







文章目录
一、需求分析及实现思路
1.1 需求分析:当日新增付费用户首单分析
按省份,用户性别,用户年龄段,统计当日新增付费用户收单平均消费及人数总比
无论是省份名称、用户性别、用户年龄、订单表中都没有这些字段,需要订单(事实表)和维度表(省份,用户)进行关联,形成宽表后将数据写入ES,通过kibana进行分析以及图形展示
-- 一张事实表,两张维度表
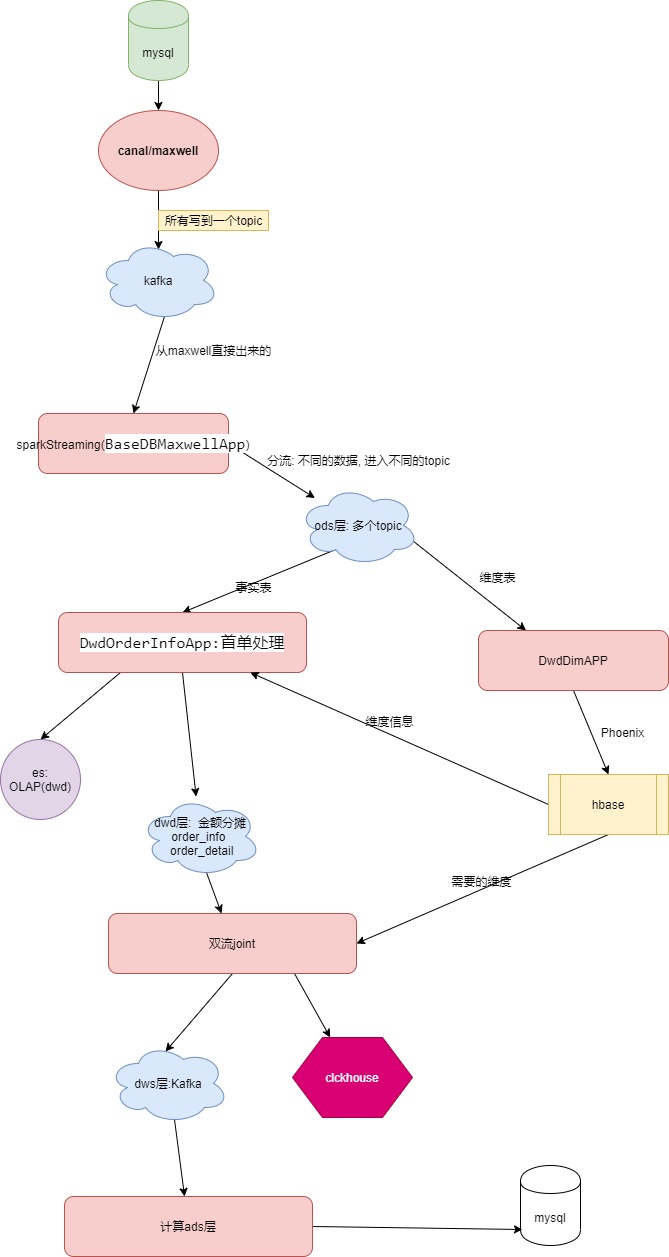
1.2 整体实时计算框架流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qd3LFqHe-1605546794467)(https://i.loli.net/2020/11/14/mZcMAfad8kXuR17.png)]
1.3 具体业务流程图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RydWFk6F-1605546794470)(https://i.loli.net/2020/11/14/baVLm7TtosFOR1S.png)]
二、实时采集mysql数据
2.1 canal实时采集mysql数据
2.1.1 什么是canal
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
2.1.2 canal使用场景
①原始场景:阿里otter中间件的一部分
otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yOuRrJwA-1605546794471)(https://i.loli.net/2020/11/14/I53i2UKbnaxp4WQ.png)]
②常见场景1:更新缓存服务器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-twHv75bp-1605546794473)(https://i.loli.net/2020/11/14/x9qvdB13TiXNwy5.png)]
③常见场景2
抓取业务数据新增变化表,用于制作拉链表
如果表中没有更新时间, 制作拉链表就需要使用canal实时监控数据的变化
④常见场景3
抓取业务表的新增变化数据,用于制作实时统计
我们实时数仓就是这种应用场景!
