







Spark Streaming实时计算框架
✎ 学习目标
1.了解什么是实时计算
2.掌握DStream的转换、窗口、输出操作
3.理解Spark Streaming工作原理
4.掌握Spark Streaming和Kafka整合
概要
近年来,在Web应用、网络监控、传感监测、电信金融、生产制造等领域,增强了对数据实时处理的需求,而Spark中的Spark Streaming实时计算框架就是为实现对数据实时处理的需求而设计。在电子商务中,淘宝、京东网站从用户点击的行为和浏览的历史记录中发现用户的购买意图和兴趣,然后通过Spark Streaming实时计算框架的分析处理,为之推荐相关商品,从而有效地提高商品的销售量,同时也增加了用户的满意度,可谓是“一举二得”。
实时计算概述
什么是实时计算
在传统的数据处理流程(离线计算)中,复杂的业务处理流程会造成结果数据密集,结果数据密集则存在数据反馈不及时,若是在实时搜索的应用场景中,需要实时数据做决策,而传统的数据处理方式则并不能很好地解决问题,这就引出了一种新的数据计算——实时计算,它可以针对海量数据进行实时计算,无论是在数据采集还是数据处理中,都可以达到秒级别的处理要求。
常用的实时计算框架
- Apache Spark Streaming
Apache公司开源的实时计算框架。Apache Spark Streaming主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。 - Apache Storm
Apache公司开源的实时计算框架,它具有简单、高效、可靠地实时处理海量数据,处理数据的速度达到毫秒级别,并将处理后的结果数据保存到持久化介质中(如数据库、HDFS)。 - Apache Flink
Apache公司开源的实时计算框架。Apache Spark Streaming主要是把输入的数据按时间进行切分,切分的数据块并行计算处理,处理的速度可以达到秒级别。 - Yahoo!S4
