




 本文详细介绍了数据库的核心概念,如SQL的DQL、DML、DDL、DCL和DTL,以及主键、外键、左连接和右连接。深入探讨了事务的ACID特性、隔离级别和并发问题,特别提到了编程式事务与声明式事务的差异。此外,对比了InnoDB和MyISAM引擎的特点,并阐述了索引的原理和优化策略,包括B树、B+树和索引失效场景。最后,讨论了数据库优化、存储过程、触发器、分页操作以及数据类型的使用。
本文详细介绍了数据库的核心概念,如SQL的DQL、DML、DDL、DCL和DTL,以及主键、外键、左连接和右连接。深入探讨了事务的ACID特性、隔离级别和并发问题,特别提到了编程式事务与声明式事务的差异。此外,对比了InnoDB和MyISAM引擎的特点,并阐述了索引的原理和优化策略,包括B树、B+树和索引失效场景。最后,讨论了数据库优化、存储过程、触发器、分页操作以及数据类型的使用。
一、DDL,DCL,DML,DQL,DTL(TCL)
-
DQL(Data Query Language) - 数据查询语言 - 也是整个sql的核心 - 最难的
select
-
DML(Data Manipulation Language) - 数据操纵语言
insert update delete
-
DDL(Data definition Language) - 数据定义语言
create alter drop
-
DCL(Data Control Language) - 数据控制语言
grant[授权],revoke[取消权限]
-
DTL(Data Transaction Language) - 数据事务语言
commit savepoint rollback
二、主键,外键,左连接,右连接
主键
- primary key - 非空且唯一
- 作用:用来确定唯一元组
外键
- foreign key
- 外键列通常情况是引入另外一张表的主键列
左连接
- left join
- 以左表为基准表,返回左表的所有记录,和右表中连接字段相等的记录,不相等的为null(在右)
右连接
- right join
- 以右表为基准表,返回右表的所有记录,和左表中连接字段相等的记录,不相等的为null(在左)
三、DB,DBMS,RDBMS,DBS,DBA
- DB:数据库
- DBMS:数据库管理系统 -操作和管理的大型数据库管理系统
- RDBMS:关系型数据管理系统————程序通过DBMS来访问操作DB
- DBS:数据库系统————DBA+DBMS+DB
- DBA:数据库管理员
四、事务
事务是指一组相关的SQL操作,我们所有的操作都是处在事务中的,执行业务的基本单位不是sql,而是事务.
命令
- begin - 标记事务的开始
- commit - 提交事务
- rollback - 回滚事务
- save - 设置事务可以回滚到的保存点
事务的四大特性(ACID)
- 原子性(Atomicity):事务不可再分割,要么同时成功,要么同时失败
- 一致性(Consistency):事务一旦结束,内存中的数据和数据库中的数据是保持一致的
- 隔离性(Isolation):多个用户并发访问数据库,事务之间相互独立,互不干扰
- 持久性(Durability):事务一旦提交,则内存中的数据持久化到数据库中,永久保存
五、事务的隔离级别
-
读未提交[READ UNCOMMITED]
事务最低的隔离级别,允许另外一个事务看到这个事务未提交的数据 -
读已提交[READ COMMITED]
保证一个事务修改的数据提交后才能被另外一个事务读取,即另外一个事务不能读取该事务未提交的数据 -
可重复读[REPEATABLE READ] - mysql默认事务隔离级别
保证一个事务相同情况下前后两次读取的数据是一致的
-
串行化[SERIALIZABLE]
事务被处理为顺序执行,有点类似于锁表,但性能很低
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | √ | √ | √ |
| 读已提交 | × | √ | √ |
| 可重复读 | × | × | √ |
| 串行化 | × | × | × |
多事务并发问题
-
脏读
一个事务读取到了另外一个事务中尚未提交的数据
一个事务正在访问数据并且对数据进行修改,另外一个事务正在查询数据,查询的事务查询到了修改的事务修改了但还没提交的事务,修改的事务可能会回滚,导致查询的事务使用脏数据
-
不可重复读
一个事务多次读取同一条记录产生不同的结果
事务A正在读取数据库中的记录,事务B正在修改数据库的事务并提交,事务A在事务B提交前和提交后读取到的记录结果不同,导致原来的数据变成不可重复读的数据.
