






文章目录
机器学习之其他常用技术——决策树
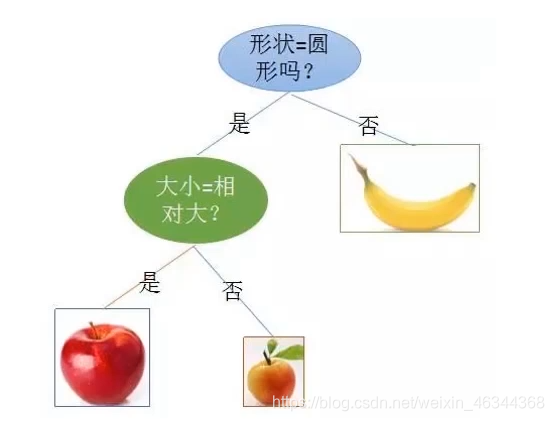
决策树:
一种对实例进行分类的树形结构,通过多层判断区分目标所属类别
本质:通过多层判断,从训练数据集中归纳出一组分类规则
优点:
计算量小,运算速度较快
易于理解,可清晰查看各属性的重要性
缺点:
忽略属性间的相关性
样本类别分布不均匀时,容易影响模型表现
举个栗子:
任务:根据用户的学习动力、能力提升意愿、兴趣度、空余时间,判断其是否适合学习AI。
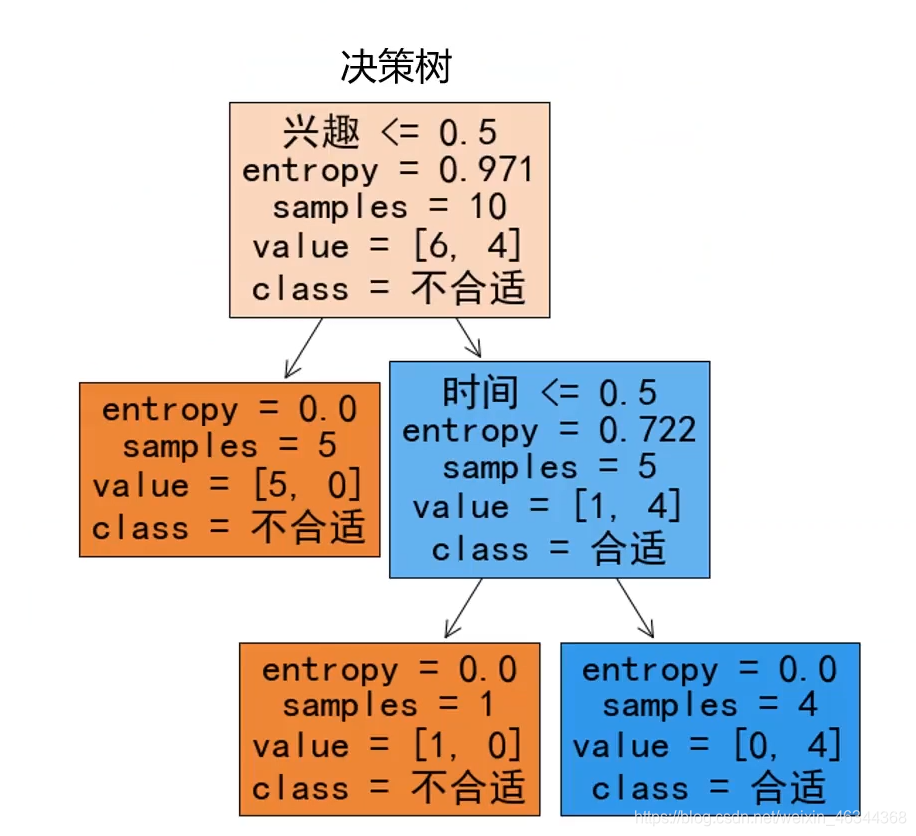
可以给出下图所示的决策树模型框架
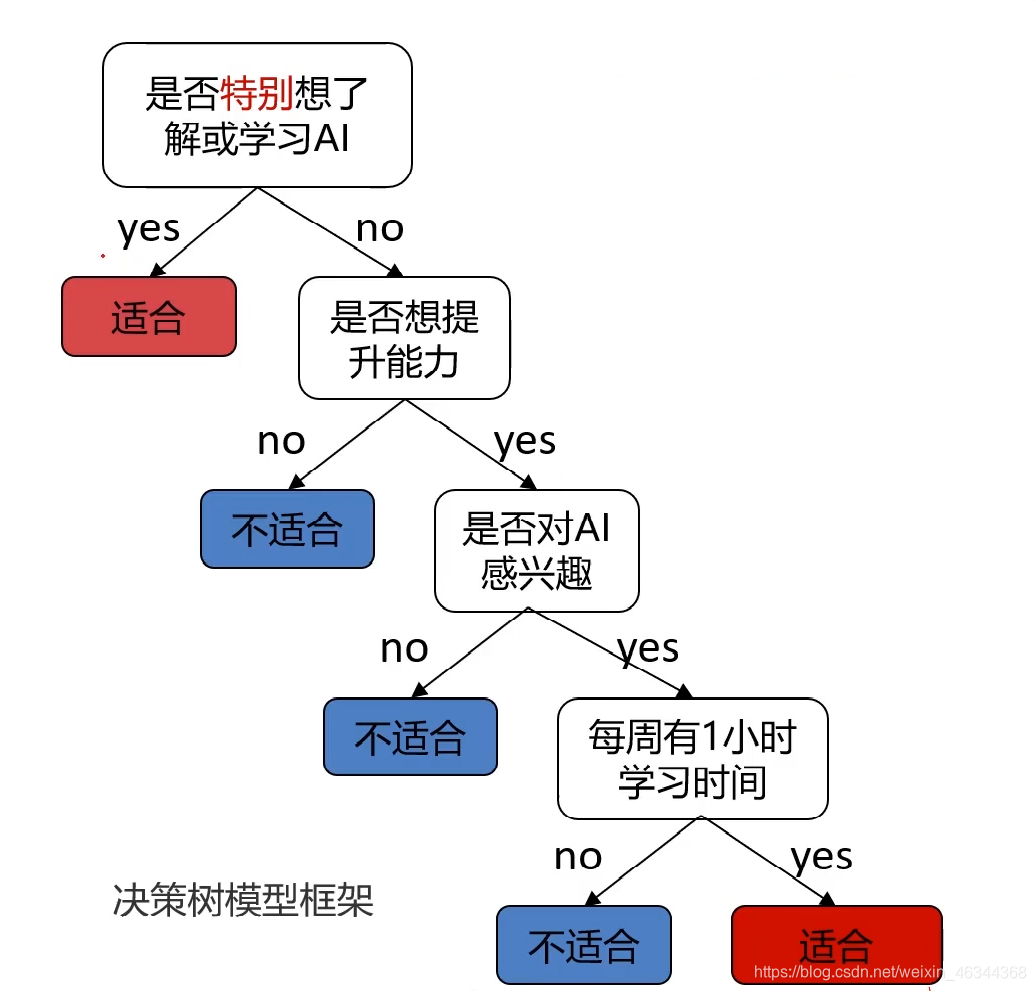
这里就是通过多层判断来对用户是否适合学习AI给出一个结论。
决策树求解

问题核心:特征选择,每一个节点。应该选用哪个特征。