Yahoo公司开源的实时计算平台。Yahoo!S4是通用的、分布式的、可扩展的,并且还具有容错和可插拔能力,供开发者轻松地处理源源不断产生的数据。
Spark Streaming的概述
Spark Streaming简介
SparkStreaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有易用性、容错性及易整合性的显著特点。
Spark Streaming工作原理
Spark Streaming支持从多种数据源获取数据,包括Kafka、Flume、Twitter、ZeroMQ、Kinesis及TCP Sockets数据源。当Spark Streaming从数据源获取数据之后,则可以使用诸如map、reduce、join和window等高级函数进行复杂的计算处理,最后将处理结果存储到分布式文件系统、数据库中,最终利用实时Web仪表板进行展示。

Spark的DStream流
DStream简介
Spark Streaming提供了一个高级抽象的流,即DStream(离散流)。DStream表示连续的数据流,可以通过Kafka、Flume和Kinesis等数据源创建,也可以通过现有DStream的高级操作来创建。DStream的内部结构是由一系列连续的RDD组成,每个RDD都是一小段时间分隔开来的数据集。对DStream的任何操作,最终都会转变成对底层RDDs的操作。

DStream编程模型
批处理引擎Spark Core把输入的数据按照一定的时间片(如1s)分成一段一段的数据,每一段数据都会转换成RDD输入到Spark Core中,然后将DStream操作转换为RDD算子的相关操作,即转换操作、窗口操作以及输出操作。RDD算子操作产生的中间结果数据会保存在内存中,也可以将中间的结果数据输出到外部存储系统中进行保存。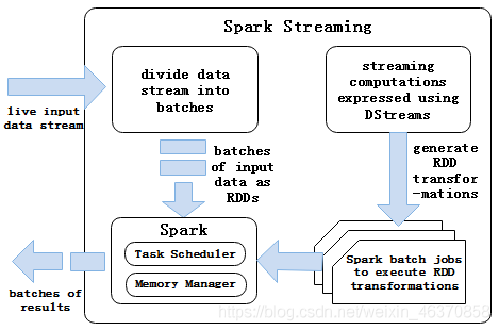
DStream转换操作
