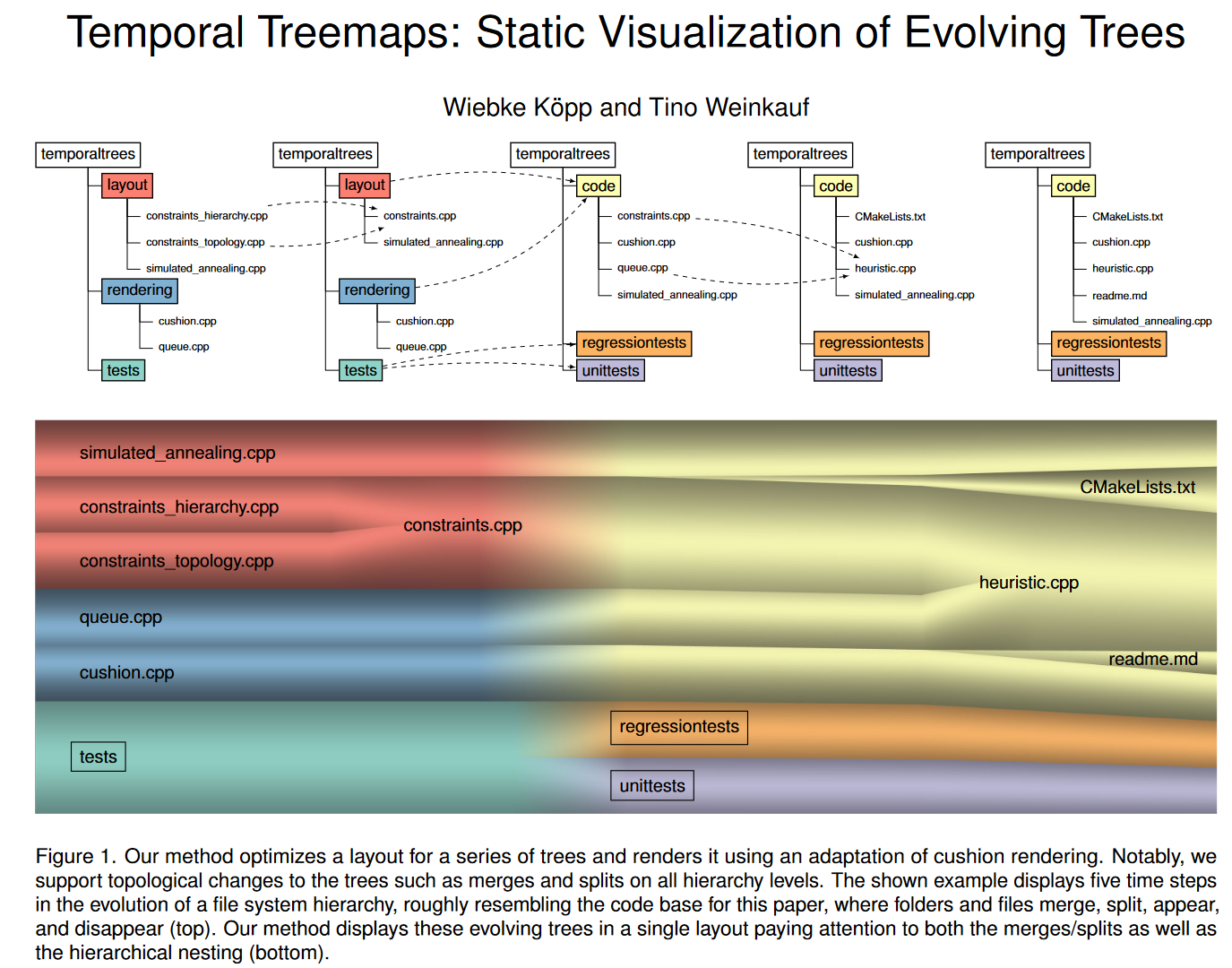
摘要
我们考虑具有变化拓扑结构和数据的随时间演化的树状结构:树的节点可能在一段时间内持续存在,发生合并或分裂,同时关联的数据也可能发生变化。实际上,这可以看作一系列树的序列,其中每一层级的节点在连续的时间步骤间有对应的映射关系。现有的可视化方法,如动态的二维树图,虽然能展示布局的改变,但难以全面观察整个数据系列。我们提出一种方法,将这些动态数据以静态、嵌套且空间填充的方式可视化。我们的方法基于两大创新点:首先,整体布局设计构成了一类图形绘制问题。我们采用全局视角,针对整个时间跨度,结合启发式算法与模拟退火技术来解决这个问题。其次,我们引入了一种渲染方式,通过改进经典软垫树图,突出显示层次结构。我们运用来自时变标量场特征追踪、文件系统层次结构演变以及全球人口数据等广泛领域的实例,展示了该方法的适用范围之广。
索引术语——树状图、时态树。
1 引言
分层数据结构很常见。文件系统、源代码存储库、HTML/XML 文件或国家和公司的组织结构只是几个例子。大量不同的树可视化方法说明了数据类型的重要性及其激发可视化社区兴趣的能力。
将数据与树的节点关联起来特别有用。然后可以使用不同的方法来揭示层次结构的最大或最小部分。嵌套布局的概念,特别是树图[28],是此类树的一种广泛使用的可视化方法。
与树相关的数据可能会随着时间的推移而变化,观察该数据的时间发展非常有趣。为此提出了动态调整树图[19,30-33,37]。此外,通过分层信息增强的流图[3,14,40]提供了具有动态变化数据的树的整个时间发展的静态概述。
本文涉及数据和拓扑随时间变化的树。本质上,只要整棵树仍然是一棵树,它就可以几乎任意地变换。准确地说,我们考虑树的时间序列,每个层次结构级别在连续时间步之间具有节点对应关系。树节点可能会在所有层次结构级别上出现和消失、合并和分裂,并且关联的数据可能会发生变化。我们只排除孩子改变父母的情况。
当然,可以通过将任何树可视化方法应用于每个单独的时间步来一般地可视化时间演化的树。这通常不能令人满意,因为不连续的布局变化使得观察数据变得困难。最近,Lukasczyk 等人。 [26]提出了嵌套跟踪图,这是处理此类数据的第一种方法。虽然该方法是在层次嵌套图的背景下描述的,但此类数据也可以视为树的时间序列。卢卡斯奇克等人。 [26]沿着空间轴静态地表示时间,并将节点绘制为沿着该轴的不同厚度的带。他们嵌套在父母的乐队中。该方法表现出大量的交叉点,因为布局算法很大程度上忽略了层次关系。此外,该方法是针对父级数据值超过子级数据总和的数据而设计的。这使得它不适用于大量子级数据总和等于父级数据的应用场景(例如文件系统)。
我们做出以下贡献:
- 我们提出了一种新颖的布局算法,用于随着拓扑和数据的变化而随时间演化的树。它同时考虑整个层次结构和时间跨度,以生成具有尽可能少的交叉点的布局。这是基于启发式和模拟退火优化方法的组合。布局算法的运行时间约为几秒钟。
- 我们提出了一种渲染方案,通过改编经典的缓冲树图来强调层次结构[38]。这使得我们的方法适用于子级数据总和等于父级数据的数据集。
- 我们提出了一种用于时间演化树的数据结构,它只记录树的变化。除了空间效率之外,它还大大减少了布局算法的计算时间。
- 我们使用来自时间相关标量场中的特征跟踪、文件系统层次结构的演变和世界人口的数据来展示广泛的适用性。
本文的结构如下:第 2 部分回顾了有关树、树图和相关可视化方法的理论和先前的工作。我们在第 3 节中介绍了时间演化树的数据结构。我们的两个主要贡献,布局和渲染,在第 4 节中介绍。我们在第 5 节中评估我们的方法,在第 6 节中显示来自不同领域的结果,并在第 6 节中得出结论第 7 节。
2 相关工作及背景
2.1 树和树图
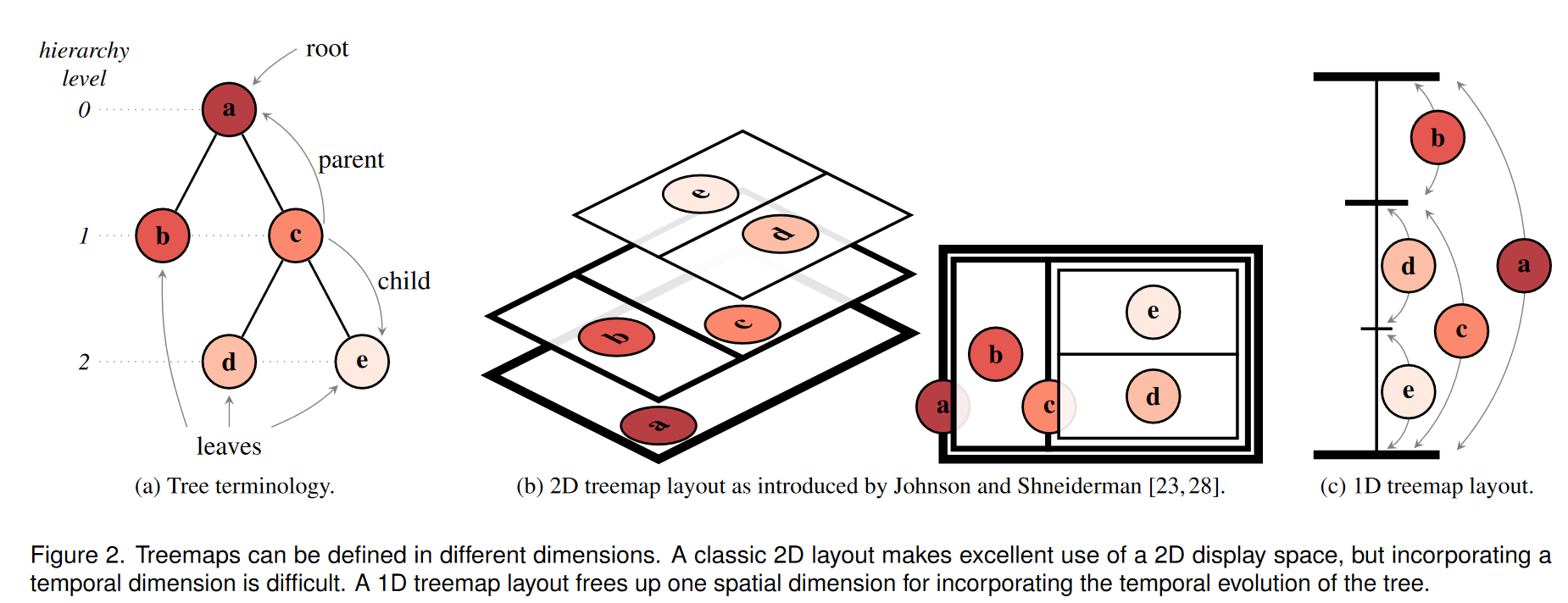
树 T = (N, E) 是一种分层数据结构,具有一组节点 N 和一组有向边 E。只有一个节点是仅具有传出边的树的根。所有其他节点恰好有一条来自其父节点的传入边,以及零个或多个指向其子节点的传出边。没有子节点的节点称为叶节点。节点的层次结构级别确定为从根到该节点的唯一定义的路径中的边数。参见图 2a。
将数据与树关联的一种常见且有用的方法是在叶子处指定数据值,并将每个父节点 p 处的数据描述为其子节点
c
i
c_i
ci 的数据之和。
d
(
p
)
=
∑
d
(
c
i
)
.