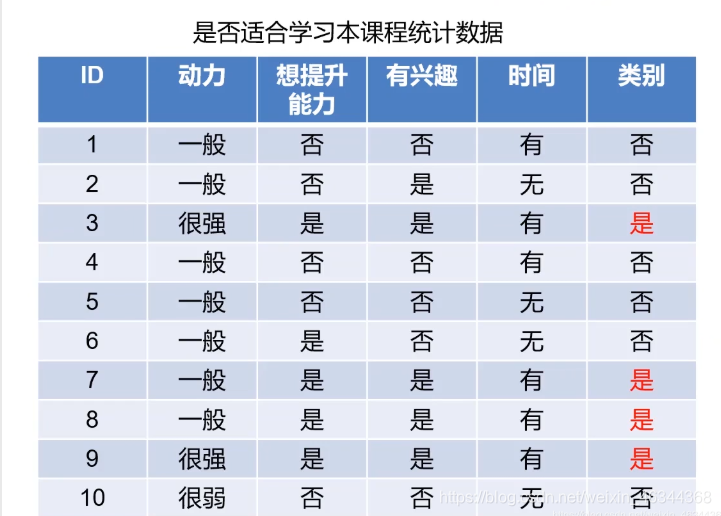
继续上面那个例子,这里有一个含有10个样本数据的表格(如下图):
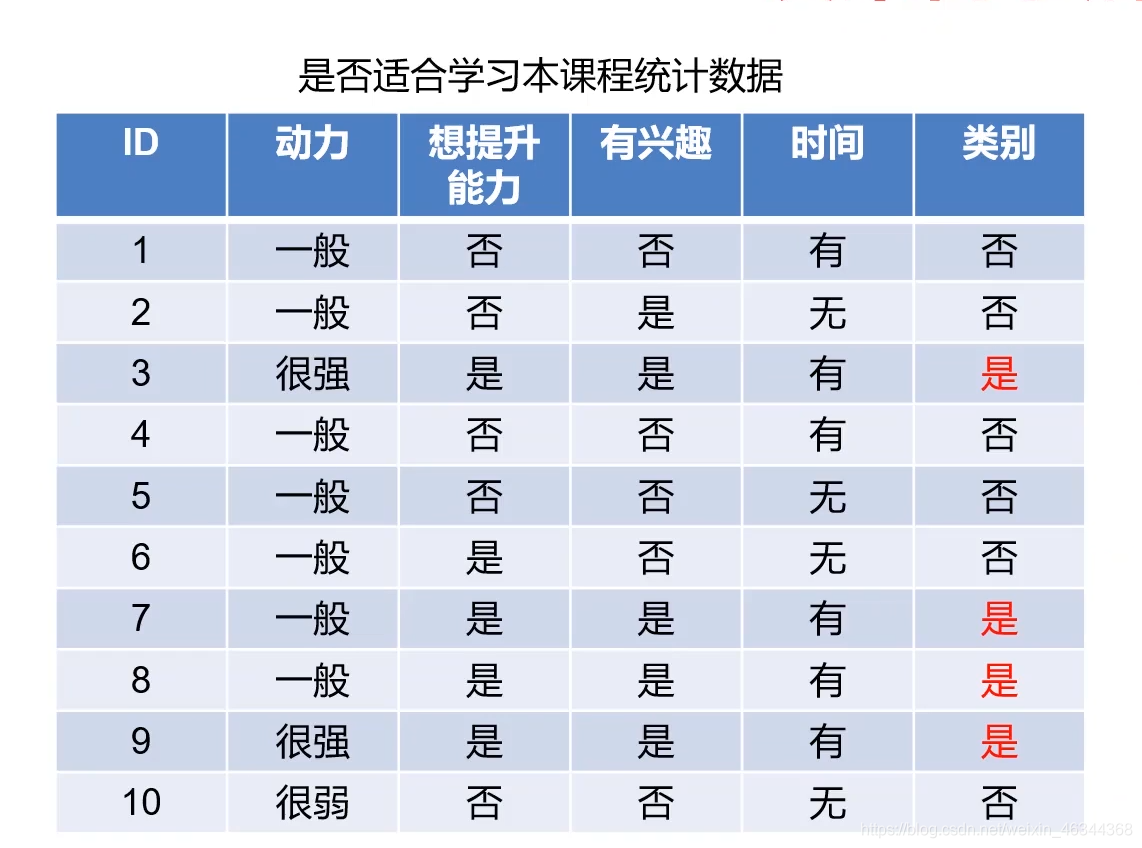
这里有4个判断条件,在我们建立决策树模型框架时,应该将哪一个条件作为第一个判断条件呢?是先根据动力数据,看用户的动力属于很强、一般、很弱哪一类,然后进行下面的判断,还是先根据时间数据,看用户是否有时间,然后再进行下面的判断呢?不同的特征会决定不同的决策树,所以我们在建立决策树模型框架时就应该考虑将每个条件放在适合它的位置上,以此来建立一个最好的决策树模型。
实现该目标常用的有3种求解方法:ID3、C4.5、CART。本文会围绕ID3做一个简单讲解
ID3:利用信息熵原理选择信息增益最大的属性作为分类属性,递归地拓展决策树的分枝,完成决策树的构造。
