




摘要
本文提出了一种基于YOLO11-MM框架的多模态目标检测改进方法,通过引入多尺度注意力聚合模块(MSAA)实现红外与可见光特征的高效融合。MSAA模块采用多尺度卷积和空间/通道双注意力机制,有效提升了模型在复杂场景下的检测性能。实验在FLIR、M3FD和LLVIP等数据集上验证了该方法的有效性,特别是在处理目标尺度差异大、低对比度等挑战时表现突出。文章详细介绍了模块实现、代码集成和训练配置,为多模态目标检测研究提供了实用参考。
目录
二、多尺度注意力聚合模块(Multi-Scale Attention Aggregation Module,MSAA)
一、核心思想(MSAA × YOLO11-MM × 多模态特征聚合)
二、突出贡献(MSAA 在 YOLO11-MM 中的实际价值)
三、优势特点(FLIR / M3FD / LLVIP 多数据集实战表现)
一、引言
本文围绕 YOLO11-MM 多模态目标检测框架 的结构改进与性能优化展开研究,重点探讨通过引入 多尺度注意力聚合模块(Multi-Scale Attention Aggregation Module,MSAA),实现红外(Infrared)与可见光(Visible)特征之间的高效交互与深度融合,从而提升模型在复杂场景下的目标检测鲁棒性与整体准确性。
在具体实现层面,本文系统分析多尺度注意力聚合模块(Multi-Scale Attention Aggregation Module,MSAA)在红外–可见光特征融合中的应用方式与插入位置,旨在探索一种兼顾性能与效率的多模态融合策略。基于多组对比实验,本文采用 中期融合(Middle Fusion) 作为主要实现方案,重点研究MSAA在多尺度特征层级中的介入时机对特征表达能力及最终检测性能的影响,使模型能够在不同语义层级上实现更加充分和有效的信息交互。
需要特别说明的是,本文实验所采用的数据集为 FLIR 数据集的子集,而非完整 FLIR 数据集。在进行实验复现或进一步扩展研究时,读者需注意数据划分与配置设置上的差异,以避免因数据规模或分布不一致而导致的结果偏差。希望本文的研究思路与工程实践经验,能够为多模态目标检测领域的研究者与工程实践者提供具有参考价值的技术借鉴与实现范式。
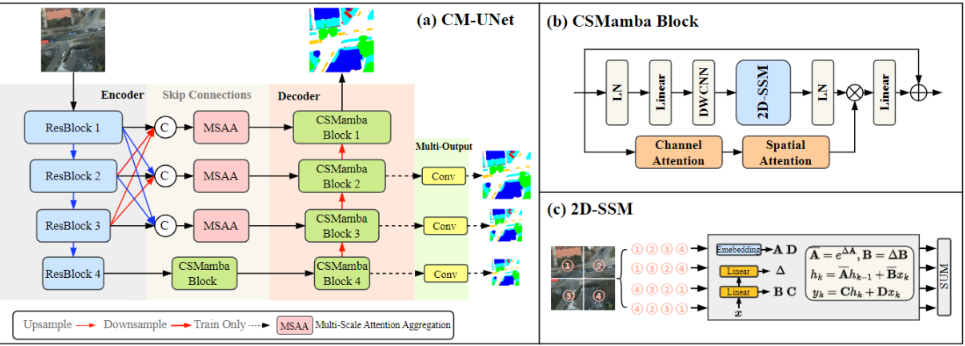
二、多尺度注意力聚合模块(Multi-Scale Attention Aggregation Module,MSAA)
论文链接: https://arxiv.org/pdf/2405.10530
代码链接:https://github.com/XiaoBuL/CM-UNet
一、核心思想(MSAA × YOLO11-MM × 多模态特征聚合)
