






来源:3DCV
0. 这篇文章干了啥?
立体匹配在计算机视觉中具有重要意义,因为它可以从捕获的图像中推断出三维场景几何,其应用范围从三维重建到机器人技术和自动驾驶。立体匹配的关键在于找到左右图像中对应的像素点。这些对应像素点位置之间的差异被称为视差,随后可用于推断深度并重建三维场景。尽管在立体匹配领域进行了大量研究,但在处理遮挡、重复结构、无纹理或透明物体等方面仍存在挑战。此外,有效地管理立体匹配中的大视差仍然是一个未解决的问题。推荐课程:国内首个面向具身智能方向的理论与实战课程
随着深度学习技术的快速发展和大规模数据集的涌现,深度立体网络已成为主流方法。其中,PSMNet是一个流行的代表,它应用三维卷积编解码器来聚合和正则化四维代价体,并使用soft argmin从正则化的代价体中回归视差图。这种基于代价体滤波的方法可以有效地探索立体几何信息,并在多个基准测试上取得令人印象深刻的性能。然而,这些方法通常在一个预定义的视差范围内(通常是最大192像素)构建代价体,最终的视差预测是通过计算这些预定义视差候选的加权和得出的。这种设计极大地限制了它们处理大视差(高达768像素)的能力,这些大视差在高分辨率图像、近距离物体和/或宽基线相机中普遍存在。构建一个全范围(即图像宽度)的代价体可能允许处理大视差,但会产生巨大的计算和内存成本,从而限制了其在时间受限/硬件受限应用中的应用。
最近,基于迭代优化的方法在高分辨率大视差数据集上表现出了吸引人的性能。与基于滤波的方法不同,迭代方法避免了计算昂贵的代价聚合操作,并通过反复从全对四维相关体中检索代价信息来逐步更新视差图。例如,RAFT-Stereo计算左右图像所有像素在同一极线上的全对相关性(APC),然后利用多级卷积门控循环单元(ConvGRUs)来递归地使用从APC中检索的局部代价更新视差图。由于全对四维相关体,RAFT-Stereo可以预测大视差。然而,没有代价聚合的原始代价体缺乏非局部几何和上下文信息。因此,现有的迭代方法在处理不适定区域的歧义(如遮挡、无纹理区域和重复结构)时存在困难。尽管ConvGRUs可以通过结合来自上下文特征和隐藏层的上下文和几何信息来改进预测的视差图,但原始代价体的局限性极大地限制了每次迭代的有效性,导致需要大量ConvGRUs迭代才能达到令人满意的性能。
在本文中,我们认为基于滤波的方法和基于迭代优化的方法具有互补的优势和局限性。前者可以充分利用三维卷积来正则化代价体,从而将足够的非局部几何和上下文信息编码到最终的代价体中,这对于视差预测至关重要,特别是在不适定区域。后者可以避免与代价聚合操作相关的高计算和内存成本,但仅基于全对相关在不适定区域的性能较差。
为了结合基于滤波和基于迭代优化的方法的互补优势,我们提出了迭代多范围几何编码体积(IGEV++),该方法通过在迭代ConvGRUs优化之前使用极轻量级的三维正则化网络聚合代价体,解决了不适定区域的歧义。为了进一步解决基于滤波方法在高效处理大视差方面的局限性,我们的IGEV++采用了新颖的多范围几何编码体积(MGEV),它为不适定区域和大视差编码了粗粒度的几何信息,并为细节和小视差编码了细粒度的几何信息。我们的MGEV受到一个关键观察的启发,即具有小视差的物体距离较远且占据较少的像素,而具有大视差的物体距离较近且占据更多的像素。我们进一步提出了一种自适应块匹配方法来实现有效且高效的MGEV构建,并引入了一个选择性几何信息融合模块来在每个迭代中有效地集成多范围和多粒度信息。
