






Python利用模糊查询两个excel文件数据 导出新表格
实际工作中,需要将两个excel表格中的数据进行模糊查询,最后将查询结果按照要求生成新的表格文件。
例如:领导安排了一个报表,需要将表2(缺陷查询数据导出.xls)中的厂站名称,缺陷描述对照表1(设备台账统计.xlsx)进行统计,表2的内容如下:

再看看表1
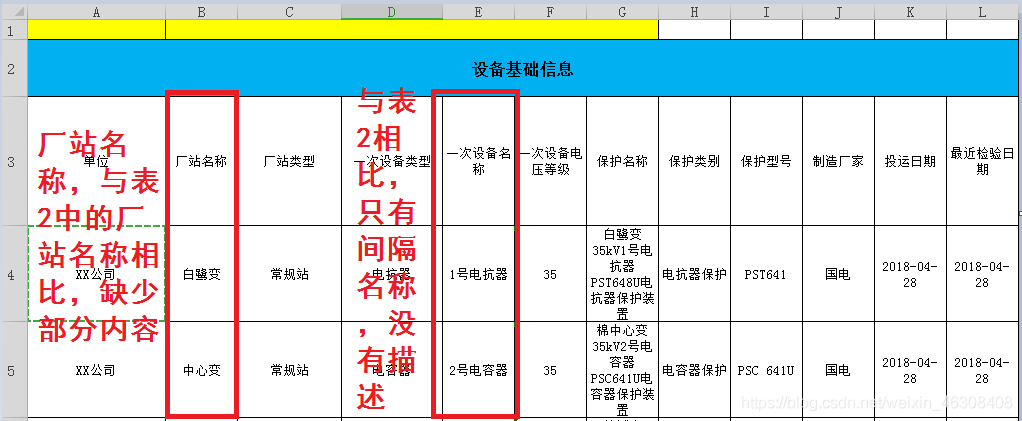
具体要求是,对照表1厂站名称,按个对表2中的厂站名称进行查找,查找后再对照表1中间隔名称查找表2中缺陷描述内容,最后把有缺陷的内容按照表1的顺序重新生成一个表格(PS:本来想在表1中更新,学的不扎实,没搞出来)。手动查询,无奈表格数据达到几万条,泪奔!!!
进过两天学习,看大神的代码(大部分看不懂),基本完成目标,顺利解放小拇指,具体代码如下:
# code=utf-8
import xlrd
import xlwt
import time
xlsx_new = xlrd.open_workbook('设备台账统计.xlsx')
sheets_new = xlsx_new.sheet_by_index(1) # 读取第二个表
xlsx_quexian = xlrd.open_workbook('缺陷查询数据导出.xls')
sheets_new_quexian = xlsx_quexian.sheet_by_index(1)
new_workbook = xlwt.Workbook()
worksheet = new_workbook.add_sheet('new_sheet')
xlsx1_row = sheets_new.nrows # 读取表1总列数
xlsx2_row = sheets_new_quexian.nrows # 读取表2总列数
all_date1 = [] # 存储表1数据,列表
all_date2 = [] # 存储表2数据,列表
quexian_huizong = ''
mun = 0 # 用于记录缺陷总数
mun1 = 0 # 用于记录当前执行表1中的次数
mun2 = 0 # 用于记录当前执行表2中的次数
print('表1总行数为:', xlsx1_row, '表2总行数为:', xlsx2_row, )
print('查询花费时间较长!!!!!''马上开始......')
time.sleep(1) # 等待1秒
for i in range(3, xlsx1_row): # 读取总的行数
key_biandianzhan = sheets_new.cell(i, 1).value # 读取表1中变电站名称
key_jiangemingcheng = sheets_new.cell(i, 4).value # 读取变电站间隔名称
date1 = {'key_biandianzhan': key_biandianzhan, 'key_jiangemingcheng': key_jiangemingcheng} # 设置字典
all_date1.append(date1) # 将表1中数据写入列表
print('表1数据复制成功!!!')
time.sleep(1) # 等待1秒
for j in range(3, xlsx2_row): # 表2总列数
key_biandianzhan_quexian = sheets_new_quexian.cell(j, 5) # 读取表2中变电站名称
key_jiangemingcheng_quexian = sheets_new_quexian.cell(j, 7) # 读取变电站缺陷
date2 = {'key_biandianzhan_quexian': key_biandianzhan_quexian,
'key_jiangemingcheng_quexian': key_jiangemingcheng_quexian} # 将表2中数据写入字典
all_date2.append(date2)
print('表2数据复制成功!!!')
time.sleep(1) # 等待1秒
print('开始查询....................')
for l in all_date1: # for循环从表1中提取变电站
biandianzhan = l['key_biandianzhan'] # 将列表1中的数据赋值到变量biandianzhan
jiangemingcheng = l['key_jiangemingcheng'] # 将列表1中的间隔名称赋值到jiangemingcheng
mun1 = mun1 + 1
print(biandianzhan)
quexian_huizong = '' #用于检测
mun2 = 0
for k in all_date2: # for循环从第二个字典中提取数据
biandianzhan_quexian = k['key_biandianzhan_quexian'] # 将列表2中变电站数据赋值到变量biandianzhan_quexian
jiangemingcheng_quexian = k['key_jiangemingcheng_quexian'] # 将列表2中变电站数据赋值到变量jiangemingcheng_quexian
mun2 = mun2 + 1 #
if str(biandianzhan) in str(biandianzhan_quexian): # 判断语句,判断表1中变电站名称在表2变电站名称,表1变电站名称相对表2变电站名称存在描述不全现象。
if str(jiangemingcheng) in str(jiangemingcheng_quexian): # 判断语句,判断表1中变电站间隔名称在包含在表2中缺陷描述。
quexian_huizong = str(jiangemingcheng_quexian) + str(quexian_huizong)
quexian_huizong = str(jiangemingcheng_quexian) + str(quexian_huizong)
print('------总进度', mun1, '/', xlsx1_row, ' 分进度', mun2, '/', xlsx2_row, '------') # 打印判断进度
mun = mun + 1 # 缺陷数量加1
print('找到', mun, '条符合条件缺陷') # 打印当前查到的缺陷数量
print('变电站名称:',
biandianzhan, '缺陷描述:', jiangemingcheng_quexian) # 打印当前查询到的变电站名称和缺陷描述
worksheet.write(mun1,0,biandianzhan) #数据写入新的工作表
worksheet.write(mun1,1,jiangemingcheng) #数据写入新的工作表
worksheet.write(mun1,2,quexian_huizong) #数据写入新的工作表
new_workbook.save('生成数据.xls')
print('执行完毕!!!')
执行后在当前目录下生成新的excel文件,已经按照表2顺序对缺陷进行统计。
当然还是有部分内容没有完全搞清楚,字符串里面有个字典,怎么赋值,还有有没有其他的方法可以更加方便的实现该功能,希望大神不吝赐教。
记录于2020年2月26日














 2254
2254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