多尺度注意力聚合模块 MSAA(Multi-Scale Attention Aggregation Module) 的核心思想是:在红外与可见光特征完成初步融合之后,通过多尺度卷积与空间/通道双注意力机制,对跨模态特征进行进一步聚合与精炼,从而压缩冗余信息并强化判别性表达。
在 YOLO11-MM 多模态检测框架中,MSAA 接收来自红外与可见光的等尺度特征(通常位于中高层特征金字塔),首先在通道维度进行拼接并通过卷积降维:
![]()
随后引入 多尺度卷积分支(3x3、5x5、7x7) 捕获不同感受野下的上下文信息,并在空间维度与通道维度分别施加注意力约束:
![]()
“多尺度建模 + 空间/通道协同调制”的设计,使 MSAA 能够在多模态场景中有效兼顾目标结构、尺度变化与模态互补特性。
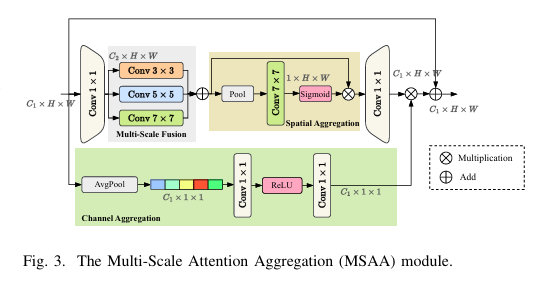
二、突出贡献(MSAA 在 YOLO11-MM 中的实际价值)
MSAA 在 YOLO11-MM 多模态框架中的突出贡献,在于将多模态融合从简单特征叠加,提升为“多尺度上下文感知 + 双重注意力精炼”的结构化聚合过程,显著增强了融合特征的表达质量。
从论文与代码实现角度来看,其关键贡献体现在三个方面:
1)多尺度上下文聚合:通过并行卷积核建模不同尺度信息,缓解 FLIR 与 M3FD 场景中目标尺度差异大、语义跨度大的问题;
2)空间注意力聚焦关键区域:利用均值池化与最大池化生成空间注意力图,抑制背景噪声与无关区域;
3)通道注意力重标定模态贡献:通过全局池化与轻量 MLP 结构,动态调节不同通道(尤其是跨模态通道)的重要性。
三、优势特点(FLIR / M3FD / LLVIP 多数据集实战表现)
从多数据集实验与工程实践角度来看,MSAA 在 YOLO11-MM 框架中展现出显著的优势特点,并且在不同类型的多模态数据集上均具备良好的适应性。
在 FLIR 红外–可见光数据集 中,MSAA 能够有效缓解红外热噪声与可见光低对比度问题,使模型更加关注行人、车辆等目标的结构边缘;
在 M3FD 遥感多模态数据集 中,多尺度卷积与空间注意力机制对大场景、小目标共存的情况尤为友好,有助于提升对复杂背景下目标的感知能力;
在 LLVIP 低照度行人检测数据集 中,通道注意力能够动态调整红外与可见光的贡献比例,提高夜间和弱光条件下的检测鲁棒性。
四 代码说明
# 论文: Efficient Visual State Space Model for Image Deblurring (CVPR 2025)
# 链接: https://arxiv.org/pdf/2405.10530
# 模块作用: 双路融合后以多尺度卷积与通道/空间注意力聚合,压缩跨模态冗余并输出单路判别表征。
import torch
import torch.nn as nn
