






这是我数据可视化的期末项目,总体来说我觉得项目呈现达到了我想要的效果
代码开源在我的github仓库,文末会附上链接
大数据安全套分析
数据大屏的呈现

引言
随着时代的发展,性文化对年轻人的影响越来越大,性行为也更趋向于年轻化。但是,性爱虽好,也要学会保护自己,那么选一个合适的Condom就显得尤为重要,本次项目选择了4个品牌(杜蕾斯、冈本、杰士邦、私激),选取销量最高的共计7件商品的评论来进行数据分析和可视化处理,帮助大家有目的的去选择condom,同时分析condom的淘宝搜索关键字词频,寻找出适合提高搜索范围的关键词,分析地区销售量并进行可视化。
下面是开始该项目前绘制的思维导图:
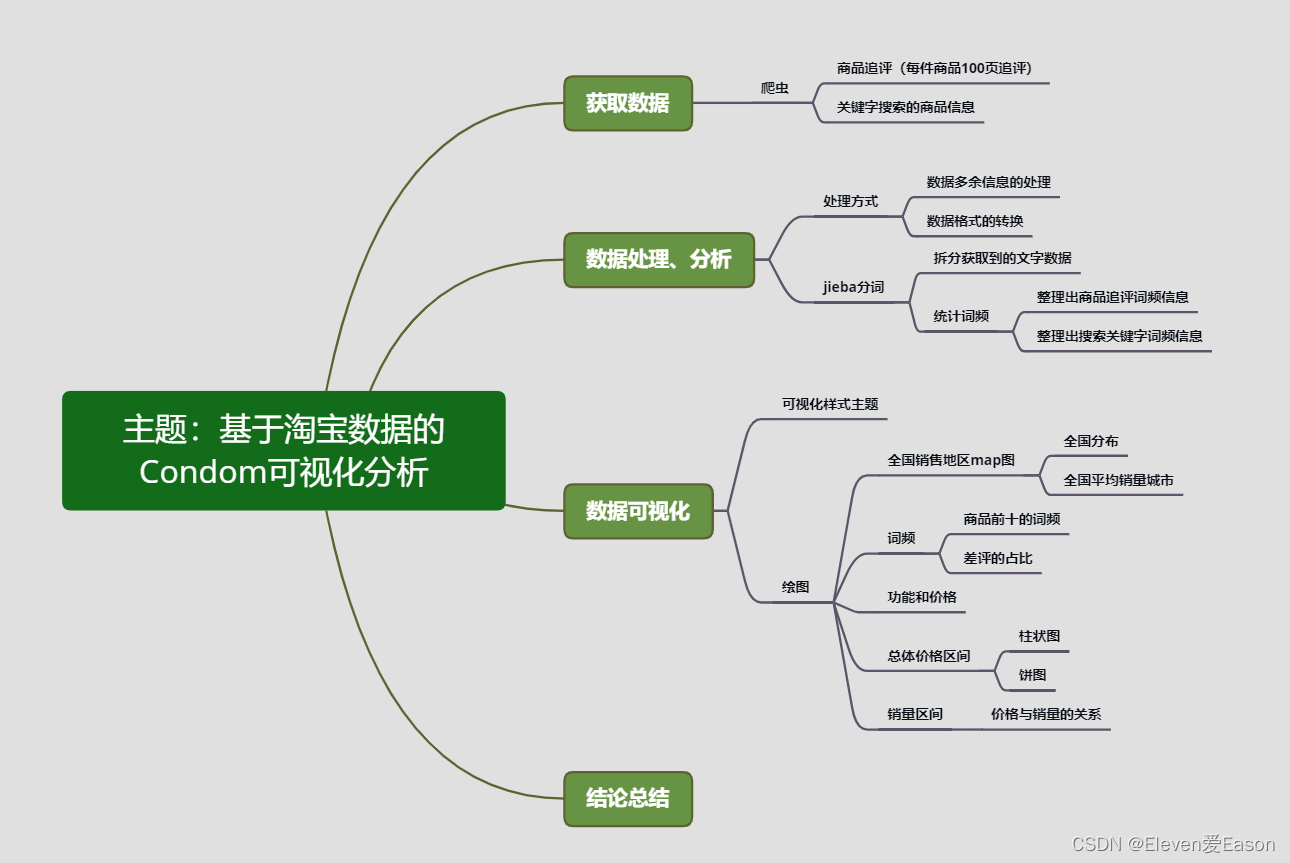
一、获取数据
一切的开始都是建立在数据之上,首要任务是获取数据。对于商品来说,能够展现其在市场的反响的数据,就是该商品的评论。但是,评论都可以人为的去刷,那么该如何去应对这样的刷屏?答案是——追评。正常来说,你购买一个商品之后,它非常好用,或者非常差劲,才会让你点开淘宝评论去给它写个追评。一定程度上来说,追评可以帮我们过滤掉那些刷出来的好评,从而增加数据的可信程度。
确定好了数据,接下来就要考虑如何获取数据。一页一页的复制粘贴肯定是不可能的,这里我选择使用爬虫爬取。
