



 文章探讨了数据的价值,比喻为现代的石油资源,说明了数据在不同领域的应用,如消费者、企业和供应商。接着介绍了爬虫技术,包括通用爬虫和聚焦爬虫,以及它们如何模拟HTTP请求获取数据。文章还讨论了开放平台与爬虫的区别,特别是在数据获取和安全防护方面的策略,如IP限制、验证码和代理IP的使用。最后,提到了安全问题,如跨站攻击和防范措施,强调了在处理数据请求时的安全重要性。
文章探讨了数据的价值,比喻为现代的石油资源,说明了数据在不同领域的应用,如消费者、企业和供应商。接着介绍了爬虫技术,包括通用爬虫和聚焦爬虫,以及它们如何模拟HTTP请求获取数据。文章还讨论了开放平台与爬虫的区别,特别是在数据获取和安全防护方面的策略,如IP限制、验证码和代理IP的使用。最后,提到了安全问题,如跨站攻击和防范措施,强调了在处理数据请求时的安全重要性。
前言
数据将成为像石油一样宝贵的资源?
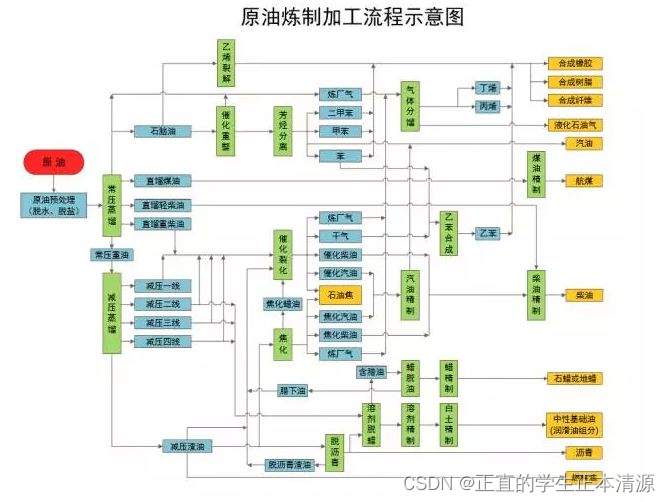
石油通过不同的方式提取可以获得工业橡胶、柴油、汽油、航空煤油等各种不同的产物。
数据从某些方面来看是和石油一样,也是可以提炼的,不同视角去看数据会有不同的作用
比如拿到所有关于车的信息,包括车的销量,价格,购车群体信息等各种信息
-
消费者角度:对比车的价格、质量、用户评价、品牌等相关信息,来决定要买哪一辆。
-
车企:对比车的不同价格销量、不同供应商销量、不同的颜色销量、用户购买群体分析,分析以后发展方向。
-
供应商:用户更喜欢什么材质的内饰,以后更多的生产哪些材料。
-
售车顾问、二手车销售、修车商… … 他们都需要不同维度展示的关于车辆的信息。
离我们最近的爬虫
捜索引擎为什么能搜索出来这么多东西?因为他们有非常庞大的抓取系统,大家有没有注意到‘百度快照’
它是“通用爬虫”

另外一种叫做聚焦爬虫
聚焦爬虫是面向特定内容进行的爬虫,目的是为了满足对特定领域信息的需求.