(
1
)
d(\mathbf{p})=\sum d(\mathbf{c}_i) .\qquad(1)
d(p)=∑d(ci).(1)
一个合适的例子是文件系统层次结构,其中文件(叶)在磁盘上占据一定的大小,而目录(父目录)只是一个容器,其大小是其文件和子目录的总和。
树形图是一种常用工具,用于在空间填充的嵌套布局中可视化具有关联数据的树。每个节点的绘制大小与其数据相关,并用作绘制其子节点的容器。 Johnson 和 Shneiderman [23, 28] 引入了一般概念:矩形空间与根相关联。它的子项是通过沿 x 轴相对于每个子项的数据量划分矩形来绘制的。此过程通过交替每个层次结构级别中的分区轴来继续。图 2b 说明了这一点。
已经提出了不同的树形图布局变体。布鲁尔斯等人。 [8]在划分空间时力求创建正方形,以使树节点更易于比较。贝德森等人。 [29]提出了在原始数据中保留给定顺序的树形图。除了嵌套矩形外,还提出了其他形状,包括矩形内的一般多边形 [16]、Voronoi 单元 [1] 和气泡 [18],后者专门针对可视化数据中的不确定性。
树形图渲染方法的不同之处在于节点的层次结构级别的显示方式。 Johnson 和 Shneiderman [23, 28] 使用矩形之间的边界线。 Balzer 和 Deussen [1] 通过边界和颜色变化强调层次结构。 Van Wijk 和 van de Wetering [38] 提出了缓冲树图,它根据层次结构模拟不同高度的漫射照明表面。在本文中,我们将这种策略应用于时间树图,请参见第 4.3 节。
请注意,树状图也可以在其他维度中定义。正如 Shneiderman [28] 所指出的,树形图可以通过细分立方体来定义 3D 树形图,也可以通过递归细分直线来定义 1D 树形图。诺伊曼等人。 [27]利用一维嵌套布局来增强具有非分层关系的分层信息。一维树形图释放了一个显示维度以用于其他信息;稍后我们将利用它来合并时间维度。图 2c 显示了一维树形图。
2.2 时间相关树的可视化方法
时间会影响树的不同方面:节点上的数据可能会随着时间而变化,或者树的拓扑可能会发生变化,或者两者兼而有之。不同的可视化方法涵盖不同的方面,如下所述。
考虑静态树上与时间相关的数据值。这可以使用每个节点 [d1, . 。 。 , dn] n 个时间步长。在父节点的数据值是其子节点的数据值之和的情况下,只需在叶子处存储时间序列并使用等式(1)在所有其他节点处恢复它们即可。
有许多方法可以表示多个相互堆叠的一维图。每个单独的图表本质上都是一个粗带,代表一个主题或类似主题的演变。 Havre 等人的 ThemeRiver。 [21] 是最早的。这些频段是有序的,以便单个频段的演变对其他频段的影响尽可能小。 Byron 和 Wattenberg [11] 以及 Bartolomeo 和 Hu [2] 对此类可视化中“摆动”的数量进行了详细讨论。许多作品 [3,14,40] 将分层信息合并到堆叠图中。层次结构通过颜色编码 [14, 40]、树的联合显示 [14, 40] 或单独显示层次结构层 [3] 来传达,并促进数据的交互式探索 [3, 40]。与我们的方法相反,树的拓扑保持静态,节点不会出现或消失。
有几种方法扩展了树图概念,以显示拓扑静态树上的时间相关数据:动画用于在不同时间步之间进行混合。面临的挑战是在良好的树形图布局和布局更改数量之间取得平衡 [19, 30–33, 37]。
考虑树的拓扑和节点数据随时间的变化。最近,Lukasczyk 等人。 [26]提出了一种处理此类数据的方法。虽然它被正交地表述为一种处理嵌套图而不是一系列树的方法,但它也可以被视为后者。该方法使用 Graphviz 库 [17] 进行布局,虽然这会产生很好的结果,但最终的合成步骤会引起大量的交叉/交叉,因为在计算图形布局时不使用分层信息。我们将在 4.1 节中详细介绍这一点。本文提出了一种新颖的图形布局算法,该算法能够生成交叉点/交叉点较少的布局。 Cui 等人也探索了与层次结构相关的合并和拆分。 [15]。他们将文本语料库中主题的演变可视化。然而,并不是在每个时间步骤中显示整个树,而只是在可能不同的层次结构级别上对树进行切割。
伯奇等人。 [10]绘制动态变化的图形,并具有彼此相邻的分层嵌套。由此产生的边缘交叉是通过泼溅技术来预测和管理的。 Beck 等人讨论了一般动态图可视化的其他方法。 [4]。
2.3 约束排序的方法
我们通过创建对象的约束顺序来对布局计算进行建模。每个约束要求所涉及的对象在排序中连续出现。在超图中寻找路径支持时也会出现类似的问题[9]。与常规图相比,超图的边可以涉及两个以上的节点。在路径支持中,与边相关的所有节点都彼此相邻放置。当且仅当所有约束都可以满足时,存在计算多项式时间内路径支持的算法[6, 22]。然而,计算最优部分解,即,如果不可能满足所有约束,则满足尽可能多的约束,已被证明是 NP 完全的[20]。
通过将叶子解释为节点,将约束解释为超图的边,我们的布局问题可以转化为路径支持问题。然而,这忽略了节点的时间方面,这导致了更大的解决方案空间。尽管如此,我们框架的未来版本可能会测试最优解决方案的存在。
除了我们的场景之外,约束排序也发生在故事的演变中 [25, 36],其中角色的共置施加了限制。该问题已使用上述超图公式[36]以及允许交互式重新排序以进一步最小化交叉的初始解决方案的计算来解决[25]。
3 时间相关树的数据结构
Lukasczyk等人最近给出了一个实际有用的定义,用于描述随时间演化的树状结构[26]:一个嵌套追踪图
G
=
(
N
,
E
T
,
E
N
)
G=(N, E_T, E_N)
G=(N,ET,EN)由一组节点
n
t
ℓ
∈
N
\mathbf{n}_t^\ell\in N
ntℓ∈N组成,其中每个节点都有一个时间步
t
t
t、一个层级
ℓ
\ell
ℓ 以及一个数据值
d
d
d。
E
N
E_N
EN中的边专门描述单个时间步内的层级关系,即,将
G
G
G 限制在一个特定时间步
t
t
t 上会得到一棵正确的树
G
∣
t
=
(
N
∣
t
,
E
N
∣
t
)
G|_t=(N|_t, E_N|_t)