爬虫
俗话说:爬虫学的好,牢饭吃的早
爬虫可以快速爬取网站上的数据,并且架构十分简单。这里我使用的是request库。
1、爬取商品追评
首先爬取7件商品的前100页追评,在试验阶段是想爬取1000页的,每页20条评论,这样就会有20000条评论。可是当开始爬取之后发现了问题。
在大概100页之后的每一页追评数据都是一样的。考虑了两种情况:
-
淘宝的反爬机制,不允许爬取更多的数据。(大概率是这种情况)
-
在100页后的数据不再更新,因为不会有人去浏览100页后的数据。
测试了许多次都是这样。所以们选取前100页、每件商品共计2000条的追评数据进行处理分析。
2、爬取商品信息
我们在淘宝首页选取以”避孕套“为关键字搜索,对搜索返回的页面信息进行数据爬取。
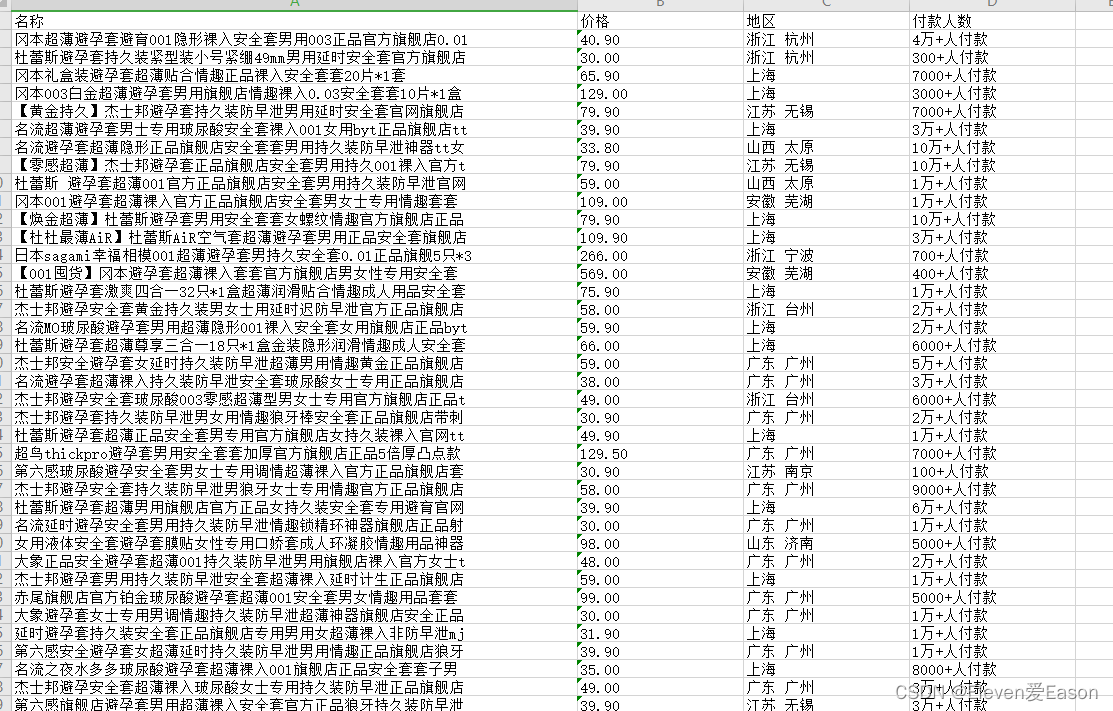
淘宝反爬的解决
在爬取淘宝的时候我经常被淘宝的反爬机制给盾:
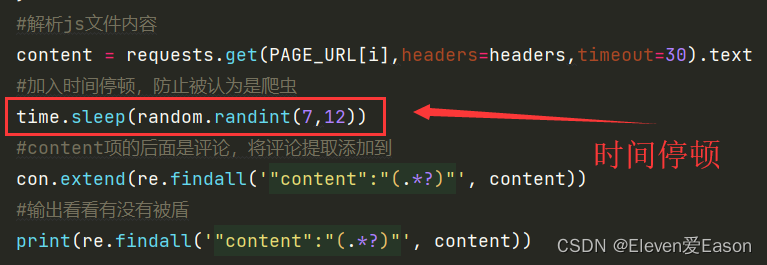
也尝试使用了IP池,但是网站上的免费IP基本都无法使用。在不停的试错中找到了一个很好的方法:sleep
在爬取的for循环中设置sleep函数,每请求爬取一次页面数据,就睡眠一段时间(测试下来7,12s之间,一次都没被盾)。这样可以让淘宝认为你是人在访问,而不是爬虫,就不会出现滑块验证这种东西。