正文
开放平台和爬虫区别
面对一个数据列表接口
-
正常访问就可以看到数据,但是数据不能够按照批量的被拿走。
-
开放平台是提供接口,提供调用方式,验证身份后就可以提供数据,这个可以批量获取数据,但是很多公司提供的相关服务是收费的。比如钉钉的开放平台有接口是可以给用户的钉钉发通知,chatgpt提供的接口是收费的。
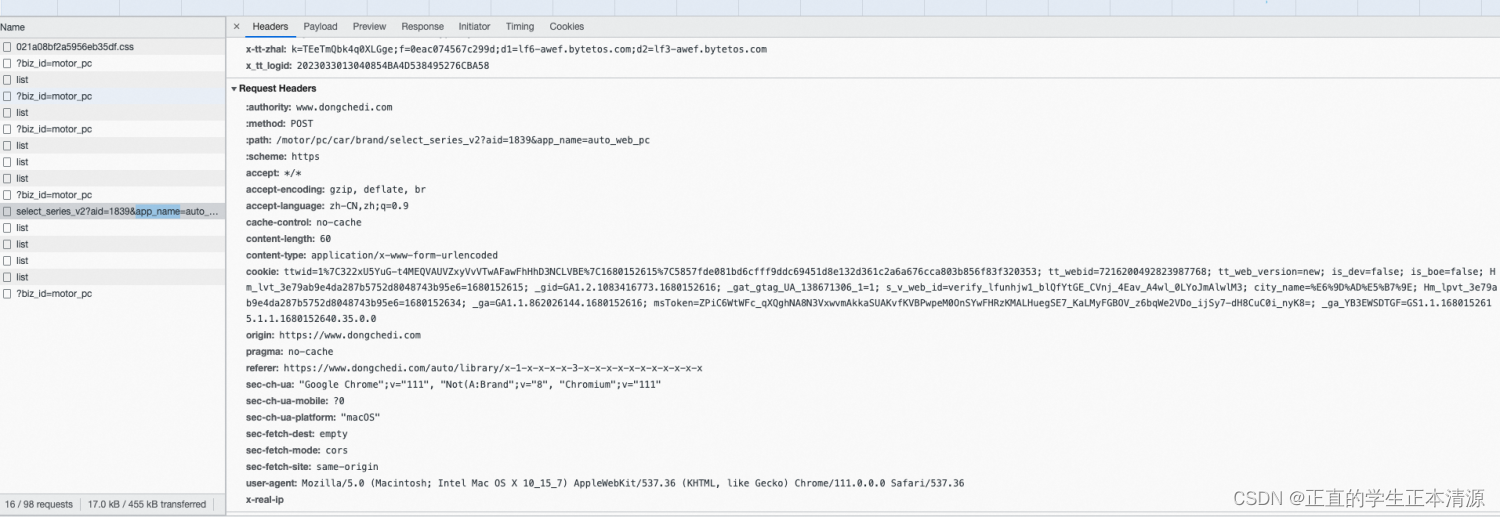
爬虫是将网页视作数据来源,通过模拟请求,获取响应结果。 通过构造一个http请求获取响应内容
页面发什么内容模拟的请求也发一样的内容,他的头部带什么内容模拟的请求头部也带一样的内容,页面翻页请求也翻页。(动态爬虫)
相应的,页面响应中获取到的内容模拟的请求也能获取一样的内容,拿到数据后可以筛选获得有需要的数据。
package com.qdnsjly.spider;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.HttpEntity;
import org.apache.http.client.HttpRequestRetryHandler;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.client.StandardHttpRequestRetryHandler;
import org.apache.http.impl.conn.PoolingHttpClientConnectionManager;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URISyntaxException;
public class MockHttpDCD {
static CloseableHttpClient httpClient = null;
static {
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager();
// 总连接池数量
connectionManager.setMaxTotal(150);
// 可为每个域名设置单独的连接池数量
// connectionManager.setMaxPerRoute(new HttpRoute(new HttpHost("xx.xx.xx.xx")), 80);
// setConnectTimeout:设置建立连接的超时时间
// setConnectionRequestTimeout:从连接池中拿连接的等待超时时间
