







说明
于目前存在的路由选择协议可以按照 距离矢量和链路状态进行分类, 可以说距离矢量和链路状态两种采用的是不同的算法,也有着不同的特性和区别,所以,在学习路由选择协议之前,了解它们怎么的特性和区别是非常有必要的。
距离矢量路由选择协议

距离矢量的路由更新 就好比我们生活中的路标,去往某某地方,按照路标指示的方向进行,而自身并不知道它是否是正确的。而距离矢量一样,都依赖于邻居路由器,邻居路由器传递了什么路由信息给自己,自己又传递给另外的邻接路由器,所以,我们有时候又称为听信传闻的路由协议,它们并不能确认这路由信息是否是最好或者有效的 。
目前存在的距离矢量协议有RIP和EIGRP,主要应用于现网的,当然RIP已经越来越不被采用了
一、距离矢量通用的属性
1、定期更新:不同的路由协议比如RIP和IGRP都会周期性的发送路由更新给邻居路由器,但是为了避免冲突,在更新周期加了一个15%的随机数,也就是说更新周期后根据这15%进行波动。比如RIP周期性为30s,实际上是25.5~30
2、 邻居:邻居之间会互相发送路由更新,并且传递给其他邻居,而邻居的概念在某些协议中并不存在,比如 RIP,它没有邻居的概念,所有的路由都存放在database中。
3、广播更新:一种把路由信息告诉邻居的方式,通过255.255.255.255向激活了某个路由协议的接口发送出去。
4、全路由表更新:当到达定期更新后期后,就会把全部路由表的信息发送给邻居。
5、大部分距离矢量协议采用的是 Bellman-Ford算法,但是,EIGRP是个例外,它采用的是DUAL算法。
这些通用属性明显的说明了早起距离矢量协议的特点,但是,对于后期的协议来说已经改进了许多工作方式,这样才能适应当前的网络。
二、依照传闻进行路由选择分析
这是卷一给出的一个经典的案例,很好的说明了,距离矢量路由协议在更新时候的过程。
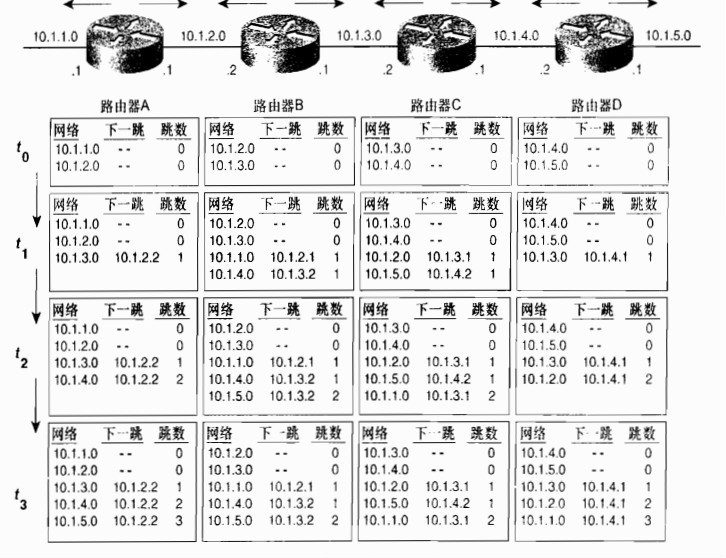
1、在t0时刻,也就是在每个设备的直连信息都正确配置的情况下,每个路由器都只有各自的直连信息。开始运行路由协议
2、在t1时刻,路由协议更新开始了,A收到了来自B的路由更新条目,包括10.1.2.0和10.1.3.0,10.1.3.0从B到A经过了一跳,所以,跳数为1,并且在A看来它的路由表中并没有关于这条路由的信息,随之加入进路由表。 再次看10.1.2.0,同样的B到A经过了一跳,所以,跳数为1,A再次查看路由表,发现10.1.2.0在路由表中有直连的存在,优于B传递过来的1跳信息,所以,A会忽略掉。其他路由器也执行相同的操作。
(可以看出来,在没有任何机制的情况下,距离矢量路由的更新是比较浪费带宽和路由器资源的)
3、在t2时刻,路由协议又再次更新,B再次发送路由更新给A,A同样的忽略掉 10.1.2.0和10.1.3.0的信息,因为路由表中存在了,不同的是,会接收到10.1.4.0的路由条目,并且跳数为2,因为从B的路由表中已经是1跳了(C传递给B经过了一跳),B经过A又经过了一跳,所以,为2跳,也就是图上 T2时刻的收敛情况,其余的路由器也会执行相同的操作。
4、t3时刻,网络已经收敛完毕,每台路都已经有了每个网络和下一跳的信息,已经到达这个网络需要经过的跳数
可以看出来,距离矢量算法只告诉了方向和距离,并没有给出具体的细节,所以,它存在很大的误导或者意外情况。
三、距离失恋算法的改进
1、路由失效计时器:路由器没收到一个路由条目更新,就会初始化对应一个计时器,当一定的时间内有没有收到这条路由条目更新则认为这条路由为不可达,在下一个更新周期传递该信息。 (在RIP中还有个Flush时间,比无效时间计时器长60s(RFC规定60~240),如果flush时间时间器也超时,那么该路由表项也会从路由表中删除。这60s用于通告给邻居,这条路由失效了)
2、holdtime:如果一台路由更新的跳数大于路由表中的跳数,那么这条路由就会进入holdtime(抑制状态),直到这个计时器超时后,如果路由信息的跳数还是一样,那么就更新路由表。在RFC中没有定义该项内容,但是,在cisco中引入了。
3、水平分割:可以达到节约资源和不会把学习到的可达性信息再返回给这台路由器。