二、数据处理、构思
1、数据处理
获取数据过后,先简单的观察一下数据。对于商品的追评,没有什么需要注意的。但是关键字搜索爬取到的信息有点问题
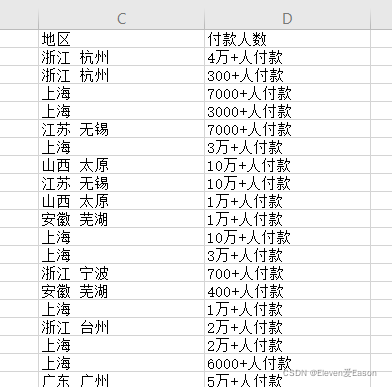
可以看到,地区后面跟有市级城市名称,付款人数不全是数字,还有汉字和符号。
- 考虑到后续需要绘制全国地图,需要的是省级地名,那么地区列中的市级城市名称就是需要省略的
- 付款人数需要进行转变 例如:1.5万+人付款 ----> 15000
- 可能会出现大数吃小数的情况,但是由于无法获取到具体的销售量,这里选择忽略
结巴分词
这里用到一个很有意思的库:jieba库
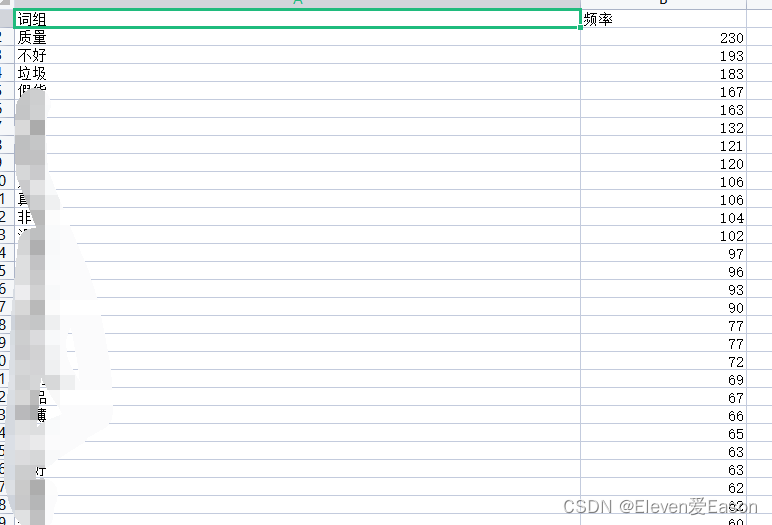
它是用来拆词用的,将一句话拆成一个个词组,可以便于我们统计词频,从而分析我们爬取的评论

通过算法统计后,可以很清楚的知晓词频,知道了一些词的词频有助于我们判断这件商品是否好用。就像上图所示数据,在2000条数据中,”不好“、”垃圾“、”假货“的词频总和超过了500条,如果每一条评论中出现一次,那么差评率将高达25%。但是这样计算我们也忽略了,是否有评论连续打10个垃圾?但是这也反映出顾客对商品的极度不满,所以我们选择保留。
