






一、Java语言概述
一. 计算机语言发展史
• 机器语言
• 汇编语言
• 高级语言
• 面向对象语言
二. Java版本发展
1. 版本更新
时间 描述
1991~1995 Sun为了占领智能消费电子产品市场,由james gosling负责该项目,来开发Oak语言
1995 将Oak改名为Java
1996 发布JDK1.0
1997 发布JDK1.1
1998 发布JDK1.2,将该版本命名为J2SDK,将Java更名为Java 2
1999 将Java分为三大块:J2SE(Java标准版)、J2EE(Java企业版)、J2ME(Java微型版本)
2000 发布J2SE1.3
2002 发布J2SE1.4
2004 此时不再叫J2SE1.5,叫5.0
2005 2005 Java 10周年,将J2SE改为 Java SE、将J2EE改为 Java EE、将J2ME改为 Java ME
2006 发布 Java SE 6
2011 Oracle 发布 Java SE 7
2014 Oracle 发布 Java SE 8
2017 Oracle 发布 Java SE 9
2. Java三大体系
Java SE
Java SE(JavaPlatform,Standard Edition)。Java SE以前称为J2SE。它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的Java应用程序。Java SE 包含了支持Java
Web服务开发的类,并为Java EE提供基础。
Java EE
Java EE(Java Platform,Enterprise
Edition)。企业版本帮助开发和部署可移植、健壮、可伸缩且安全的服务器端Java应用程序。Java EE是在Java
SE的基础上构建的,它提供Web 服务、组件模型、管理和通信API,可以用来实现企业级的面向服务体系结构和Web 2.0应用程序。 Java
EE既是一个框架又是一种规范,说它是框架是因为它包含了很多我们开发时用到的组件,例如:Servlet,EJB,JSP,JSTL等。说它是规范又如我们开发web应用常会用到的一些规范模式,Java
EE提供了很多规范的接口却不实现,将这些接口的具体实现细节转移到厂商身上,这样各家厂商推出的Java
EE产品虽然名称实现不同,但展现给外部使用的却是统一规范的接口。
Java ME
Java ME(Java Platform,Micro Edition)。Java
ME为在移动设备和嵌入式设备(比如手机、PDA、电视机顶盒和打印机)上运行的应用程序提供一个健壮且灵活的环境。Java
ME包括灵活的用户界面、健壮的安全模型、许多内置的网络协议以及对可以动态下载的连网和离线应用程序的丰富支持。基于Java
ME规范的应用程序只需编写一次,就可以用于许多设备,而且可以利用每个设备的本机功能。
如图所示

3. Java特性
语言特点
简单易学、面向对象 、平台无关性
4. Java环境搭建
4.1 环境配置
安装JDK
JDK是整个Java开发的核心,它包含了Java的运行环境(JVM+Java系统类库)和JAVA工具。

从官网下载JDK,根据不同系统选择需要的版本。 官网下载地址如下:http://www.oracle.com/technetwork/java/javase/downloads,下载后直接点击下一步安装即可。
配置环境变量(以windows系统为例)
第一步:
配置JAVA_HOME环境变量右击我的电脑–>点击属性–>左侧的高级系统设置–>点击右下方的环境变量–>点击新建或者编辑系统变量中的JAVA_HOME–>输入JDK的安装目录

第二步:配置Path环境变量右击我的电脑–>点击属性–>左侧的高级系统设置–>点击右下方的环境变量–>双击系统变量中Path属性–>添加%JAVA_HOME%/bin值至尾部 【注意】: “;”来分隔

第三步:配置CLASSPATH环境变量右击我的电脑–>点击属性–>左侧的高级系统设置–>点击右下方的环境变量–>双击系统变量中classpath属性或新建classpath–>添加%JAVA_HOME%/lib值至尾部
【注意】: “.”添加至最前边,并用”;”与后边的隔开

环境变量简介
(1) JAVA_HOME:指定JDK的安装路径,作为全局变量用作后面配置的变量。
(2) Path:windows系统根据Path环境变量来查找命令。Path环境的值是一系列的路径,如果能通过Path找到这个命令,则该命令是可执行。否则报“XXX命令不是内部或外部命令,也不是可运行的执行程序或批处理文件”。
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
(3) CLASSPATH:指定了运行Java程序时,查找Java程序文件的路径。
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
验证环境变量
按键win+r->输入cmd->进入window命令行界面->输入javac -version->验证版本是否正确。
【注意】:设置环境后要新打开cmd窗口才能生效
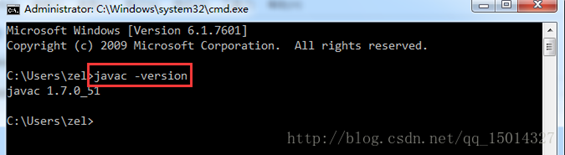
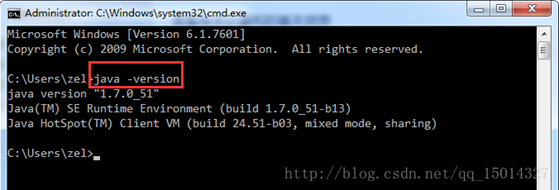
按键win+r->输入cmd->进入window命令行界面->输入java -version验证版本和输出是否正确。
4.2 Eclipse安装使用
• 下载和安装
下载地址:官网下载!
安装:绿色版免安装
• 基本使用
• 使用Eclipse创建一个HelloWorld工程,并实现打印 “HelloWorld”到控制台
5. Java编码规范
• 严格区分大小写
• 源文件以”.java”为后缀,基本组成单元为class
• 一个Java源文件只能有一个public类,其它非public不限。当存在public类时,源文件名称必须与该类同名,区分大小写。
• 程序主入口为main方法,标准格式为:public static void main(String[] args){}
• 类内部的方法代码以语句为最小单位,每个语句以”;”为分号结束
二、程序设计基础
一、介绍
本章节主要学习程序基础,主要涉及的知识点分为三大块:变量、流程控制、方法。
那么在开始本章内容之前,我们先思考几个问题:
1. 我们经常看到一个项目成千上万行代码,这些代码都是形成的呢?
2. 一条语句又是怎么形成的呢?
3. 如果在项目中某一段功能代码需要被重复使用几遍,怎么办?我们就一遍遍地写么?
【答案】:
这些成千上万行的代码都是由最简单的一个个语句按照某种流程堆积而成的;
一条语句一般由关键字、变量和运算符等组成。
Java中方法可以解决代码复用问题。
1、标识符
1.标识符
1.1释义
标识符就是用于给程序中的变量、类、方法命名的符号。标识符可以有编程人员自由定义,但需要遵循一定的命名规则。
1.2命名规则
可以由字母、数字、下划线(_)、美元符号($)组成。
必须以字母、下划线或美元符号开头,不能以数字开头。
不能指定为关键字。
长度没有限制,但定义时一般以见名知义为原则。
使用驼峰命名,类名首名字均大写,常量全部字母大写;方法名、属性名的单词首字母小写中间的单词首字母大写。
2、关键字
2.关键字
2.1释义
Java语言中用以特殊用途而预占用的单词或标识符称之为关键字,Java中的关键字均为小写。
2.2关键字
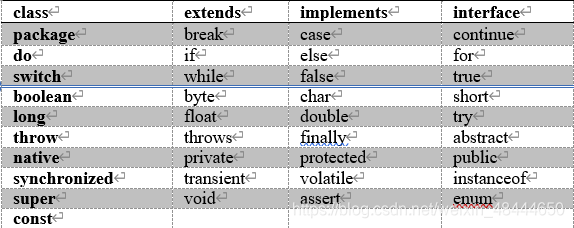
除了上面表格中,goto和const为Java语言中的两个保留字。保留字是指预留的还未被使用的关键字,但可能在将来的版本中使用。
3、常量、变量及作用域
常量
常量也可称为字面值,即字面显示的值,其本身不会发生变化。
【样例】
数值型 1234 , 3.14
字符常量 'c'
逻辑常量值 true , false
字符串常量 "Hello"
-
一种final修饰下的变量也称为常量。 【格式】 final 数据类型 常量名称[=值]
【常量与变量区别】
常量在程序运行过程中其值不能改变。变量是用于存储可变数据的容器,存储一定格式的可变数据。
命名规范不一样。默认常量为全大写,而变量为驼峰。
修饰符不同。一般常量都会用final修饰。变量不会。而且,为了节省内存,常量都会同时使用static修饰。
变量
变量是程序中最基本的存储单元,由作用域、变量类型、变量名组成。
1.1变量的声明
Java是强声明式语言,每个变量在使用前均要先声明。
【声明格式】数据类型 变量名称[=值];
【代码示例一】 int age; //只声明
【代码示例二】 int age = 18; //直接初始化
1.2变量分类
变量分为局部变量、成员变量、类变量。