class _MSAAChannelAttention(nn.Module):
def __init__(self, in_channels: int, reduction: int = 4) -> None:
super().__init__()
red = max(in_channels // reduction, 1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_channels, red, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(red, in_channels, 1, bias=False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
avg = self.fc(self.avg_pool(x))
mx = self.fc(self.max_pool(x))
return self.sigmoid(avg + mx)
class _MSAASpatialAttention(nn.Module):
def __init__(self, kernel_size: int = 7) -> None:
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
y = torch.cat([avg_out, max_out], dim=1)
y = self.conv(y)
return self.sigmoid(y)
class FusionConvMSAA(nn.Module):
def __init__(
self,
dim: int | None = None,
factor: float = 4.0,
spatial_kernel: int = 7,
reduction: int = 4,
) -> None:
super().__init__()
self.dim = dim
self.factor = float(factor)
self.spatial_kernel = int(spatial_kernel)
self.reduction = int(reduction)
self._built = False
self._c = None
self._mid = None
self.down: nn.Module | None = None
self.conv3: nn.Module | None = None
self.conv5: nn.Module | None = None
self.conv7: nn.Module | None = None
self.spatial_attn: nn.Module | None = None
self.channel_attn: nn.Module | None = None
self.up: nn.Module | None = None
def _build_if_needed(self, c: int) -> None:
if self._built and self._c == c:
return
mid = max(int(c // self.factor), 1)
self.down = nn.Conv2d(c * 2, mid, kernel_size=1, stride=1)
self.conv3 = nn.Conv2d(mid, mid, kernel_size=3, stride=1, padding=1)
self.conv5 = nn.Conv2d(mid, mid, kernel_size=5, stride=1, padding=2)
self.conv7 = nn.Conv2d(mid, mid, kernel_size=7, stride=1, padding=3)
self.spatial_attn = _MSAASpatialAttention(kernel_size=self.spatial_kernel)
self.channel_attn = _MSAAChannelAttention(mid, reduction=self.reduction)
self.up = nn.Conv2d(mid, c, kernel_size=1, stride=1)
self._built = True
self._c = c
self._mid = mid
def forward(self, x1, x2=None):
if x2 is None and isinstance(x1, (list, tuple)):
x1, x2 = x1
if not isinstance(x1, torch.Tensor) or not isinstance(x2, torch.Tensor):
raise TypeError("FusionConvMSAA 需要两路输入张量")
if x1.shape != x2.shape:
raise ValueError(f"FusionConvMSAA 要求两路输入形状一致,got {x1.shape} vs {x2.shape}")
_, c, _, _ = x1.shape
self._build_if_needed(c)
x = torch.cat([x1, x2], dim=1)
x = self.down(x)
res = x
x3 = self.conv3(x)
x5 = self.conv5(x)
x7 = self.conv7(x)
xs = x3 + x5 + x7
xs = xs * self.spatial_attn(xs)