2、数据构思
在处理完数据之后,我得到了七件商品的追评和搜索后的商品数据,当然这些都是通过结巴分词处理好的文件。
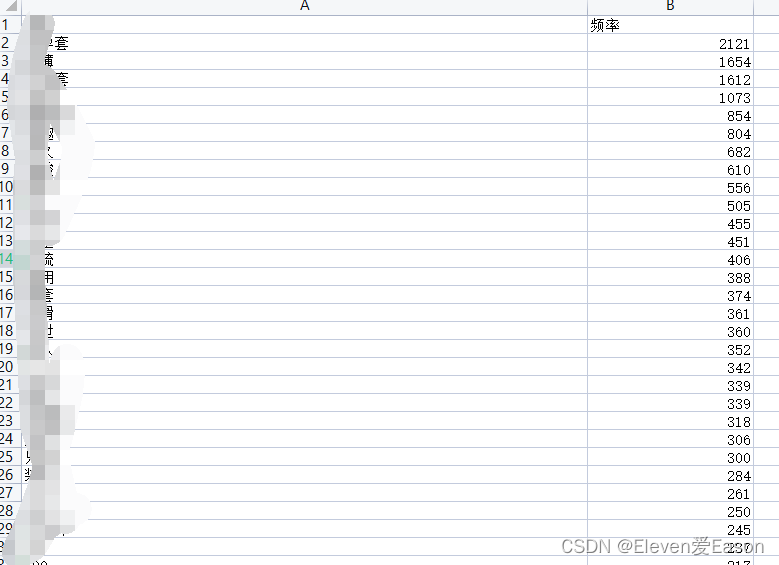
当然还有一份商品信息的数据
打码防止图片挂掉
就这些数据而言,我需要可视化的情况有:全国销售商的销售量、每件商品前十的词频柱状图、价格区间、全国地区的商家数量、搜索关键词的各个词频。
有了这些构思,接下来就进行数据的可视化处理
三、数据可视化
1、销售商销售量
选取不同地区销售商的销售量总和来绘制(PS:由于无法获取到全国地区的买家信息,我只能站在客户的角度对销售商进行分析)
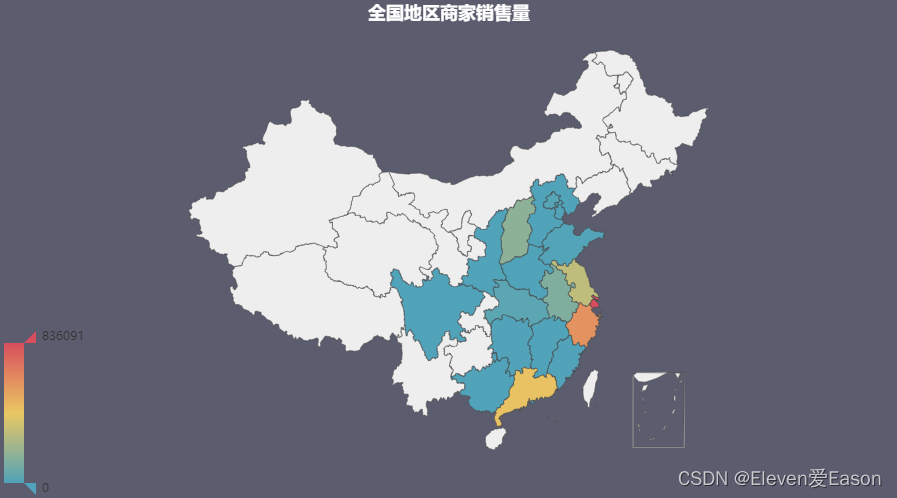
可以看到,上海周边的商家销售量是最高的,广州地区也有很大的产出。所有的销售商都集中在中国的东南沿海方向,但是在西部和北部的销售商却寥寥无几,甚至没有(淘宝商品前50页)
2、每件商品前十评论柱状图
有七件商品,考虑到最后的呈现效果,这里选择使用pyecharts的时间轴组件,将商品名称作为时间轴的标签
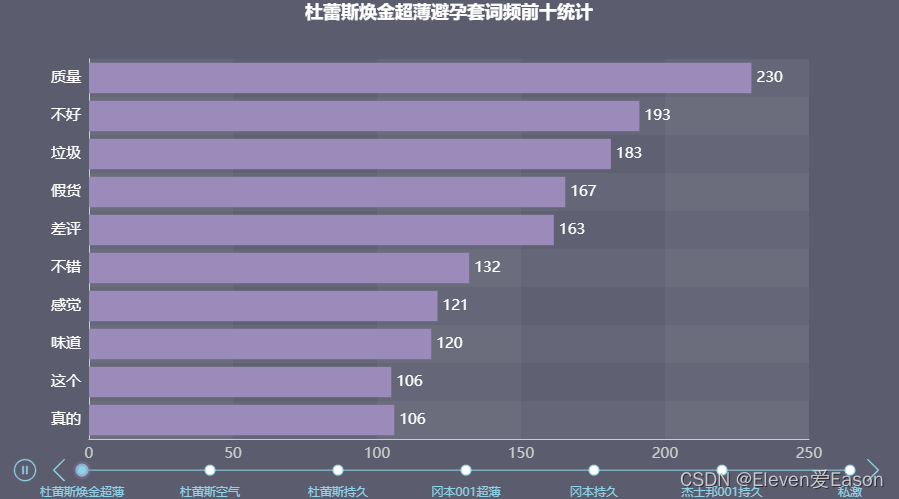
通过时间轴滚动播放可以看到不同商品的追评词频