1.2.1局部变量 (本地变量)
方法的形式参数以及在方法中定义的变量。
【格式】 (type name = value)
【作用范围】
形参:在方法体中任何位置都可以访问。
方法中定义变量:从定义处开始,直到所在代码块结束。
【生命周期】
出生:运行到创建变量语句时。
死亡:超过其作用范围。
1.2.2成员变量 (实例变量,属性)
成员变量就是类中的属性。当new对象的时候,每个对象都有一份属性。一个对象中的属性就是成员变量。
【格式】 (访问修饰符 type name = value)
【作用范围】 在类内部,任何地方都可以访问成员变量。
【生命周期】
出生:new对象的时候,开辟内存空间。
死亡:堆内存地址没有引用,变成垃圾,被垃圾回收器回收后。
1.2.3类变量 (静态属性)
被static修饰的属性。
【格式】 (访问修饰符 static type name = value)
【作用范围】 在类变量定义之后。
【生命周期】
出生:类加载时,类变量就分配内存空间。
死亡:JVM退出。
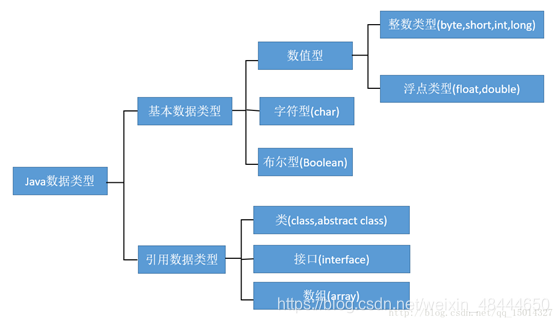
4、数据类型
1.释义
数据类型是为了把数据分成所需内存大小不同的数据,编程的时候需要用大的数 据才申请大内存,这样可以充分利用内存。
Java语言是一种强类型语言,要求所有变量先声明后使用。目的就是为了保证变量或者表达式在编译时就能够确定其类型,
并为其分配相应的内存。
2.分类
2.1整型
2.1.1 Java整型
byte/short/int/long
2.1.2整型取值范围
Java语言整数型默认为int类型,如果要声明成long类型在变量值后加入L,如:long l = 123L
| 类型 | 占用存储空间字节数 | 数值范围 |
|---|---|---|
| byte | 1 | -128~127 |
| short | 2 | -2的15次方2的15次方-1(-3276832767) |
| int | 4 | -2的31次方~2的31次方-1 |
| long | 8 | -2的63次方~2的63次方-1 |
2.1.3 Java整型常量的三种表示方法
十进制:如123=1*100+2*10+3*1=123
八进制,八进制0开头:如:013=1*8+3*1=11
十六进制,十六进制0x开头:如:0x23=2*16+3*1=35
【进制转换】
10进制到二进制
示例:求十进制数10的二进制
6/2=3 余 0
3/2=1 余 1
1/2=0 余 1
将余数逆序输出就是6的二进制表示:110,位数不够补零
二进制到十进制
示例:求二进制110的十进制
规则:取出最后一位,从2的0次方开始乘,将得到的结果相加即可
0*2的0次方=0
1*2的1次方=2
1*2的2次方=4
110的十进制为:0+2+4=6
八进制与二进制、十进制转换类同
2.2浮点型
2.2.1 Java浮点型
float/double
2.2.2两种表示形式
十进制形式:例如:123.456 0.314
科学计数法:例如:1.23456E2 3.14E-1
2.2.3 Java浮点型取值范围
浮点声明默认是double类型,若要是float,请在尾部添加f或是F。如:float myFloat=1.23
| 类型 | 占用存储空间字节数 | 数值范围 |
|---|---|---|
| float | 4 | -3.4E38 ~ 3.4E38 |
| double | 8 | -1.7E308~ 1.7E308 |
2.3布尔型
适用于逻辑运算,用于程序流程控制
只允许取值为true,false,不可以任何其它形式代替
[示例]
boolean real=true; //正确
boolean notReal=false; //正确
boolean read2=1; //错误
boolean notReal2=0; //错误
2.4字符型
2.4.1 Java字符型
通常意义上的字符,用单个引号括起来的单个字符
如'1','a','b'等等
Java采用Unicode编码(即为全球统一语言编码),均可以用十六进制表示编码值
char c = '\u0012';
转义字符,用’\n’来表示,即为转变之前的意义,但依然是个字符
char c='\n'; //表示换行符
3.基本类型转换
布尔类型不能与其它类型做任何转换
数值型、字符型可以相互转换,规则如下:
容量小的自动转换成表数范围容量大的,但byte,short,char不能相互转换,均转化成int做计算
容量大小排序为:byte,char,short<int<long<float<double
容量大转换为容量小的,要加强制转换符,此时容易丢失精度
多类型混合运算时,系统会自动转换成统一类型(大容量数据)后再进行计算,即先类型转换后计算
5、运算符与表达式
1.运算符
释义
用于表示数据的运算、赋值和比较的一系列符号我们称之为运算符。
分类
运算符按功能划分如下:
| 运算符类型 | 运算符 |
|---|---|
| 算术运算符 | +,-,*,/,++,–,% |
| 关系运算符 | <,<=,>,>=,==,!= |
| 布尔运算符 | &&, |
| 位运算符 | &, |
| 赋值类运算符 | =, +=, -=, *=, /=, %= |
| 字符串连接运算符 | + |
| 条件运算符(三目运算符) | ? : |
| 其他运算符 | instanceof,new |
1.1算术运算符
| 类型 | 描述 | 示例 |
|---|---|---|
| ++(自加运算符) | ++在变量前面时,先做运算后赋值++在变量后面时,先做赋值后运算 | i = 1, j; j = ++i; 则j=2;i = 1, j; j = i++; 则 j = 1 |
| –(自减运算符) | 同上 | i = 1, j; j = - -i; 则 j = 0;i = 1, j; j = i- -; 则 j = 1; |
1.2关系运算符
注意 ‘==’关系运算,其意义为全等,基本数据类型比较值,引用数据类型比较地址
1.3逻辑运算符
与 &:两个操作数相与,如果都为true,则为true
或 |:两个操作数相或,有一个为true,则为true
异或 ^:相异为true,两个操作数不一样就为true,相同为false
短路&& 和 逻辑& 区别?
1.短路与,从第一个操作数推断结果,只要有一个为fase,不再计算第二个操作数
2.逻辑与,两个操作数都计算
短路|| 和 逻辑| 区别?
1.短路或,从第一个操作数推断结果,只要有一个为true,不再计算第二个操作数
2.逻辑或,两个操作数都计算
1.4赋值运算符
注意
1)当 "=" 两侧数据类型不一致时,适用默认转换或强制转换处理,如long num=20;int i=(int)num;
2)特殊情况为:当byte,char,short被整赋值时,不需要进行强制类型转换,不超过取值范围即可。即一个自动装载的过程。
char c=100;byte b=20; //正确
char c2=-99999;byte b2=128; //类型越界错误
| 运算符 | 用法 | c |
|---|---|---|
| += | a+=b | a=a+b |
| -= | a-=b | a=a-b |
| *= | a*=b | a=a*b |
| /= | a/=b | a=a/b |
| %= | a%=b | a=a%b |
1.5字符串连接运算符
"+" 可用于数值计算,当有一方是字符时,则为将左右两个数据转化成字符串连在一起。如int i=10+20;String j="10"+"20"。
当" +" 任意一侧为字符串时,系统将自动将两侧转化成字符串,做字符串链接操作。
当进行System.out.println(var)打印操作的时候,均自动转化为字符串进行输出。
1.6运算优先级
| 优先级 | 运算符分类 | 结合顺序 | 运算符 |
|---|---|---|---|
| 由高到低 | 分隔符 | 左结合 | . [] ( ) ; , |
| 一元运算符 | 右结合 | ! ++ – - ~ | |
| 算术运算符 | 左结合 | * / % + - | |
| 移位运算符 | << >> >>> | ||
| 关系运算符 | 左结合 | < > <= >= instanceof == != | |
| 逻辑运算符 | 左结合 | ! && | |
| 三目运算符 | 右结合 | 布尔表达式?表达式1:表达式2 | |
| 赋值运算符 | 右结合 | = *= /= %= += -= <<= >>= >>>= &= *= |
【问】:做一道综合性强点的练习题,感受感受运算符优先级怎么样?
int a = 5;
int b = 4;
int c = a++ - --b * ++a / b-- >> 2 % a--;
c的值是多少?