G∣t=(N∣t,EN∣t),如上所述,或者可能得到这样的树的森林。
E
T
E_T
ET中的边专门连接同一层次层的节点
ℓ
\ell
ℓ,即限制
G
∣
ℓ
=
(
N
∣
ℓ
,
E
T
∣
ℓ
)
G|_\ell = ( N|_\ell , E_T |_\ell)
G∣ℓ=(N∣ℓ,ET∣ℓ) 给出一个跟踪图,其中节点可能出现、消失、合并或分裂。图 3a 显示了一个示例。
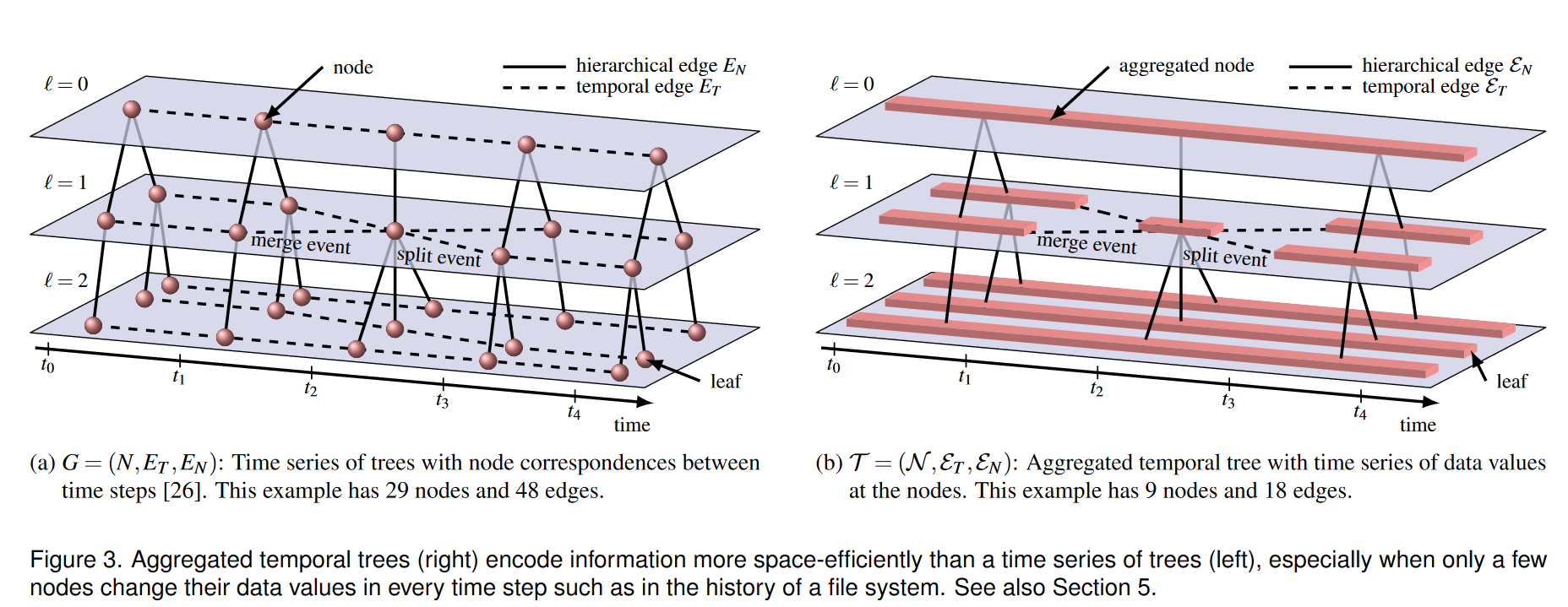
本质上,嵌套跟踪图每个时间步存储一棵树以及其间的跟踪信息。当跟踪时间相关标量场中的上层或下层集[26]时,这个定义非常有用,其中每个节点的数据值在每个时间步都发生变化。然而,在处理每个时间步中只有少数节点发生变化的数据集(例如在文件系统层次结构中)时,这种数据结构相当消耗空间:为文件的每次更改存储整个文件系统树很快会导致大量数据丢失。节点和边的数量。
我们遵循 Lukasczyk 等人的嵌套跟踪图定义聚合时间树 T = ( N , E T , E N ) T = (\mathcal{N} , E_T , E_N ) T=(N,ET,EN)。 [26] 适应节点 n t a , t b ℓ ∈ N \mathbf{n}_{t_a,t_b}^\ell\in\mathcal{N} nta,tbℓ∈N 在时间跨度 [ t a , t b ] [t_a,t_b] [ta,tb] 上存在并存储数据值的时间序列 [ d t a , . . . , d t b ] [d_{t_a} , ... ,d_{t_b}] [dta,...,dtb]。这允许对仅记录更改的数据值进行紧凑编码。图 3b 显示了一个示例。
我们也可以使用经典的树术语来表示 T \mathcal{T} T 。我们有不同的层次结构级别 ℓ \ell ℓ、父节点、子节点、叶子等。与 G G G 相比,我们定义 T \mathcal{T} T,使其始终具有单个根,我们可以从中访问时间树的所有其他部分,例如,通过以下方式分层边缘 E N \mathcal{E}_{N} EN。
虽然树在时间上不断演化,但它可能会发生结构变化。我们称它们为拓扑事件,它们是一个节点的出现、一个节点的消失、多个节点的合并、以及分裂成多个节点。合并和分割是计算布局时最重要的拓扑事件,因为它们要求所涉及的节点彼此相邻。合并和拆分事件如图 3 所示。
将 G G G 转换为 T \mathcal{T} T 非常简单,反之亦然。我们通过消除直接时间对应将 G G G 转换为 T \mathcal{T} T。如果边 ( u , v ) ∈ E T (\mathbf{u}, \mathbf{v}) ∈ E_T (u,v)∈ET 是 u \mathbf{u} u 的唯一传出时间边和 v \mathbf{v} v 的唯一传入时间边,则两个节点 u \mathbf{u} u, v \mathbf{v} v 具有直接的时间对应关系。我们将此类节点和边的链聚合为单个具有数据值时间序列的节点。我们通过收集 T \mathcal{T} T 中所有时间序列的所有时间步并将所有节点 n t a , t b ℓ ∈ N \mathbf{n}_{t_a,t_b}^\ell\in\mathcal{N} nta,tbℓ∈N 分解为一条链,将 T \mathcal{T} T 转换为 G G G,所有时间步与范围 [ t a , t b ] [t_a,t_b] [ta,tb] 重叠的时间步具有直接时间对应关系。
请注意,在图论中,节点被认为是零维结构,而我们的聚合节点是一维实体。因此,聚合节点在平面中绘制时可以彼此相交,这转化为两个节点-边链的平面嵌入中的边交叉。在本文的其余部分中,当提到“聚合节点”时,我们通常只会谈论“节点”。
我们还注意到,本文中的所有算法都可以在非聚合 G G G 或聚合 T \mathcal{T} T 上运行,从而产生不同的计算成本。最值得注意的是,第 4.2.3 节中的图形布局优化在聚合 T \mathcal{T} T 上运行时的计算时间大大缩短。我们在第 5 节中评估了我们方法的运行时方面。
4 时间树图
我们的目标是创建随时间变化的树(包括拓扑事件)的静态可视化。我们使用二维平面进行布局:一个维度代表时间,而另一个维度代表类似于一维树形图布局的分层嵌套(参见图 2c)。
下一节将其描述为图形绘制问题,并回顾现有方法的缺点。 4.2 节接下来是我们自己解决这个问题的方法。 4.3 节介绍了我们对缓冲树图对时间树的适应。
4.1 表征为绘图问题
我们的数据结构 T \mathcal{T} T 是一个分层嵌套图。如果我们独立地考虑每个层次结构级别,则每个级别中的节点形成一个有向图,其拓扑事件由 ET 中的边给出。这本身就已经是每个层次结构级别的图形绘制问题。
具有挑战性的部分是由于层次嵌套:目标是将所有这些图绘制在彼此内部,即层次结构级别 ℓ \ell ℓ 的图应绘制在层次结构级别 ℓ \ell ℓ −1的图内部。这意味着拓扑事件在层 ℓ \ell ℓ -1对层 ℓ \ell ℓ 中的图形绘制有影响。例如,考虑在时间 t i t_i ti 合并层 ℓ \ell ℓ −1 中的两个节点。他们每个人都有孩子,必须在层 ℓ \ell ℓ 中绘制这些孩子,以便他们在时间 t i t_i ti 彼此相邻,以适应父母的合并。如果子节点在时间 t i t_i ti 不是彼此相邻的,则它们需要与其他节点相交,以便从 t i t_i ti 开始绘制在新合并的父节点内。换句话说,层次嵌套对每一层的图形绘制都施加了约束。
卢卡斯奇克等人。 [26]提出了第一种绘制嵌套图的方法,方法是独立计算每个层次结构级别中的图形布局,并在最终绘制阶段强制它们相互嵌套。这导致最终图像中存在大量交叉点。每个层次结构级别的图形布局是使用 Graphviz 库 [17] 完成的。该库的优化图形布局确保在每个层次结构级别中尽可能避免交叉。但由于没有给出层次嵌套的知识,图形布局无法适应其他层次结构级别的约束。最后的绘图阶段仅直接使用
ℓ
\ell
ℓ= 0 的图形布局。所有其他级别都强制子级生活在其父级内部,如下所示:对于父级
p
\mathbf{p}