这里通过分析可以知道,焕金超薄的差评词汇出现的非常多,不建议大家购买;冈本001超薄是口碑最好的产品,虽然也有些许差评,但总体而言大家可以放心购买
3、价格区间分布
价格也是衡量一个商品销售量的重要指标,每当生产出一件商品,需要对市场的价格有所了解和分析才能确定销售价格,不然盲目的定价只会被市场的大流冲散。
这里我选用饼状玫瑰图进行绘制
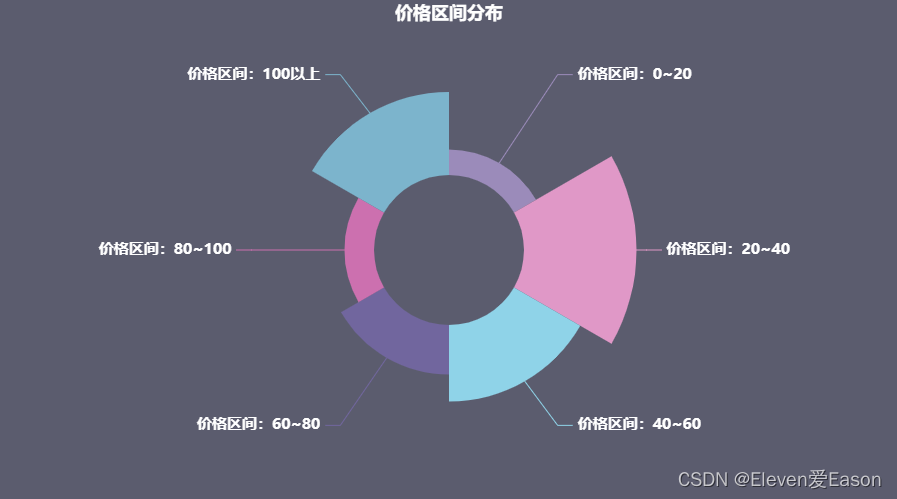
可以看到,在20~40区间的销售量是最高的,但同时我也发现,价格在100以上的也有不少的人数。考虑到现在避孕套市场的普遍售价,100以上的应该是囤货。
4、商家分布
比较好奇哪里商家多,就画出来看看
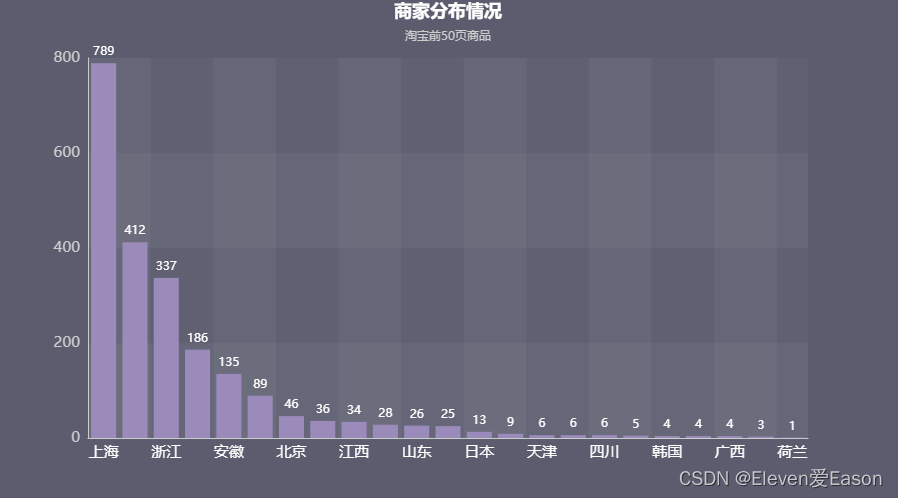
绘制完图形后发现一个问题,商家的分布和地区商家销售量有非常直接的关系,商家分布的前三甲是上海、广东、浙江,同样的全国不同地区商家销售总量的前三甲也是上海、浙江、广东。
但是排列顺序不一样,所以我选择不同地区商家的平均销售量绘制图形,看看有没有新的发现
5、不同地区商家平均销售量
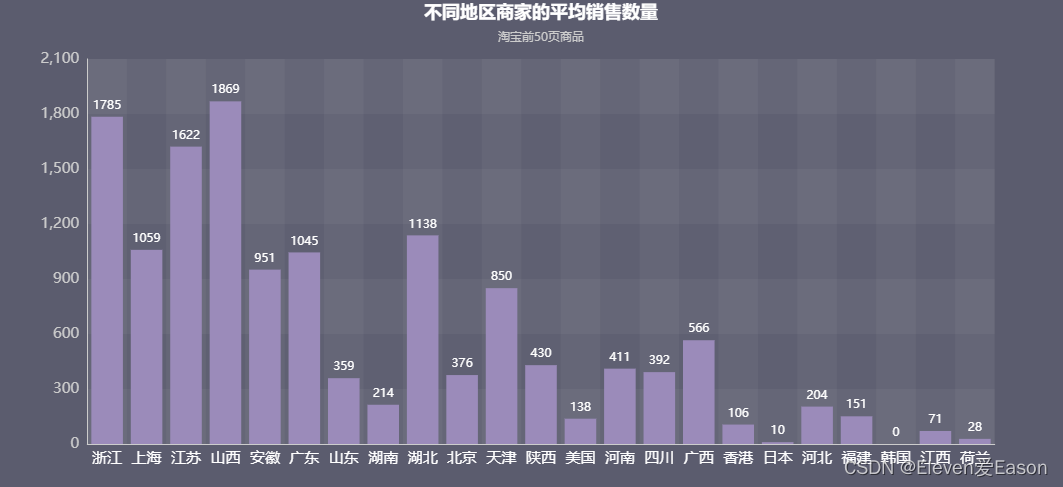
有意思的事情发生了,山西名列榜首,其次才是浙江。上海的平均销售量连前三都没有碰到。而江苏勇夺了第三的宝座。