2.表达式
表达式是指由(常量、变量、操作数)与运算符所组合而成的语句。
符合语法规则的运算符+操作数,即为表达式,如:5+3,2.0+3.0,a+b,3%2
表达式最终运行结果即为表达式的值,值的类型就是表达式的类型
运算符优先级,决定表达式的运算顺序
三目运算符:
形如:x?y:z
释义:计算x的值,若为true,则表达式的值为y;若为false,则表达式的值为z
6、流程控制结构
程序控制结构是指以某种顺序执行的一系列动作,用于解决某个问题。程序可以通过控制语句来对程序实现选择、循环、转向和返回等流程控制。
程序控制结构包括:顺序结构、分支结构、循环结构。
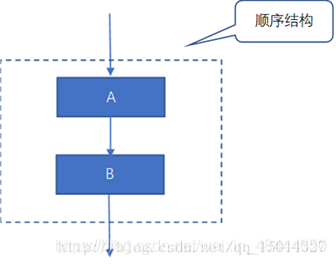
1. 顺序结构
顺序结构程序就是按语句出现的先后顺序执行的程序结构。计算机按顺序逐条执行语句,当一条语句执行完毕,
自动转到下一条语句。
如图:
示例:
int a = 11; //第一步
int b = 2; //第二步
int c = a+b; //第三步
System.out.println(“a+b的结果为:”+c); //第四步
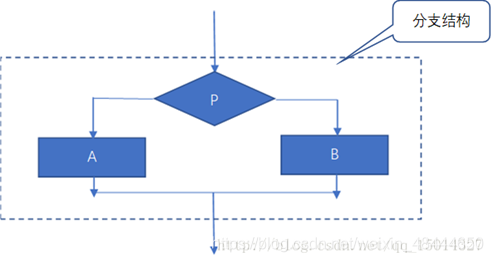
2. 分支结构
1)分支结构又称为选择结构。当程序执行到控制分支语句时,首先判断条件,根据条件表达式的值选择相应的语句执行(放弃另一部分语句的执行)。
2)分支结构包括单分支、双分支和多分支三种形式。
如图:
2.1单分支
【语法格式】
if(布尔表达式){语句块;}
说明:当语句块为一条语句时,大括号可以省略。只有布尔表达式为true时,才进入if语句中。
【示例】
int age = 20;
if(age >= 18){
System.out.println("成年人");
}
2.2双分支
【语法格式】
if(布尔表达式){
语句块;//if分支
}else{
语句块;//else分支
}
【示例】
int age = 20;
if(age >= 18){
System.out.println("成年人");
}else{
System.out.println("未成年人");
}
2.3多分支-1
【语法格式】
if(布尔表达式){
语句块;
}else if(布尔表达式){
语句块;
}else{
语句块;
}
【示例】
int age = 20;
if(age >0 && age <=18){
System.out.println("未成年");
}else if(age > 18 && age <=40) {
System.out.println("青年");
}else if(age > 40&& age<=50) {
System.out.println("中年");
}else if(age > 50) {
System.out.println("老年");
}else{
System.out.println("见鬼了");
}
2.4多分支-2
【语法格式】
switch (表达式) {
case 值1:
语句;
break;
case 值2:
语句;
break;
default:
语句;
break;
}
说明:
表达式的值只能为:char、byte、short、int类型、String、enum类型,其它类型均非法
break语句可以省略,但会出现switch穿透
default语句也可以省略,一般不建议省略,并且放置在最后
【示例】
public static void main(String[] args) {
String type = "dog";
switch(type) {
case "cat":
System.out.println("喵");
break;//注意break
case "dog":
System.out.println("旺");
break;
case "sheep":
System.out.println("咩");
break;
default:
System.out.println("哇!");
}
System.out.println("switch执行结束!");
}
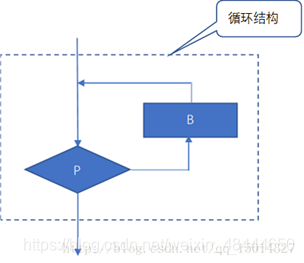
3. 循环结构
当程序执行到循环控制语句时,根据循环判定条件对一组语句重复执行多次。
循环结构的三个要素:循环变量、循环体和循环终止条件。
while、do…while、for三种循环。
如图:
3.1 while语句
【语法格式】
while(布尔表达式){
循环体; //一条或多条语句
}
【示例】
int i = 1;
while(i<=5) {
System.out.println(i);
i++;
}
3.2 do…while语句
【语法格式】
do {
循环体;
}while(条件判断表达式);
【示例】
int i = 1;
do{
System.out.println(i);
i++;
}while(i<=0); //注意分号
3.3 for语句
【语法格式】
for(表达式1;表达式2;表达式3) {
循环体; //一条或多条语句
}
【示例】
for (int i=1; i<=5; i++) {
System.out.println(i);
}
3.4 break语句
强制退出某个循环体,结束循环语句的执行
【示例】
public static void main(String[] args) {
for(int i=1; i<=10; i++) {
System.out.println(i);
if(i == 5){
break; //会跳出当前循环
}
}
//break跳到这里
}
3.5 continue语句
终止某次循环过程,跳过continue语下方未执行的代码,开始下一步循环过程
【示例】
public static void main(String[] args) {
for (int i=1; i<=10; i++) {
if (i == 5) {
continue; //会跳该次循环,跳到i++代码处
}
System.out.println(i);
}
}
3.6 流程控制语句总结
条件判断语句:if语句、switch语句。
循环执行语句:do while语句、while语句、for语句。
跳转语句:break语句、continue语句、return语句。
| 控制语句类型 | 关键字 | 作用 |
|---|---|---|
| 选择结构语句 | if、if else、else if、switch | 通过开关机制,选择要执行的代码 |
| 循环结构语句 | for、while、do while | 通过循序机制,反复执行相同的代码段 |
| 改变语句执行序 | break、continue | 通过打断或继续机制,改变当前工码的执行顺序 |
三种循环结构的异同点:
用while和do…while循环时,循环变量在循环体之前初始化,而for循环一般在语句1进行初始化。
while 循环和for循环都是先判断表达式,后执行循环体;而do…while循环是先执行循环体后判断表达式。
也就是说do…while的循环体最少被执行一次,而while循环和for就可能一次都不执行。
这三种循环都可以用break语句跳出循环,用continue语句结束本次循环。
7、方发初识
1.释义
方法是组合在一起来执行操作语句的集合。
2.方法作用
1) 使程序变得更简短更清晰
2) 有利于程序维护
3) 提高程序开发效率
4) 提高代码重用性
3.方法创建与使用
【语法格式】
访问修饰符 返回值类型 方法名(参数列表){
方法体 ;
}
【方法分类】
根据方法是否带参、是否带返回值,可将方法分为四类
1) 无参无返回值方法
2) 无参带返回值方法
3) 带参无返回值方法
4) 带参带返回值方法
3.1无参无返回值方法
public void print(){
System.out.println("大家好,我是我是papi酱");
System.out.println("一个集美貌和才华与一身的女子");
}
3.2无参带返回值方法
public int callForYou(){
System.out.println("老铁,双击666!");
return 666;
}
3.3带参无返回值方法
public void printResult(int a, int b){
int c = a + b;
System.out.println("我只是打印结果而已,两数相加结果:"+c);
}
3.4带参带返回值方法
public String ifAdult(int age){
if(age >= 18){
return "成年人";
}else{
return "未成年人";
}
}
3.5递归方法
释义
程序自身调用自身的编程技巧称为递归
递归四个特性
1.必须有可最终达到的终止条件,否则程序将陷入无穷循环;
2.子问题在规模上比原问题小,或更接近终止条件;
3.子问题可通过再次递归调用求解或因满足终止条件而直接求解;
4.子问题的解应能组合为整个问题的解。
技巧
找到递归实现的递归部分和终止部分
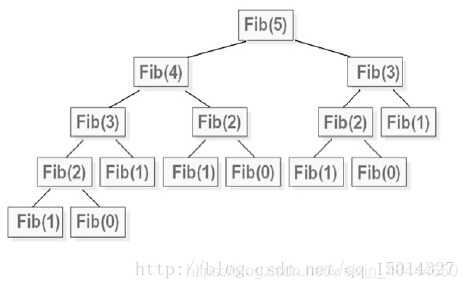
斐波那契数列
Fibonacci: 1 , 1 , 2 , 3 , 5 , 8 , 13 , 21 ... ...
终止部分:F1=1,F2=1;
递归部分为:F(n)=F(n-1)+F(n-2),其中n>2
图解斐波那契递归过程
Fibonacci递归实现代码
public class Test {
public static long fibonacci(int n) {
if(n==0||n==1) return 1;
else {
return fibonacci(n-1)+fibonacci(n-2);
}
}
public static void main(String[] args) {
for(int i=0;i<10;i++) {
long num = fibonacci(i);
System.out.print(num+" ");
}
}
}
三、数组
1.数组
释义
数组是在程序设计中,为了处理方便, 把具有相同类型的若干元素按无序的形式组织起来的一种形式。这些无序排列的同类数据元素的集合称为数组。
数组有一维数组和多维数组。
2. 一维数组
1. 一维数组介绍
把int类型的四个数字1,2,3,4组织起来。
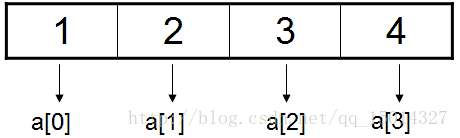
一维数组声明
两种声明格式
元素类型[] 变量名称 示例:int[] intArray;
元素类型 变量名称[] 示例:int intArray[];
一行中允许声明多个数组
int[] array1,array2,array3;
一维数组初始化
数组初始化的过程就是为数据分配内存空间的过程。
静态初始化
声明数组时,对数组初始化,数组的大小会根据初始值的个数确定长度。
【示例】
public static void main(String[] args)
{
String[] nameArray={"one","two","three"};
for(int i=0;i<nameArray.length;i++){
System.out.println(nameArray[i]);
}
}
动态初始化
声明数组时,指定数组的长度即可。
【示例】
public static void main(String[] args)
{
int[] girlFriendArray=new int[10];
for(int i=0;i<10;i++){
girlFriendArray[i]=i;
}
for(int i=0;i<10;i++){
System.out.println(girlFriendArray[i]);
}
}
2. 一维数组的使用
2.1长度属性:length
int arr = new int[5]; //数组arr的长度属性,即arr.length=5
2.2下标访问数组元素
int arr = {12,23,5,34,7};
System.out.println("取出arr的第一个元素的值:"+arr[0]);
2.3数组遍历
下标循环
for(int 下标变量值=0;下标变量值<遍历对象的长度值;下标变量值++){
循环体
}
【示例】
int[] arr = new int[5];
for(int i=0;i<arr.length;i++){
循环体
}
增强循环
for(元素类型t 元素变量x : 遍历对象obj){
语句;
}
【示例】
int[] arr = {2,5,8,12,51};
for(int i : arr){
循环体
}
3. 二维数组
1. 二维数组介绍
二维数组本质上是以数组作为数组元素的数组,即“数组的数组”。
int[][] a = {{1,3,5,7},{9,11,13,15},{17,19,21,23}};
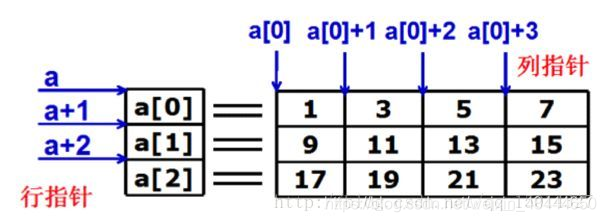
2. 二维数组的声明
【语法格式】
类型说明符 数组名[常量表达式][常量表达式]
【常见二维数组声明问题】
二维数组的声明和初始化,严格按从高维到低维的顺序进行
int tempArray[][]=new int[][3]; //错误
int tempArray[][]=new int[3][]; //正确
int tempArray[][]=new int[3][4]; //正确
3.二维数组的使用
静态初始化
public static void main(String[] args)
{
int[][] myArr={{1,2},{3,4},{5,6}};
}
动态初始化
public static void main(String[] args)
{
int[][] myArr=new int[10][10];
for(int i=0;i<10;i++){
for(int j=0;j<10;j++){
myArr[i][j] = (i+1)*j;
}
}
}
4. 数组总结
数组是一种引用数据类型
数组是一组类型相同的数据集合
数组元素的类型可以是基本类型或引用类型,但所有元素类型要一致