Spark Streaming中对DStream的转换操作会转变成对RDD的转换操转换流程如下。
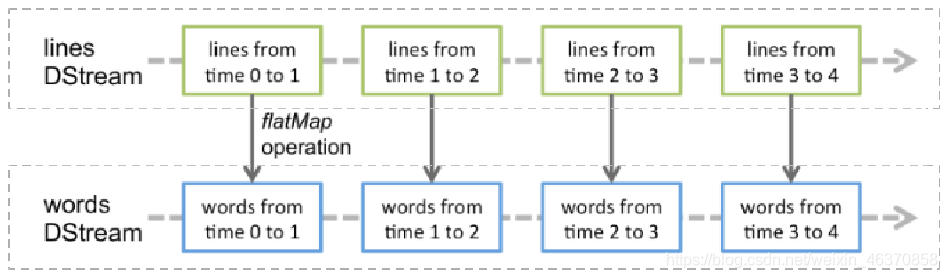
其中,lines表示转换操作前的DStream,words表示转换操作后生成的DStream。对lines做flatMap转换操作,也就是对它内部的所有RDD做flatMap转换操作。
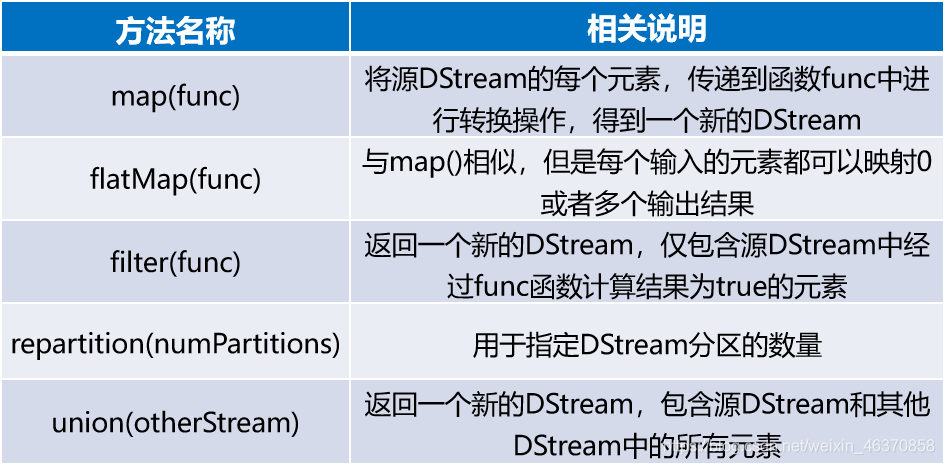
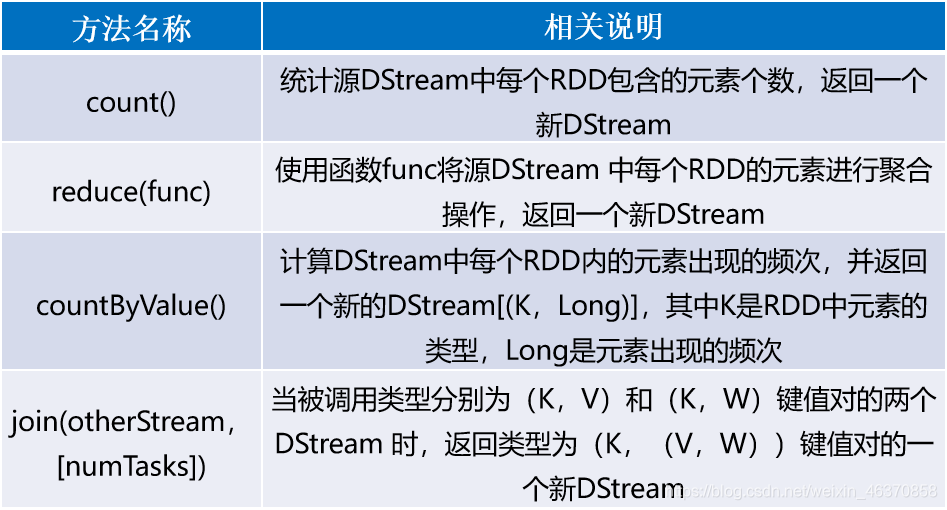
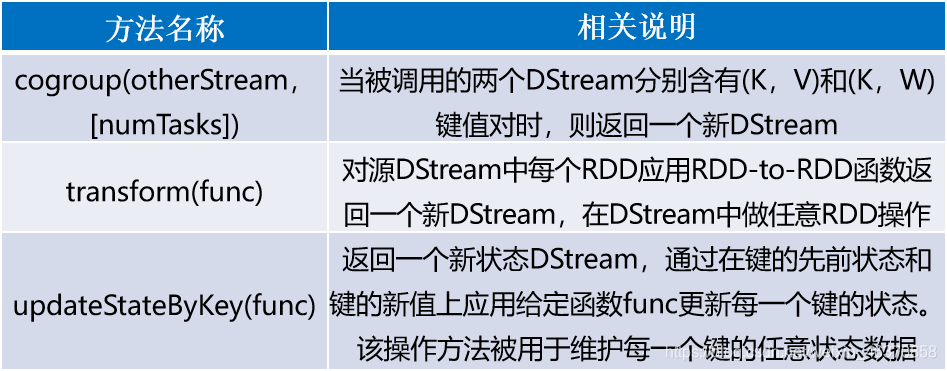
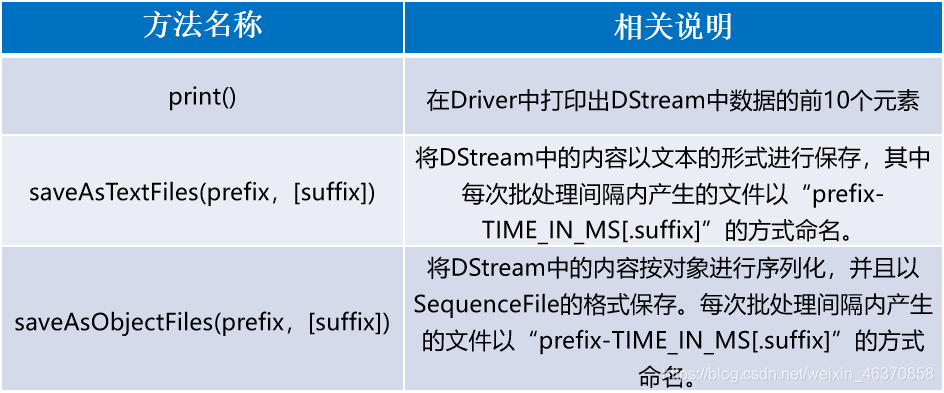
DStream API提供的与转换操作相关的方法
DStream窗口操作
在Spark Streaming中,为DStream提供窗口操作,即在DStream流上,将一个可配置的长度设置为窗口,以一个可配置的速率向前移动窗口。根据窗口操作,对窗口内的数据进行计算,每次落在窗口内的RDD数据会被聚合起来计算,生成的RDD会作为Window DStream的一个RDD。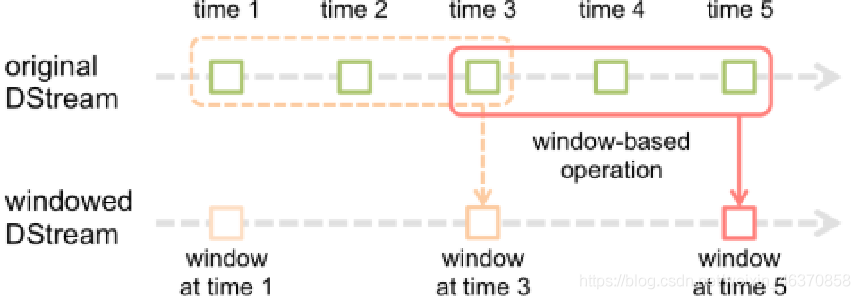
DStream API提供的与窗口操作相关的方法
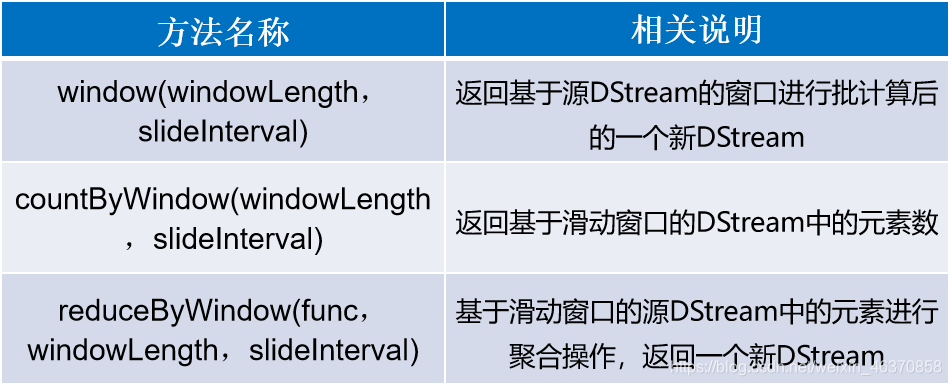
DStream API提供的与窗口操作相关的方法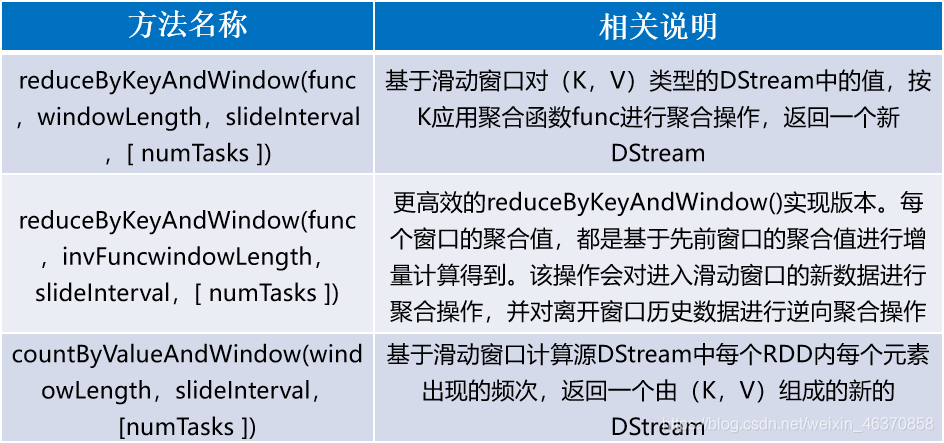
DStream输出操作
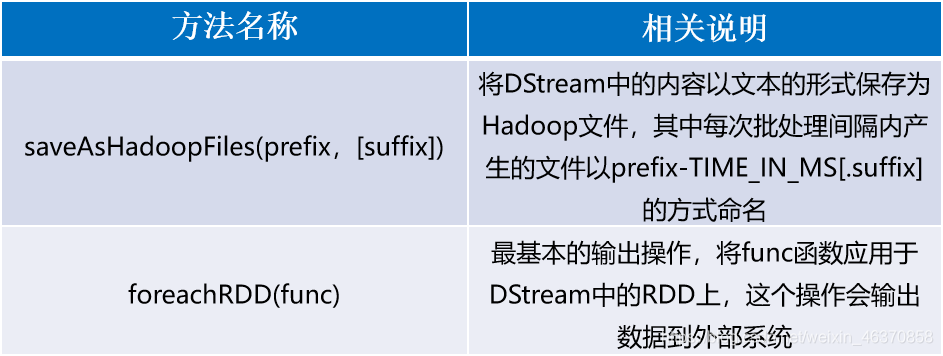
DStream API提供的与输出操作相关的方法
DStream实例——实现网站热词排序
网站热词排序能够分析出用户对网站内容的喜好程度,以此来增加用户感兴趣的内容,从而提升用户访问网站的流量。利用SparkStreaming计数就可以编程实现热词排序的需求。