2.1.3 canal的工作原理
mysql的主从复制原理
①. MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
②. MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
③. MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3uc5qupu-1605546794474)(https://i.loli.net/2020/11/15/BI8F3pRV4hTqo6r.png)]
canal工作原理
①. canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
②. MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
③. canal 解析 binary log 对象(原始为 byte 流)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3VVAmTtp-1605546794475)(https://i.loli.net/2020/11/15/D9jx5HdmhXAeUPt.png)]
2.1.4 mysql的binlog
①什么是binlog
MySQL的二进制日志可以说是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
--一般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
其一:MySQL Replication在Master端开启binlog,Mster把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
--二进制日志包括/两类文件:
A: 二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制的文件,
B:二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
②开启binlog
默认情况下, mysql是没有开启binlog的, 需要手动开启.
开启步骤:
- 找到mysql的配置文件:my.cnf. 大部分的mysql版本默认在: /etc/my.cnf.
如果没有找到, 则可以通过下面的命令查找:
sudo find / -name my.cnf
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4y7OPcKB-1605546794477)(https://i.loli.net/2020/11/16/nsYzC8FIqmR1g2X.jpg)]
#而在环境变量的文件加入这条命令,防止乱码
export LANG="en_US.UTF-8"
- 修改my.cnf. 在my.cnf文件中增加如下内容:
server-id= 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=gmall
③配置说明
server-id:
mysql主从复制的时候, 主从之间每个实例必须有独一无二的id
log-bin:
这个表示binlog日志的前缀是mysql-bin ,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成。 每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
Binlog_format:
mysql binlog的格式,有三种值,分别是statement, row, mixed
三者区别:
statement:
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
'优点':节省空间
'缺点':有可能造成数据不一致。
row:
行级, binlog会记录每次操作后每行记录的变化。
'优点':保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
'缺点':占用较大空间
mixed:
statement的升级版,
一定程度上解决了,因为一些情况而造成的statement模式不一致问题
在某些情况下譬如:
当函数中包含 UUID() 时, 包含 AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照 ROW的方式进行处理
'优点':节省空间,同时兼顾了一定的一致性。
'缺点':还有些极个别情况依旧会造成不一致,另外statement和mixed对
于需要对binlog的监控的情况都不方便。
由于canal不是数据库,是不能执行sql语句的,所以,只能设置为row格式
binlog-do-db:
设置把哪个database的变化写入到binlog,
如果不配置, 则所有database的变化都会写入到binlog.
如果要设置多个数据库需要, 需要写多次这个参数的配置
binlog-do-db = a
binlog-do-db = b
④检测配置是否成功
A: 重启mysql服务器.
Sudo systemctl restart mysqld
B: 启动msyql客户端, 执行sql语句:
show variables like ‘%log_bin%’
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cadl2c60-1605546794478)(https://i.loli.net/2020/11/16/hao4ZVTW9e1LgPS.jpg)]
C: 也可以去对应的目录下查看是否生成log_bin文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CQ6sd0tw-1605546794479)(https://i.loli.net/2020/11/16/hao4ZVTW9e1LgPS.jpg)]
2.1.5 在mysql准备业务数据
使用离线数仓中, 业务数据的生产工具生产数据即可.
注意: 更改application.properties的配置, 能够连上mysql
2.1.6 下载安装canal
①. 在mysql创建canal用户
canal需要监控mysql数据, 在企业中一般拿不到root用户, 需新创建只读取权限的用户.
Mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO ‘canal’@’%’ IDENTIFIED BY ‘canal’;
mysql> FLUSH PRIVILEGES;
②. 下载canal
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
③. 解压安装canal
mkdir /opt/module/canal
tar -zxvf canal.deployer-1.1.4.tar.gz -C /opt/module/canal
2.1.7 配置canal
canal有两种配置: server级别和instance级别
- server级别的配置是对整个canal进行配置, 是一些全局性的配置. 一个sever中可以配置多个instance
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lJQnW4m2-1605546794479)(https://i.loli.net/2020/11/16/q9rOlNZPEQYadps.jpg)]
- instance级别的配置, 是最小的订阅mysql的队列.
比如example实例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hgelC84t-1605546794480)(https://i.loli.net/2020/11/16/q9rOlNZPEQYadps.jpg)]
**①canal server配置**
vim /opt/module/canal/conf/
重点关注以下配置:
canal.ip = hadoop162 # canal服务器绑定ip地址
canal.port = 11111 # canal端口号, 将来客户端通过这个端口号可以读到数据
canal.zkServers = hadoop162:2181,hadoop163:2181,hadoop164:2181 # zk地址, 用来管理canal的高可用
\# tcp, kafka, RocketMQ
\# tcp:客户端通过tcp方式从Canal服务端拉取增量数据
\# kafka:Canal服务端将增量数据同步到kafka中,客户端从kafka消费数据,此时客户端感知不到Canal的存在,只需要跟kafka交互。
\# RocketMQ:同kafka,增量数据同步到RocketMQ中。
canal.serverMode = kafka
canal.destinations = atguigu # 配置实例, 如果有多个实例, 用逗号隔开. 我们创建一个atguigu实例
canal.mq.servers = hadoop162:9092,hadoop163:9092,hadoop164:9092
②canal instance配置
把目录名example改为atguigu(其实就是和刚才的配置保存一致, 用来表示atguigu实例)
mv example atguigu
打开实例配置文件:
vim /opt/module/canal/conf/atguigu/instance.properties
在其中配置要监控的mysql和监控到的数据发送到kafka
# canal实例(slave)的id, 不能和mysql的id重复. 可以自动生成, 无需手工配置
\# canal.instance.mysql.slaveId=0
\# 要监控的mysql地址
canal.instance.master.address = hadoop162:3306
\# 连接mysql的用户名
canal.instance.dbUsername=canal
\# 连接mysql的密码
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
\# 该实例监控的 库.表 默认所有库下所有表
canal.instance.filter.regex=gmall\\..* # 监控gmall数据库下所有包
\# kafka topic配置
canal.mq.topic=gmall_db
\# 注释掉此配置, 此配置是只发送到一个固定分区中
\# canal.mq.partition=0
\# 散列模式的分区数, 要和kafka的topic的分区数保持一致
canal.mq.partitionsNum=2
\# 如何计算每条数据进入的分区
canal.mq.partitionHash= .*\\..*:$pk$ # 指定所有的表用主键hash得到分区索引
2.1.8 canalHA配置和启动canal
① canal只是支持HA, 不支持高负载, 没有负载均衡的概念.