数组长度固定
数组元素可通过下标访问,下标从0开始
5. 数组排序
1. 自己写算法排序
(1) 冒泡排序
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有
再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢 “浮”到数列的顶端,
故名 “冒泡”。
【算法原理】
冒泡排序算法的运作如下:(从后往前)
1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3. 针对所有的元素重复以上的步骤,除了最后一个。
4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
【算法描述】
public static void bubbleSort(int[] arr)
{
int temp = 0;
int size = arr.length;
for(int i = 0 ; i < size-1; i ++)
{
for(int j = 0 ;j < size-1-i ; j++)
{
if(arr[j] > arr[j+1]) //交换两数位置
{
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
(2)选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
【算法思想】
1. 在未排序序列中找到最小元素,存放到排序序列的起始位置
2. 再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。
3. 以此类推,直到所有元素均排序完毕。
【算法描述】
public static void selectSort(int[] numbers)
{
int size = numbers.length; //数组长度
int temp = 0 ; //中间变量
for(int i = 0 ; i < size ; i++)
{
int k = i; //待确定的位置
//选择出应该在第i个位置的数
for(int j = size -1 ; j > i ; j--)
{
if(numbers[j] < numbers[k])
{
k = j;
}
}
//交换两个数
temp = numbers[i];
numbers[i] = numbers[k];
numbers[k] = temp;
}
}
2. 调用API排序方法
int[] arr = {7,9,4,8,3,5};
Arrays.sort(arr);
6. 数组元素查找
(1). 顺序查找
顺序查找是在一个已知无(或有序)序队列中找出与给定关键字相同的数的具体位置。
【算法原理】
让关键字与队列中的数从最后一个开始逐个比较,直到找出与给定关键字相同的数为止。
【算法描述】
public static int ordersearch(int[] arry,int des){
int i=0;
for(;i<=arry.length-1;i++){
if(des==arry[i])
return i;
}
return -1;
}
(2). 二分查找
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好,占用系统内存较少;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
【算法原理】
假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;
否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,
否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
【算法要求】
1)必须采用顺序存储结构。
2)必须按关键字大小有序排列。
【算法描述】
public static int binarySearch(Integer[] srcArray, int des) {
//定义初始最小、最大索引
int low = 0;
int high = srcArray.length - 1;
//确保不会出现重复查找,越界
while (low <= high) {
//计算出中间索引值
int middle = (high + low)/2 ;//防止溢出
if (des == srcArray[middle]) {
return middle;
//判断下限
} else if (des < srcArray[middle]) {
high = middle - 1;
//判断上限
} else {
low = middle + 1;
}
}
//若没有,则返回-1
return -1;
}
四、面向对象
1. 面向对象介绍
1. 面向过程与面向对象
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;
面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
2. 类和对象
Java是面向对象的程序设计语言,类是面向对象的重要内容,我们可以把类当成一种自定义数据类型,可以使用类来定义变量,这种类型的变量称为引用型变量。也就是说,所有类是引用数据类型。
2.1概念
面向对象的程序设计中有两个重要概念:类和对象。其中类是某一类对象的抽象。对象才是一个具体的实体。如:有一条狗叫”花花”,那么这条真实存在的狗才是对象,而”狗”是类,代表一类”花花”这样的实体。
抽象的重要性
抽象是继承和多态的基础。在抽象的过程中,我们获得是事物本质的东西和事物独特的东西,这样我们很自然的认识到抽象的事物和具体的事物之间是一种继承的关系,而他们之间的不同性可以通过多态来表现出来。
2.2定义类
2.2.1语法格式
[权限控制符] class 类名 {
//零个到多个构造器 * 构造器定义 * 注意:构造器无返回值类型
[权限控制符] 类名(参数列表){};
//零个到多个属性 * 属性定义
[权限控制符] [static | final] 属性类型 属性名;
//零个到多个方法 * 方法定义
[权限控制符] [abstract | final] [static] 返回值类型 方法名(参数表){};
}
提示:定义类的时候,不是必须显式写构造方法、属性、方法。
【示例】
定义一个学生类
属性:学号、姓名、年龄、班级
方法:学习、唱歌
public class Student{
public Student(){
//....
}
public Student(String name,int age){
this.name = name;
this.age = age;
}
public String name;
public int age;
//.....
public void study(){
System.out.println(“爱学习”);
}
public void sing(){
//唱歌
System.out.println(“爱唱歌”);
}
}
2.2.2对象的创建和使用
1)对象创建语法格式
类名 对象名 = new 类名();
示例
Student s = new Student();
2)操作对象的属性和方法
【语法格式】
使用类的属性: 对象名.属性
实用类的方法: 对象名.方法名()
以上面学生类Student为例:
Student s = new Student();
s.age = 18; //为属性age赋值为18
s.sing(); //调用sing方法
Student s = new Student(“小明”,18);
System.out.println(s.age);
2.3构造方法
构造方法是一种特殊的方法,它是一个与类同名且没有返回值类型的方法。对象的创建就是通过构造方法来完成,其功能主要是完成对象的初始化。当类实例化一个对象时会自动调用构造方法。构造方法和其他方法一样也可以重载。
特殊性
1)构造方法作用:构造出来一个类的实例,对构造出来的类的对象初始化。
2)构造方法的名字必须与定义他的类名完全相同,没有返回类型,甚至连void也没有。
3)系统会默认为类定义一个无参构造方法,即默认构造方法。若显式定义了构造方法,则系统不会提供默认无参构造函数。
示例
public class Constructor_01 {
int age;
public static void main(String[] args) {
Constructor_01 c = new Constructor_01(12);
System.out.println(c.age);
}
//有参构造方法
public Constructor_01(int i) {
age = i;
}
//无参构造方法
public Constructor_01() {
age = 18;
}
}
思考
我们可以定义两个名称一样的属性么?不可以。那么两个方法的名称一样呢?这里的两个构造方法名称相同了,但是没有报错,
为什么呢?这就是方法重载。
2.4方法重载
特点
1)方法名一定要相同
2)参数列表不同——参数类型、参数个数
3)与方法的访问控制符和返回值无关
2.5对象的引用与this
引用
Student s = new Student(“张三”);
上面的对象名s即为对象的引用,而 new Student(“张三”)才是张三对象。
this
总要有个事物来代表类的当前对象,就像C++中的this指针一样,Java中的this关键字就是代表当前对象的引用。
图例
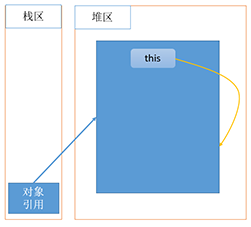
它有三个主要的作用
1)在构造方法中调用其他构造方法
比如:有一个Student类,有三个构造函数,某一个构造函数中调用另外构造函数,就要用到this(),而不可以直接使用Student()。
2)返回当前对象的引用
3)区分成员变量名和参数名
2.6 static
static关键字的用途
被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访问。
static方法
static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说:
1. static是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。
2. 在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。
3. 虽然在静态方法中不能访问非静态成员方法和非静态成员变量,但是在非静态成员方法中是可以访问静态成员方法/变量的。
static变量
static变量也称作静态变量,静态变量和非静态变量的区别是:
1. 静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。
2. 非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
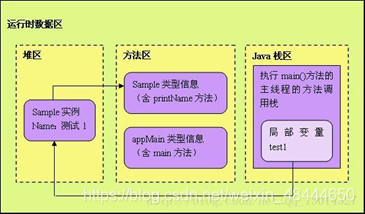
二. JVM内存分析——案例
内存分配图
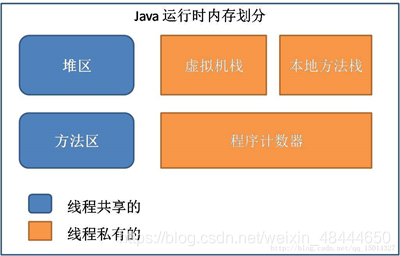
JAVA的JVM的内存可分为3个区:堆(heap)、栈(stack)和方法区(method)
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身。
3.一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中。
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
4.由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。
静态区/方法区:
1.方法区又叫静态区,跟堆一样,被所有的线程共享。方法区包含所有的class和static变量。
2.方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
3.全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。
举例
Sample test1=new Sample(“测试1”);
3. 封装
1. 概念
什么是封装
封装是把对象的所有组成部分组合在一起,封装使用访问控制符将类的数据隐藏起来,控制用户对类的修改和访问数据的程度。
作用
适当的封装可以让代码更容易理解和维护,也加强了代码的安全性。
2. 访问控制符
访问控制符用来控制父类、子类间,不同包中的类间数据和方法的访问权限。
包括private、protected、public和默认四中类型。其访问权限如下:
| 访问控制符 | 同一类中 | 同一包中 | 同一子类中 | 其他 |
|---|---|---|---|---|
| private | 是 | 否 | 否 | 否 |
| default | 是 | 是 | 否 | 否 |
| protected | 是 | 是 | 是 | 否 |
| public | 是 | 是 | 是 | 是 |
4. 继承
1. 概念
继承是从已有的类中派生出新的类,新的类能吸收已有类的属性和行为,并能扩展新的属性和行为。
1.1 Java继承特点
1) Java是单继承的,不支持多继承。这样使得Java的继承关系很简单,一个类只能有一个父类,易于管理程序。同时一个类可以实现多个接口,从而克服单继承的缺点。
2) 继承关系是传递的
3) private修饰的成员变量或方法是不能被继承的
1.2解决什么问题
提高了代码的效率,避免了代码重写。
2. 语法格式
[修饰符] class 子类 extends 父类 {
//类体
}
【示例】
实现一个继承,定义学生类为父类,定义一个大学生类作为子类。