信息熵是度量随机变量不确定性的指标,熵越大,变量的不确定性就越大。假定当前样本集合D中第k类样本所占比例为Pk,则D的信息熵为:
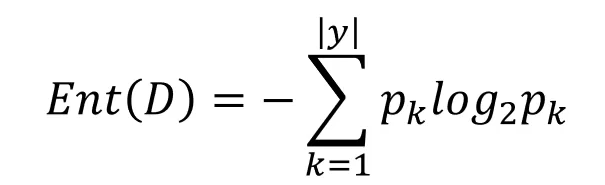
根据信息熵,可以计算以属性a进行样本划分带来的信息增益:

以动力为例,动力分为很强、一般、很弱,所以这里v就等于3;然后共有10个样本,所以D为10
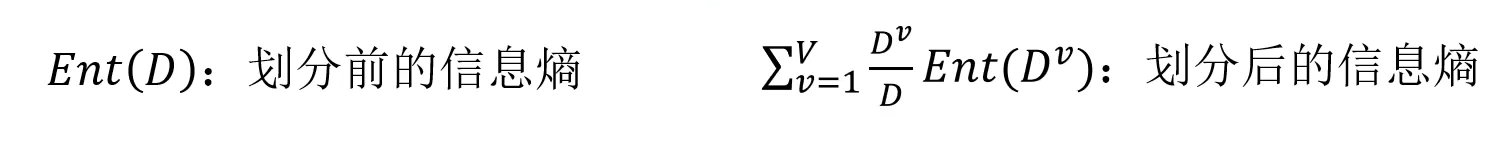
Dv/D,是因为每个类别是有对应的比例的,需要根据每个类别的样本数乘以对应的类别下产生的信息熵,最后把它加起来就是当前的一个总信息熵。
目标:划分后样本分别不确定性尽可能小,即划分后信息熵小,信息增益大。
仍以上述例子为例:
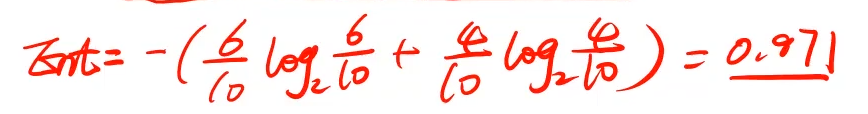
最开始类别那一栏只有是和否,其中"否"占比0.6,"是"占比0.4,可计算出Ent。