-
幻读
一个事务修改表中的多行记录,一个事务往表里插入记录,第一个事务查询时发现仍旧有未更新的记录(新插入的),好像出现了幻觉一样
不可重复读的重点是一个事务查一个事务修改,而幻读的重点是一个事务更新,一个事务插入.
六、编程式事务/声明式事务
-
编程式事务:通过编码的方式实现事务,导致事务和业务的代码耦合在一起,类似JDBC编程实现事务管理.
try { ..... connection.setAutoCommit(false); ..... // 一连串SQL操作 connection.commit(); } catch(SQLException) { // 发生错误,撤消所有变更 connection.rollback(); } -
声明式事务: 建立在AOP之上,最大的优点是不需要通过编程的方式管理事务,不需要在业务逻辑代码中掺杂事务管理的代码,只需要在配置文件中做相关的申明,或通过@Transactional注解的方式就可以将事务规则应用到业务逻辑中.
七、Innodb和myisam的区别
- Innodb支持事务,MyISAM 不支持
- InnoDB 支持外键,MyISAM 不支持
- InnoDB 支持行锁,MyISAM 支持表锁
- 在索引方面myisam和innodb有很大区别
- myisam中索引文件和数据文件是分开的独立的两个文件,innodb中索引文件和数据文件合二为一,只有一个文件.
- myisam中的聚簇索引和非聚簇索引的方式都是一致的,叶子结点存储的是索引的值和索引文件物理行地址.innodb中的聚簇索引的叶子结点存储的是索引的值和行记录,非聚簇索引的叶子结点存储的是索引的值和主键的值
八、索引
数据结构-演变过程
二叉树
- 左子节点必须小于当前结点的键值
- 右子节点必须大于当前结点的键值
弊端:很有可能在极端的情况下产生一个链表结构的二叉树
平衡二叉树
每个结点的左右子树的高度差不能大于1
弊端:
- 每个结点仅仅只存储一个键值和数据**(每个磁盘块只存储一个键值和数据)**
- 其实每次查询的时候,都是一次磁盘交互的情况,非常频繁
- 如果存储的数据很多,二叉树的结点将会很多,高度也会极高,导致比较的次数增多,多次与磁盘IO交互,查询效率低下
B树
特点:
- 根结点【第一页】 — 永驻内存
- 每个结点保存更多的key和value - 会导致B树又矮又胖
- B树的m阶 —– 看他 最大的子节点的个数就是m的值
- 每查找一次数据就需要从磁盘中读取一个结点,也就是我们说的一个磁盘块,读取的单位是页,每一页的大小是16KB,可以存储更多的key-value——把磁盘块中的一夜数据【16KB】加载进内存
- 页与页之间是一个链表的结构
B+树
与b树的区别:
- B+树中非叶子结点仅仅只存储了key值,这样每一个非叶子结点都可以存储更多的key
- B+树索引的所有数据都放在了叶子结点上,而且是按照顺序存储的
- 页与页之间是一个双向链表,叶子结点中的数据是单向链表
聚簇索引
以主键作为B+树索引的键值而构建的B+树索引
非聚簇索引
以主键之外的列值作为B+树的键值而构建的B+树索引
聚簇索引和非聚簇索引的区别
- 区别就是非聚簇索引的叶子结点不是存储表中的数据,而是存储该列对应的主键列,想要查找数据还需再根据主键再去聚簇索引中进行查找,这个二次查找的过程称为回表
- 聚簇索引的叶子结点存储的索引列值和行记录
- 非聚簇索引的叶子结点存储的是索引列值和主键值
有一种查询
非聚簇索引在查询时,首先查询到主键值,再根据主键值到聚簇索引中找到行记录,这个过程称之为回表
但是不一定会回表,如果查询的列就是索引列或者是主键列,就不需要回表
以innodb作为存储引擎的表,表中的数据都会有一个主键,即使不创建主键,系统也会创建一个隐式的主键.
九、索引失效场景或者条件/如何提高sql查询效率
遵循最左原则
简介:针对的是复合索引 - 查询语句where最左边的列一定要和创建复合索引的第一个列保持一致.