// setSocketTimeout:发出请求后等待对端应答的超时时间
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(1000)
.setConnectionRequestTimeout(2000)
.setSocketTimeout(3000)
.build();
// 重试处理器,StandardHttpRequestRetryHandler
HttpRequestRetryHandler retryHandler = new StandardHttpRequestRetryHandler();
httpClient = HttpClients.custom().setConnectionManager(connectionManager).setDefaultRequestConfig(requestConfig)
.setRetryHandler(retryHandler).build();
}
public static void main(String[] args) throws URISyntaxException, IOException {
URIBuilder uriBuilder = new URIBuilder("https://www.dongchedi.com/motor/pc/car/brand/select_series_v2?aid=1839&app_name=auto_web_pc");
HttpPost httpGet = new HttpPost(uriBuilder.build());
httpGet.addHeader("content-type","application/x-www-form-urlencoded");
httpGet.addHeader("cookie","ttwid=1%7C322xU5YuG-t4MEQVAUVZxyVvVTwAFawFhHhD3NCLVBE%7C1680152615%7C5857fde081bd6cfff9ddc69451d8e132d361c2a6a676cca803b856f83f320353; tt_webid=7216200492823987768; tt_web_version=new; is_dev=false; is_boe=false; Hm_lvt_3e79ab9e4da287b5752d8048743b95e6=1680152615; _gid=GA1.2.1083416773.1680152616; _gat_gtag_UA_138671306_1=1; s_v_web_id=verify_lfunhjw1_blQfYtGE_CVnj_4Eav_A4wl_0LYoJmAlwlM3; city_name=%E6%9D%AD%E5%B7%9E; Hm_lpvt_3e79ab9e4da287b5752d8048743b95e6=1680152634; _ga=GA1.1.862026144.1680152616; msToken=ZPiC6WtWFc_qXQghNA8N3VxwvmAkkaSUAKvfKVBPwpeM0OnSYwFHRzKMALHuegSE7_KaLMyFGBOV_z6bqWe2VDo_ijSy7-dH8CuC0i_nyK8=; _ga_YB3EWSDTGF=GS1.1.1680152615.1.1.1680152640.35.0.0");
httpGet.addHeader("origin","https://www.dongchedi.com");
httpGet.addHeader("pragma","no-cache");
httpGet.addHeader("referer","https://www.dongchedi.com/auto/library/x-1-x-x-x-x-3-x-x-x-x-x-x-x-x-x-x-x");
httpGet.addHeader("sec-ch-ua","\"Google Chrome\";v=\"111\", \"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"111\"");
httpGet.addHeader("sec-ch-ua-platform","\"macOS\"");
httpGet.addHeader("sec-fetch-dest","empty");
httpGet.addHeader("sec-fetch-mode","cors");
httpGet.addHeader("sec-fetch-site","same-origin");
httpGet.addHeader("user-agent","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36");
HttpContext context = HttpClientContext.create();
CloseableHttpResponse response = httpClient.execute(httpGet,context);