//父类
public class Student {
}
//子类
class BStudent extends Student{
}
3. super
this是指当前对象引用,super是指当前对象的父类对象的引用。由于继承子类可以访问父类的成员,所以this除了可以访问自己的成员还可以访问父类的成员,但是为了明确的指明访问的是父类的成员,则要用关键字super来指定。
【示例】
public class Super_01 extends A{
Super_01() {
//不写,默认会有super()调用父类无参构造
super();
System.out.println("子类构造方法");
}
int i = 2;
public static void main(String[] args) {
Super_01 s = new Super_01();
s.m1();
}
public void m1(){
//子类
System.out.println(i);
//父类
System.out.println(super.i);
//子类
System.out.println(this.i);
}
}
class A{
A(){
super();
System.out.println("父类构造方法");
}
int i = 10;
}
4. final
final表示不可改变的含义
采用final修饰的类不能被继承
采用final修饰的方法不能被重写
采用final修饰的变量不能被修改
final修饰的变量必须显式初始化 如果修饰的引用,那么这个引用只能指向一个对象,该引用不能再次赋值,但对象本身内部可以修改
构造方法不能被final修饰
5. 方法重写
在Java中,子类可继承父类中的方法,而不需要重新编写相同的方法。但有时子类并不想原封不动地继承父类的方法,而是想作一定的修改,这就需要采用方法的重写。
方法重写的特性
1)发生方法重写的两个方法返回值、方法名、参数列表必须完全一致(子类重写父类的方法)
2)子类抛出的异常下不能超过父类相应方法抛出的异常(子类异常不能大于父类异常)
3)子类方法的访问级别不能低于父类相应方法的访问级别(子类访问级别不能低于父类访问级别)
【示例】
public class Override_01 {
public static void main(String[] args) {
Cat cat = new Cat();
cat.move();
System.out.println(cat.i);
Animal a = new Animal();
a.move();
//多态
Animal ac = new Cat();
ac.move();
System.out.println(ac.i);
}
}
class Animal{
int i = 10;
public void move(){
System.out.println("动物在移动");
}
}
class Cat extends Animal{
int i = 20;
@Override
public void move() {
// super.move();
System.out.println("猫在走猫步");
}
}
6. 父子对象间转换和instanceof
父类和子类拥有公共的属性和方法,那么能否通过父类来访问子类中的继承的公共的属性和方法呢?
我们在上面了解到,如果在子类内部肯定可以,而且通过this和super关键字可以轻松的使用。 那么如果在类的外部怎么实现这个应用需求呢?Java提供了类对象间的转换来满足这个需求。 我们回顾一下之前的基本数据类型强制转换,父类和子类之间的转换与其类似。
隐式转换:小类转大类,也叫为向上转
强制转换:大类转小类,也为向下转,需要有 “()”作为强制转换。
如:Student student = new DaXueSheng();//隐式转换
DaXueShen daXueShen= (DaXueSheng)student;//强制转换
【总结】
* 子类对象可以被视为其父类的一个对象,如一个大学生(子类)肯定是一个学生(父类)。
* 父类对象不能被声明为某一个子类的对象,如一个学生不能完全表示一个大学生。
* 父类引用可以指向子类对象,但不能访问子类对象新增的属性和方法。
instanceof运算符
Java提供了instanceof关键字,使我们在强制转换之前,判断前一个对象是否后一个对象的实例,是否可以成功的转换,以增强代码的健壮性。
5. 多态
1. 概念
多态性
多态指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
示例
public class Poly_01 {
public static void main(String[] args) {
Sup sup =new Sub();
sup.m1();
System.out.println(sup.i);
// System.out.println(sup.a);
}
}
//父类
class Sup{
int i = 10;
public void m1(){
System.out.println("父类成员方法");
}
}
//子类
class Sub extends Sup{
int i = 20;
int a = 1;
public void m1(){
System.out.println("子类成员方法");
}
}
必要条件
继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重写,在调用这些方法时就会调用子类的方法。
向上转型:在多态中需要父类的引用指向子类的对象。
2. 体现方式
使用父类作为方法形参实现多态。 使用父类作为方法返回值实现多态 。
3. 好处
把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,写出通用的代码,做出通用的编程,以适应需求的不断变化。
//不使用多态,本来想拥有一条狗,后来想拥有一只猫,就需要改代码了
public class Person{
//Dog d;
Cat c;
//public void setAnimal(Dog d){
// this.d = d;
//}
public void setAnimal(Cat c){
this.c = c;
}
public static void main(String[] args) {
Person p = new Person();
//p.setAnimal(new Dog());
p.setAnimal(new Cat());
}
}
//使用多态,本来想拥有一条狗,后来想拥有一只猫,只需重新设置
public class Person{
Animal a;
public void setAnimal(Animal a){
this.a = a;
}
public static void main(String[] args) {
Person p = new Person();
//p.setAnimal(new Dog());
p.setAnimal(new Cat());
}
}
//动物类及其子类
class Animal{
}
class Dog extends Animal{
}
class Cat extends Animal{
}
6. 抽象类与接口
1. 抽象类
1.1概念
抽象类往往用来表示设计中得出的抽象概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。
比如:动物,它只是一个抽象的概念,并没有一个 “东西”叫做 “动物”。所以,它并不能代表一个实体,这种情况下,我们就适合把它定义成抽象类。
1.2语法格式
修饰符 abstract class 类名(){
//……
abstract 方法名();
}
abstract修饰:它修饰类就是抽象类,修饰方法就是抽象方法
含有抽象方法的类,必须是抽象类;抽象类必须被继承,抽象方法必须得重写
抽象方法只需声明,不需写具体实现
抽象类不能被实例化,即不能被new操作 abstract不能与final并列修饰同一类
abstract不能与private,static,final并列修饰同一方法 abstract方法必须位于abstract类中
【示例】
public class Abstract_01 {
public static void main(String[] args) {
// A a = new A();
A c= new C();
c.move();
m1();
m2();
A a = null;
a.delete();
a.add();
}
public static void m1() {
}
public static void m2() {
// TODO Auto-generated method stub
}
}
abstract class A{
public void eat(){
System.out.println("这是一个抽象类");
}
//抽象方法
public abstract void move();
public abstract void add();
public abstract void load();
public abstract void delete();
A(){
System.out.println("A的构造方法");
}
}
abstract class B extends A{
}
class C extends A{
@Override
public void move() {
System.out.println("着火了,快跑");
}
@Override
public void add() {
// TODO Auto-generated method stub
}
@Override
public void load() {
// TODO Auto-generated method stub
}
@Override
public void delete() {
// TODO Auto-generated method stub
}
}
2.接口
2.1概念
Java接口是一些方法声明的集合,一个接口只有方法的声明没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为。
作用
1)Java是一种单继承的语言
2)实现多态
2.2语法格式
定义接口
[访问控制符] interface <接口名>{
类型标识符final 符号常量名n = 常数;
返回值类型 方法名([参数列表]);
…
}
实现接口
[访问控制符] class 类名 [implements <interface>[,<interface>]*],]
{
//类体,必须实现接口中的方法
}
特性
我们可以把接口看作是抽象类的一种特殊情况,在接口中只能定义抽象的方法和常量
接口不可实例化,可结合多态进行使用(接口 对象=new 对象())
接口里的成员属性全部是以 public(公开)、static(静态)、final(最终) 修饰符修饰
接口里的成员方法全部是以 public(公开)、abstract(抽象) 修饰符修饰
接口里不能包含普通方法
子类继承接口必须实现接口里的所有成员方法,除非子类也是抽象类
【示例】
public class Interface_01 {
public static void main(String[] args) {
System.out.println(A.i);
A.m1();
E e = new E();
e.m3();
}
}
interface A{
//都是静态常量
public static final String SUCCESS = "SUCCESS";
int i = 2;
byte MAX_VALUE = 127;
public static void m1(){
System.out.println("----");
}
public default void m3(){
System.out.println("----");
}
public abstract void m2();
}
interface B{
void m4();
}
//多继承
interface C extends A,B{
void m5();
}
//抽象类实现0~N个抽象方法
abstract class D implements A,B{
}
class E implements C{
@Override
public void m2() {
// TODO Auto-generated method stub
}
@Override
public void m4() {
// TODO Auto-generated method stub
}
@Override
public void m5() {
// TODO Auto-generated method stub
}
}
3.抽象类与接口的对比
普通类 抽象类 接口
代表一类实体,可以被实例化 代表一类实体,但不能被实例化 不能代表一类实体,只能代表功能或是属性
单继承 单继承 多实现
已经很具体,没有再抽象的需要 在多个普通类中有共用的方法或属性又有相同方法的不同实现方式
单纯的规范,单纯的功能或属性需要独立体现出来
举个例子
有四个方法:吃饭,穿衣,跑步,开豪车; 吃饭,穿衣,跑步这三件事情,普通人都做得到,可以说是
“共性”的行为,只是具体行为实现不同;开豪车不是普通人可以做到的,比较 “独特”。
吃饭,穿衣,跑步三个行为适合放在抽象类,开豪车适合放在接口。
7. Object类
Object类是所有Java类的祖先,每个类都使用Object作为超类。
所有对象(包括数组)都实现这个类的方法。
在不明确给出超类的情况下,Java会自动把Object作为要定义类的超类。
可以使用类型为Object的变量指向任意类型的对象。
重点:toString()、equals()、hashCode()三个方法。
问:toString() 方法实现了什么功能?