p 和时间步
t
i
t_i
ti ,在子级级别的图形布局中找到
p
\mathbf{p}
p 的子级,并按照与它们之前相同的顺序将它们绘制在
p
\mathbf{p}
p 内。在儿童层面遇到过。图 4 说明了每个级别的图形布局是如何独立完成的,以及这如何导致最终绘图阶段的交叉。这个例子是用[26]的原始软件创建的。
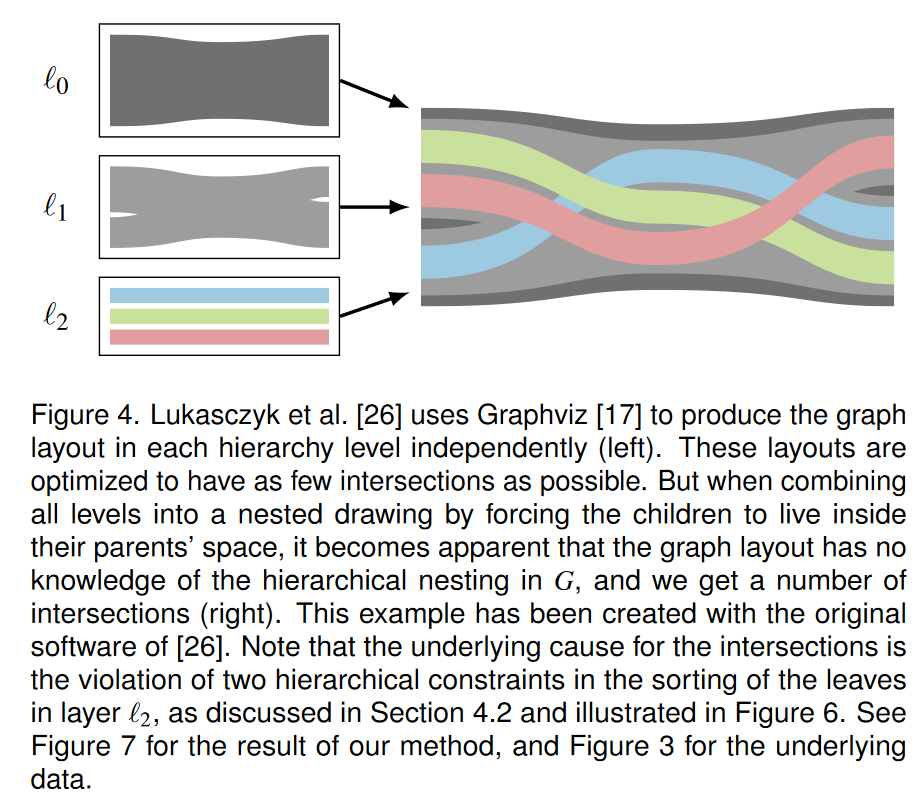
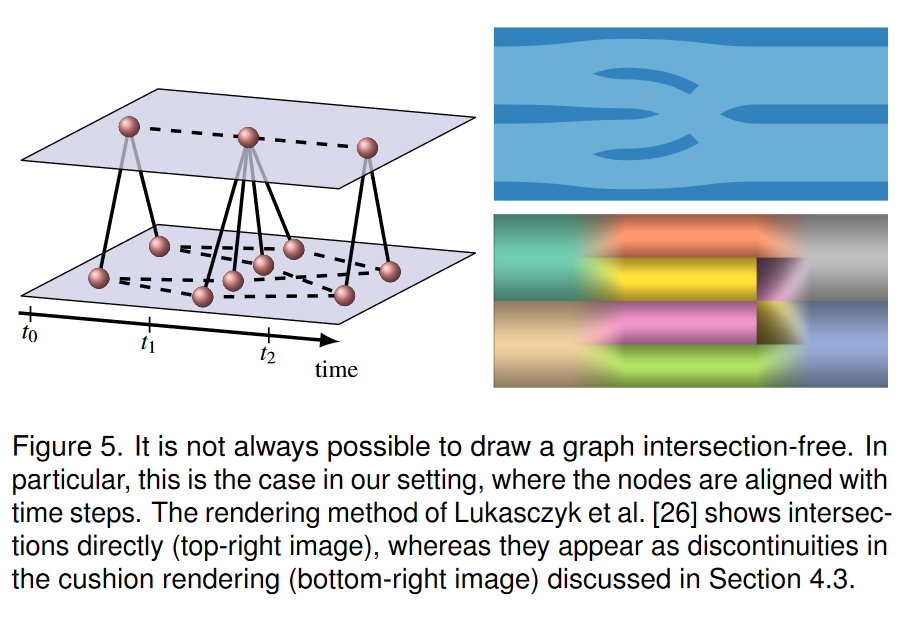
应该注意的是,并不总是可以绘制无交集的图。众所周知,并不是每个图都可以嵌入到平面中[5]。除此之外,我们的设置限制了嵌入,即节点与时间步对齐,即它们的 x 坐标是固定的。图 5 显示了一个示例。虽然不能期望每个数据集都有无交叉点的布局,但我们应该努力实现最少的交叉点数量。这是下一节的主题。
4.2 使用叶子约束排序的图形布局
时间树 T \mathcal{T} T 的嵌套绘制需要综合考虑各层次中的拓扑事件以及层次嵌套带来的约束。我们将这两个要求带入一个共同的环境中,在那里我们寻找具有最少交叉点的解决方案。
我们的方法以对 T \mathcal{T} T 的叶子进行排序为中心。我们将对直接从拓扑事件和 T \mathcal{T} T 的层次嵌套得出的顺序施加约束。我们提出了一种快速启发式和优化方法来找到满足大多数约束的排序。给定 T \mathcal{T} T 的叶顺序,我们展示如何计算 T \mathcal{T} T 的所有其他节点的排序顺序。详细信息如下。
4.2.1 排序和约束
令 B = { b 1 , … , b n } \mathcal{B}=\{\mathbf{b}_1,\ldots,\mathbf{b}_n\} B={b1,…,bn}是时间树 T 的所有叶子的集合,其中 B ⊆ N \mathcal{B}\subseteq\mathcal{N} B⊆N。我们的目标是为叶子建立一个排序,用 σ = ( b 1 , … , b n ) \sigma=(\mathbf{b}_1,\ldots,\mathbf{b}_n) σ=(b1,…,bn) 表示,它本质上是 B \mathcal{B} B 元素的有序序列,或者说是一种排列。这可以看作是一个函数,其中 σ ( b i ) \sigma(\mathbf{b}_i) σ(bi)返回 b i \mathbf{b}_i bi在排序中的索引。由于时间树的节点仅存在于特定时间跨度内,因此我们引入符号 σ ∣ t a , t b \sigma|_{t_a,t_b} σ∣ta,tb作为生命周期与时间跨度 [ t a , t b ] [t_a,t_b] [ta,tb]重叠的所有叶子的顺序。该限制排序是通过删除该时间跨度内不存在的叶子并保持所有其他元素的相对顺序,直接从无限制排序 σ σ σ 获得的。如果我们想要解决叶子子集 G \mathcal{G} G 的排序问题,与时间跨度无关,我们可以使用符号 σ ∣ G \sigma|^{\mathcal{G}} σ∣G。
我们引入排序约束作为工具,要求特定的叶子集合在给定的时间跨度内彼此相邻。更正式地,考虑一组叶子 G = { g 1 , . . . . , g n } \mathcal{G} = \{g_1,...., g_n\} G={g1,....,gn} 至少部分与时间跨度 [ t a , t b ] [t_a,t_b] [ta,tb] 重叠。如果这些叶子在相应的排序中彼此相邻,则满足排序约束 C = ( G , t a , t b ) C=(\mathcal{G},t_a,t_b) C=(G,ta,tb),可以表示为
∣ G ∣ = max G ( σ ∣ t a , t b ) − min G ( σ ∣ t a , t b ) + 1. ( 2 ) |\mathcal{G}|=\max_{\mathcal{G}}\left(\left.\boldsymbol{\sigma}\right|_{t_a,t_b}\right)-\min_{\mathcal{G}}\left(\left.\boldsymbol{\sigma}\right|_{t_a,t_b}\right)+1. \qquad (2) ∣G∣=Gmax(σ∣ta,tb)−Gmin(σ∣ta,tb)+1.(2)
请注意,我们不要求 G 中的叶子有特定的排序,只是要求它们之间没有其他叶子。
我们现在拥有将 T 的层次嵌套及其拓扑事件描述为排序约束所需的形式。我们对叶顺序引入以下约束:
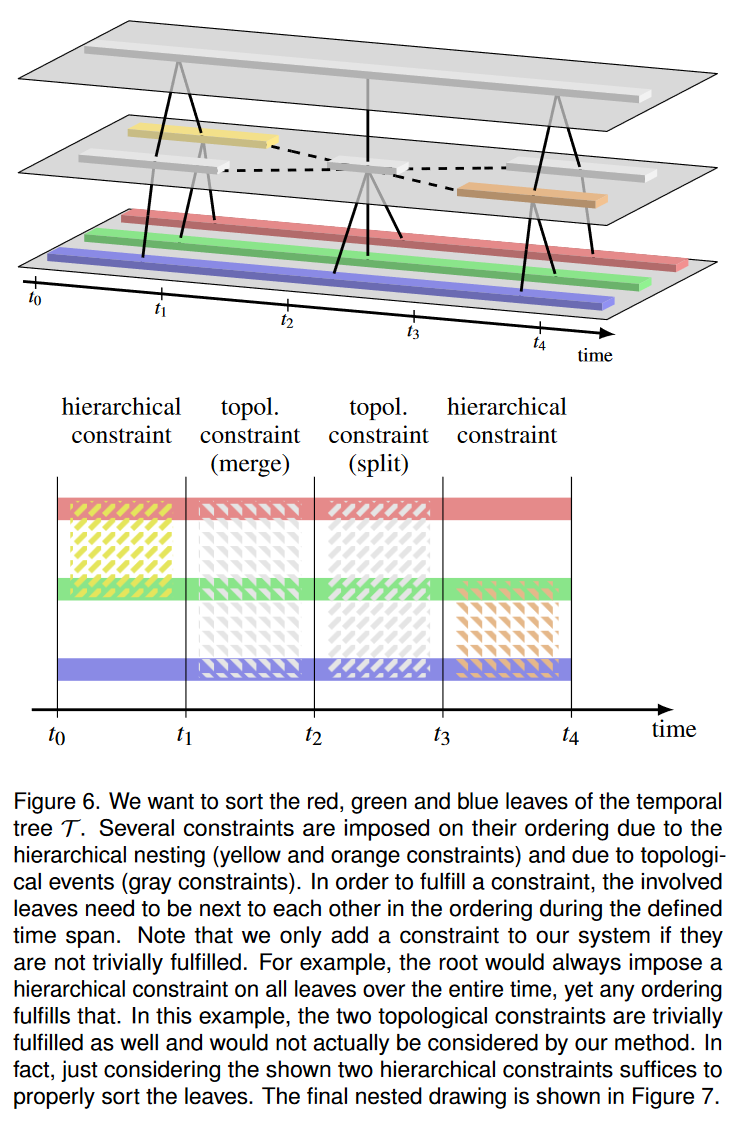
- 分层约束强制从内部节点p 可到达的叶子在p 的生命周期内彼此相邻。内部节点 p 可以是 T 的任何非叶节点。考虑到其生命周期 [ t a , t b ] [t_a,t_b] [ta,tb],层次约束正式写为 C H = ( l e a v e s ( p ) , t a , t b ) C_H=(\mathrm{leaves}(\mathbf{p}),t_a,t_b) CH=(leaves(p),ta,tb)。
- 拓扑约束强制从合并和分裂节点可到达的叶子在事件的时间步彼此相邻。合并/分裂事件发生在时间步 t i t_i ti,并且通过合并和/或分裂成生命周期从 t i + 1 t_{i+1} ti+1开始的节点 R \mathcal{R} R 而包括生命周期在 t i t_i ti 结束的节点 L \mathcal{L} L。拓扑约束的正式形式为 C T = ( l e a v e s ( L ∪ R ) , t i , t i + 1 ) C_T=(\mathrm{leaves}(\mathcal{L}\cup\mathcal{R}),t_i,t_{i+1}) CT=(leaves(L∪R),ti,ti+1)。
图 6 使用我们之前使用过的相同示例说明了这些约束。
假设对于给定的排序
σ
σ
σ ,不满足排序约束
C
=
(
G
,
t
a
,
t
b
)
C=(\mathcal{G},t_a,t_b)
C=(G,ta,tb) 。这意味着,叶子
G
=
{
g
1
,
.
