







单链表的算法之插入节点
1.访问链表中各个自己的指针
(1)只能用头指针,不能用各个节点自己的指针。因为实际中我们保存链表不会保存各个节点的指针,只能通过头指针来访问链表节点。
(2)前一个节点内部的pNext指针能帮助我们找到下一个节点。
2.将创建节点的代码封装成一个函数
(1)封装时的关键点就是函数的接口(函数参数和返回值)的设计
3.从链表尾部插入新节点
#include <stdio.h>
//构建一个链表的节点
struct node
{
int data; //有效数据
struct node* pNext; //指向下一个节点的指针
};
//创建一个链表的节点
//返回值:指针,指针指向我们本函数新创建的节点的首地址
struct node* creat_node(int data)
{
struct node* pHeader = NULL;
//每创建一个新的节点,把这个新的节点和它前一个节点关联起来
//创建一个链表节点
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc failure\n");
return NULL;
}
memset(p, 0, sizeof(struct node));
//bzero(p, sizeof(struct node));
p->data = data;
p->pNext = NULL; //将来要指向下一个节点的首地址,实际操作时将下一个节点malloc返回的指针赋值给它
return p;
}
//尾部插入
void insert_tail(struct node* pH, struct node* new)
{
//分两步完成插入
//第一步,先找到链表中最后一个节点
struct node* p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
//第二部,将新节点插入到最后一个节点尾部
p->pNext = new;
}
int main()
{
//头指针
//struct node* pHeader = NULL;
struct node* pHeader = creat_node(1);
insert_tail(pHeader, creat_node(2));
insert_tail(pHeader, creat_node(3));
insert_tail(pHeader, creat_node(4));
/*pHeader = creat_node(1);
pHeader->pNext = creat_node(2);
pHeader->pNext->pNext = creat_node(3);*/
//访问链表中的各个节点的有效数据,这个访问必须注意不能使用p,p2,p3,只能使用pHeader
//访问链表的第一个有效数据
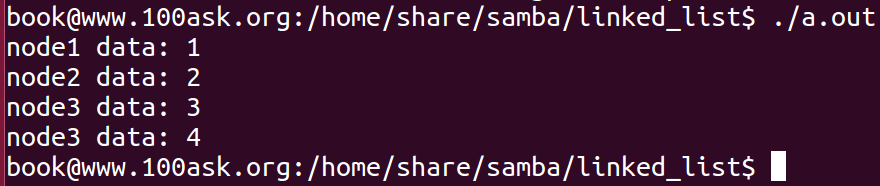
printf("node1 data: %d\n", pHeader->data); //pHeader->data == p->data
//访问链表的第二个有效数据
printf("node2 data: %d\n", pHeader->pNext->data); //pHeader->data == p->data
//访问链表的第一个有效数据
printf("node3 data: %d\n", pHeader->pNext->pNext->data); //pHeader->data == p->data
printf("node3 data: %d\n", pHeader->pNext->pNext->pNext->data); //pHeader->data == p->data
return 0;
}
4.什么是头结点
(1)链表还有另外一种用法,就是把头指针指向的第一个节点作为头节点使用。头节点的特点是:第一,它紧跟在头指针后面。第二,头节点的数据部分是空的(有时候不是空的,而是存储整个链表的节点数),指针部分指向下一个节点,也就是第一个节点。
(2)这样看来,头节点确实和其他节点不同。我们在创建一个链表时添加节点的方法也不同。头节点在创建头指针时一并创建并且和头指针关联起来;后面的真正的存储数据的节点用节点添加的函数来完成,譬如insert_tail.
(3)链表有没有头节点是不同的。体现在链表的插入节点、删除节点、遍历节点、解析链表的各个算法函数都不同。所以如果一个链表设计的时候就有头节点那么后面的所有算法都应该这样来处理;如果设计时就没有头节点,那么后面的所有算法都应该按照没有头节点来做。实际编程中两种链表都有人用,所以大家在看别人写的代码时一定要注意看它有没有头节点。
#include <stdio.h>
//构建一个链表的节点
struct node
{
int data; //有效数据
struct node* pNext; //指向下一个节点的指针
};
//创建一个链表的节点
//返回值:指针,指针指向我们本函数新创建的节点的首地址
struct node* creat_node(int data)
{
struct node* pHeader = NULL;
//每创建一个新的节点,把这个新的节点和它前一个节点关联起来
//创建一个链表节点
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc failure\n");
return NULL;
}
memset(p, 0, sizeof(struct node));
//bzero(p, sizeof(struct node));
p->data = data;
p->pNext = NULL; //将来要指向下一个节点的首地址,实际操作时将下一个节点malloc返回的指针赋值给它
return p;
}
//尾部插入
//计算添加了新的节点后总共有多少个节点,然后把这个数写进节点中
void insert_tail(struct node* pH, struct node* new)
{
int count = 0;
//分两步完成插入
//第一步,先找到链表中最后一个节点
struct node* p = pH;
while(NULL != p->pNext) //由头指针向后便利,走到最后一个节点
{
p = p->pNext;
count++;
}
//第二部,将新节点插入到最后一个节点尾部
p->pNext = new; //新节点成为最后一个节点
pH->data = count + 1;
}
int main()
{
//头指针
//struct node* pHeader = NULL;
struct node* pHeader = creat_node(0);
insert_tail(pHeader, creat_node(1));
insert_tail(pHeader, creat_node(2));
insert_tail(pHeader, creat_node(3));
/*pHeader = creat_node(1);
pHeader->pNext = creat_node(2);
pHeader->pNext->pNext = creat_node(3);*/
//访问链表中的各个节点的有效数据,这个访问必须注意不能使用p,p2,p3,只能使用pHeader
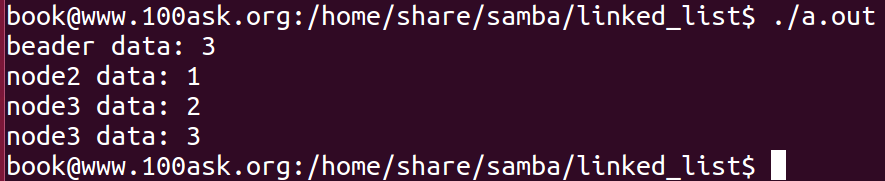
//访问链表的头结点有效数据
printf("beader data: %d\n", pHeader->data); //pHeader->data == p->data
//访问链表的第1个有效数据
printf("node2 data: %d\n", pHeader->pNext->data); //pHeader->data == p->data
//访问链表的第2个有效数据
printf("node3 data: %d\n", pHeader->pNext->pNext->data); //pHeader->data == p->data
//访问链表的第3个有效数据
printf("node3 data: %d\n", pHeader->pNext->pNext->pNext->data); //pHeader->data == p->data
return 0;
}














 1532
1532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