1、简单水平分割原则:从某个接口收到的路由信息,不再从该接口发送出去。
2、毒性逆转水平分割:从邻居学习到的路由,再次发往这个邻居的时候,会标识无穷大。而且是可以不受受水平分割的影响,为了更好的加快收敛。
4、计数无穷大:当一条路由在更新的时候,超过了最大的跳数,那么就认为这条路由为无穷大,不可达。
5、触发更新:当某个链路或者路由出现了故障,那么就立即通知网络中的邻居,而不需要等待更新周期。
链路状态路由选择协议
链路状态路由像一张公路线路图,它不会因为被欺骗而作出错误的路由决策,每台路由器都有一个相同的有关网络的详细信息,并且每台路由器都独立计算各自的最优路由。使用的是Dijkstra的最短路径算法 (主要是OSPF和ISIS)
链路状态的特性
1、hello协议:定义一个Hello数据包的格式和交换数据包并处理数据包信息的过程。一个Hello数据包至少包含一个路由器的ID和发送数据包的网络地址,路由器ID是用来区分不同的路由器发送的数据包。Hello包还作为发现和维持邻居的存在,当在特定的时候内没有收到关于邻居的hello信息,那么就认为邻居路由器不可达。典型的hello数据包交换为10s,死亡时间为hello间隔的4倍。
2、链路状态泛洪扩散:在邻居建立以后,路由器就开始发送LSA,路由器保存接受到的LSA,并向每个邻居转发,除了发送该LSA的邻居之外。这也是链路状态协议优于距离矢量的一个原因,LSA几乎是立刻被转发的,而距离失恋在发送路由更新之前必须运算并更新自身的路由表。
说明
(1)、序列号:泛洪扩散的一个难点在于,当所有路由器收到的所有LSA时,泛洪扩散必须停止。序列号来标记是否最新的的LSA,如果相同则丢弃,如果序列号更大,接收再泛洪给其他邻居。
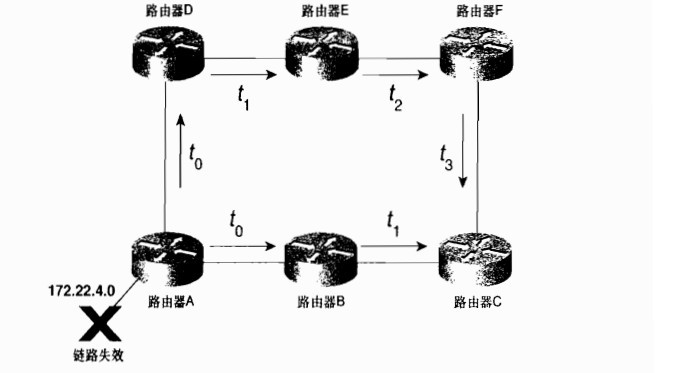
这又是卷一给出经典的案例,分析序列号在链路状态泛洪过程中的作用
1、在t0时刻,路由器A的172.22.4.0的网段出现故障,这时候路由器A向路由器D和B通告了一个LSA,LSA的内容就是告诉路由器B和D链路状态发生了改变。
2、在t1时刻,路由B把这个链路状态信息一通告给了路由器C,同样的路由器D也通告给了E
3、在t3时刻,从另外一个路径过来的 A-D-E-F到达C,C路由器已经有该LSA了,这时候路由器C是否转发给B呢,肯定是不转发的,因为这条LSA的序列号与之前收到的LSA的序列号是一样的。
4、这时候,LSA的泛洪停止了,因为所有路由器的LSA都已经同步了。
5、假设,这时候172.22.4.0的网段在出现了故障后,立马又恢复了,路由器先发送一个故障的LSA通告,序列号为166,紧接着又发送了一个恢复了的LSA的通告,序列号为167,路由器C会先后收到关于故障和恢复的LSA通告,如果没有序列号存在的话,那么路由器C就不知道该接收哪个LSA才是正确的,所以,通过序列号的比较,路由器C会丢弃故障的通告。
(2)、老化时间:用于包含一个通告年龄的字段,其中有个MaxAge来定义LSA的最大年龄值,当某一条LSA到达MaxAge后,那么带有MaxAge值的LSA被泛洪到所有的邻居,邻居收到以后,从数据库中删除。
(3)、LSRefreshTime:一种防止有效LSA到达MAAge的机制。当某条LSA到达了LSRefreshTime时间后,它就会进行flooding,通知邻居刷新LSA的age
链路状态数据库包含的内容
1、路由器链路信息(使用三元组、路由器ID、邻居ID、代价)通告路由器的邻居路由器,
2、末梢网络信息(使用三元组、路由器ID、邻居ID、代价)通过路由器直连连接的末梢网络(没有邻居的网络)区域的意义 为了减少链路状态协议的一些不利影响所采用的概念,把影响尽量的缩小在一个区域内。(数据包对内存需求大、算法对CPU消耗更高、链路状态泛洪对带宽的消耗)。

如果大家有任何疑问或者文中有错误跟疏忽的地方,欢迎大家留言指出,博主看到后会第一时间修改,谢谢大家的支持,更多技术文章尽在网络之路Blog(其他平台同名),版权归网络之路Blog所有,原创不易,侵权必究,觉得有帮助的,关注、转发、点赞支持下!~。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









