






作者丨知凡
来源丨PaperWeekly
编辑丨极市平台
大家是不是埋头准备 CVPR 2025 的投稿苦于涨点困难?快来看看热气腾腾的新鲜 TPAMI 2024 论文:

论文链接:
https://www.arxiv.org/abs/2408.12879
代码已开源:
https://github.com/Linwei-Chen/FreqFusion
在语义分割、目标检测、实例分割、全景分割上都涨点!
01 这篇论文做了什么?
现有的语义分割、目标检测等高层密集识别模型中,往往需要将低分辨高层特征与高分辨率低层特征融合,例如 FPN:
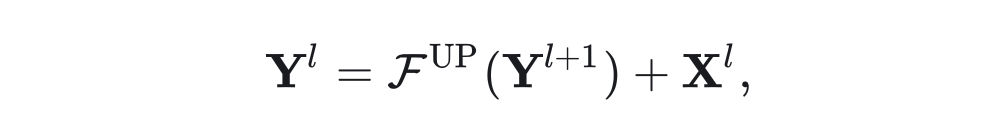
虽然简单,但这样粗糙的特征融合方式显然不够优秀,一方面特征本身对同一类目标的一致性不够高,会出现融合特征值在对象内部快速变化,导致类别内不一致性,另一方面简单的上采样会导致边界模糊,以及融合特征的边界模糊,缺乏精确的高频细节。
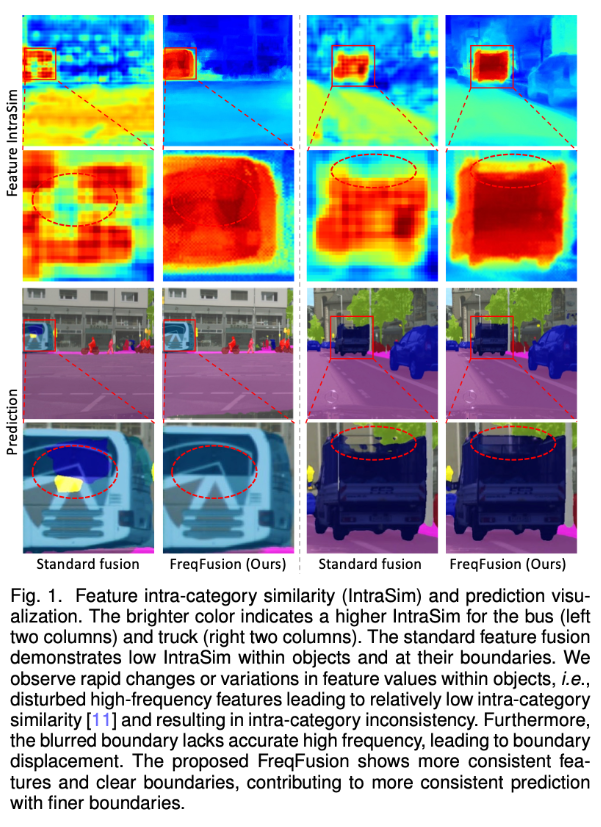
02 提出了什么方法?