-
复合索引(a,b,c) - 必须要连续.
a、ab、abc、 都走索引
ac、ca,ba(底层被优化)走a
必须遵循最左原则—找A 开始,无A则全部失效,以此类推(A后找B)
索引失效条件
-
范围之后索引列也会失效
-- a列和b列是走了索引的,但是c列没有走索引.因为c列是范围之后的判断 ----特殊 mysql>explain select * from index_test where a=100 and b>10 and c='daa'; -
模糊查询(%不是出现在末尾,有:%a,%a%)
like '%'出现在末尾,仍然a,b,c都是走索引 -- key_len = 73 - a,b,c都是走了索引的 mysql> explain select * from index_test where a=100 and b=10 and c like 'd%'; -- like '%'如果出现在开始,不走索引的 -- 只有a,b是走了索引的,c是没有走索引的 -- key_len = 10 mysql>explain select * from index_test where a=100 and b=10 and c like'%d'; -- 只有a,b是走了索引的,c是没有走索引的 -- key_len=10 mysql>explain select * from index_test where a=100 and b=10 and c like'%d%'; -
索引列使用函数
索引列套在函数中使用,将会导致索引失效 -- 进行了ALL全表扫描 mysql> explain select * from index_test where abs(id)=1; -
索引列参加了计算
-- 导致索引列失效 mysql> explain select * from index_test where id+1=2; mysql> explain select * from index_test where id = 2 - 1; -
索引列参加运算符 ——(有些情况下会失效)
-- is null(没有走索引)和is not null(走索引) -- is null - type='ALL' mysql>explain select first_name,commission_pct from s_emp where commission_pct is null; -- is not null type='range' - 走了索引的. mysql> explain select first_name,commission_pct from s_emp where commission_pct is not null; -- in(走索引 - range) not in(不走索引 - ALL) mysql> explain select * from index_test where id in(1,2,3); mysql> explain select * from index_test where id not in(1,2,3); -
在查询时使用or连接查询条件
-
mysql在使用!= <>的时候无法使用索引
建立索引的策略
- 索引不是越多越好,因为索引也是需要占用空间的,需要进行维护
- 推荐建立索引的列
- 主键列
- 唯一列
- 不经常改变的列【在update列数据的数据的时候,也会更新索引文件】
- 满足以上条件并且经常作为查询条件的列
- 不建议建立索引的列
- 重复值太多的列
- null值太多的列
十、数据库的优化处理
sql优化
- 尽量避免在 where 子句中使用!=或<>操作符
- 尽量避免在where子句中对字段进行not null值判断
- 尽量避免在where子句中使用or来连接条件
- 尽量避免在where子句中对字段进行表达式操作
- 尽量避免在where子句中对字段进行函数操作
- 不要在where子句中的“=”左边进行函数、算术运算或其他表达式运算
- not in慎用
- 很多时候用exists代替in[查询性能很低]是一个好的选择
- 避免频繁创建和删除临时表,以减少系统表资源的消耗。
- 尽量避免大事务操作,提高系统并发能力。
数据库结构优化
- 范式优化 ———— 比如消除冗余(节省空间)
- 反范式优化 ————比如适当加冗余等(减少join)
- 拆分表
索引优化
服务器硬件优化
- 这个么多花钱咯!
十一、三大范式
- 保证列的原子性,不可在分割
- 所有的非关键列都依赖于关键列
- 所有的非关键列都直接的依赖关键列
十二、 描述使用数据库连接池的优势与原理
优势:不用频繁的和db表进行交互,减少了内存的消耗
原理:建立一个连接池,在里面设置多了连接供用户去使用,可以分别设置他的最小连接数以及最大连接数,当用户去连接的时候,连接池里的连接数不够,连接池会自动放连接在里面,但不超过最大连接数,如果连接池里面空闲的连接比较多,连接池也会关闭几个连接,用户不可以自己手动关闭连接。主要有连接池与DB表进行对接,如果连接池的连接数已经达到最大连接,可以设置一个最大等待时间,这样可以告诉用户等待时间片长。用户使用完立即释放到连接池中供其他用户使用。
十三、悲观锁和乐观锁
悲观锁
总是假设最坏的情况,每次取数据都认为别人会修改,所以在每个操作上都进行上锁. Java的synchronized和reentrantlock等独占锁就是悲观锁.
乐观锁
总是假设最好的情况,每次拿数据都认为别人不修改,所以不上锁,但是在更新的时候会判断一下在此期间有没有人去更新这个数据.
悲观锁和乐观锁的使用场景
- 悲观锁适用于写的情况比较多的场景.
- 乐观锁适用于读的情况比较多的场景.
乐观锁的实现方式
版本号机制
在数据表中加上一个版本号version字段,表示数据被修改的次数,当数据被修改时,version的值会加一.