.
.
.
,
g
n
}
\mathcal{G} = \{g_1,...., g_n\}
G={g1,....,gn} 彼此不相邻,因为许多其他叶子
H
=
{
h
1
,
…
,
h
m
}
\mathcal{H}=\{\mathbf{h}_1,\ldots,\mathbf{h}_m\}
H={h1,…,hm} 混合在:
σ ∣ t a , t b = ( … , g 1 , … , h 1 , … , g i , h j , … , h m , … , g n , … ) . ( 3 ) \sigma|_{t_a,t_b}=(\ldots,\mathbf{g}_1,\ldots,\mathbf{h}_1,\ldots,\mathbf{g}_i,\mathbf{h}_j,\ldots,\mathbf{h}_m,\ldots,\mathbf{g}_n,\ldots)\mathrm{~.~}\quad(3) σ∣ta,tb=(…,g1,…,h1,…,gi,hj,…,hm,…,gn,…) . (3)
我们总是可以通过将叶子 H \mathcal{H} H 移动到 g 1 g_1 g1 之前和/或 g n g_n gn 之后来满足这个约束,但可能会破坏其他约束。我们确定 m + 1 个新的排序顺序 σ σ σ 如下:
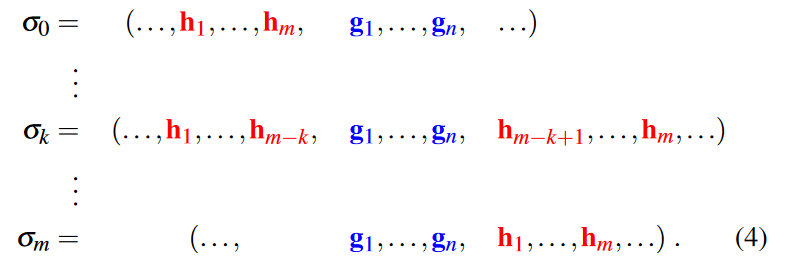
请注意,移动后的叶子 σ ∣ H \sigma|^{\mathcal{H}} σ∣H 的顺序不会改变,这对于保持其他约束完好无损可能至关重要。此外,叶子直接移动到 g 1 g_1 g1 前面或 g n g_n gn 后面,这也尽可能避免了与其他约束的潜在冲突。
如果排序 σ σ σ 满足所有约束,则可以在没有交集的情况下完成时间树的嵌套绘制。这直接来自上面的定义。如果排序 σ σ σ 不能满足所有约束,则视觉伪像的严重程度取决于所选的渲染方法。我们的目标是两种渲染方法:类似于 Lukasczyk 等人的嵌套绘图。 [26]以及我们提出的缓冲渲染(第4.3节)。前者将显示一定数量的交点,其中未满足的约束可能导致两条曲线之间出现单个交点,或者也可能导致更大的交点集(参见图 4)。另一方面,我们的缓冲渲染仅将叶子绘制为没有相交的曲线,但未满足的约束以缓冲着色中的视觉伪影的形式显示。图 5 显示了两种渲染方法如何处理违反的约束。
为了支持这两种渲染方法,我们专注于获得满足尽可能多的约束的 σ σ σ。在下文中,我们提出了一种可能足以满足更简单示例的启发式方法,以及一种适用于更大数据集的优化方法。
4.2.2 求解约束的启发式
考虑任何给定顺序的时间树的叶子。我们通过迭代所有内部节点和所有拓扑事件来记录上一节中讨论的排序约束。所有未满足的约束都被推入先进先出队列 (FIFO)。我们迭代这个队列:从队列中弹出第一个元素并检查它是否仍未完成后,我们计算新的排序顺序 σ 0 , . . . , σ m σ_0,..., σ_m σ0,...,σm 遵循上述 (4)。我们继续满足大多数约束的排序顺序。如果我们有其中几个,我们会随机选择其中之一。此过程未满足的所有约束都会被推入队列。 当队列为空时或经过一定次数的迭代(通常是在处理队列中的约束数量是我们开始时的约束数量的两倍之后),我们会停止此过程。
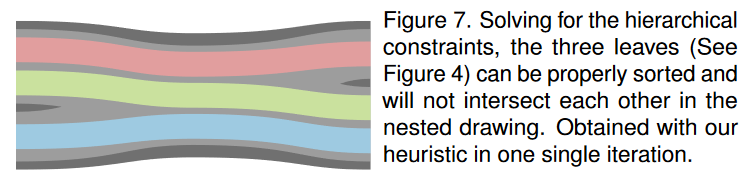
在许多情况下,这种启发式方法可以解决所有约束。图 7 显示了我们在本节中一直使用的示例数据集的计算排序。启发式算法能够通过一次迭代来解决这个问题。事实上,除了图 9 中的数据集之外,启发式方法能够为本文中的所有示例找到最佳解决方案。因此,我们认为这种启发式方法对于某些应用程序来说是一种易于实现的选项。
在复杂的数据集中,如图 9 所示的数据集或补充材料中所示的大图,这种启发式方法至少能够大幅减少未满足约束的数量。然而,它经常陷入循环,即它一遍又一遍地满足和打破相同的约束循环。尽管如此,在这些设置中,它仍然有助于为下一节中介绍的更高级的优化方法找到一个良好的起点。
4.2.3 求解约束的模拟退火
叶子顺序 σ σ σ 是时间树叶子的排列。如果我们有 n n n 个叶子,那么我们就有 n ! n! n!不同的 σ σ σ 。我们的目标是找到一个不违反或仅违反少量排序约束的特定叶顺序 σ σ σ。为此,我们应用了优化方法。这需要我们定义一个目标函数来为每个叶顺序分配质量度量。通过优化方法,我们尝试找到最小化该函数的叶序。
令 { C } \{C\} {C} 为所有层次和拓扑排序约束的集合。给定特定的叶顺序 σ σ σ ,其中一些可能会被违反。我们用 { C ˉ σ } \{\bar{C}^{\sigma}\} {Cˉσ} 表示给定 σ σ σ 的违反约束集。我们将违反率 v ( σ ) v(σ ) v(σ)定义为以标准化方式评估违反约束数量的方法:
ν ( σ ) = ∣ { C ˉ σ } ∣ ∣ { C } ∣ 0 ≤ ν ≤ 1. ( 5 ) \nu(\sigma)=\frac{|\{\bar{C}^{\sigma}\}|}{|\{C\}|}\quad0\leq\nu\leq1 .\qquad(5) ν(σ)=∣{C}∣∣{Cˉσ}∣0≤ν≤1.(5)