int statusCode = response.getStatusLine().getStatusCode();
System.out.println(statusCode);
HttpEntity entity = response.getEntity();
if (null != entity) {
String resStr = EntityUtils.toString(entity, "utf-8");
JSONObject jsonObject = JSON.parseObject(resStr);
System.out.println(jsonObject);
JSONObject data = jsonObject.getJSONObject("data");
JSONArray series = data.getJSONArray("series");
for (Object serie : series){
JSONObject car = JSON.parseObject(serie.toString());
System.out.println("车企:" +car.getString("brand_name") +",车名:"+ car.getString("outter_name") +",价位区间"+ car.getString("pre_price"));
// System.out.println(car);
}
}
}
}
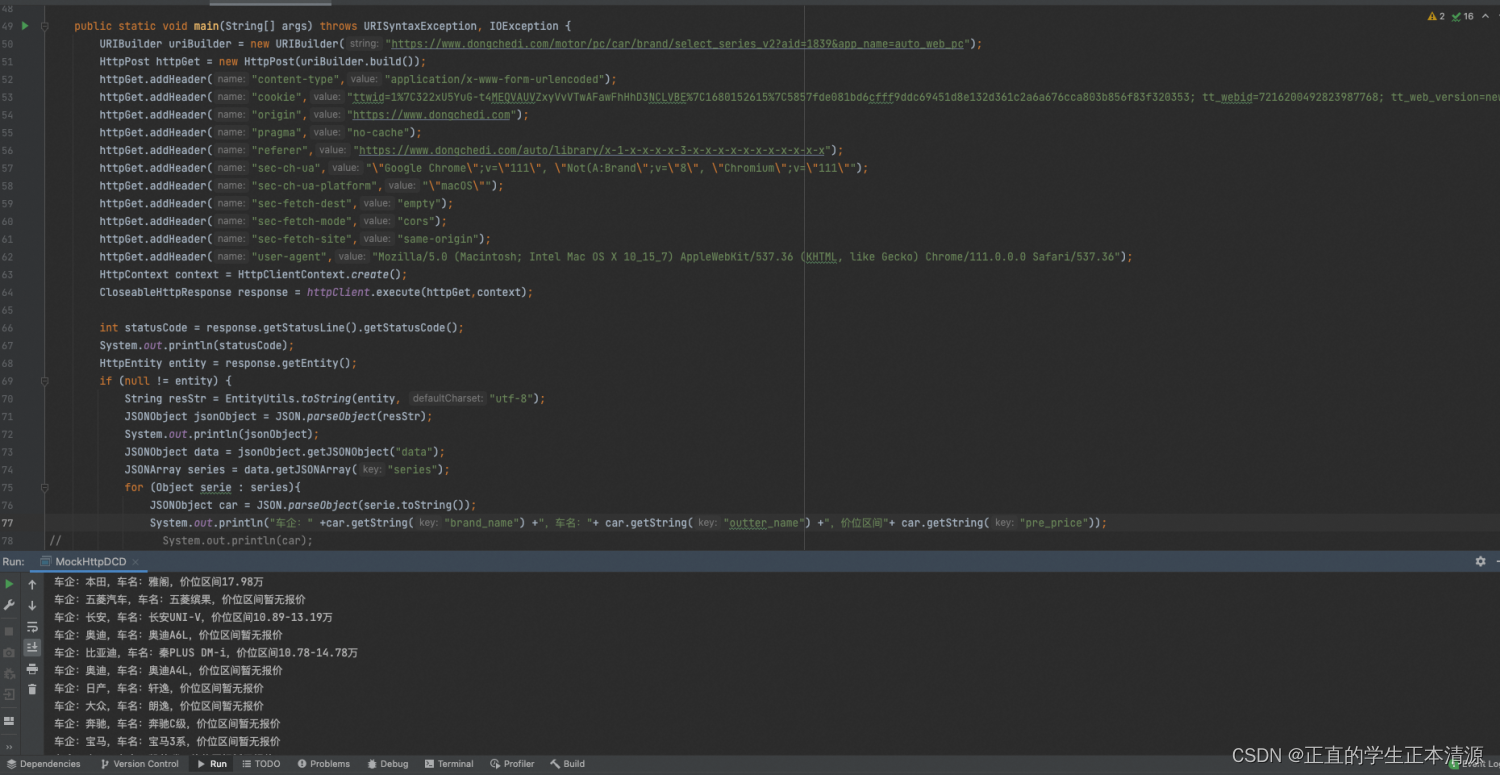
这里使用的是CloseableHttpClient,它是HttpClient的子接口,对比原来的httpClient优势在于可以构建多线程并发环境。(需要你把cookie换成你自己的)
在爬取过程中会遇到很多的问题,因为所有网站都不希望数据被别人轻易拿走,但是又不能让真正想要访问的正常用户获取不到要看到的内容。
这个接口是可以直接获取到一个json的信息,但是如果获取到的不是json,而是一个页面,就需要用Xpath去抽取页面元素中的内容。
XPath是一门在XML和HTML文档中查找信息的语言
攻防一体:当爬虫来敲门
攻击:
通过模拟请求获取数据的过程中,迅速翻页,换参数,不停的发请求
防御:
1.时间段内ip限制访问次数
2.让用户登录
3.前端混淆(方法多种多样,请求加一个加密参数,或者字典码)

4.验证码

再攻击:
使用代理ip请求,每个代理ip模拟请求,分散访问次数,破ip次数限制(代理ip是收费的,根据代理ip的匿名性以及使用时间收费不等,但是可以通过不断优化代码去减少这个成本)
