



原文链接:
https://www.gbase.cn/community/post/3883
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。
GBase 8c数据库具有死锁检测和自动解除机制。由多个CN和多个DN构成。就死锁发生的范围来讲,死锁可以发生在单个CN或单个DN里,也可以发生在多个CN或DN里。发生在单个CN或单个DN里的情况,称之为单机死锁;发生在多个CN或DN里的情况,称之为全局死锁,即数据库集群内多个CN、DN上的多个数据库进程间互相调用资源而出现循环等待的情况。本文主要论述分布式全局死锁解除内容。

如上图中所示,在T1这个时刻,事务1 开始(begin),在T2时刻,事务1 更新(update)了id=1行的t(列)值,同时事务2 开始(begin)。在T3时刻,事务2更新(update)了id=4行的t(列)值。然后在T4时刻,事务1想要更新id=4的t值,同时事务2想要更新id=1的t值,此时就会互相等待,形成全局死锁。
全局死锁检测算法主要分为两种,一种是集中式的算法一种是分布式的算法:
1.集中式:GTM节点(中心节点)负责收集集群其他节点的事务锁等待信息,来构建全局等待图-》查询死锁环(深度优先搜索算法、拓扑排序算法)并下发退出命令。这种算法会增加GTM节点负载,使其更容易成为集群性能瓶颈,并且一旦GTM节点有问题则死锁检测就失效了,不建议采用这种算法。
2.分布式:(GBase 8c当前采用的算法)每个CN都会发起死锁检测。探测消息沿着等待关系方向在节点事务处理进程/线程间转发,事务处理线程收到自己发送的探测消息则表名存在全局死锁,事务自己回滚从而解除全局死锁。
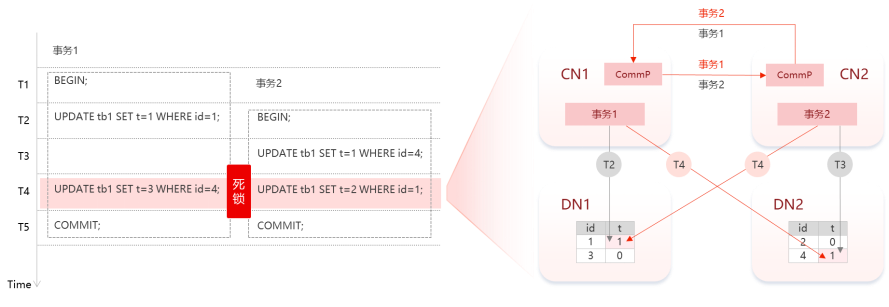
【举例】
当事务1发现要update的数据被其他锁住后,会将这个等待信息发送给锁住数据的那个节点,在这个例子里面就是发起事务2的CN2节点;然后同时事务2发现要update的数据被事务1锁住了,也会在等待超时时间以后,将这个等待信息发送给事务1所在的节点就是CN1。这样事务锁住的时候,后台首先等待一个预先设定的超时时间,当超过这个时间两个节点就发现了他们的等待环,那么首个发现环的节点会将自己的事务退出,从而解除全局死锁的这个问题。
【测试方法】
默认的死锁超时时间是1s,修改成20s:
show deadlock_timeout ;
alter system set deadlock_timeout=20;创建测试表
create table test(id int,info text);
insert into test values(1,'Tom');
insert into test values(2,'Lane');session1,执行更新
begin;
update test set info = 'test' where id = 1;session2,执行更新
begin;
update test set info = 'test' where id = 2;session1,执行更新
update test set info = 'test' where id = 2; --卡住session2,执行更新
update test set info = 'test' where id = 1; --卡住过20s后其中一个会话的事务检测到死锁被杀掉,另外一个会话提交成功。
原文链接:
https://www.gbase.cn/community/post/3883
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