请注意, v v v 的值越低越好,即我们希望最小化该函数。优化问题现在可以表示为
arg min σ ν ( σ ) . ( 6 ) \arg\min_{\sigma} \nu(\sigma) .\qquad(6) argσminν(σ).(6)
我们使用模拟退火 [24] 来处理它,简而言之,它的工作原理如下:我们从初始叶序 σ 0 σ_0 σ0 开始。为了在每次迭代中计算新的叶阶 σ i σ_i σi,我们采用前一次迭代中的叶阶 σ i − 1 σ_{i−1} σi−1 并解决一个随机的、当前违反的约束。根据(4),这给了我们可能的几个新的叶序,我们随机选择一个,用 σ ′ σ ' σ′表示。如果 v ( σ ′ ) ≤ v ( σ i − 1 ) v(σ ′) ≤ v(σ_{i−1}) v(σ′)≤v(σi−1),则我们设置 σ i = σ ′ σ_i = σ′ σi=σ′并继续下一次迭代。然而,如果 v ( σ ′ ) > v ( σ i − 1 ) v(σ ′) > v(σ_{i−1}) v(σ′)>v(σi−1),则模拟退火的主要特征生效:新的叶序比前一个差,但它可能会被模拟退火尝试接受不要陷入局部最小值或循环。这是由一个称为温度 T 的参数控制的,该参数用一个高值进行初始化,然后以每 k k k 次迭代步骤应用的因子 0 < d < 1 0 < d < 1 0<d<1 缓慢衰减:
T 0 = T i n i t , T i = d T i − 1 . ( 7 ) T_0=T_{\mathrm{init}}, T_i=dT_{i-1}.\qquad(7) T0=Tinit,Ti=dTi−1.(7)
在这种情况下,如果温度高,我们更有可能选择较差的新叶顺序。接受更差叶序的概率计算为
p = e ν ( σ i − 1 ) − ν ( σ ′ ) T . ( 8 ) p=e^{\frac{\nu(\sigma_{i-1})-\nu(\sigma^{\prime})}T}.\qquad(8) p=eTν(σi−1)−ν(σ′).(8)
一旦温度降至接近零的阈值以下,或达到最大迭代次数,或满足所有约束,该过程就会停止。
我们使用通过上一节的启发式获得的叶顺序来初始化此优化。模拟退火始终能够改进初始排序。运行时间从几秒到几分钟不等,具体取决于问题的大小和初始温度。我们在第 5 节中详细评估了这种方法。
4.2.4 所有节点的排序顺序
绘制时间树需要对所有节点进行排序,这可以直接从叶顺序 σ σ σ 计算:对于 T \mathcal{T} T 的每个内部节点 p \mathbf{p} p,找到从 p \mathbf{p} p 可到达的 σ σ σ 中的第一个叶,并使用此索引对其他节点中的 p \mathbf{p} p 进行排序来自同一层次结构级别。
4.3 缓冲图的适配
在许多应用案例(例如文件系统)中,每个父节点的数据值是其子节点数据的总和,请参见等式(1)。如果绘图应该真实地表示数据,那么父级的整个空间都会被其子级占用。事实上,整棵树的叶子消耗了整个绘图空间,因为它们的数据总计为根的数据值。如图 7 所示,为父级留出空间的嵌套绘图并不是此类应用案例的最佳选择。
我们提出了一种时态树的绘制方案,完全考虑到了这些应用案例。它是经典缓冲树图 [38] 的改编,它计算 CPU 上每个像素的缓冲值。我们希望利用图形硬件并利用 GPU 来实现此目的。因此,我们将对树的叶子进行三角测量,并为每个顶点提供足够的信息,以便可以在着色器中的 GPU 上计算缓冲垫。我们将在下面详细介绍这一点。
首先,我们需要识别时间树中任何数据值发生变化的所有时间步。这可以通过迭代所有叶子并收集其时间序列的时间步来轻松获得。这个全局唯一且排序的时间步长列表用于划分绘图的时间轴(x 轴)。此外,我们还获得了这些时间步长的所有叶子数据值的总和。这可用于标准化每个时间步中的值。
正如刚才所观察到的,绘制叶子就足够了,因为叶子的总和等于根的数据值。给定优化的叶子顺序 σ σ σ ,我们从第一个叶子 b 1 b_1 b1 开始。它延伸到时间跨度 [ t a , t b ] [t_a,t_b] [ta,tb]。我们在绘图空间的底部放置一个三角形条。 x 坐标由 [ t a , t b ] [t_a,t_b] [ta,tb] 中的全局时间步长给出。 y 坐标由每个时间步长的标准化数据值给出。我们以相同的方式为每个后续叶子添加一个三角形条,只不过它们附加到先前绘制的叶子的顶部。
拓扑事件需要特殊处理。我们的目标是在最终的缓冲渲染中通过合并/分割高光曲线来指示合并或分割。我们进行如下转换:考虑一个分裂事件,其中叶子 b 1 b_1 b1 分裂成叶子 b 2 b_2 b2、 b 3 b_3 b3。由于我们的数据结构, b 1 b_1 b1 在分割时直接结束,而 b 2 b_2 b2、 b 3 b_3 b3 从那里开始。此外,它们的大小也匹配,即 d ( b 1 ) = d ( b 2 ) + d ( b 3 ) d(b_1) = d(b_2) + d(b_3) d(b1)=d(b2)+d(b3)。我们在事件发生之前将一个新顶点插入到 b 1 b_1 b1 的三角形带中。它直接放置在垫高光的顶部,并连接到 b 2 b_2 b2、 b 3 b_3 b3 的常规第一个顶点。这样,我们在数据分割之后对缓冲高光进行分割。这对于合并以及分割/合并次数超过两次的事件同样有效。