答:toString() 方法将根据调用它的对象返回其对象的字符串形式。
问:当 toString() 方法没有被覆盖的时候,返回的字符串通常是什么样子的?
答:当 toString() 没有被覆盖的时候,返回的字符串格式是 类名@哈希值,哈希值是十六进制的。
举例说,假设有一个 Employee 类,toString() 方法返回的结果可能是 Empoyee@1c7b0f4d。
问:euqals()函数是用来做什么的?
答:用来检查一个对象与调用这个equals()的对象是否相等。
问:使用Object类的equals()方法可以用来做什么比较?
答:调用它的对象和传入的对象的引用是否相等。也就是说,默认的equals()进行的是引用比较。
如果两个引用是相同的,equals()函数返回true;否则,返回false。
问:hashCode()方法是用来做什么的?
答:hashCode()方法返回给调用者此对象的哈希码(其值由一个hash函数计算得来)。
这个方法通常用在基于hash的集合类中,像HashMap,HashSet和Hashtable。
问: 在类中覆盖equals()的时候,为什么要同时覆盖hashCode()?
答: 在覆盖equals()的时候同时覆盖hashCode()可以保证对象的功能兼容于hash集合。
这是一个好习惯,即使这些对象不会被存储在hash集合中。
8. 设计模式
单例模式(懒汉模式、饿汉模式)、工厂模式
懒汉模式:用到的时候再创建对象,并且只创建一次
我们一般使用懒汉模式
[示例]
public class Singleton_01 {
//1 私有化构造
private Singleton_01(){
}
//保存当前对象的变量
private static Singleton_01 s = null;
//用于获取对象的方法
public static Singleton_01 getInstance(){
//如果为null说明没有对象,就创建一个
//如果不能为null 说明有对象,就直接返回
if (s == null) {
s = new Singleton_01();
}
return s;
}
}
饿汉模式:类加载阶段就初始化对象
[示例]
public class Singleton_02 {
//1 私有化构造
private Singleton_02(){
}
//保存当前对象的变量
private static Singleton_02 s = new Singleton_02();
//用于获取对象的方法
public static Singleton_02 getInstance(){
return s;
}
}
五、异常
1. 概念
异常是Java中提供的一种识别及响应错误情况的一致性机制。有效地异常处理能使程序更加健壮、易于调试。
异常发生的原因有很多,比如:
1) 用户输入了非法数据
2) 要打开的文件不存在
3) 网络通信时连接中断
4) JVM内存溢出
5) 这些异常有的是因为用户错误引起,有的是程序错误引起的,还有其它一些是因为物理错误引起的。
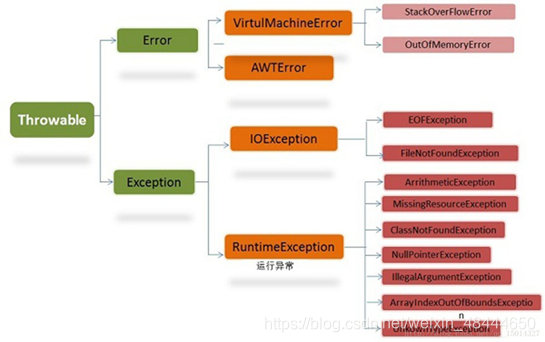
2. 系统异常分类
3. Error
1. 概念
系统内部错误,这类错误由系统进行处理,程序本身无需捕获处理。
比如:OOM(内存溢出错误)、VirtualMachineError(虚拟机错误)、StackOverflowError(堆栈溢出错误)等,一般发生这种情况,JVM会选择终止程序。
2. 示例
//堆栈溢出错误
public class TestError {
public static void recursionMethod() {
recursionMethod();// 无限递归下去
}
public static void main(String[] args) {
recursionMethod();
}
}
报错信息:
Exception in thread “main” java.lang.StackOverflowError
at com.TestError.recursionMethod(TestError.java:5)
at com.TestError.recursionMethod(TestError.java:5)
at com.TestError.recursionMethod(TestError.java:5)
at com.TestError.recursionMethod(TestError.java:5)
at com.TestError.recursionMethod(TestError.java:5)
at com.TestError.recursionMethod(TestError.java:5)
… …
4. Exception
1. 介绍
Exception是所有异常类的父类。分为非RuntimeException和RuntimeException 。
非RuntimeException
指程序编译时需要捕获或处理的异常,如IOException、自定义异常等。属于checked异常。
RuntimeException
指程序编译时不需要捕获或处理的异常,如:NullPointerException等。属于unchecked异常。
一般是由程序员粗心导致的。如空指针异常、数组越界、类型转换异常等。
2. 示例
//空指针异常
public class TestException {
private static int[] arr;
public static void main(String[] args) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
报错信息:
Exception in thread “main” java.lang.NullPointerException
at com.TestException.main(TestException.java:7)
3. 常用方法
Exception类和其他普通类一样,有自己的属性和方法,为我们提供异常的相关信息。常用的方法有:
| 方法 | 说明 |
|---|---|
| public String getMessage() | 返回关于发生的异常的详细信息。这个消息在Throwable类的构造函数中初始化了。 |
| public void printStackTrace() | 打印toString()结果和栈层次到System.err,即错误输出流。 |
【示例】
public class TestException {
public static void main(String[] args) {
Exception exp = new Exception("异常方法演示");
//打印异常信息
System.out.println("exp.getMessage()=" + exp.getMessage());
//跟踪异常栈信息
exp.printStackTrace();
}
}
4. 异常捕获与处理
程序在执行时如果发生异常,会自动的生成一个异常类对象,并提交给JAVA运行环境,这个过程称为抛出异常。程序也可以自行抛出异常。
当出JAVA运行环境接收到异常对象时,会寻找能处理这个异常的代码并按程序进行相关处理,这个过程称为捕获异常。
4.1 throws
【语法格式】
修饰符 返回类型 方法名(参数列表) throws 异常类名列表
【示例】
public class TestException {
public static void main(String[] args) throws FileNotFoundException{
File file = new File("our.txt");
InputStream input = new FileInputStream(file);
}
}
【注意】
子类继承父类,并重写父类的方法时,若方法中抛出异常,则要求:子类方法抛出异常只能是父类方法抛出的异常的同类或子类。
4.2 throw
throw的作用是抛出异常,抛出一个异常类的实例化对象。
【语法格式】
throw new XXXException();
【示例】
public class ExceptionDemo {
public static void main(String[] args) throws Exception {
Exception exp = new Exception("异常方法演示");
throw exp;
}
}
【总结】
这种抛出异常的方式一般在满足某条件时主动抛出,即满足用户定义的逻辑错误发生时执行。
含有throw语句的方法,或者调用其他类的有异常抛出的方法时,必须在定义方法时,在方法头中增加throws异常类名列表。
使用throws关键字声明的方法表示此方法不处理异常,而交给方法调用处进行处理。
4.3 try…catch
【语法格式】
try{
有潜在异常抛出的语句组
}catch(异常类名 异常形参){
异常处理语句组
}catch(异常类名 异常形参){
异常处理语句组
}catch(异常类名 异常形参){
异常处理语句组
}catch(异常类名 异常形参){
异常处理语句组
}finally{
语句组
}
其中:
1. try用来捕获语句组中的异常
2. catch用来处理异常可以有一个或多个,而且至少要有一个catch语句或finally语句
3. finally中的语句组无论是否有异常都会执行
常用捕捉异常方式
1. try…catch try…finally
2. try…catch…finally
3. try…catch1…catch2…finally(体现异常出现的大小顺序)
说明:多重catch处理异常,大异常类在后,小异常类在前。
5. 自定义异常
系统定义的异常主要用来处理系统可以预见的常见运行错误,对于某个应用所特有的运行错误,需要编程人员根据特殊逻辑来创建自己的异常类。
【语法格式】
public class 自定义异常类名 extends Exception{ … }
六、常用类
1. 基本类型包装类
【问】想要对基本类型数据进行更多的操作,怎么办?