- 创建数据库和表
mysql>create database spark;
mysql>use spark;
mysql>create table searchKeyWord(insert_time date, keyword varchar(30),
>search_count integer);
- 导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
- 创建Scala类,实现热词排序
在spark_chapter07项目的/src/main/scala/cn.itcast.dstream文件夹下,创建一个名为“HotWordBySort”的Scala类,用于编写Spark Streaming应用程序,实现热词统计排序, - 运行Scala类,并在hadoop01 9999端口输入数据
[root@hadoop01 servers]# nc -lk 9999
hadoop,111
spark,222
hadoop,222
hadoop,222
hive,222
hive,333
- 查看数据表searchKeyWord中的数据
mysql> select * from searchKeyWord;
±------------- ±---------±----------------+
| insert_time | keyword | search_count |
±------------- ±---------±----------------+
| 2018-12-04 | hadoop | 3 |
| 2018-12-04 | hive | 2 |
| 2018-12-04 | spark | 1 |
±------------- ±--------- ±---------------+
Spark Streaming整合Kafka实战
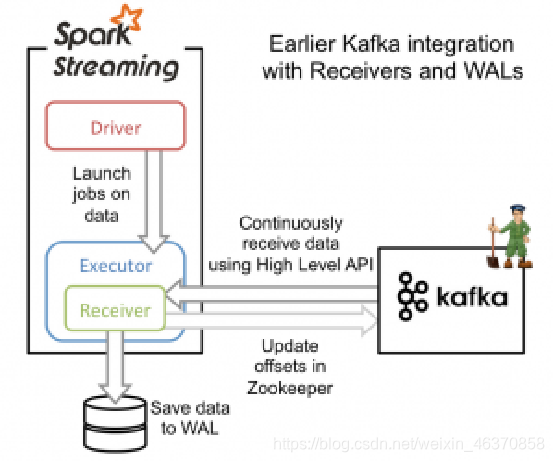
KafkaUtils.createDstream方式
Kafka作为一个实时的分布式消息队列,实时地生产和消费消息。在大数据计算框架中,可利用Spark Streaming实时读取Kafka中的数据,再进行相关计算。在Spark1.3版本后,KafkaUtils里面提供了两个创建DStream的方式,一种是KafkaUtils.createDstream方式,另一种为KafkaUtils.createDirectStream方式。
KafkaUtils.createDstream是通过Zookeeper连接Kafka,receivers接收器从Kafka中获取数据,并且所有receivers获取到的数据都会保存在Spark executors中,然后通过Spark Streaming启动job来处理这些数据。
- 导入依赖
# 添加Spark Streaming整合Kafka的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_0-8_2.11</artifactId>
<version>2.3.2</version>
</dependency>
- 创建Scala类,实现词频统计
在spark_chapter07项目的/src/main/scala/cn.itcast.dstream目录下,创建一个名为“SparkStreaming_Kafka_createDstream”的Scala类,用来编写Spark Streaming应用程序实现词频统计。 - 创建Topic,指定消息的类别
[root@hadoop01~]#kafka-topics.sh --create --topic kafka_spark –partitions 3
--replication-factor 1 --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "kafka_spark".