xc = self.channel_attn(x)
out = self.up(res + xs * xc)
return out
三、逐步手把手添加MSAA
3.1 第一步
在 ultralytics/nn 目录下面,新建一个叫 fusion的文件夹,然后在里面分别新建一个.py 文件,把注意力模块的“核心代码”粘进去。
注意🔸 如果你使用我完整的项目代码,这个 fusion文件夹已经有了、里面的模块也是有的,直接使用进行训练和测试,如果没有你只需要在里面新建一个 py 文件或直接修改已有的即可,如下图所示。
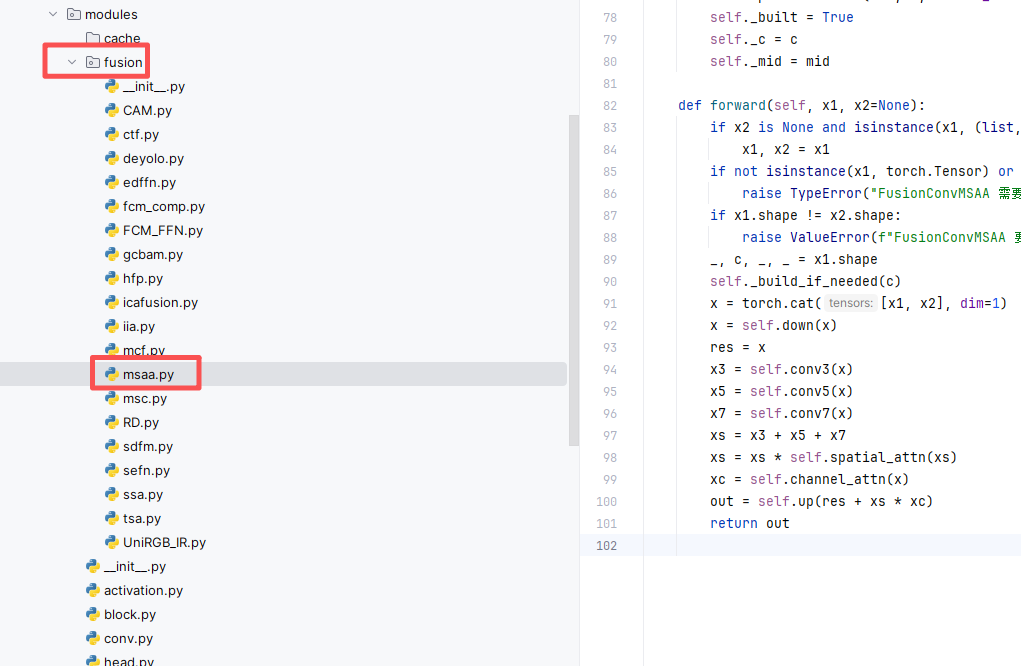
3.2 第二步
第二步:在该目录下新建一个名为 __init__.py 的 Python 文件(如果使用的是我项目提供的工程,该文件一般已经存在,无需重复创建),然后在该文件中导入我们自定义的注意力EMA,具体写法如下图所示。
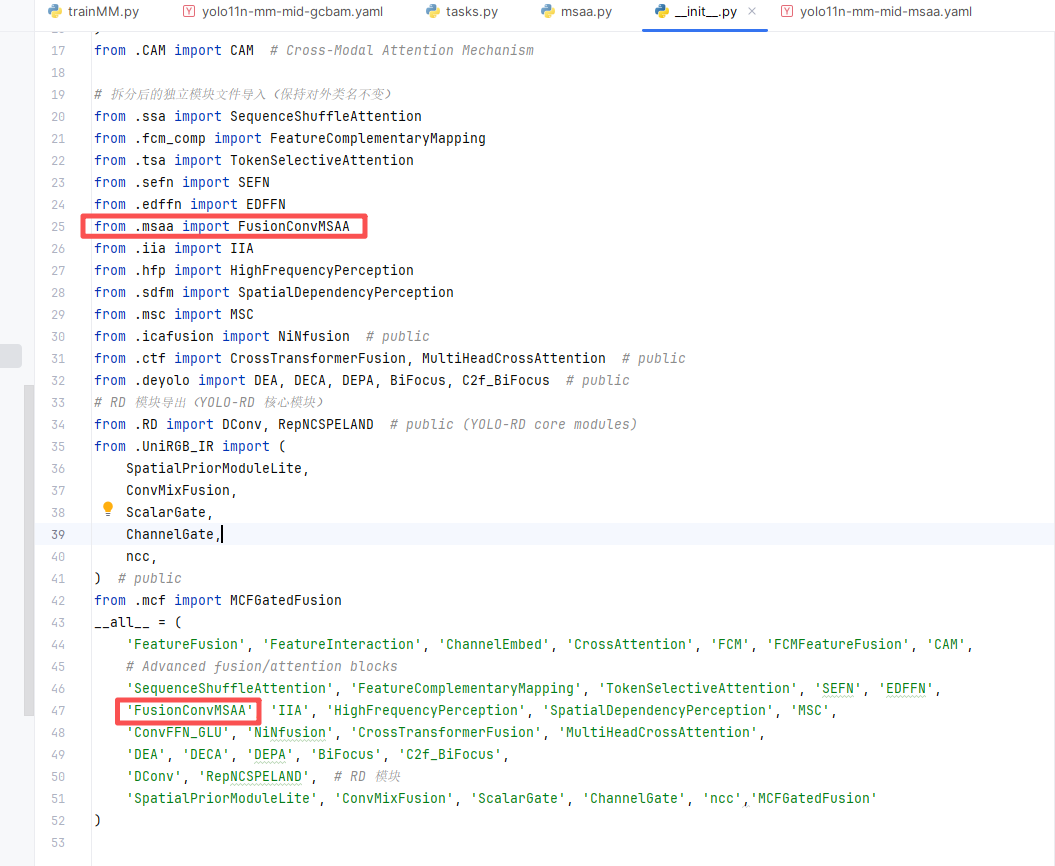
3.3 第三步
第三步:找到 ultralytics/nn/tasks.py 文件,在其中完成我们模块的导入和注册(如果使用的是我提供的项目工程,该文件已自带,无需新建)。具体书写方式如下图所示
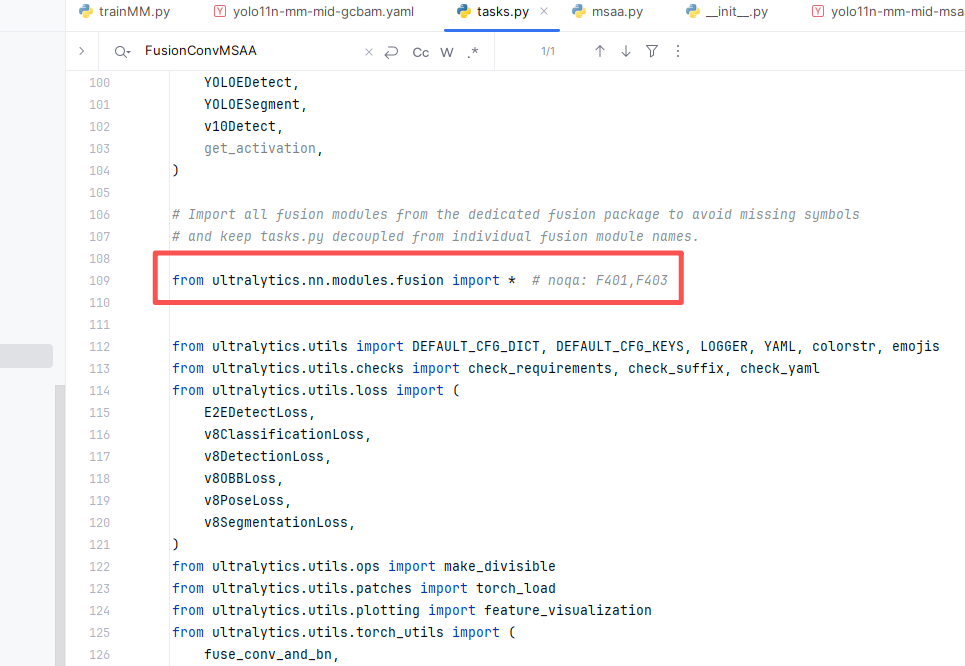
3.4 第四步
第四步:找到 ultralytics/nn/tasks.py 文件,在 parse_model 方法中加入对应配置即可,具体书写方式如下图所示。
elif m in frozenset({FusionConvMSAA}):
# Expect exactly two inputs; output channels follow the left branch
if isinstance(f, int) or len(f) != 2:
raise ValueError(f"{m.__name__} expects 2 inputs, got {f} at layer {i}")
c_left, c_right = ch[f[0]], ch[f[1]]
# Auto infer dim if not provided (None or missing)
if len(args) == 0:
args.insert(0, c_left)
elif args[0] is None:
args[0] = c_left
c2 = c_left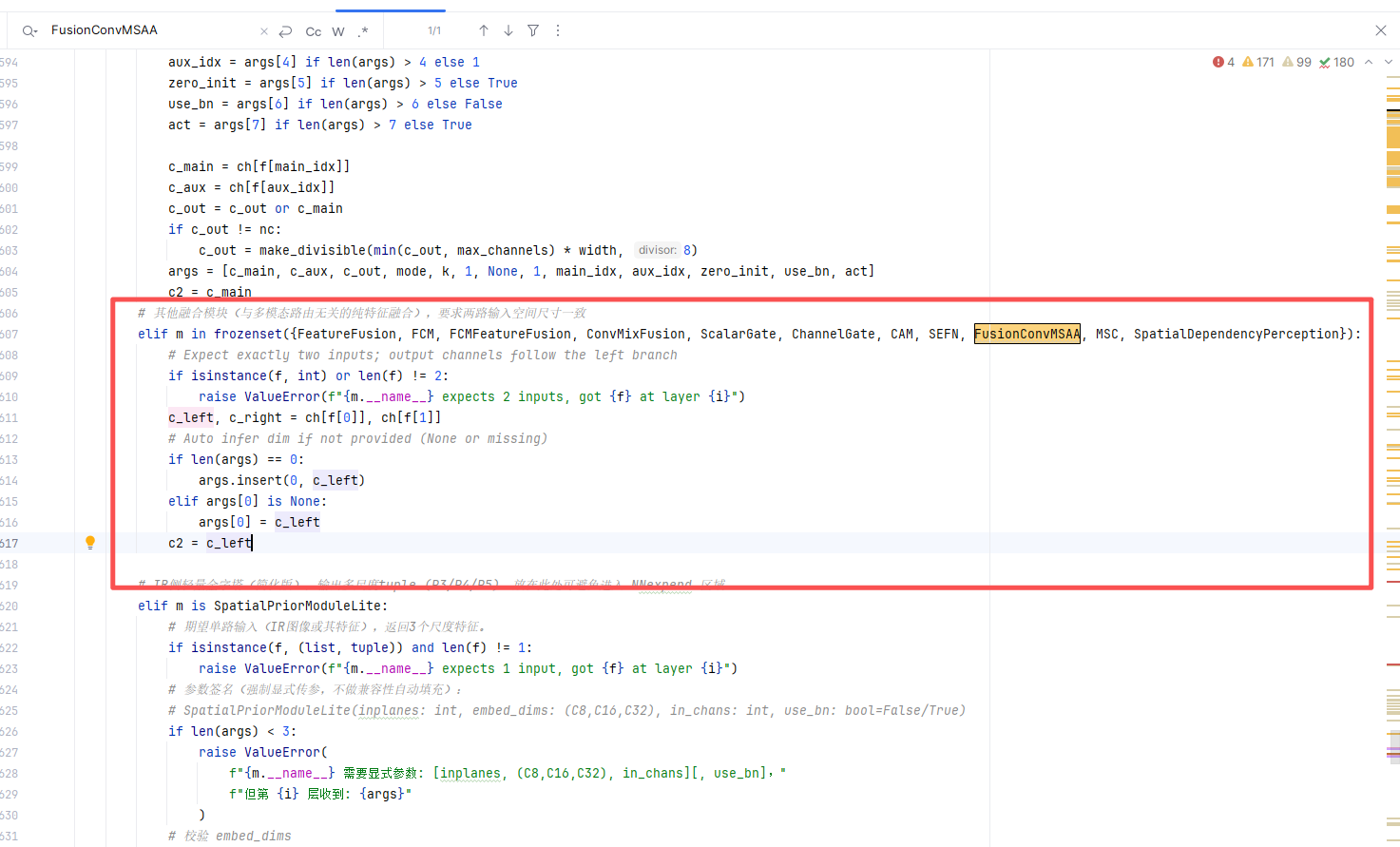
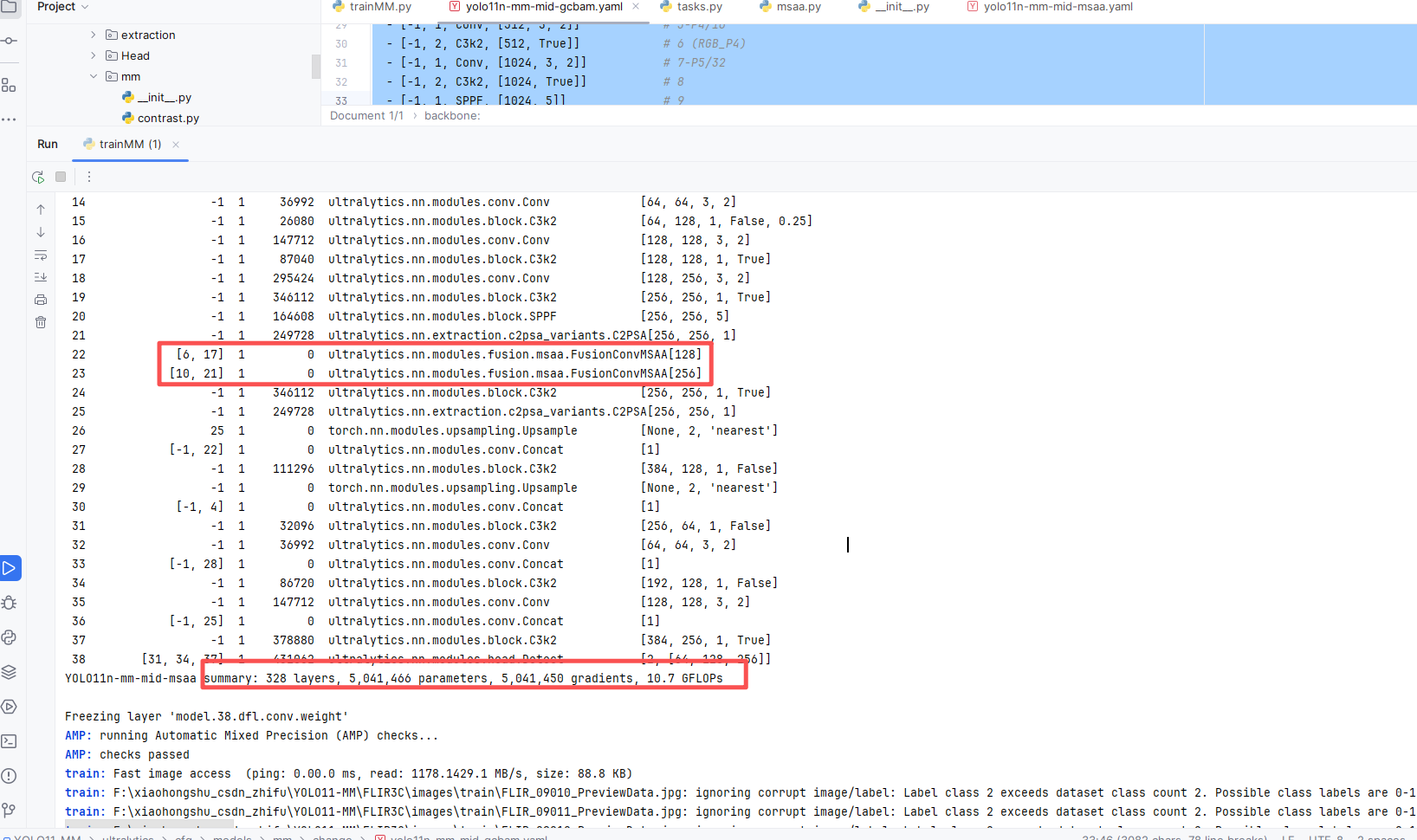
四 完整yaml
训练信息:summary: 328 layers, 5,041,466 parameters, 5,041,450 gradients, 10.7 GFLOPs
