










BAT机器学习面试1000题系列
整理:July、元超、立娜、德伟、贾茹、王剑、AntZ、孟莹等众人。本系列大部分题目来源于公开网络,取之分享,用之分享,且在撰写答案过程中若引用他人解析则必注明原作者及来源链接。另,不少答案得到寒小阳、管博士、张雨石、王赟、褚博士等七月在线名师审校。
说明:本系列作为国内首个AI题库,首发于七月在线实验室公众号上:julyedulab,并部分更新于本博客上,且已于17年双十二当天上线七月在线官网、七月在线Android APP、七月在线iPhone APP,后本文暂停更新和维护,另外的近3000道题都已更新到七月在线APP或七月在线官网题库板块上,欢迎天天刷题。另,可以转载,注明来源链接即可。
前言
July我又回来了。
之前本博客整理过数千道微软等公司的面试题,侧重数据结构、算法、海量数据处理,详见:微软面试100题系列,今17年,近期和团队整理BAT机器学习面试1000题系列,侧重机器学习、深度学习。我们将通过这个系列索引绝大部分机器学习和深度学习的笔试面试题、知识点,它将更是一个足够庞大的机器学习和深度学习面试库/知识库,通俗成体系且循序渐进。
此外,有四点得强调下:
- 虽然本系列主要是机器学习、深度学习相关的考题,其他类型的题不多,但不代表应聘机器学习或深度学习的岗位时,公司或面试官就只问这两项,虽说是做数据或AI相关,但基本的语言(比如Python)、编码coding能力(对于开发,编码coding能力怎么强调都不过分,比如最简单的手写快速排序、手写二分查找)、数据结构、算法、计算机体系结构、操作系统、概率统计等等也必须掌握。对于数据结构和算法,一者 重点推荐前面说的微软面试100题系列(后来这个系列整理成了新书《编程之法:面试和算法心得》),二者 多刷leetcode,看1000道题不如实际动手刷100道。
- 本系列会尽量让考察同一个部分(比如同是模型/算法相关的)、同一个方向(比如同是属于最优化的算法)的题整理到一块,为的是让大家做到举一反三、构建完整知识体系,在准备笔试面试的过程中,通过懂一题懂一片。
- 本系列每一道题的答案都会确保逻辑清晰、通俗易懂(当你学习某个知识点感觉学不懂时,十有八九不是你不够聪明,十有八九是你所看的资料不够通俗、不够易懂),如有更好意见,欢迎在评论下共同探讨。
- 关于如何学习机器学习,最推荐机器学习集训营系列。从Python基础、数据分析、爬虫,到数据可视化、spark大数据,最后实战机器学习、深度学习等一应俱全。
另,本系列会长久更新,直到上千道、甚至数千道题,欢迎各位于评论下留言分享你在自己笔试面试中遇到的题,或你在网上看到或收藏的题,共同分享帮助全球更多人,thanks。
限于篇幅,完整版可以扫码领取,添加时备注:领取面经100篇

BAT机器学习面试1000题系列
101 准备机器学习面试应该了解哪些理论知识?机器学习 ML模型 中
@穆文,来源:https://www.zhihu.com/question/62482926
看下来,这些问题的答案基本都在本BAT机器学习面试1000题系列里了。