假设现在同时有线程A和B对数据库的同一行数据进行操作,此时线程A读取版本号version=1然后进行数据更新,在线程A操作的同时线程B也读取版本号version=1并进行修改.线程A提交时先查看数据库的版本是否和自己读取的版本一致,发现是一致的,完成提交.
CAS算法 - compare and swap(比较与交换)
CAS算法是一种有名的无锁算法,即在不使用锁的情况下实现多线程之间的变量同步.它涉及到三个操作数
- 需要读写的内存位置V- 主存
- 需要进行比较的预期值A - 主存中V的旧值
- 需要写入的新值
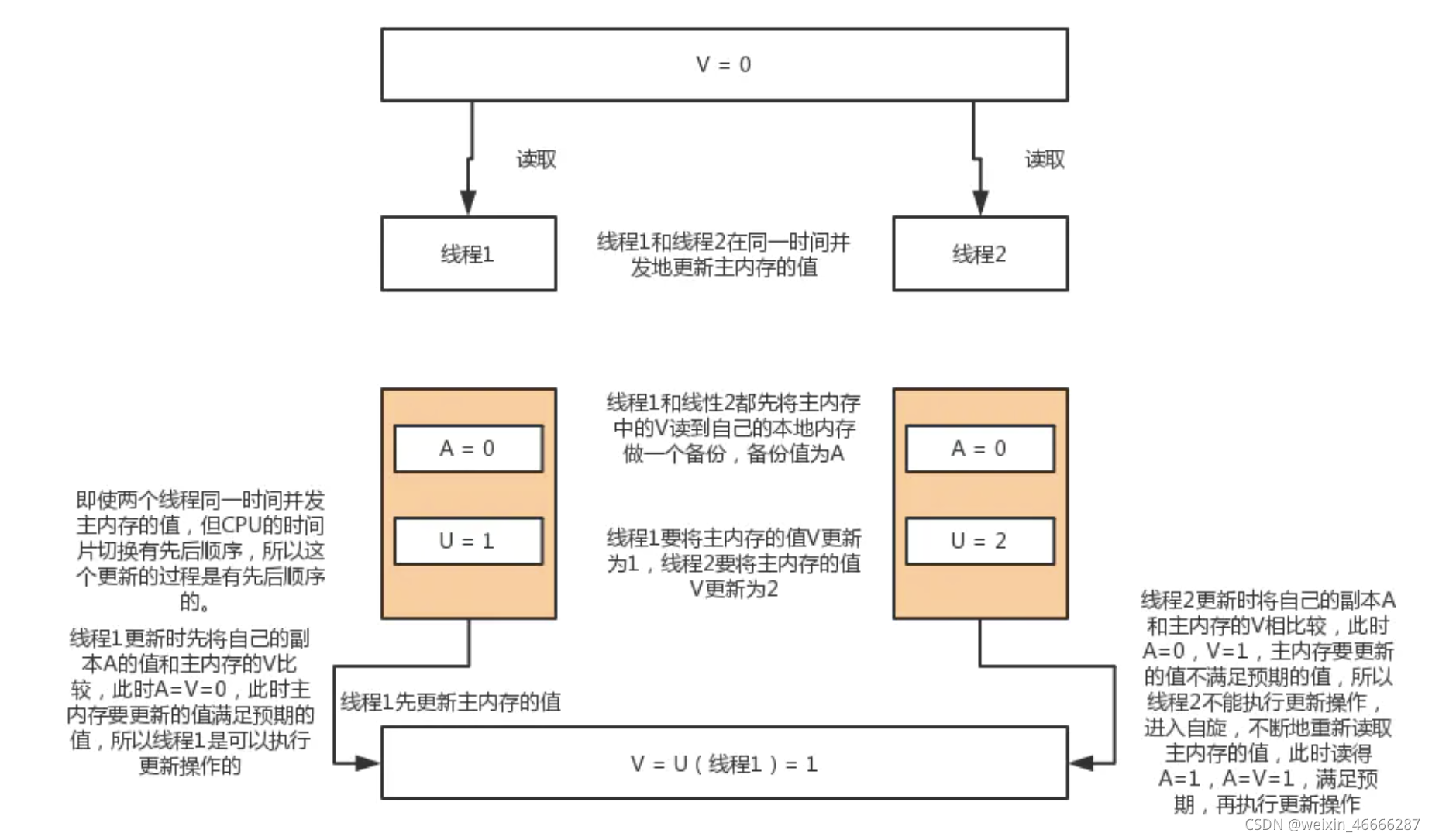
首先拷贝一份读写的内存值
十四、truncate和delete,drop区别
- truncate 表名 - DDL; delete from 表名 where… - DML
- delete删除可以rollback,truncate不能回滚[truncate效率更高]
- truncate不能操作视图,其他的都可以
十五、单行函数
!日期函数 字符串转日期 日期转字符串
还有字符串啥的稍微看看
十六、group by / order by / 多行函数 / 组函数
group by/order by
语法select 语句 where 语句 group by 语句 [having 组函数判断] order by 语句
order by默认是升序,asc是升序,desc是降序.