分发canal到hadoop103和hadoop104
注意: 修改canal.ip = hadoop102, 为hadoop103和hadoop104
② 在hadoop102,hadoop103,hadoop104分别启动canal
/opt/module/canal/bin/startup.sh
注意: 需要先启动zookeeper和kafka
2.1.9 测试kafka是否收到实时数据
起一个终端消费者, 消费gmall_db
bin/kafka-console-consumer.sh –bootstrap-server hadoop102:9092 –topic gmall_db
生产数据:
java -jar gmall2020-mock-db-2020-05-18.jar
观察消费者是否消费到数据, 如果没有消费到数据, 则需要重新检测canal配置
2.1.10 接收到的数据格式分析
发送到kafka的数据格式
{
“data”:[
{
“id”:”350”,
“consignee”:”蒋雄”,
“consignee_tel”:”13325313235”,
“final_total_amount”:”389.0”,
“order_status”:”1005”,
“user_id”:”62”,
“delivery_address”:”第17大街第7号楼9单元324门”,
“order_comment”:”描述353475”,
“out_trade_no”:”822287931878949”,
“trade_body”:”十月稻田 沁州黄小米 (黄小米 五谷杂粮 山西特产 真空装 大米伴侣 粥米搭档) 2.5kg等2件商品”,
“create_time”:”2020-08-26 15:02:40”,
“operate_time”:”2020-08-26 15:02:41”,
“expire_time”:”2020-08-26 15:17:40”,
“tracking_no”:null,
“parent_order_id”:null,
“img_url”:”http://img.gmall.com/933223.jpg”,
“province_id”:”3”,
“benefit_reduce_amount”:”108.0”,
“original_total_amount”:”488.0”,
“feight_fee”:”9.0”
}
],
“database”:”gmall”,
“es”:1598425361000,
“id”:73,
“isDdl”:false,
“mysqlType”:{
“id”:”bigint(20)”,
“consignee”:”varchar(100)”,
“consignee_tel”:”varchar(20)”,
“final_total_amount”:”decimal(16,2)”,
“order_status”:”varchar(20)”,
“user_id”:”bigint(20)”,
“delivery_address”:”varchar(1000)”,
“order_comment”:”varchar(200)”,
“out_trade_no”:”varchar(50)”,
“trade_body”:”varchar(200)”,
“create_time”:”datetime”,
“operate_time”:”datetime”,
“expire_time”:”datetime”,
“tracking_no”:”varchar(100)”,
“parent_order_id”:”bigint(20)”,
“img_url”:”varchar(200)”,
“province_id”:”int(20)”,
“benefit_reduce_amount”:”decimal(16,2)”,
“original_total_amount”:”decimal(16,2)”,
“feight_fee”:”decimal(16,2)”
},
“old”:[
{
“order_status”:”1002”
}
],
“pkNames”:[
“id”
],
“sql”:””,
“sqlType”:{
“id”:-5,
“consignee”:12,
“consignee_tel”:12,
“final_total_amount”:3,
“order_status”:12,
“user_id”:-5,
“delivery_address”:12,
“order_comment”:12,
“out_trade_no”:12,
“trade_body”:12,
“create_time”:93,
“operate_time”:93,
“expire_time”:93,
“tracking_no”:12,
“parent_order_id”:-5,
“img_url”:12,
“province_id”:4,
“benefit_reduce_amount”:3,
“original_total_amount”:3,
“feight_fee”:3
},
“table”:”order_info”,
“ts”:1598425365252,
“type”:”UPDATE”
}
2.1.11 验证canal高可用是否正常工作
当前启动canal的时候, 只有一台设备会启动 atguigu实例
[zk: localhost:2181(CONNECTED) 21] get /otter/canal/destinations/atguigu/running
{“active”:true,”address”:”hadoop102:11111”}
停止hadoop102的canal, 然后观察:
[zk: localhost:2181(CONNECTED) 1] get /otter/canal/destinations/atguigu/running
{“active”:true,”address”:”hadoop104:11111”}