102 标准化与归一化的区别?机器学习 ML基础 易
@艾华丰,本题解析来源:https://www.zhihu.com/question/20467170
归一化方法:
1、把数变为(0,1)之间的小数主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
2、把有量纲表达式变为无量纲表达式 归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
标准化方法: 数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
随机森林如何处理缺失值?机器学习 ML模型 中
方法一(na.roughfix)简单粗暴,对于训练集,同一个class下的数据,如果是分类变量缺失,用众数补上,如果是连续型变量缺失,用中位数补。
方法二(rfImpute)这个方法计算量大,至于比方法一好坏?不好判断。先用na.roughfix补上缺失值,然后构建森林并计算proximity matrix,再回头看缺失值,如果是分类变量,则用没有缺失的观测实例的proximity中的权重进行投票。如果是连续型变量,则用proximity矩阵进行加权平均的方法补缺失值。然后迭代4-6次,这个补缺失值的思想和KNN有些类似12。
103 随机森林如何评估特征重要性?机器学习 ML模型 中
衡量变量重要性的方法有两种,Decrease GINI 和 Decrease Accuracy:
1) Decrease GINI: 对于回归问题,直接使用argmax(VarVarLeftVarRight)作为评判标准,即当前节点训练集的方差Var减去左节点的方差VarLeft和右节点的方差VarRight。
2) Decrease Accuracy:对于一棵树Tb(x),我们用OOB样本可以得到测试误差1;然后随机改变OOB样本的第j列:保持其他列不变,对第j列进行随机的上下置换,得到误差2。至此,我们可以用误差1-误差2来刻画变量j的重要性。基本思想就是,如果一个变量j足够重要,那么改变它会极大的增加测试误差;反之,如果改变它测试误差没有增大,则说明该变量不是那么的重要。
104 优化Kmeans?机器学习 ML模型 中
使用kd树或者ball tree
将所有的观测实例构建成一颗kd树,之前每个聚类中心都是需要和每个观测点做依次距离计算,现在这些聚类中心根据kd树只需要计算附近的一个局部区域即可
105 KMeans初始类簇中心点的选取。机器学习 ML模型 中
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。
1. 从输入的数据点集合中随机选择一个点作为第一个聚类中心
2. 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3. 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4. 重复2和3直到k个聚类中心被选出来
5. 利用这k个初始的聚类中心来运行标准的k-means算法
106 解释对偶的概念。机器学习 ML基础 易
一个优化问题可以从两个角度进行考察,一个是primal 问题,一个是dual 问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM中就是将primal问题转换为dual问题进行求解,从而进一步引入核函数的思想。
107 如何进行特征选择?机器学习 ML基础 中
特征选择是一个重要的数据预处理过程,主要有两个原因:一是减少特征数量、降维,使模型泛化能力更强,减少过拟合;二是增强对特征和特征值之间的理解
常见的特征选择方式:
1. 去除方差较小的特征
2. 正则化。1正则化能够生成稀疏的模型。L2正则化的表现更加稳定,由于有用的特征往往对应系数非零。
3. 随机森林,对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。一般不需要feature engineering、调参等繁琐的步骤。它的两个主要问题,1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。
4. 稳定性选择。是一种基于二次抽样和选择算法相结合较新的方法,选择算法可以是回归、SVM或其他类似的方法。它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。理想情况下,重要特征的得分会接近100%。稍微弱一点的特征得分会是非0的数,而最无用的特征得分将会接近于0。
108 数据预处理。机器学习 ML基础 易
1. 缺失值,填充缺失值fillna:
i. 离散:None,
ii. 连续:均值。
iii. 缺失值太多,则直接去除该列
2. 连续值:离散化。有的模型(如决策树)需要离散值
3. 对定量特征二值化。核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。如图像操作
4. 皮尔逊相关系数,去除高度相关的列
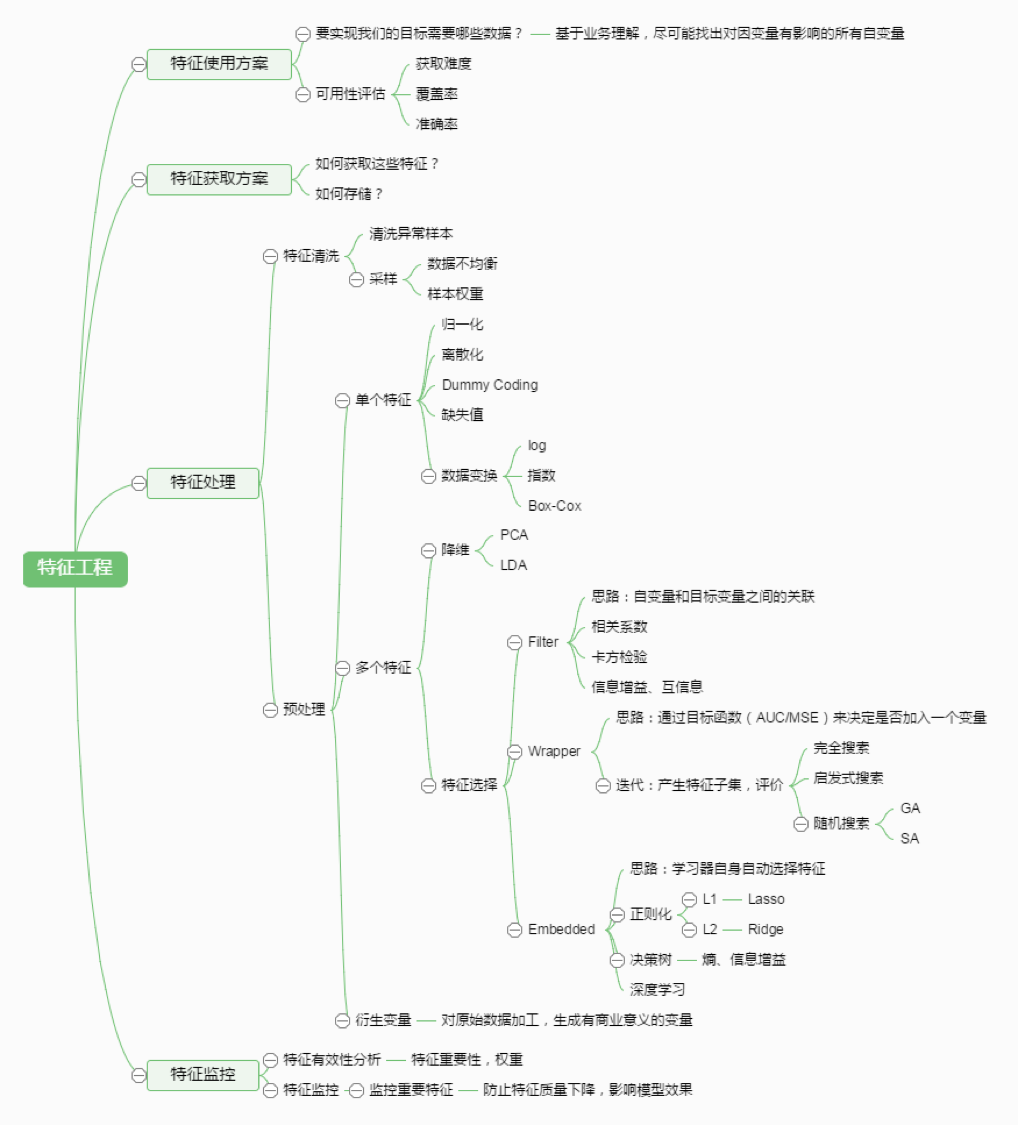
109 简单说说特征工程。机器学习 ML基础 中
上图来源:http://www.julyedu.com/video/play/18