三角测量完成后,我们向每个顶点提供缓冲信息。缓冲渲染[38]的目标是即使在看不到父母的情况下也能传达分层信息。主要思想是模拟一个虚拟的“景观”,通过阴影揭示嵌套信息。基本上,树的每个节点都分配有一条抛物线,其高度取决于节点的层次结构级别。假设在给定时间步内将节点放置在 [y0, y1] 之间,则抛物线给出为:
Δ z ( y ) = 4 f ℓ h ( y − y 0 ) ( y 1 − y ) y 1 − y 0 , ( 9 ) \Delta z(y)=\frac{4f^\ell h\left(y-y_0\right)\left(y_1-y\right)}{y_1-y_0}, \qquad (9) Δz(y)=y1−y04fℓh(y−y0)(y1−y),(9)
其中 h 是所有垫子的基础高度, 0 < f < 1 0 < f < 1 0<f<1 确定随着层次级别的增加而发生的高度衰减。最终的缓冲“景观”是所有节点的抛物线之和。值得庆幸的是,两条抛物线之和本身就是一条抛物线!因此,我们可以通过为每片叶子分配适当总结的抛物线来描述最终的垫子“景观”。从技术上讲,我们将抛物线参数存储在叶子三角剖分的顶点,并使用它在 GPU 上执行着色计算。
最后,我们还使用颜色来表示层次嵌套。为此,我们从根开始遍历 T \mathcal{T} T ,访问每个节点并在用户定义的层次结构级别之间分配颜色。颜色以不同的方式选择,例如,沿着 HSV 颜色模型的色调轴随机选择,或使用不同的 colorbrewer 方案 [7]。
4.4 与时间树图交互
我们的最终可视化带有许多交互元素。颜色、坐垫、照明条件、节点选择等方面都可以在订单最终确定后进行交互修改。
通过利用 GPU 着色程序,我们可以交互地更改光属性,例如其方向或环境/漫反射颜色。对于垫子,改变参数 h 和 f 突出了层次结构的不同方面。较低的因子 f 会更加关注第一层次结构层,而较高的值则强调较深层的部分。高度 h 的变化导致整体高度轮廓变得更平坦或更陡峭。我们还可以选择着色和缓冲的深度范围。这允许通过关注选定的分层层来探索数据。还支持对时间跨度的进一步过滤和第一级层次结构节点的切换。
我们建议读者观看展示这些交互的补充视频。
5 评价
5.1 与 Lukasczyk 等人的比较[26]
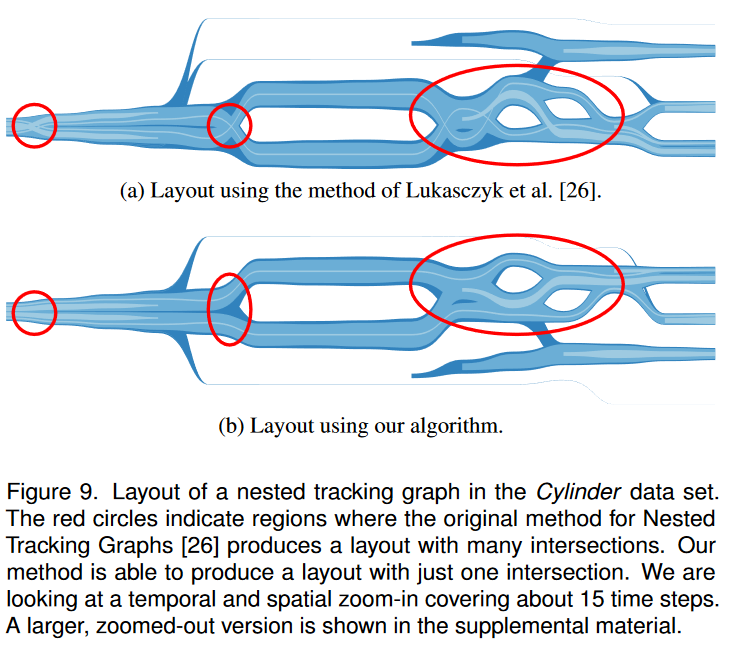
我们首先使用粘性手指数据集的特写进行比较,该数据集在嵌套跟踪图的原始方法的发布中使用[26]。我们感谢作者公开他们的代码和数据。图 8 显示了图形布局的并排比较。很容易看出,我们的方法创建了一个无交集的布局,而原始方法却无法做到这一点。
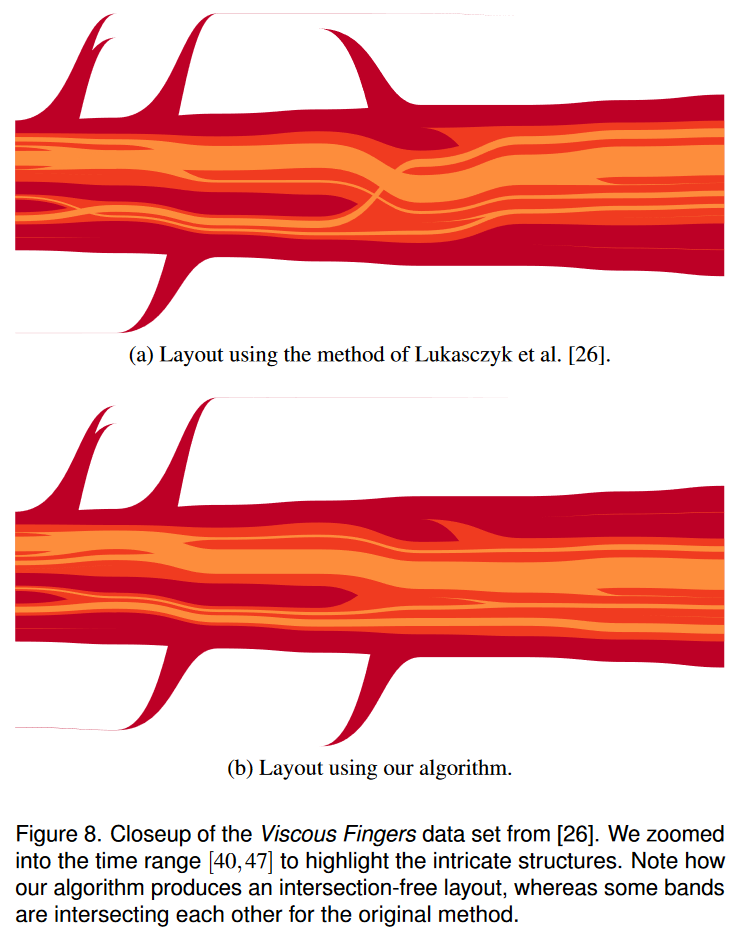
图 9 讲述了类似的情况,只不过该数据具有更多时间步长,并且显示了原始方法的更多交集。底层的时间相关数据(我们将其称为圆柱体数据集)通过 Okubo-Weiss 准则 [12, 39] 描述了方圆柱体尾迹中的涡流活动。我们查看 15 个时间步长的时间放大的一部分。
在表 1 中,我们以定量方式比较了两种方法所采用的数据结构。对于每个时间步只有少数节点发生变化的数据集,我们新的聚合时间树 T 的压缩率最高。 Pyhton 数据集就是一个例子,因为它通过扫描从 20 世纪 90 年代至今的时间范围内对存储库的超过 10 万次提交来记录对 Python 源代码文件树的所有更改。
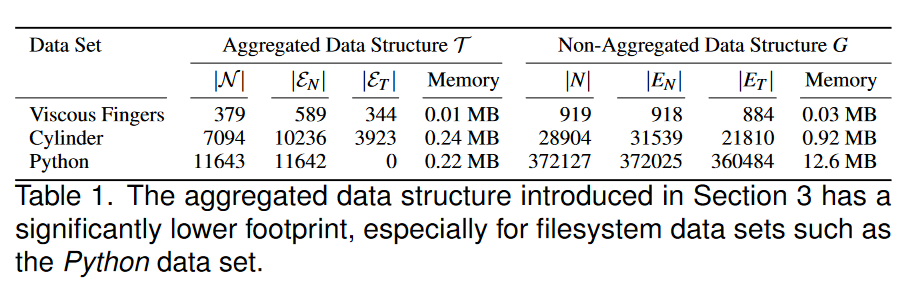
聚合最重要的优点是大大减少了我们算法的计算时间。例如,我们的方法需要 30 秒来处理总共 508 个时间步长的 Cylinder 数据集的聚合版本。非聚合版本的运行时间为 30 分钟。
我们认为将我们的方法与 Lukasczyk 等人的方法进行比较是不可行的,也没有建设性。 [26]在计算时间方面。我们采用截然不同的技术。而卢卡斯奇克等人。 [26] 大部分布局都调用 Graphviz,最终的绘制发生在浏览器中的 Javascript 中。在我们的例子中,一切都是用 C++ 本机完成的。尽管如此,在这两种情况下,用户都必须等待超过半分钟才能得到结果。
然而,应该指出的是,我们的方法只需要不到一秒的时间就可以得到如图 8b 和 9b 所示的结果。
5.2 模拟退火评价
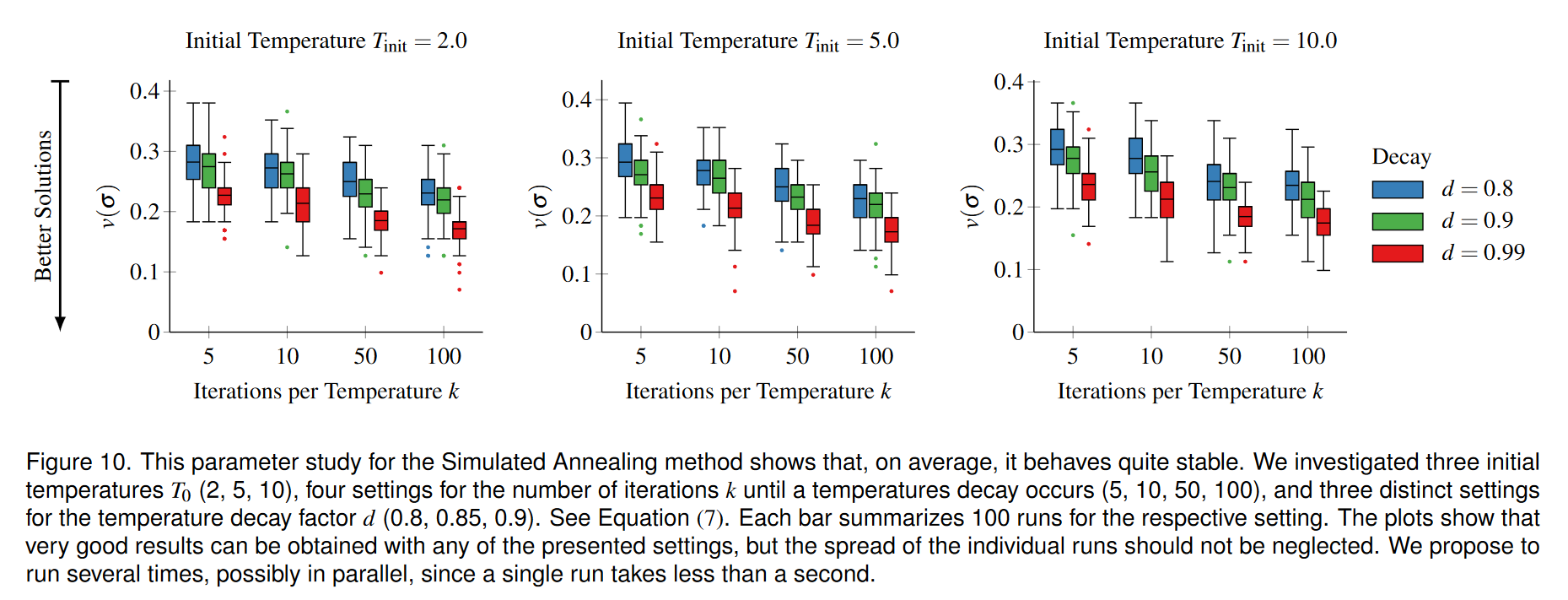
图 11 绘制了在图 9b 所示的 Cylinder 数据集上运行模拟退火方法期间违反约束的数量。该方法一开始只违反了一些约束,但经过大约 25 次迭代并且温度仍然很高,它选择恶化条件并打破一些约束,以尝试找到全局更好的解决方案。这是模拟退火的典型行为,实际上也是其优点之一。一旦温度冷却下来,波动就会减少,该方法在迭代 350 次左右找到了一个好的解决方案。整个过程只需不到一秒。
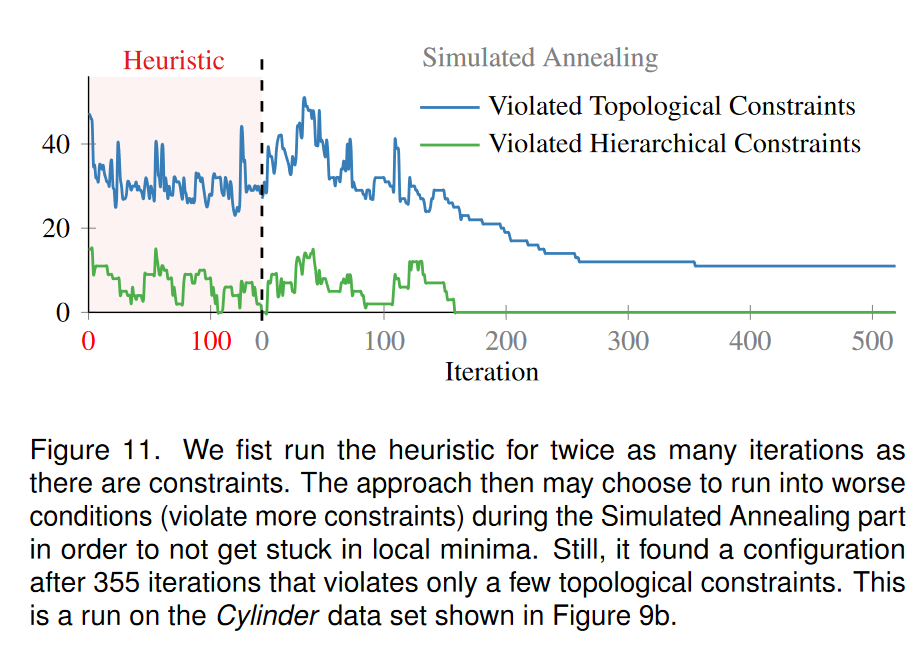