我们的IGEV++在所有视差范围内均大幅优于现有方法。具体而言,随着视差范围的增加,现有方法的准确性显著下降。相比之下,我们的方法在大视差范围内保持稳健。我们的方法还展示了处理广泛不适定区域的卓越能力,在KITTI 2012基准测试中的反射区域实现了最佳性能。此外,提出的MGEV为ConvGRUs提供了更全面但简洁的信息进行更新,使我们的IGEV++能够更快地收敛。例如,我们的IGEV++仅通过4次迭代就实现了较低的EPE(即0.79),而DLNR则需要32次迭代(即推理EPE为0.81)。
为了充分发挥所提出几何编码体积的优势,我们还引入了IGEV++的实时版本RT-IGEV++,为时间受限的应用提供了一个有吸引力的解决方案。我们的RT-IGEV++在KITTI基准测试上实现了实时速度和所有已发布的实时方法中的最佳准确性。
下面一起来阅读一下这项工作~
1. 论文信息
标题:IGEV++: Iterative Multi-range Geometry Encoding Volumes for Stereo Matching
作者:Gangwei Xu, Xianqi Wang, Zhaoxing Zhang, Junda Cheng, Chunyuan Liao, Xin Yang
原文链接:https://arxiv.org/abs/2409.00638
代码链接:https://github.com/gangweiX/IGEV-plusplus
2. 摘要
立体匹配是许多计算机视觉和机器人系统中的核心组件。尽管在过去十年中取得了重大进展,但处理不适定区域和大差异中的匹配歧义仍然是一个公开的挑战。在本文中,我们提出了一种新的用于立体匹配的深度网络架构,称为IGEV++。所提出的IGEV++构建多范围几何编码体(MGEV ),其对不适定区域和大差异的粗粒度几何信息进行编码,并对细节和小差异的细粒度几何信息进行编码。为了构建MGEV,我们引入了一个自适应补丁匹配模块,该模块可以高效地计算大视差范围和/或不适定区域的匹配成本。我们进一步提出了选择性几何特征融合模块,用于自适应地融合多范围和多粒度的几何特征。然后,我们索引融合的几何特征,并将它们输入到ConvGRUs中,以迭代地更新视差图。MGEV允许有效地处理大差异和不适定区域,例如遮挡和无纹理区域,并且在迭代期间享受快速收敛。我们的IGEV++在所有视差范围的场景流测试集上实现了最佳性能,最高可达768px。我们的IGEV++还在Middlebury、ETH3D、KITTI 2012和2015基准测试中实现了一流的精度。具体来说,IGEV++在大视差基准Middlebury上实现了3.23%的2像素异常率(Bad 2.0),与RAFT-Stereo和GMStereo相比,误差分别减少了31.9%和54.8%。我们还展示了IGEV++的实时版本,它在KITTI基准测试中取得了所有已发布的实时方法中的最佳性能。
3. 效果展示