FreqFusion 提出: 为了解决这些问题,作者提出了一种名为 Frequency-Aware Feature Fusion(FreqFusion)的方法。FreqFusion 包括:
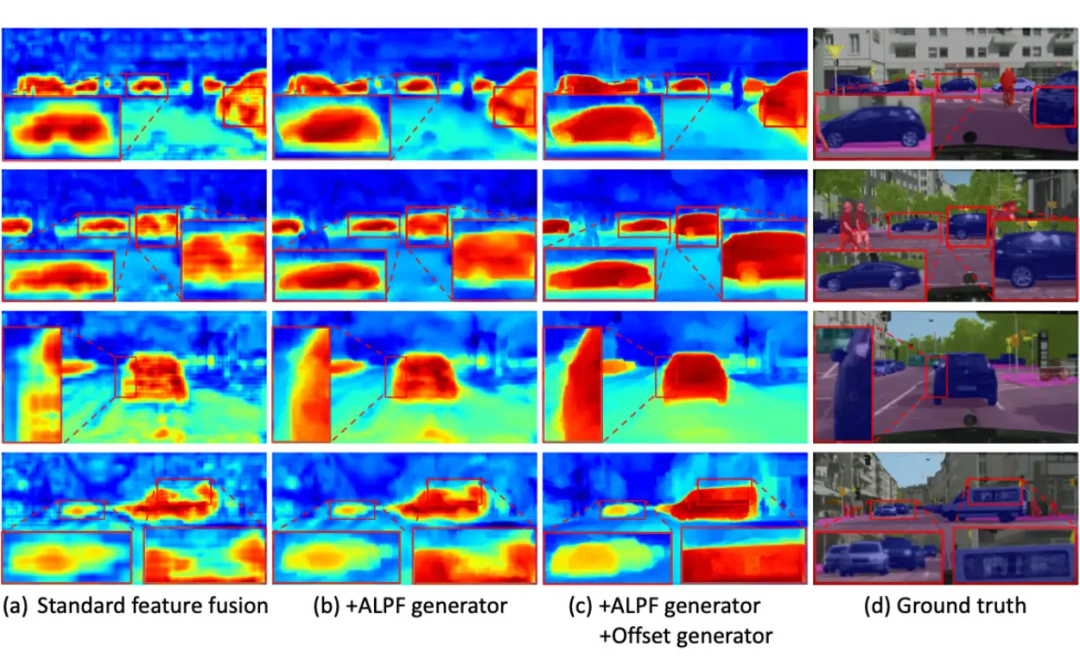
自适应低通滤波器(ALPF)生成器: 预测空间变化的低通滤波器,以在上采样过程中减少对象内部的高频成分,降低类别内不一致性。
偏移生成器: 通过重采样,用更一致的特征替换大的不一致特征,使得同一类目标特征更稳定一致。
自适应高通滤波器(AHPF)生成器: 增强在下采样过程中丢失的高频细节边界信息。

用特征图进行分析对比,发现 FreqFusion 各个部分都可以显著提高特征的质量!
文中给了大量的分析和详细的说明,具体方法可以看原文~
03 涨点涨了多少?
3.1 语义分割semantic segmentation
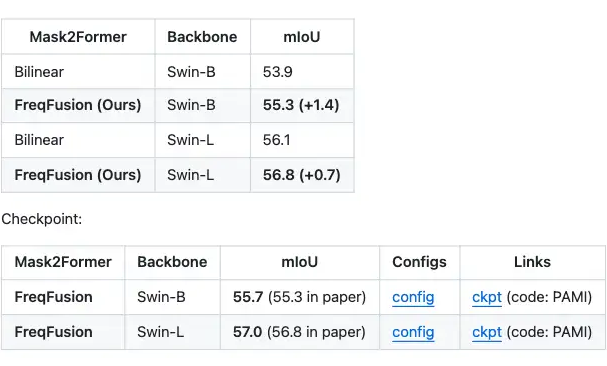
轻量化语义分割 SegNeXt,在 ADE20K 上 +2.4 mIoU(实际 checkpoint,+2.6mIoU)

强大的 Mask2Former 已经在 ADE20K 上取得很好的结果,FreqFusion 还能狠狠进一步讲 Swin-B 提升 +1.4 mIoU(实际给出的 checkpoint,+1.8 mIoU),即便是重型的 Swin-Large,也能提升高 +0.7 mIoU(实际给出的 checkpoint,+0.9 mIoU)。不得不说论文里汇报的结果还是保守了。
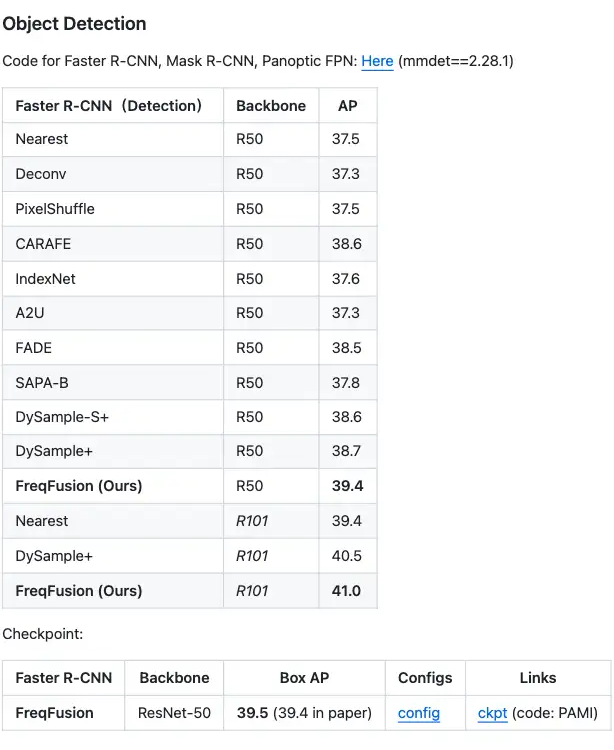
