







**
问题:urllib.error.HTTPError: HTTP Error 418:
**
问题描述:当我使用Python的request爬取网页时返回了http状态码为418,
错误描述:经过网上查询得知,418的意思是被网站的反爬程序返回的,网上解释为,418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that the server refuses to brew coffee because it is a teapot. This error is a reference to Hyper Text Coffee Pot Control Protocol which was an April Fools’ joke in 1998.
翻译为:HTTP 418 I’m a teapot客户端错误响应代码表示服务器拒绝煮咖啡,因为它是一个茶壶。这个错误是对1998年愚人节玩笑的超文本咖啡壶控制协议的引用。
解决办法:添加header的信息,然后再次请求,就可以了
使用requests并添加headers信息后:
import requests
headers={'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
r = requests.get(url,headers=headers)
html = r.text
print(html)
Http Header之User-Agent
User Agent中文名为用户代理,是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。通过这个标 识,用户所访问的网站可以显示不同的排版从而为用户提供更好的体验或者进行信息统计;例如用手机访问谷歌和电脑访问是不一样的,这些是谷歌根据访问者的 UA来判断的。UA可以进行伪装。
浏览器的UA字串的标准格式:浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识版本信息。但各个浏览器有所不同。
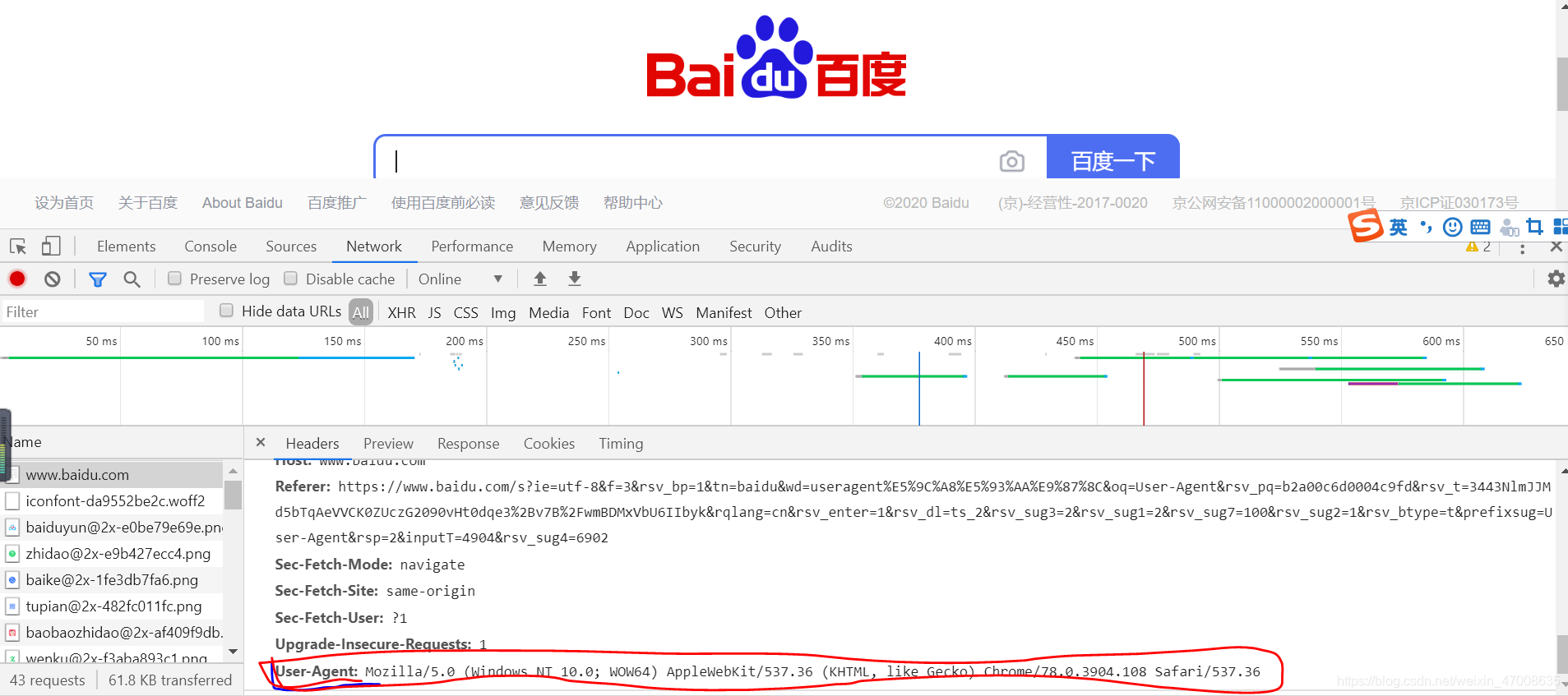
如何查看自己浏览器的User-Agent
1.鼠标右键,“审查元素”

2.network,刷新页面,在左侧Name列找到网址点击,右侧Header,Request Headers里面















 6336
6336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