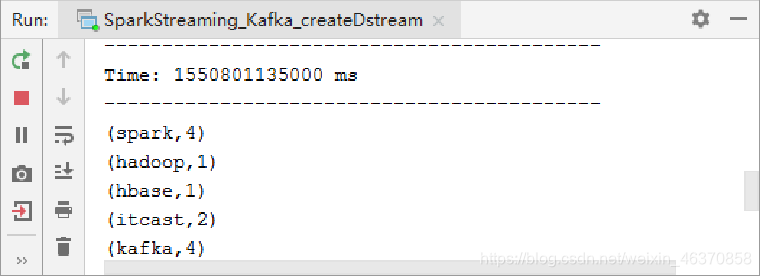
- 启动Kafka的消息生产者,并观察IDEA控制台输出
[root@hadoop01 servers]# kafka-console-producer.sh --broker-list hadoop01:9092
--topic kafka_spark
>hadoop spark hbase kafka spark
>kafka itcast itcast spark kafka spark kafka
KafkaUtils.createDirectStream方式
当接收数据时,它会定期地从Kafka中Topic对应Partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,然后Spark通过调用Kafka简单的消费者API(即低级API)来读取一定范围的数据。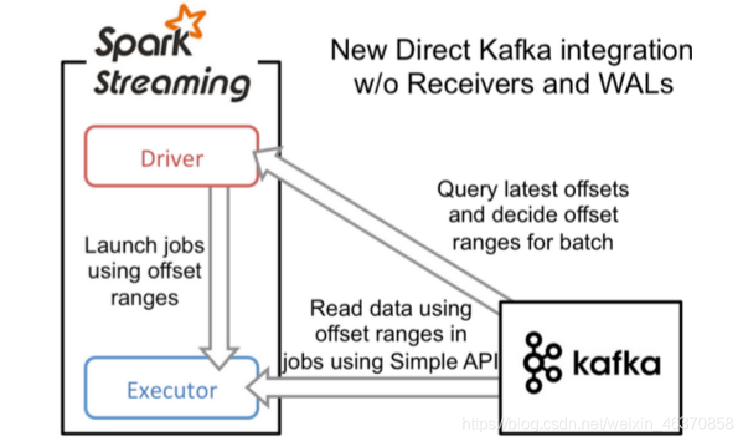
- 导入依赖
# 添加Spark Streaming整合Kafka的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_0-8_2.11</artifactId>
<version>2.3.2</version>
</dependency>
- 创建Scala类,实现词频统计
在spark_chapter07项目的/src/main/scala/cn.itcast.dstream目录下,创建一个名为“SparkStreaming_Kafka_createDirectStream”的Scala类,用来编写Spark Streaming应用程序实现词频统计。 - 创建Topic,指定消息的类别
[root@hadoop01~]# kafka-topics.sh --create --topic kafka_direct0 -–partitions 3
--replication-factor 1--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic "kafka_direct0".
- 启动Kafka的消息生产者,并观察IDEA控制台输出
[root@hadoop01 servers]# kafka-console-producer.sh --broker-list hadoop01:9092
--topic kafka_direct0
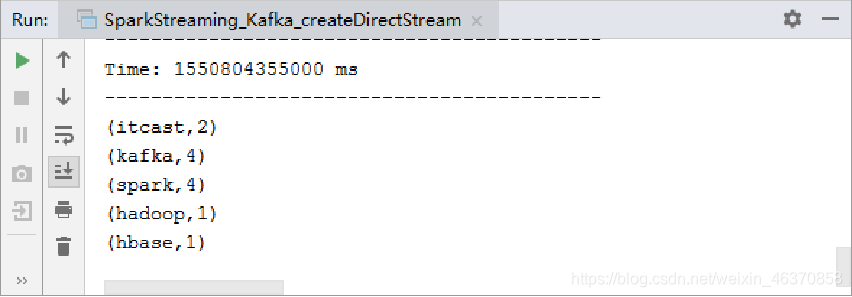
>hadoop spark hbase kafka spark
>kafka itcast itcast spark kafka spark kafka















 6859
6859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