Selenium(Selenium是web自动化的一个工具,可以模拟一个真的浏览器,然后再模拟鼠标操作,但是缺点是太慢了,而且调用浏览器比较多消耗内存,多线程会出现卡死情况)
下载下来页面的js文件,破解混淆(需要一定的js功力)(使用webpack类似工具的打包之后代码可读性变得非常差)

购买第三方接口去对图片验证码解析
再防御:
打包做成应用:手机app,电脑app,小程序(隐藏混淆代码)
加大查封代理ip的力度(对于恶意的请求ip地址逐渐的加大力度)
攻击升级:
分布式爬虫:肉鸡(仅用来做发请求,接收数据,再将数据包传给主机)大量使用代理ip
反编译app或者小程序
防御升级:
购买专业的安全服务,由专业人士负责打理安全问题
fiddler网络代理调试工具
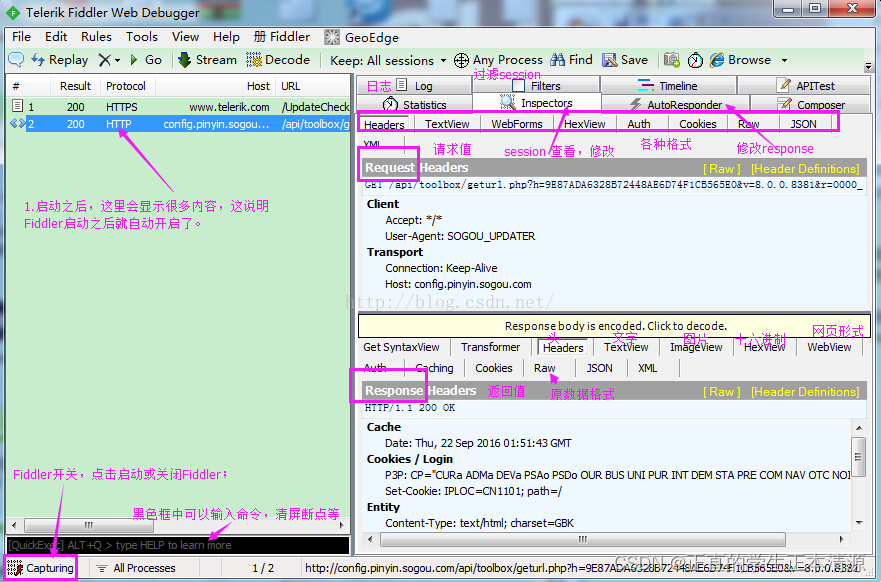
这个应用可以用来做APP抓包,因为app不像网页中的请求一样可以用f12打开开发调试面板,电脑上的应用和手机上的应用以及小程序发出请求后,如果不依靠工具很难看到请求内容。
如果遇到混淆的请求,就需要去反编译,脱壳之后看小程序或者应用的源码。
构造一只http爬虫须知
/robots.txt协议
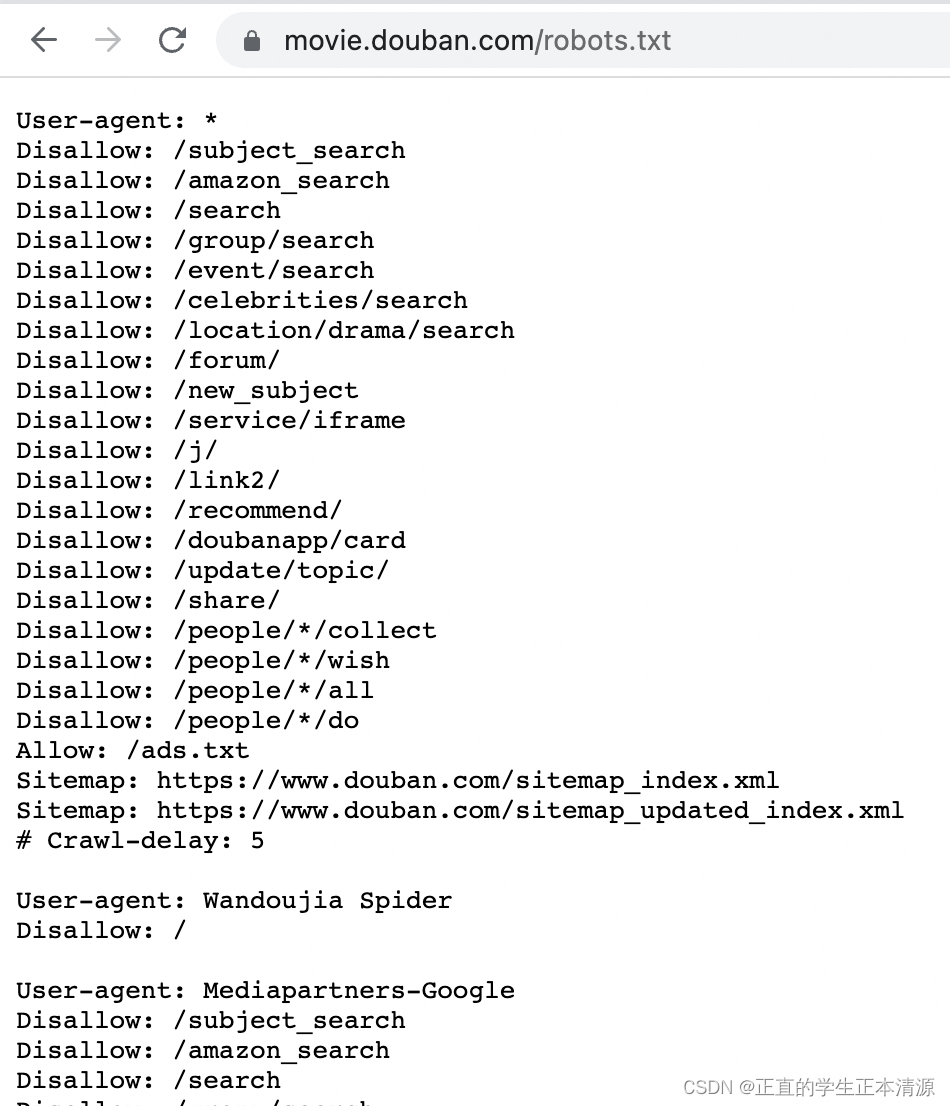
User-agent: 搜索机器人的名称
Disallow: 不允许搜索机器人访问的地址
Allow: 允许搜索机器人访问的地址
我们好像可以做点什么
短信轰炸机
使用一个手机号作为请求参数访问多个可以发短信验证码的地址
拿到数据之后可以通过不同维度展示数据,以这种形式做一个网站
抢茅台
大家有没有更好的想法?
警惕违法犯罪行为
越重要的数据反爬做的越严格,但是如果是一个以内容为核心的网站,抓取一次全量的数据后就可以复刻出来。
跨站攻击(也是模拟请求)-登录后,是有cookie和session在的,如果再打开一个钓鱼网站,可能就直接发送一个转账或者别的请求,因为你的登录态还没有失效,如果没有做好防范就有可能被攻击。
安全相关需要警惕的
如果有人尝试模拟一个请求来访问接口(有正确的cookie,session)
修改,删除时要注意校验当前数据是否是当前用户的,如果很随意就写了根据主键修改,这样非常不安全 ,要根据数据是否属于操作用户再校验一下

















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