# Ultralytics YOLOMM 🚀 Mid-Fusion (GCBAM Test)
# 在 P4/P5 融合后插入 GCBAM(分组 CBAM 增强,单路输入、通道保持)。
# 使用注释
# - 模块: GCBAM(分组通道+空间注意力,单路输入)
# - 输入: [B,C,H,W];输出通道与输入一致
# - 约束: C 必须能被 group 整除
# - 参数(args)顺序: [channel, group, reduction]
# · channel: 传 null 使用运行时输入通道自动推断(推荐)
# · group: int(示例 8),通道分组数,需整除 C
# · reduction: int(默认 4),通道注意力压缩比
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
backbone:
# ========== RGB路径 (层0-10) ==========
- [-1, 1, Conv, [64, 3, 2], 'RGB'] # 0-P1/2 RGB路径起始
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 2
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 (RGB_P3)
- [-1, 2, C3k2, [512, False, 0.25]] # 4
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]] # 6 (RGB_P4)
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]] # 8
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10 (RGB_P5)
# ========== X路径 (层11-21) ==========
- [-1, 1, Conv, [64, 3, 2], 'X'] # 11-P1/2 X路径起始
- [-1, 1, Conv, [128, 3, 2]] # 12-P2/4
- [-1, 2, C3k2, [256, False, 0.25]] # 13
- [-1, 1, Conv, [256, 3, 2]] # 14-P3/8 (X_P3)
- [-1, 2, C3k2, [512, False, 0.25]] # 15
- [-1, 1, Conv, [512, 3, 2]] # 16-P4/16
- [-1, 2, C3k2, [512, True]] # 17 (X_P4)