这里以兴趣为例:“是”和“否”各占一半,然后“否”对应的类别全为“否”,“是“对应的类别有一个为”否“,其它为”是“。”否“对应的标签为0。”是“对应的标签为1,则有:
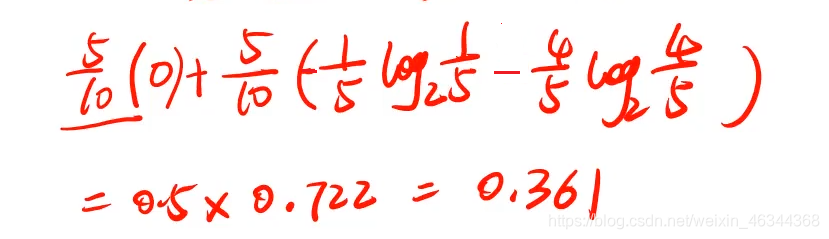

以同样的方式去计算其它属性下的信息增益,则有:
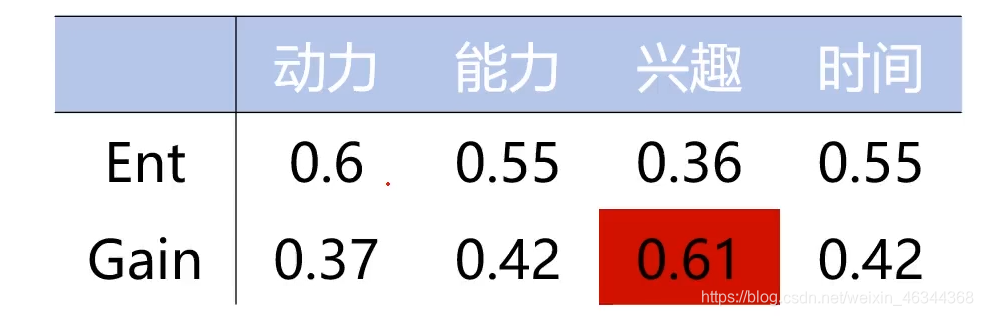
可以发现以兴趣进行划分,信息增益是最大的,此时以兴趣为节点划分好的数据的不确定性是最小的,所以会将兴趣作为决策树的第一个节点。(如图)
本次的分享就到这里了,下次博主会讲一个有关决策树的实战。 Thanks~~














 9582
9582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