【答】最方便的方式就是将其封装成对象。因为在对象描述中就可以定义更多的属性和行为对该基本数据类型进行操作。
我们不需要自己去对基本类型进行封装,JDK已经为我们封装好了。
【概念】
- 装箱就是自动将基本数据类型转换为包装器类型
- 拆箱就是自动将包装器类型转换为基本数据类型
| 基本类型 | 封装类型 |
|---|---|
| byte | Byte |
| char | Character |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
以Integer为例
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | public Integer(int value)public Integer(String s) | |
| 常用属性 | static int MAX_VALUE static int MIN_VALUE | 返回int类型的最大值返回int类型的最小值 |
| 常用方法 | (基本类型之间转换) byte byteValue()int intValue()… … | Integer类型转byte类型Integer类型转int类型… … |
| 常用方法 | (基本类型、字符串转换) static int parseInt(String s)static Integer valueOf(String s) | 字符串类型转int类型字符串类型转Integer类型 |
【示例】
public class TestInteger {
public static void main(String[] args) {
// 属性值
System.out.println("Integer类型最大值:" + Integer.MAX_VALUE);
System.out.println("Integer类型最小值:" + Integer.MIN_VALUE);
// 构造方法
Integer int1 = new Integer(123);
Integer int2 = new Integer("123");
System.out.println("构造方法传int参数:" + int1);
System.out.println("构造方法传String参数:" + int2);
// 类型转换
// 基本类型之间转换
System.out.println("Integer转byte类型:" + int1.byteValue());
System.out.println("Integer转int类型:" + int1.intValue());
// 基本类型与字符串之间转换
System.out.println("字符串123转成int:" + Integer.parseInt("123"));
System.out.println("字符串123转成Integer:" + Integer.valueOf("123"));
// System.out.println("字符串abc可以转成Integer类型吗?" + Integer.valueOf("abc"));
}
}
2. 字符串类
字符串类主要包括String、StringBuilder、StringBuffer。
1. String
String类是通过char数组来保存字符串的。char[]数组是final修饰的,所以String类型的变量值不可变。
String类是final类,也即意味着String类不能被继承,并且它的成员方法都默认为final方法。
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | public String()public String(String str) | |
| 常用方法 | equals() | 字符串相等比较,不忽略大小写 |
| startsWith() | 判断字符串是否以指定的前缀开始 | |
| indexOf() | 取得指定字符在字符串的位置 | |
| length() | 取得字符串的长度 | |
| substring() | 截取子串 |
【示例】
public static void main(String[] args) {
// 不同构造方法声明String变量
String str1 = "天亮教育";
String str2 = new String("天亮教育");
String str3 = "天亮";
// 长度:length()
System.out.print(str1.length() >= str3.length() ? "str1长" : "str3长");
// 判断是否以指定字符开头
if (str1.startsWith(str3)) {
// str3第一次出现在str1中的位置
int startIndex = str1.indexOf(str3);
// 截取子串
String str1Sub = str1.substring(startIndex, str3.length() - 1);
String str2Sub = str2.substring(startIndex, str3.length() - 1);
System.out.println("两个字符串是否相等:" + str1Sub.equals(str2Sub));
}
}
}
2. StringBuilder
既然在Java中已经存在了String类,那为什么还需要StringBuilder和StringBuffer类呢?我们看个例子来分析一下。
public class StringDemo {
public static void main(String[] args) {
String str = "";
for(int i=0;i<100;i++){
str += "hello";
}
}
}
分析:
string += “hello”; 相当于将原有的string变量指向的对象内容取出与 “hello”做字符串相加操作
再存进另一个新的String对象当中,再让string变量指向新生成的对象。浪费时间和空间。
StringBuilder类为可变字符串,解决String在字符变更方面的低效问题,低层依赖字符数组实现。
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | StringBuilder()StringBuilder(String s) | |
| 常用方法 | toString() | 返回此序列中数据的字符串表示形式 |
| append() | 表示将括号里的某种数据类型的变量插入某一序列中 | |
| delete() | 移除此序列的子字符串中的字符 | |
| insert() | 表示将括号里的某种数据类型的变量插入某一序列中 | |
| reverse() | 将此字符序列用其反转形式取代 | |
| subString() | 返回一个新的 String,它包含此序列当前所包含的字符子序列 |
String和StringBuilder对比
• 都是 final 类, 都不允许被继承
• String 长度是不可变的, StringBuilder长度是可变的
3. StringBuffer
StringBuffer类的构造方法和用法与StringBuilder相同,可以认为是线程安全的StringBuilder。
StringBuilder和StringBuffer的对比
StringBuilder速度快,线程不安全的
StringBuffer线程安全的
StringBuffer、StringBuilder 长度是可变的
备注:线程安全的内容后面章节会具体讲解。
3. 数字常用类
1. Math
提供科学计算和基本的数字操作方法
| 类目 | 表示 | 描述 |
|---|---|---|
| 常用方法 | static double abs(数值型 a) | 返回指定数值的绝对值 |
| static double ceil(double a) | 返回最小的(最接近负无穷大)double值,大于或等于参数,并等于一个整数 | |
| static double floor(double a) | 返回最大的(最接近正无穷大)double值小于或相等于参数,并相等于一个整数 | |
| static long max(数值型 a, 数值型 b) | 返回比较参数的较大的值 | |
| static long min(数值型 a, 数值型 b) | 返回比较参数的较小的值 | |
| static double random() | 返回一个无符号的double值,大于或等于0.0且小于1.0 | |
| static double sqrt(double a) | 返回正确舍入的一个double值的正平方根 |
2. DecimalFormat
DecimalFormat类主要的作用是用来格式化数字使用,可以直接按用户指定的方式进行格式化。
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | public DecimalFormat() | |
| public DecimalFormat(String pattern) | ||
| 常用方法 | public final String format(double number) | 按照指定格式对数值进行格式化 |
| 符号 | 含义 |
|---|---|
| 0 | 阿拉伯数字 |
| # | 阿拉伯数字,如果不存在则显示为空 |
3. Random
Random类专门用于生成一个伪随机数,它有两个构造器。
相对于Math的random()方法而言,Random类提供了更多方法来生成各种伪随机数,它不仅可以生成浮点类型的伪随机数,也可以生成整形类型的伪随机数,还可以指数定生成随机数的范围。
4. 日期处理类
Java提供了一系列用于处理日期、时间的类,包括创建日期、时间对象,获取系统当前日期、时间等操作。
1. Date类
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | Date() | |
| Date(long date) | ||
| 常用方法 | long getTime() | 返回该时间对应的long型整数 |
| int compareTo(Date anotherDate) | 比较两个日期的大小 | |
| void setTime(long time) | 设置该Date对象的时间 |
2. Calendar类
Date类不方便实现国际化,已经不被推荐使用。所以,引入了Calendar类进行日期和时间处理。
【介绍】
Calendar类是抽象类,所以不能通过构造方法来创建对象。Calendar与Date都是表示日期的工具类,可以自由转换。
| 类目 | 表示 | 描述 |
|---|---|---|
| 常用属性 | YEAR | |
| MONTH | ||
| WEEK_OF_YEAR | ||
| WEEK_OF_MONTH | ||
| DATE | ||
| DATE_OF_MONTH | ||
| 常用方法 | int get(int field) | 返回指定日历字段的值 |
| void set(int y,int mon,int date,int h,int min,int sec) | 设置对象的年月日时分秒 | |
| void add(int field,int amount) | 为给定的日历字段添加或减去指定的时间量 |
3. SimpleDateFormat类
SimpleDateFormat是最常用的日期处理类,创建对象时需要传入一个日期模板字符串。
| 类目 | 表示 | 描述 |
|---|---|---|
| 构造方法 | public SimpleDateFormat()public SimpleDateFormat(String pattern) | 按照日期模板格式化 |
| 常用方法 | public final String format(Date date) | 对日期格式化 |
| public Date parse(String source) | 把一个字符串解析成Date对象 |
5. 枚举类型
【介绍】
枚举类型是Java 5新增的特性,它是一种新的类型 枚举类型的定义中列举了该类型所有可能值 使用java.lang.Enum类型来定义枚举
【语法格式】
[修饰符] enum 类名{
... ...