- [-1, 1, Conv, [1024, 3, 2]] # 18-P5/32
- [-1, 2, C3k2, [1024, True]] # 19
- [-1, 1, SPPF, [1024, 5]] # 20
- [-1, 2, C2PSA, [1024]] # 21 (X_P5)
# ========== P4 / P5 融合 + GCBAM ==========
- [[6, 17], 1, Concat, [1]] # 22: P4 融合
- [-1, 2, C3k2, [1024, True]] # 23: Fused_P4
- [-1, 1, GCBAM, [null, 8, 4]] # 24: Fused_P4_GCBAM(group=8)
- [[10, 21], 1, Concat, [1]] # 25: P5 融合
- [-1, 2, C3k2, [1024, True]] # 26
- [-1, 1, C2PSA, [1024]] # 27: Fused_P5
- [-1, 1, GCBAM, [null, 8, 4]] # 28: Fused_P5_GCBAM
head:
# 自顶向下路径 (FPN)
- [28, 1, nn.Upsample, [None, 2, "nearest"]] # 29 Fused_P5_GCBAM 上采样
- [[-1, 24], 1, Concat, [1]] # 30 + Fused_P4_GCBAM
- [-1, 2, C3k2, [512, False]] # 31
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 32
- [[-1, 4], 1, Concat, [1]] # 33 + RGB_P3(4)
- [-1, 2, C3k2, [256, False]] # 34 (P3/8-small)
# 自底向上路径 (PAN)
- [-1, 1, Conv, [256, 3, 2]] # 35
- [[-1, 31], 1, Concat, [1]] # 36
- [-1, 2, C3k2, [512, False]] # 37 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 38
- [[-1, 27], 1, Concat, [1]] # 39
- [-1, 2, C3k2, [1024, True]] # 40 (P5/32-large)
- [[34, 37, 40], 1, Detect, [nc]] # 41 Detect(P3, P4, P5)
五 训练代码和结果
5.1 模型训练代码
import warnings
from ultralytics import YOLOMM
