









一、PCA
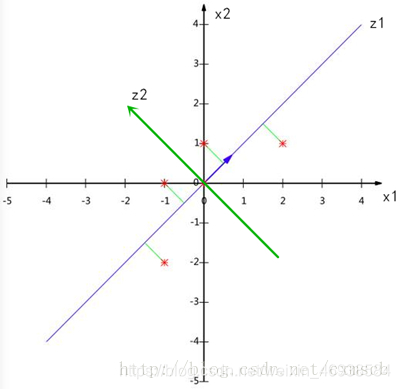
如下图所示:四个样本点在原始特征x1、x2上进行分布,可将这些样本点投影映射到 z1 上的维度。在 z1 维度上,样本间表现出了较大的差异性,即样本的方差较大,因此,特征z1可以看作样本的一个主成分;而若在 z2 维度上投影,样本间表现的差异性在这个维度上会少很多。
二、相关库
from sklearn.decomposition import PCA
三、函数
1、sklearn.decomposition.PCA():
pca=PCA(n_components=None,copy=True,whiten=False)
#n_components:取大于等于1的整数时,表示PCA要保留的特征维度个数n;默认None,即全部保留;也可以为'mle',将自动选择特征个数n;取0-1的浮点数时,即指定降维后的方差和占比
#copy:表示是否在运行算法时,将原始训练数据复制一份;默认True;若为False,则运行PCA算法后,原始训练数据的值会改变,因为是在原始数据上进行降维计算
#whiten:白化,使得每个特征有相同的方差;默认False
2、PCA中的重要属性:
pca.components_:降维后保留的成分。每一行代表一个主成分(最大方差的方向,每行的列数=原始数据特征的个数),各主成分(行)按方差大小排序。
pca.explained_variance_:返回降维后各主成分的方差值,按方差值从大到小排序。
pca.explained_variance_ratio_:返回降维后各主成分的方差百分比,从大到小排序。
3、fit()&fit_transform():
pca.fit(data,y=None)
#表示用data数据来训练PCA模型。因为PCA是无监督学习,此处y自然等于None
new_data=pca.fit_transform(data)
#用data来训练PCA模型,同时返回降维后的数据
也可以这样用:
pca.fit(data)
new_data=pca.transform(data)
pca.inverse_transform(new_data)#必要时复原数据
四、观察保留不同特征维度个数时的方差和占比
以sklearn中自带的digits手写字体数据集为例:
横坐标:保留的特征维度个数
纵坐标:降维后的所有主成分的方差和占比
from sklearn.datasets import load_digits
#numpy,matplotlib,PCA库自行导入
digits=load_digits()#加载手写数字数据集
X=digits.data#特征矩阵,维度:(1797,64)
y=digits.target#标签向量,维度:(1797,1)
#初始化pca模型
pca=PCA()
#pca=PCA(n_components=0.9)
#pca=PCA(n_components=0.99)
pca.fit(X,y)
ratio=pca.explained_variance_ratio_
print("pca.components_:",pca.components_.shape)
print("pca.explained_variance_ratio_:",pca.explained_variance_ratio_.shape)
#绘制图形
plt.plot([i for i in range(X.shape[1])],
[np.sum(ratio[:i+1]) for i in range(X.shape[1])])
plt.xticks(np.arange(X.shape[1],step=5))
plt.yticks(np.arange(0,1.01,0.05))
plt.grid()
plt.show()
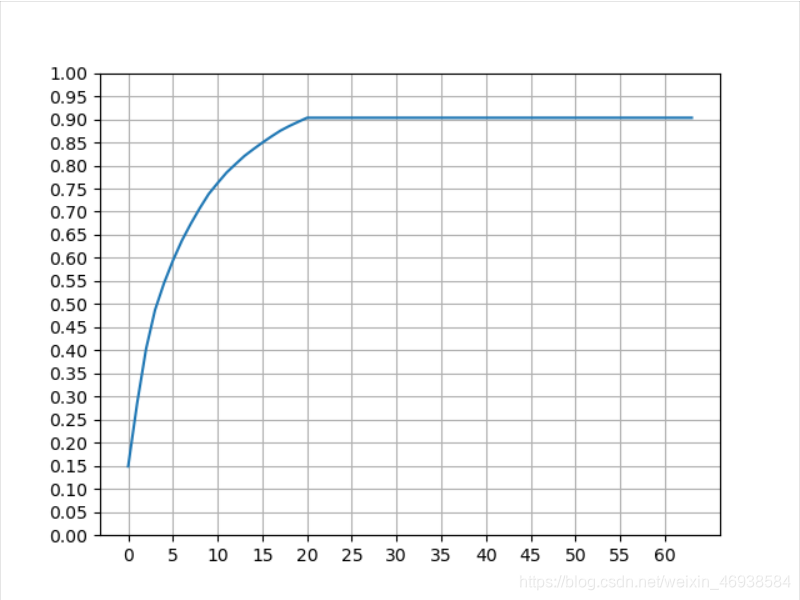
结果如下:


我们可以发现,随着降维个数的增加,方差和占比是先快速增长,然后就平稳增长了。当降维后的维度个数为20时,所有主成分的方差和占比为90%,即约10%的信息被丢失了。
将上文中的代码pca=PCA( )替换为pca=PCA(n_components=0.9),得到下面的结果:

由64维降维至了21维。
再次修改为pca=PCA(n_components=0.99),得到:
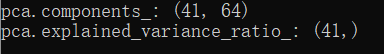
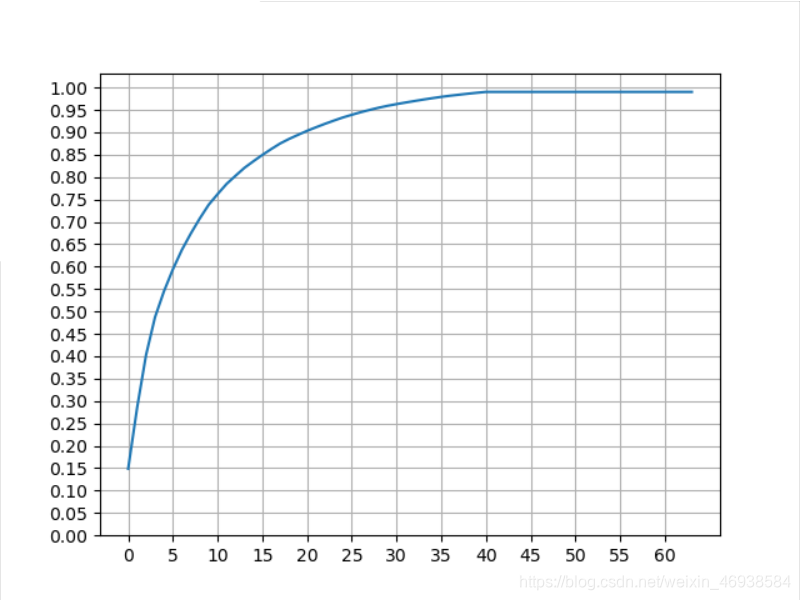
在只有约1%的信息丢失的情况下,特征维度降至了41维,很大程度上提升了计算效率。














 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