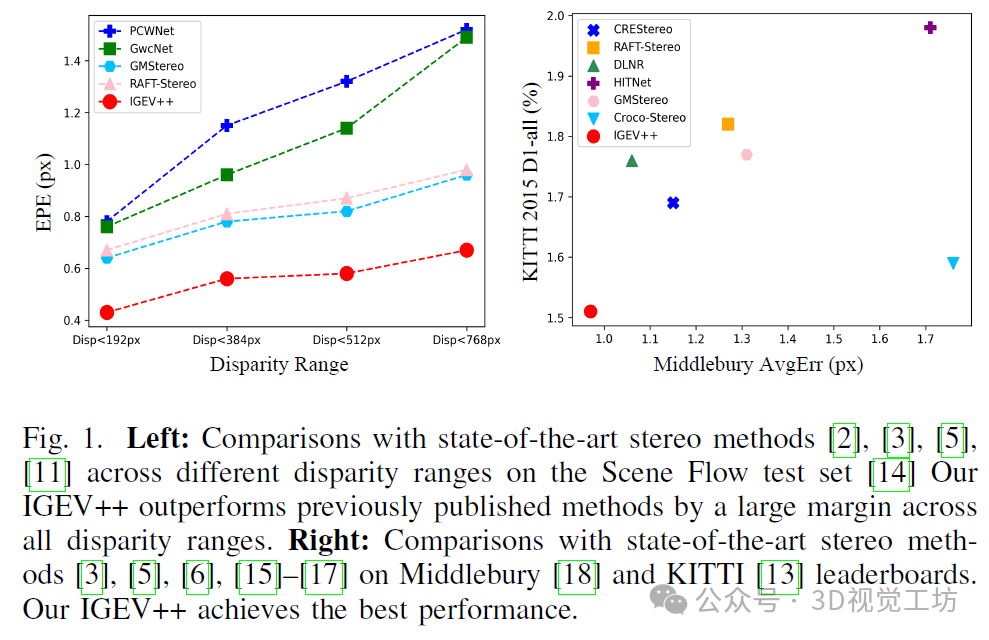
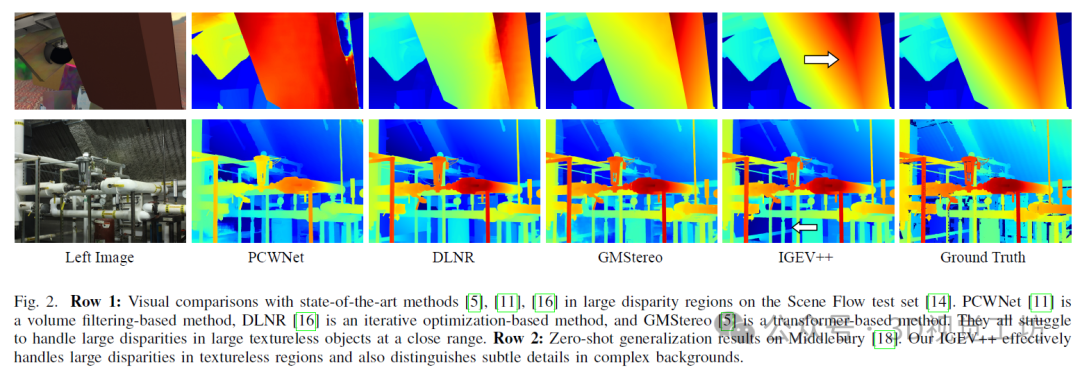
4. 主要贡献
综上所述,我们的主要贡献如下:
• 我们提出了IGEV++,这是一种新颖的用于立体匹配的深度网络架构,它结合了基于滤波和基于优化方法的互补优势。
• 我们提出了新颖的多范围几何编码体积(MGEV),它编码了全面但简洁的几何信息,以在每个迭代中有效地进行视差优化。我们的MGEV能够很好地解决不适定区域的匹配歧义,并有效地处理大视差,同时促进对细节和小视差区域的准确预测。
• 我们引入了一个自适应块匹配模块来实现有效且高效的MGEV构建,以及一个选择性几何特征融合模块来跨多个范围和粒度自适应地融合几何特征。
• 我们的IGEV++在四个流行的基准测试(Middlebury、ETH3D、KITTI 2012和KITTI 2015)上实现了最先进的准确性。具体而言,在具有大视差(768像素)的Middlebury基准测试中,IGEV++在Bad 2.0度量上分别比RAFT-Stereo和GMStereo高出31.9%和54.8%。我们的IGEV++还在具有大视差范围(768像素)的Scene Flow测试集中实现了最高准确性。
• 我们提出了IGEV++的实时版本,该版本能够实现实时推理并在所有已发布的实时方法中表现最佳。
5. 基本原理是啥?
提出的IGEV++的网络架构。IGEV++首先通过自适应块匹配(APM)构建多范围几何编码体(MGEV)。MGEV在三维聚合或正则化之后,对无纹理区域和大视差进行粗粒度几何信息编码,对细节视和小差进行细粒度几何信息编码。然后,我们通过soft argmin从MGEV中回归出一个初始视差图,该视差中图作为ConvGRU的起点。在每次迭代中,我们从MGEV索引多范围和多粒度的几何特征,选择性地融合它们,然后将它们输入到ConvGRU中以更新视差场。

6. 实验结果
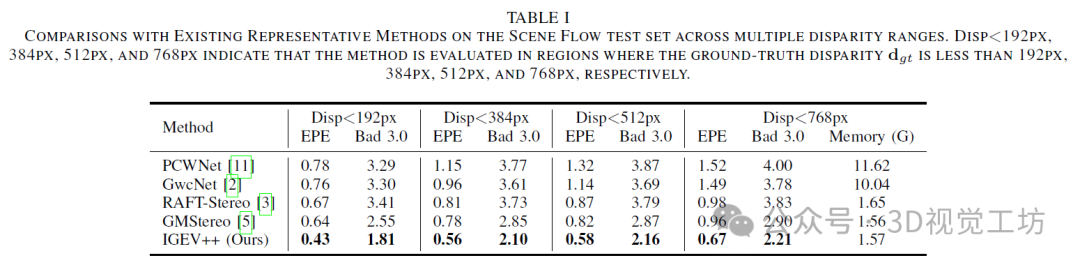


7. 总结 & 未来工作
本文提出了IGEV++,这是一种新颖的立体匹配网络架构,它充分利用了基于滤波和基于迭代优化的方法,同时克服了它们各自的局限性。具体而言,IGEV++构建了一个几何编码体,该编码体集成了空间线索并编码了几何信息,然后迭代地索引它以更新视差图。
为了有效地处理大视差和无纹理/反射区域,我们进一步提出了多范围几何编码体(MGEV),该编码体对无纹理区域和大视差进行粗粒度几何信息编码,对细节和小视差进行细粒度几何信息编码。为了有效且高效地构建MGEV并在MGEV内跨多个范围和粒度融合几何特征,我们分别引入了自适应块匹配模块和选择性几何特征融合模块。我们的IGEV++在Scene Flow测试集上实现了所有视差范围内的最佳性能,最高可达768px。我们的IGEV++还在Middlebury、ETH3D、KITTI 2012和2015基准测试中实现了最先进的精度,并展现出对未见真实世界数据集的惊人泛化能力。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