# 1. 可选:屏蔽 timm 的未来弃用警告(不影响训练,仅减少控制台噪音)
warnings.filterwarnings(
"ignore",
category=FutureWarning,
message="Importing from timm.models.layers is deprecated, please import via timm.layers"
)
if __name__ == "__main__":
# 2. 加载多模态模型配置(RGB + IR)
# 这里使用官方提供的 yolo11n-mm-mid 配置,你也可以换成自己的 yaml
model = YOLOMM("ultralytics/cfg/models/fusion/yolo11n-mm-mid-msaa.yaml")
# 3. 启动训练
model.train(
data="FLIR3C/data.yaml", # 多模态数据集配置(上一节已经编写)
epochs=10, # 训练轮数,实际实验中建议 100+ 起步
batch=4, # batch size,可根据显存大小调整
imgsz=640, # 输入分辨率(默认 640),可与数据集分辨率统一
device=0, # 指定 GPU id,CPU 训练可写 "cpu"
workers=4, # dataloader 线程数(Windows 一般 0~4 比较稳)
project="runs/mm_exp", # 训练结果保存根目录
name="rtdetrmm_flir3c", # 当前实验名,对应子目录名
# resume=True, # 如需从中断的训练继续,可打开此项
# patience=30, # 早停策略,连降若干轮 mAP 不提升则停止
# modality="X", # 模态消融参数(默认由 data.yaml 中的 modality_used 决定)
# cache=True, # 启用图片缓存,加快 IO(内存足够时可打开)
)
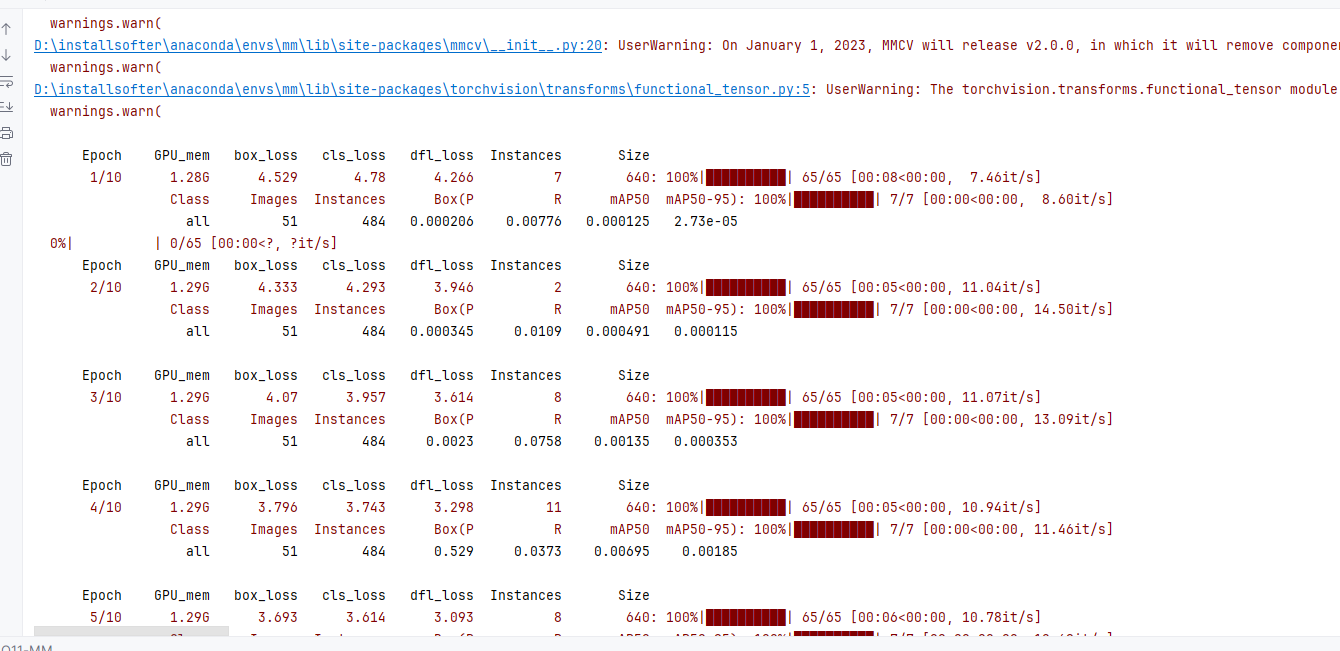
5.2 模型训练结果

六 总结
到这里,本文的正式内容就告一段落啦。
最后也想郑重向大家推荐我的专栏 「YOLO11-MM 多模态目标检测」。目前专栏整体以实战为主,每一篇都是我亲自上手验证后的经验沉淀。后续我也会持续跟进最新顶会的前沿工作进行论文复现,并对一些经典方法及改进机制做系统梳理和补充。
✨如果这篇文章对你哪怕只有一丝帮助,欢迎订阅本专栏、关注我,并私信联系,我会拉你进入 「YOLO11-MM 多模态目标检测」技术交流群 QQ 群~
你的支持,就是我持续输出的最大动力!✨


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