6、搜索关键词的词频
搜索商品后返回商品界面的呈现也是一门学问,如果你的商品信息包含了人们喜欢搜索的词组,那么被呈现在前面的概率就越高,你的商品就能以更高的曝光率呈现在顾客的视线里面。这里我选择使用词云图绘制

可以看到,超薄是绝大多数产品所出现的关键词,同时一些新颖而且高频的词也呈现了出来,如尿酸、情趣、持久、颗粒。
7、差评率表格绘制
我选择【‘不好’,‘垃圾’,‘差评’】为差评词组的参考,绘制如下表格
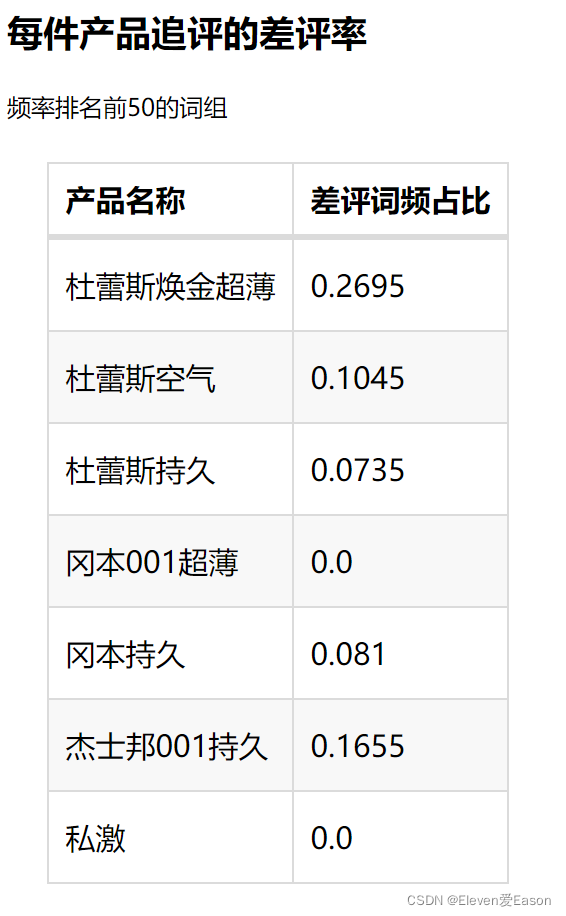
可以看到,私激和冈本001在排名前五十的词组中没有差评,但是杜蕾斯的焕金超薄差评率达到了惊人的27%
四、结论总结
根据上图所示数据,如果我是一个新晋的避孕套销售商,我会有以下的考虑:
- 我可能会考虑去山西分一杯羹,因为山西的平均销售量是最高的。
- 内陆也是不错的选择,由于沿海到内陆地区的物流速度影响,在内陆进行销售可以让内陆消费者购买的商品有更短的配送时间、更少的运输成本。可见内陆市场也是一块大蛋糕。
- 内陆的前景是广阔的,因为销售商少,并且随着国家的发展,新疆西藏这些西部地区也在慢慢的发展起来,网络购物也会更加普及,这也是一个非常庞大的消费群体。更少的运输成本和时间是内陆销售的优势所在,有谁愿意等一个星期的快递呢?