2.2 maxwell实时采集mysql数据
2.2.1 什么是maxwell
maxwell 是由美国zendesk开源,用java编写的Mysql实时抓取软件。 其抓取的原理也是基于binlog。
2.2.2 maxwell和canal的对比
-
Maxwell 没有 Canal那种server+client模式,只有一个server把数据发送到消息队列或redis。
-
Maxwell 有一个亮点功能,就是Canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
-
Maxwell不能直接支持HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
-
Maxwell只支持json格式,而Canal如果用Server+client模式的话,可以自定义格式。
-
Maxwell比Canal更加轻量级。
2.2.3 使用maxwell前的准备工作
- 在mysql中创建一个数据库, 用于存储maxwell的元数据
CREATE DATABASE ‘maxwell’CHARACTER SET ‘utf8’ COLLATE ‘utf8_general_ci’;
- 创建可以操作数据库maxwell的用户:maxwell
GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY 'aaaaaa';
- 给用户maxwell分配操作其他数据库的权限
GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@’%’;
FLUSH PRIVILEGES;
2.2.4 安装和配置maxwell
①.下载maxwell
wget https://github.com/zendesk/maxwell/releases/download/v1.27.1/maxwell-1.27.1.tar.gz
②.解压
tar -zxvf maxwell-1.27.1.tar.gz -C /opt/module
③.配置maxwell
cd /opt/module/maxwell-1.27.1
vim config.properties #注意要将之前文件删除,新建一个
如下配置
# tl;dr config
log_level=info
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafka_topic=maxwell_gmall_db
producer_partition_by=primary_key # 按照主键的hash进行分区, 如果不设置是按照数据库分区
# mysql login info
host=hadoop102
user=maxwell
password=aaaaaa
client_id=maxwell_1 # 初始化维度表数据的时候使用
2.2.5 启动maxwell
①启动maxwel
/opt/module/maxwell-1.27.1 » bin/maxwell --config config.properties --daemon
②确定kafka是否收到数据
起一个终端消费者
bin/kafka-console-consumer.sh –bootstrap-server hadoop102:9092 –topic maxwell_gmall_db
③在mysql中生成数据, 确认kafka是否收到数据.
2.2.6 maxwell发送到kafka的数据格式
{
“database”:”gmall”,
“table”:”comment_info”,
“type”:”insert”,
“ts”:1598434438,
“xid”:27085,
“commit”:true,
“data”:{
“id”:1298554271214907454,
“user_id”:988,
“sku_id”:5,
“spu_id”:5,
“order_id”:548,
“appraise”:”1201”,
“comment_txt”:”评论内容:78483837649887576216843442715245587379516398154672”,
“create_time”:”2020-08-26 17:33:58”,
“operate_time”:null
}
}
2.3 Canal和Maxwell发送到kafka的数据对比
为了方便做对比, 在gmall数据库下创建一个表:test_user_info
create table test_user_info(id int primary key, name varchar(255), tel char(11));
1.插入数据
insert into test_user_info values(1, ‘lisi’, ‘13838389438’);

2.删除数据
delete from test_user_info where id=1;

3.更新数据
update test_user_info set name=’zs’ where id=1;

总结数据特点
①日志结构
canal 每一条SQL会产生一条日志,如果该条Sql影响了多行数据,则已经会通过集合的方式归集在这条日志中。(即使是一条数据也会是数组结构)
maxwell 以影响的数据为单位产生日志,即每影响一条数据就会产生一条日志。如果想知道这些日志是否是通过某一条sql产生的可以通过xid进行判断,相同的xid的日志来自同一sql
②数据类型
当原始数据是数字类型时,maxwell会尊重原始数据的类型不增加双引,变为字符串。Canal一律转换为字符串。
③待遇按时数据字段的定义
canal数据中会带入表结构。Maxwell更简洁。
三、实时数据分层
目前在企业中, 对实时数据分层的做法还不是太普遍, 实时数据分层有好处也有坏处
好处
1. 数据可以复用,
2. 简化计算.
