








简介
Scrapy 框架
- Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架。
- 用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片。
(提高请求效率) - Scrapy 使用了Twisted(aiohttp)异步网络框架来处理网络通讯,可以加快下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求。
安装
pip install --upgrade pip
建议首先更新pip 再安装下列依赖库 否则可能会遇到诸多错误:
pip install twisted
安装 twisted可能会遇到这样问题
building ‘twisted.test.raiser’ extension
error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools
意思是说缺少C++的一些编译工具
所以这里建议大家直接安装编译好的twisted的whl文件
对应资源下载网址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

下载twisted对应版本的whl文件,cp后面是python版本,amd64代表64位,运行命令:
pip install C:\Users\CR\Downloads\Twisted-17.5.0-cp36-cp36m-win_amd64.whl
(后边一部分是 whl文件的绝对路径)
lxml之前应该安装过 可以略过
pip install lxml
这个安装应该没问题
pip install pywin32
安装scrapy框架
pip install Scrapy
如果中途报错,有TimeOut的字眼,应该是网络问题,重复安装几次就行
当然最省事的还是直接替换安装源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
知识
整体结构
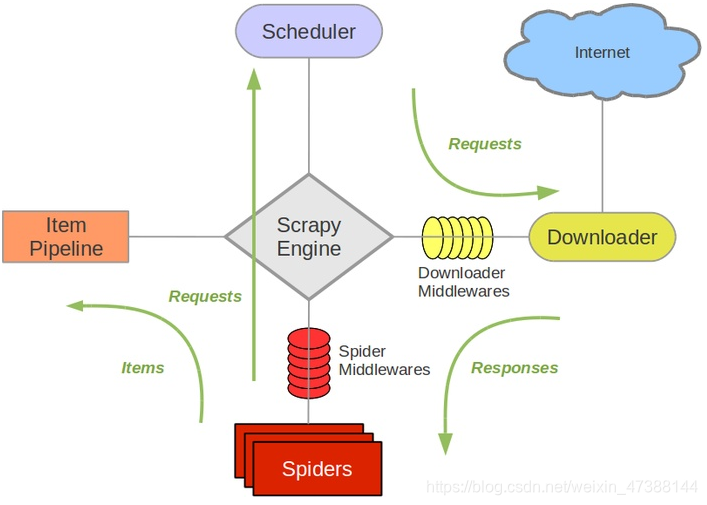
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2958
2958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