多行函数/组函数/聚合函数
count / avg / sum / min / max
十七、视图的定义和优点
定义
视图是从一个或多个基本表中到处的虚表,数据库只存放视图的定义,我们通过视图所看到的数据其实仍然存放在基本表中
定义视图
create view <视图名>[(<列名>[<列名>]…)]
as <子查询>
[with check option];
create view 'IS_Student'
as
select Sno,Sname,Sage
from Student
where Sdept = 'IS'
优点
- 可以简化数据操作
- 使数据就有了一定的安全性
- 可以定制用户数据,聚焦特定的数据
- 适当的利用视图可以更清晰地表达语句
十八、存储过程的定义语法和优点
存储过程的定义语法
-
创建存储过程
-- 创建存储过程 delimiter // create procedure 存储过程名([in|out] [参数列表]) begin -- 过程体 end // delimiter ; -
调用存储过程
call 存储过程名 -
删除存储过程
-- 删除存储过程 drop procedure 存储过程名;
优点
- 重复使用。存储过程可以重复使用,从而减少数据库开发人员的工作量
- 减少网络流量。存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数就可以
- 安全性。参数化的存储过程可以防止SQL注入式攻击
十九、存储过程和函数的区别
区别
- 存储过程中可以调用函数,函数中不可以调用存储过程
- 储存过程可以有返回值也可以无返回值,函数必须有返回值
- 函数的调用用select关键字,存储过程调用使用call关键字
- 储存过程可以输入输出参数,函数只可以输入参数
- 存储过程是用in来接受参数,out来返回结果.
[存储过程和函数各记一个例子]
-- 存储过程
drop procedure if_pro;
delimiter //
create procedure if_pro(in a int)
begin
declare msg varchar(20) default '';
if a>=90 then
set msg = '优秀';
elseif a>=80 then
set msg = '良好';
else
set msg = '及格';
end if;
select msg;
end //
delimiter ;
call if_pro(85);
-- 函数
drop function adds;
delimiter //
create function adds(a int,b int) returns int
begin
return a + b;
end //
delimiter ;
二十、触发器
在mysql中,当我们执行一些操作的时候[比如dml操作 - 触发器能够触发的事件],一旦事件被触发,就会执行一段程序
触发器的本质上就是一个特殊的存储过程
分类
- after触发器 - 在触发条件之后执行
- before触发器 - 在触发条件之前执行
前置触发器/后置触发器
-- 语法
-- 删除触发器
drop trigger 触发器名称;
delimiter //
create trigger 触发器名称
触发时机(after,before) 触发事件(insert,delete,update) on 触发器事件所在的表名
for each row
-- 触发器事件程序
begin
end //
delimiter ;
二十一、如何自己使用mysql进行分页操作
*limit (pageNow-1)pageSize,pageSize
limit缺点 - 如果偏移量很大,性能就会降低.
limit的优化
- 如果要优化limit查询的话,where条件中的字段一定要有索引
二十二、数据库的数据类型
| TINYINT | 1 Bytes |
|---|---|
| SMALLINT | 2 Bytes |
| MEDIUMINT | 3 Bytes |
| INT或INTEGER | 4 Bytes |
| BIGINT | 8 Bytes |
| FLOAT | 4 Bytes |
| DOUBLE | 8 Bytes |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 |
日期和时间类型
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB(图片存储方式可以blog) | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
mysql分组子查询[分组效率高]
二十三、约束的类型
- default:默认约束
- not null:非空约束
- unique:唯一约束
- primary key :主键约束
- foreign key :外键约束
- check:检查约束
- auto_increment:自增长约束
- zerofill:零填充约束
- unsigned:无符号约束

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