110 你知道有哪些数据处理和特征工程的处理?机器学习 ML应用 中
更多请查看此课程《机器学习工程师 第八期 [六大阶段、层层深入]》第7次课 特征工程。
后记
熟悉我的朋友可能已经知道,我个人从 2010 年开始在CSDN写博客,写了十年,如今接近1700万PV,创业做「七月在线」则已五年,五年已30多万学员。这五年经历且看过很多的人和事,比如我们的机器学习集训营帮助了超过1000人就业、转型、提升,他们就业后有的同学会分享面经,当看到那一篇篇透露着面经作者本人的那股努力、那股不服输的劲的面经的时候,则让我倍感励志。比如“双非渣本三年 100 次面试经历精选:从最初 iOS 前端到转型面机器学习” 这篇面经,便让我印象非常深刻。在佩服主人公毅力和意志的同时,也对他愿意分享对众多人有着非常重要参考价值和借鉴意义的成功经验倍感欣慰。
当然,类似的面经远远不止于此,后来我们整理出了100篇面经,汇总成册为《名企AI面经100 篇:揭开三个月薪资翻倍的秘诀》,这 100 篇面经分为机器学习、深度学习、 CV、NLP、推荐系统、金融风控、计算广告、数据挖掘/数据分析八大方向。分享面经的作者各种背景都有,比如
- 科班,或非科班;
- 985、211,或双非院校;
- 研究生或本科,甚至大专;
- 学生,或在职;
- 至于传统IT转型 AI 的就更多了,有从 Java、PHP、C、C++等偏后端服务转型的,也有从 Android、iOS、前端等偏客户端开发转型的,当然也有数据分析、大数据方向等转型的。
但令人振奋的是,他们都转型成功了,而且他们中的很多人都通过集训营/就业班三个月到半年的学习,成功实现薪资翻倍——这些成功的经验就更值得借鉴了。
就业部的同事特地将这些宝贵的经验整理出来,希望可以帮到更多人。
限于篇幅,完整版可以扫码领取,添加时备注:领取面经100篇















 50万+
50万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