- 对于销售商品的价格定位,如果是3只一盒的商品定位,我会选择定价在20~40这个区间;考虑到囤货的消费者也不在少数,也需要增添大包装的产品(12只装)来顺应消费者的购买习惯。
- 产品的定位:
- 尿酸似乎是一个非常新颖的方向,我也去了解过,使用尿酸的避孕套在性爱过程中不容易干,这也是广大消费者需要的功能。
- 颗粒、狼牙、情趣这些关键词也有一定的指向性,消费者喜欢玩一些花里胡哨的,那么衍生一下,使用情趣内衣、情趣玩具作为附加产品也会提高消费者的购买欲望,因为这些东西并没有太多专门的实体店去销售,就算有,这些私密物品大家往往也不会选择线下实体店去购买,那么网络销售将会挑起大梁。
- 超薄是除开一些主要关键词(避孕套,安全套这些)出现频率最高的,冈本是这方面的领军人物,可以考虑和冈本企业谈合作关系。
- 持久似乎是人们一直关注的问题,要是有外用产品可以提高持久性,那我相信肯定会卖爆掉。
- 早泄是病,得治,别想着避孕套能解决你秒射。
同时重要的事情说三遍:不要卖假货!不要卖假货!不要卖假货!
这是一个销售商最重要的品质,也是消费者最关注的重心,所以不要售假。
















 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