3. 为OLAP查询分担压力
坏处
增加了中间数据层, 会增加实时数据的延迟.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CAmvrESE-1605546794481)(https://i.loli.net/2020/11/16/kxEU9nuc6wfLrA4.png)]
四、ODS层处理 ——一个表一个topic
思路
--用canal和maxwell将数据发送到kafka之后,一个topic【kafka_gmall_db】里面存了所有的数据
这时候我们需要将数据分流:
1.使用spark-streaming对数据进行分流——怎么分流呢?就是将不同表的数据消费到不同的topic里面 【ods层】
总体思路:
①我们先将SparkStreaming消费kafka的数据的一些公共代码抽象到一个抽象类BaseApp中,方便后面使用
具体的数据用抽象字段表示出来
具体的逻辑使用抽象函数,定义一个抽象函数run方法
将 ssc: StreamingContext,
offsetRanges: ListBuffer[OffsetRange],
sourceStream: DStream[String]
当做参数传递过去
②定义一个BaseDBCanalApp类,继承抽象类BaseApp,实现数据的分流
分流(处理你可能用到的表,现在用什么,处理什么,分流的时候只用这些表)
--先查看canal的数据格式
这里我们只需要三个
data是一个集合,里面有可能有多个对象,我们使用flatMap
4.1 定义抽象类——B a s e A p p(一个流消费一个Topic)
将使用SparkStreaming消费kafka的数据的一些公共代码抽象到一个抽象类BaseApp,方便后面使用
在包com.atguigu.gmall.realtime下创建抽象类:BaseApp
思路
1.我们先将SparkStreaming消费kafka的数据的一些公共代码抽象到一个抽象类BaseApp中,方便后面使用
具体的数据用抽象字段表示出来
具体的逻辑使用抽象函数,定义一个抽象函数run方法
将 ssc: StreamingContext,
offsetRanges: ListBuffer[OffsetRange],
sourceStream: DStream[String]
当做参数传递过去
package com.atguigu.realtime
import com.atguigu.realtime.util.{MyKafkaUtil_1, OffsetManager}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.json4s.CustomSerializer
import org.json4s.JsonAST.{JDouble, JInt, JLong, JString}
import scala.collection.mutable.ListBuffer
abstract class BaseApp {
//消费者组和主题
val master:String
val appName:String
val groupId :String
val topic:String
val bachTime:Int
val toLong: CustomSerializer[Long] = new CustomSerializer[Long](ser = format => ({
case JString(s) => s.toLong
case JInt(s) => s.toLong
},{
case s:Long => JLong(s)
}))
val toDouble = new CustomSerializer[Double](ser = format => ({
case JString(s) => s.toDouble
case JDouble(s) => s.toDouble
},{
case s:Long => JDouble(s)
}))
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster(master).setAppName(appName)
val ssc: StreamingContext = new StreamingContext(conf, Seconds(bachTime))
val offsets: Map[TopicPartition, Long] = OffsetManager.readOffsets(groupId, topic)
val offsetRanges = ListBuffer.empty[OffsetRange]
val sourceStream: DStream[String] = MyKafkaUtil_1
.getKafkaStream(ssc, groupId, topic, offsets)
.transform(rdd => {
val newOffsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges]
.offsetRanges
offsetRanges.clear()
offsetRanges ++= newOffsetRanges
rdd
})
.map(_.value())
//具体的业务逻辑
run(ssc, offsetRanges, sourceStream)
ssc.start()
ssc.awaitTermination()
}
def run(ssc: StreamingContext, offsetRanges: ListBuffer[OffsetRange], sourceStream: DStream[String])
}
4.2 在Mykafkautil_1中添加需要的方法
把向kafka发数据的方法封装在Mykafkautil_1工具类中
//此方法出来的是kafka中读取出来的流
val kafkaProducerParams: Map[String, Object] = Map(
"bootstrap.servers" -> "hadoop162:9092,hadoop163:9092,hadoop164:9092",
"key.serializer" -> "org.apache.kafka.common.serialization.StringSerializer",
"value.serializer" -> "org.apache.kafka.common.serialization.StringSerializer",
"enable.idempotent" -> (true: java.lang.Boolean)
)
def getProducer = {
import scala.collection.JavaConverters._
new KafkaProducer[String, String](kafkaProducerParams.asJava)
}
4.3 处理canal采集的数据
数据格式
{
“data”:[
{
“id”:”350”,
“consignee”:”蒋雄”,
“consignee_tel”:”13325313235”,