我们对同一数据集进行了参数研究。我们研究了三个初始温度、发生温度衰减之前的迭代次数的四种设置以及温度衰减因子的三种设置。我们对整个定义的 3D 参数空间运行模拟退火,图 10 显示了结果的三个二维投影。这些图表明,通过许多不同的设置可以获得非常好的结果。我们观察到运行时间较长的参数设置有一点优势,即初始温度较高、每个温度的迭代次数较多以及衰减较高。平均而言,该方法表现良好并产生稳定的结果。然而,由于它在设计上使用随机性,因此需要考虑各个运行的分布。例如,建议多次运行该方法并选择最佳结果。这可以并行完成。我们的实现目前不是并行的,并且在当前硬件上需要不到一秒的时间。
6 结果
除了已经显示的结果之外,我们还想通过另外三个数据集来展示我们的方法的实用性。
我们的方法可以使用不同类型的数据标准化。图 12 举例说明了联合国在《世界人口展望:2017 年修订版》[35] 中根据对生育率、死亡率和净移民做出假设的不同模型所预测的到 2100 年世界人口的发展情况。我们在这里展示了九个变体中的两个;有关所有变体和详细信息,请参阅补充材料。图 12a 显示了假设生育率和死亡率保持不变的人口发展情况。左图显示了每个时间步标准化的数据。这利用了整个可视化空间并支持相对规模比较:欧洲占世界人口的比例在整个时间跨度内都在下降,亚洲的比例自 21 世纪初以来一直在下降,而到 2100 年,超过每秒钟的人口将生活在非洲。图 12a 中的右图显示了相同的绝对数据(标准化为全球最大值),这表明至少所有地区的绝对人口数都是恒定的自 21 世纪初以来,除了非洲出现强劲增长外。请注意,该模型被认为是不切实际的。根据[35],最有可能的模型如图 12b 所示。右图显示世界人口约为 110 亿。
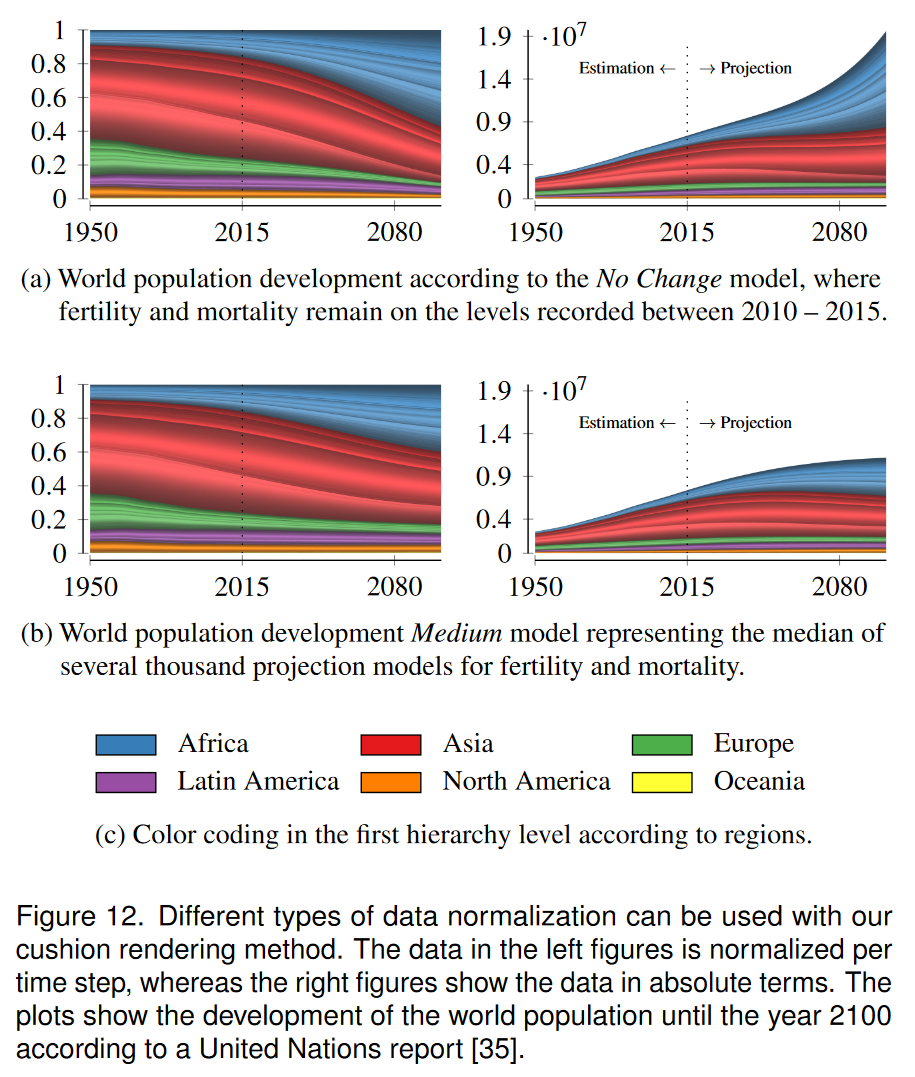
上一个示例中的数据不包含拓扑事件,尽管对历史的准确描述会显示国家的分裂和合并。尤其是欧洲,在20世纪已经发生过很多这样的案例。我们使用 1975 年至 2016 年间欧洲人口的最新可用人口数据 [34],并遵循 1990 年德国统一和 1991 年苏联解体等历史事件。图 13 中的结果显示了缓冲渲染的情况有效传达这些事件。

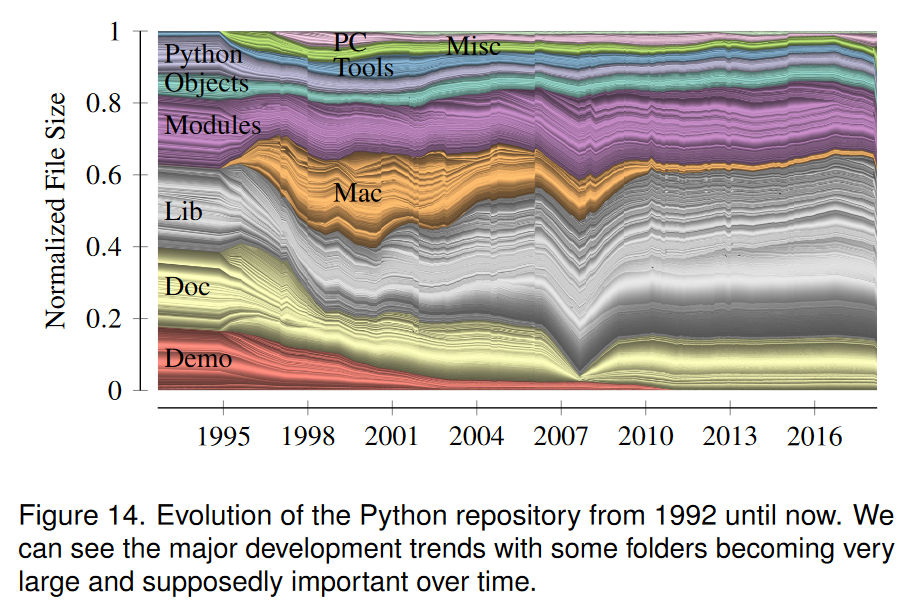
图 14 显示了 CPython 源代码存储库 [13] 自早期开发以来的发展情况。涵盖的时间跨度为 1992 年 8 月至 2018 年 3 月,通过对 101181 次提交中的每 1000 个采样进行采样而获得。彩色垫渲染有效地揭示了两个有趣的事件。首先,Doc 文件夹的相对大小在 2007 年首先减小,然后急剧增加:Python 文档从 LATEX切换到 reStructuredText,并且在很短的时间内 Doc 文件夹根本不存在。其次,Mac文件夹似乎是在1995年左右才添加的。经过进一步调查,这个文件夹从一开始就存在,尽管几乎是空的。 1994 年 8 月介绍了如何在 Mac 上使用 Python。图 14 显示我们的渲染方法可用于识别此类数据的主要趋势。我们当前实施的一个缺点也可以看出。我们不应用任何形式的平滑,这使得绘图的某些部分相当不连续。此外,还有待确定,例如通过用户研究,缓冲垫是否单独允许感知数据的分层性质。我们怀疑颜色和坐垫的结合是必要的。
7 结论和未来工作
我们提出了一种新颖的布局算法,用于随着拓扑和数据的变化而随时间演化的树。基于启发式和模拟退火的组合,它生成具有尽可能少的交叉点的布局。我们的评估表明,该算法运行速度很快,这也是由我们用于时间演化树的新数据结构(仅记录树的变化)所促进的。我们新的基于缓冲的渲染方案同时强调了时间演变和层次嵌套。
等式(5)中当前的目标函数本质上只计算违反约束的数量。对于未来的研究来说,这是一个有趣的途径,可以结合更多方面,例如未满足约束的视觉伪影的严重性,具体取决于所选的渲染方法、相关数据值(最终绘图中的厚度)或最终绘图的摆动度类似于 Bartolomeo 和 Hu [2] 对流图的做法。
我们排除了孩子改变父母的情况。这种情况在文件系统中经常发生:文件从一个文件夹移动到另一个文件夹。在图 13 中,我们通过将父节点分为两个单独的节点来为苏联建模:一个在移动之前,一个在移动之后。然而,对于具有许多移动节点的数据集,分割的引入会降低我们的数据结构所获得的一些效率。直接支持将节点移动到不同的父节点是可取的,但任何此类移动都会导致绘图中的交叉点,因为子节点需要跨越到另一个父节点。尽管如此,人们还是能够最大限度地减少相交带的数量。
此外,我们相信通过链接和刷动将其连接到快照可视化可以增强可视化的导航。卢卡斯奇克等人。 [26] 在嵌套跟踪图旁边显示层次结构级别的等值面,允许选择和突出显示组件。对于其他类型的数据集(文件系统、世界人口),2D 树状图或世界地图可以用于可视化不同上下文中所选时间步的状态。
致谢
这项工作得到了瑞典战略研究基金会 (SSF) 和瑞典电子科学研究中心 (SeRC) 的资助。所提出的概念已在 Inviwo 框架中实现。
参考文献





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