3.2 目标检测object detection
Faster RCNN +1.9 AP(实际公开的 checkpoint,+2.0 AP)
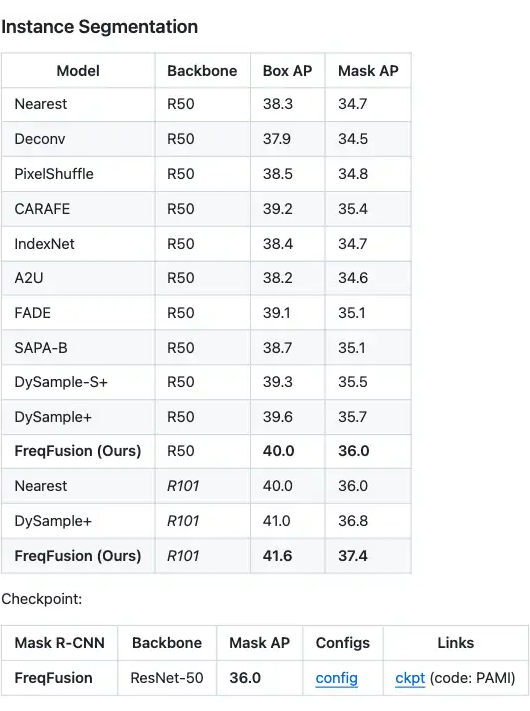
3.3 实例分割instance segmentation
Mask R-CNN,+1.7 box AP,+1.3 mask AP。
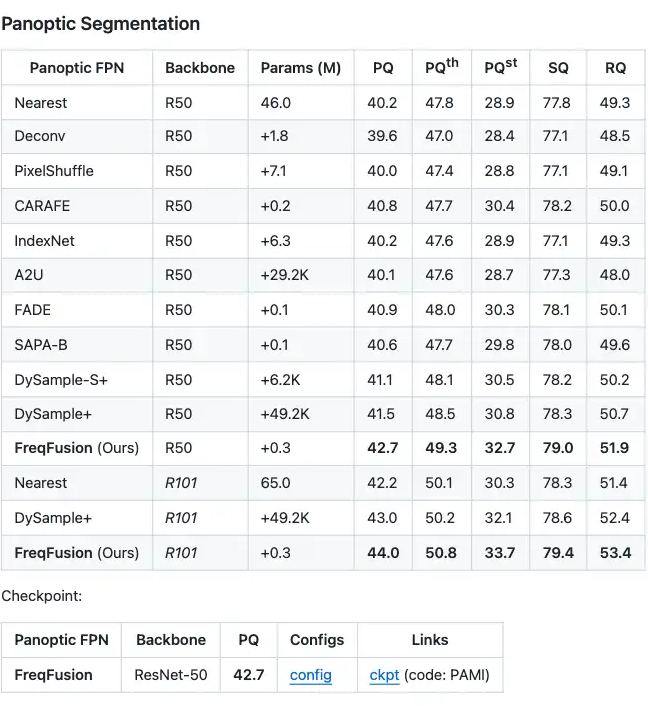
3.4 全景分割panoptic segmentation
PanopticFCN,+2.5 PQ。
04 如何使用?
简单来说,示例如下:
m = FreqFusion(hr_channels=64, lr_channels=64)
hr_feat = torch.rand(1, 64, 32, 32)
lr_feat = torch.rand(1, 64, 16, 16)
_, hr_feat, lr_feat = m(hr_feat=hr_feat, lr_feat=lr_feat)FreqFusion 的简洁代码可在此处获得。通过利用它们的频率特性, FreqFusion 能够增强低分辨率和高分辨率特征的质量 (分别称为 和 feat, 假设的大小 是的两倍 Ir_feat )。用法非常简单, 只要模型中存在 这种形式的不同分辨率特征相融合的情况就可以使用 FreqFusion 对模型进行提升涨点。
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