“final_total_amount”:”389.0”,
“order_status”:”1005”,
“user_id”:”62”,
“delivery_address”:”第17大街第7号楼9单元324门”,
“order_comment”:”描述353475”,
“out_trade_no”:”822287931878949”,
“trade_body”:”十月稻田 沁州黄小米 (黄小米 五谷杂粮 山西特产 真空装 大米伴侣 粥米搭档) 2.5kg等2件商品”,
“create_time”:”2020-08-26 15:02:40”,
“operate_time”:”2020-08-26 15:02:41”,
“expire_time”:”2020-08-26 15:17:40”,
“tracking_no”:null,
“parent_order_id”:null,
“img_url”:”http://img.gmall.com/933223.jpg”,
“province_id”:”3”,
“benefit_reduce_amount”:”108.0”,
“original_total_amount”:”488.0”,
“feight_fee”:”9.0”
}
],
“table”:”order_info”,
“type”:”UPDATE”
}
思路
②定义一个BaseDBCanalApp类,继承抽象类BaseApp,实现数据的分流
分流(处理你可能用到的表,现在用什么,处理什么,分流的时候只用这些表)
--先查看canal的数据格式
--解析数据
这里我们只需要三个(data,)
data是一个集合,里面有可能有多个对象,
1)--将canal消费过来的数据封装成集合.flatMap(str=>{
我们使用flatMap解析出三个参数
implicit val f = org.json4s.DefaultFormats
val j: JValue = JsonMethods.parse(str)
val data: JValue = j \ "data" //一个集合或者数组
val tableName: String = (j \ "table").extract[String]
val operate: String = (j \ "type").extract[String]
data是一个集合,我们使用如下操作拿到集合的所有对象,返回值为
data.children.map(child =>(tableName,operate.toLowerCase(),Serialization.write(child)))
'返回值类型DStream(String,String,String),是一个元组'
--})
2)--过滤出需要的表的数据.filter{
怎么过滤呢?根据表名过滤,只要表名是给出表名集合里的数据就过滤出来
当filter和rdd传入的是元组的时候使用偏函数方便
case (tableName,operate,data)=>
只要满足要求的表,和非删除的数据和内容不能是0
tableNames.contains(tableName) && operate != "delete" &&data.length>0
--}
3)--得到了我们需要的数据之后,就写入到ods层.foreachRdd(rdd=>{
【每张表一个topic】
每个分区写一个
--rdd.foreachPartition((it:Iterator[(String,String,String)]) =>{
先获取一个kafka的生产者
将数据遍历写入
--it.foreach{只处理order_info的insert的数据
case (tableName,operate,data)=>{
val topic = s"ods_$tableName"
if(tableName !="order_info"){
producer.send(new ProducerRecord[String, String](topic, data))
}else if (operate == "insert"){
producer.send(new ProducerRecord[String, String](topic, data))
}
}
--}
关闭生产者
--}
--})
4)---将偏移量保存
OffsetManager.saveOffsets(offsetRanges,groupId,topic)
代码
package com.atguigu.realtime.ods
import com.atguigu.realtime.BaseApp
import com.atguigu.realtime.util.{MyKafkaUtil_1, OffsetManager}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.OffsetRange
import org.json4s.JValue
import org.json4s.jackson.{JsonMethods, Serialization}
import scala.collection.mutable.ListBuffer
object BaseDBCanalApp extends BaseApp{
override val master: String = "local[2]"
override val appName: String = "BaseDBCannalApp"
override val groupId: String = "BaseDBCanalApp"
override val topic: String = "gmall_db"
override val bachTime: Int = 3
val tableNames = List(
"order_info", //
"order_detail",
"user_info",
"base_province",
"base_category3",
"sku_info",
"spu_info",
"base_trademark")
override def run(ssc: StreamingContext,
offsetRanges: ListBuffer[OffsetRange],
sourceStream: DStream[String]): Unit ={
//分流
sourceStream.flatMap(str =>{
implicit val f = org.json4s.DefaultFormats
val j: JValue = JsonMethods.parse(str)
val data: JValue = j \ "data" //一个集合或者数组
val tableName: String = (j \ "table").extract[String]
val operate: String = (j \ "type").extract[String]
//拿到date集合的每个对象
//date.children.map(child =>(tableName,operate,JsonMethods.compact(JsonMethods.render(child))))
date.children.map(child =>(tableName,operate.toLowerCase(),Serialization.write(child)))
})
//过滤出数据
.filter{
case (tableName,operate,data)=>
//主要满足要求的表,和非删除的数据和内容不能是0
tableNames.contains(tableName) && operate != "delete" &&data.length>0
}
.foreachRDD(rdd =>{
//写入到ODS层(kafka)
rdd.foreachPartition((it:Iterator[(String,String,String)]) =>{
//先获取一个kafka的生产者
val producer: KafkaProducer[String, String] = MyKafkaUtil_1.getProducer
//写入
it.foreach{
case (tableName,operate,data)=>{
val topic = s"ods_$tableName"
if(tableName !="order_info"){
producer.send(new ProducerRecord[String, String](topic, data))
}else if (operate == "insert"){
producer.send(new ProducerRecord[String, String](topic, data))
}
}
}
//关闭生产者
producer.close()
})
OffsetManager.saveOffsets(offsetRanges,groupId,topic)
})
}
}
4.4 处理maxwell采集的数据
package com.atguigu.realtime.ods
import com.atguigu.realtime.BaseApp
import com.atguigu.realtime.util.{MyKafkaUtil_1, OffsetManager}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.OffsetRange
import org.json4s.JValue
import org.json4s.jackson.{JsonMethods, Serialization}
import scala.collection.mutable.ListBuffer
object BaseDBMaxwellApp extends BaseApp{
override val master: String = "local[2]"
override val appName: String = "BaseDBMaxwellApp"
override val groupId: String = "BaseDBMaxwellApp"
override val topic: String = "maxwell_gmall_db"
override val bachTime: Int = 3
val tableNames = List(
"order_info", //
"order_detail",
"user_info",
"base_province",
"base_category3",
"sku_info",
"spu_info",
"base_trademark")
override def run(ssc: StreamingContext,
offsetRanges: ListBuffer[OffsetRange],
sourceStream: DStream[String]): Unit ={
//分流
sourceStream
.map(str =>{
implicit val f = org.json4s.DefaultFormats
val j: JValue = JsonMethods.parse(str)
val date: JValue = j \ "data" //一个集合或者数组
val tableName: String = (j \ "table").extract[String]
val operate: String = (j \ "type").extract[String]
//拿到date集合的每个对象
//date.children.map(child =>(tableName,operate,JsonMethods.compact(JsonMethods.render(child))))
(tableName,operate.toLowerCase(),Serialization.write(date))
})
//过滤出数据
.filter{
case (tableName, operate, data)=>
//主要满足要求的表,和非删除的数据和内容不能是0
tableNames.contains(tableName) && operate!="delete" &&data.length>0
}
.foreachRDD(rdd =>{
//写入到ODS层(kafka)
rdd.foreachPartition((it:Iterator[(String,String,String)]) =>{
//先获取一个kafka的生产者
val producer: KafkaProducer[String, String] = MyKafkaUtil_1.getProducer
//写入
it.foreach{
case (tableName,operate,data)=>{
val topic = s"ods_$tableName"
if(tableName !="order_info"){
producer.send(new ProducerRecord[String, String](topic, data))
}else if (operate == "insert"){
producer.send(new ProducerRecord[String, String](topic, data))
}
}
}
//关闭生产者
producer.close()
})
OffsetManager.saveOffsets(offsetRanges,groupId,topic)
})
}
}
测试
启动zk,kafka,
启动canal
bin/startup.sh
启动redis
redis-server
redis-server /etc/redis.conf
maxwell开启:
/opt/module/maxwell-1.27.1 » bin/maxwell --config config.properties --daemon
--偏函数
--模式匹配
--抽象类
--继承,多态,封装数据和行为,数据放到抽象里面
--java转scala














 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