}
【意义】
可以替代常量定义,自动实现类型检查,便于维护、编程,减少出错概率 。
七、集合、Map
1. 集合概述*
介绍
Java集合是使程序能够存储和操纵元素不固定的一组数据。 所有Java集合类都位于java.uti包中。
| 数组 | 集合 |
|---|---|
| 长度固定 | 长度不固定 |
| 存放任意类型 | 不能存放基本数据类型,只能存放对象的引用 |
注意:如果集合中存放基本类型,一定要将其 “装箱”成对应的”基本类型包装类”。
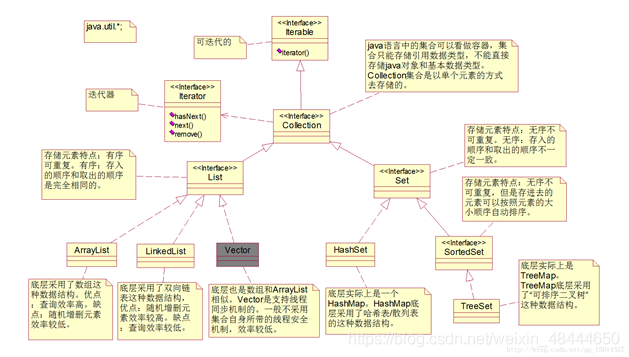
2. 层次结构
Java的集合类主要由两个接口派生而出:Collection和Map。Collection和Map是Java结合框架的根接口,这两个接口又包含了一些子接口或实现类。
1. Collection的继承层次结构
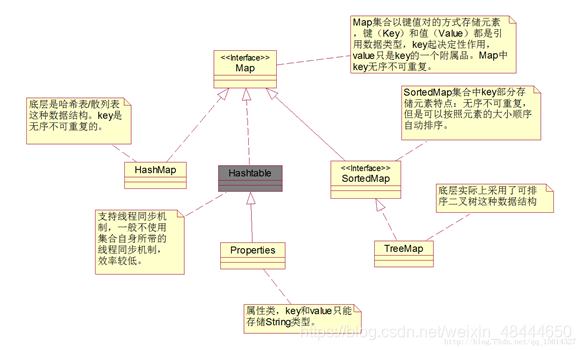
2. Map的继承层次结构
3. 总结
由以上两图我们可以看出Java集合类有清晰的继承关系,有很多子接口和实现类。但是,并不是所有子接口或实现类都是最常用的。
下面我们列举出最常用的几个子接口和实现类:
Collection ——> List ——> ArrayList类
Collection ——> List ——> LinkedList类
Collection ——> Set ——> HashSet类
Collection ——> Set ——> SortedSet接口 ——> TreeSet类
Map ——> HashMap类
Map ——> SortedMap ——> TreeMap类
2. Collection接口和Iterator
1. Collection介绍
Collection接口是List接口和Set接口的父接口,它定义的方法可以用于操作List集合和Set集合。
Collection接口定义的方法
| 方法 | 描述 |
|---|---|
| boolean add(Object o) | 该方法用于向集合里添加一个元素,添加成功返回true |
| void clear() | 清除集合里的所有元素,将集合长度变为0 |
| boolean contains(Object o) | 返回集合里是否包含指定元素 |
| boolean containsAll(Collection c) | 返回集合里是否包含集合c里的所有元素 |
| int hashCode() | 返回此collection的哈希码值 |
| boolean isEmpty() | 返回集合是否为空,当集合长度为0时,返回true |
| Iterator iterator() | 返回一个Iterator对象,用于遍历集合里的元素 |
| boolean remove(Object o) | 删除集合中指定元素o,当集合中包含了一个或多个元素o时,这些元素将被删除,该方法将返回true |
| boolean removeAll(Collection c) | 从集合中删除集合c里包含的所有元素,如果删除了一个或一个以上的元素,返回true |
| boolean retainAll(Collection c) | 从集合中删除不在集合c里包含的元素,如果删除了一个或一个以上的元素,返回true |
| int size() | 返回集合中的元素个数 |
| Object[] toArray() | 该方法把集合转换成一个数组,所有集合元素变成对应的数组元素 |
【示例】
public class Collection_01 {
public static void main(String[] args) {
//创建集合
Collection c1 = new ArrayList();
//自动装箱为Integer类型,然后向上转型 为Object 类型,发生多态
c1.add(1);
c1.add(1);
c1.add(1);
c1.add(1);
c1.add(1.2);
c1.add(true);
c1.add(new Collection_01());
c1.add(new Object());
System.out.println(c1.size());
System.out.println(c1.isEmpty());
c1.remove(1);
System.out.println(c1.size());
//直接遍历集合
for (Object object : c1) {
System.out.println(object);
}
//把集合转换为Object数组,再遍历
Object[] arr = c1.toArray();
for (Object object : arr) {
System.out.println(object);
}
//清空集合
c1.clear();
System.out.println(c1.size());
}
}
2. Iterator
【介绍】
Collection接口的iterator()和toArray()方法都用于获得集合中的所有元素,前者返回一个Iterator对象,后者返回一个包含集合中所有元素的数组。
Iterator接口隐藏底层集合中的数据结构,提供遍历各种类型集合的统一接口。
【接口主要方法】
| 方法 | 描述 |
|---|---|
| boolean hasNext() | 如果被迭代的集合有下一个元素,则返回true |
| Object next() | 返回集合里下一个元素 |
| void remove() | 删除集合里上一次next方法返回的元素 |
【示例】
//创建迭代器
Iterator it = c.iterator();
//如果添加或删除数据之后,一定要重新生成迭代器
c.add(2);
it = c.iterator();
while (it.hasNext()) {
Object o = it.next();
System.out.println(o);
}
//1 迭代器使用完之后,不会自动复原,需要重新创建才能再次遍历
while (it.hasNext()) {
Object o = it.next();
System.out.println(0);
}
【for与iterator对比】
Iterator的好处在于可以使用相同方式去遍历集合中元素,而不用考虑集合类的内部实现。
使用Iterator来遍历集合中元素,如果不再使用List转而使用Set来组织数据,则遍历元素的代码不用做任何修改
使用for来遍历,那所有遍历此集合的算法都得做相应调整,因为List有序,Set无序,结构不同,他们的访问算法也不一样
for循环需要下标
【foreach增强循环】
foreach遍历集合相当于获取迭代器,通过判断是否有下一个元素,执行操作。遍历数组相当于经典的for循环。
| 优点 | 缺点 |
|---|---|
| 遍历的时候更加简洁不用关心集合下标的问题。减少了出错的概率 | 不能同时遍历多个集合在遍历的时候无法修改和删除集合数据 |
3. List
【特点】
List是一个有序集合,既存入集合的顺序和取出的顺序一致
List集合允许添加的元素重复
List不单单继承了Collection的方法,还增加了一些新的方法。
| 方法 | 描述 |
|---|---|
| void add(int index, Object element) | 将元素element插入到List的index处 |
| boolean addAll(int index, Collection c) | 将集合c所包含的所有元素都插入在List集合的index处 |
| Object get(int index) | 返回集合index处的元素 |
| int indexOf(Object o) | 返回对象o在List集合中出现的位置索引 |
| int lastIndexOf(Object o) | 返回对象o在List集合中最后一次出现的位置索引 |
| Object remove(int index) | 删除并返回index索引处的元素 |
| Object set(int index, Object element) | 将index索引处的元素替换成element对象,返回新元素 |
| List subList(int fromIndex, int toIndex) | 返回从索引fromIndex(包含)到索引toIndex(不包含)处所有集合元素组成的子集合 |
【示例】
public class Collection_05_List_01 {
@Override
public String toString() {
return "----------";
}
public static void main(String[] args) {
List li = new ArrayList();
li.add(1);
li.add("张三");
li.add(new Collection_05_List_01());
//[1,张三,-------],因为输出一个list的时候,结构是这样的 [元素1,元素2,...]
//会调用集合中每个元素自身的toString方法
System.out.println(li);
//get:获取指定索引对应的元素,等于数组[index]
for (int i = 0; i < li.size(); i++) {
System.out.println(li.get(i));
}
//把元素插入到指定位置,原始位置数据和原位置之后的数据向后移动一位
li.add(1,"你吃了吗?");
for (Object object : li) {
System.out.println(object);
}
//用指定的元素把指定位置上的元素替换
li.set(2, "吃了");
Iterator it = li.iterator();
while (it.hasNext()) {
Object object = it.next();
System.out.println(object);
}
}
}
3.1 ArrayList、Vector
【特点对比】
1. ArrayList和Vector都是基于数组实现的,两者用法差不多
2. ArrayList随机查询效率高,随机增删元素效率较低
3. Vector提供了一个Stack子类,模拟“栈”数据结构——”先进后出”
4. ArrayList是线程不安全的,Vector是线程安全的
3.2 LinkedList
【特点】
LinkedList是双向链表实现的
随机查询效率低,随机增删效率高
【LinkedList新增方法】
| 方法 | 描述 |
|---|---|
| void addFirst(Object e) | 将指定元素插入该集合的开头 |
| void addLast(Object e) | 将指定元素插入该集合结尾 |
| boolean offerFirst(Object e) | 将指定元素插入该集合的开头 |
| boolean offerLast(Object e) | 将指定元素插入该集合结尾 |
| boolean offer(Object e) | 将指定元素插入该集合结尾 |
| Object getFirst() | 获取,但不删除集合第第一个元素 |
| Object getLast() | 获取,但不删除集合最后一个元素 |
| Object peekFirst() | 获取,但不删除该集合第一个元素,如果集合为空,则返回null |
| Object peekLast() | 获取,但不删除该集合最后一个元素,如果集合为空,则返回null |
| Object pollFirst() | 获取,并删除该集合第一个元素,如果集合为空,则返回null |
| Object pollLast() | 获取,并删除该集合最后一个元素,如果集合为空,则返回null |
| Object removeFirst() | 获取,并删除该集合的第一个元素 |
| Object removeLast() | 获取,并删除该集合的最后一个元素 |
| Object pop() | pop出该集合的第一个元素 |
| void push(Object e) | 将一个元素push到集合 |
【示例】
public class Collection_07_LinkedList {
public static void main(String[] args) {
LinkedList li = new LinkedList();
//尾部添加 成功返回true
li.add(1);
//头部添加
li.push(7);
//头部添加
li.addFirst(2);
//尾部添加
li.addLast(3);
//头部添加,成功返回true
li.offerFirst(4);
//尾部添加,成功返回true
li.offerLast(5);
//尾部添加,成功返回true
li.offer(6);
//上面几个方法,本质调用的就是两个方法,linkLast和linkFirst 所以没有任何区别,主要为了解决大家的命名习惯问题
System.out.println(li);
System.out.println("----");
//获取指定下标对应的元素
System.out.println(li.get(2));
//获取首位元素
System.out.println(li.getFirst());
//获取最后一个元素
System.out.println(li.getLast());
//获取首位元素,并删除该元素,如果没有首位元素(就是集合中元素个数为0)返回null
System.out.println(li.poll());
//获取首位元素,并删除该元素,如果没有首位元素(就是集合中元素个数为0),报错
// java.util.NoSuchElementException
System.out.println(li.pop());
for (Object object : li) {
System.out.println(object);
}
}
}
【总结】
List主要有两个实现ArrayList和LinkedList,他们都是有顺序的,也就是放进去是什么顺序,取出来还是什么顺序
ArrayList——遍历、查询数据比较快,添加和删除数据比较慢(基于可变数组)
LinkedList——查询数据比较慢,添加和删除数据比较快(基于链表数据结构)
Vector——Vector已经不建议使用,Vector中的方法都是同步的,效率慢,已经被ArrayList取代
Stack——继承Vector实现的栈,栈结构是先进后出,但已被LinkedList取代
4. Set
【特点】
1. Set是一个无序集合,既存入集合的顺序和取出的顺序不一致
2. Set集合中元素不重复
【常用方法】
| 方法 | 描述 |
|---|---|
| boolean add(E e) | 如果此set中尚未包含指定元素,则添加指定元素 |
| boolean isEmpty() | 如果此set不包含任何元素,则返回true |
| boolean contains(Object o) | 如果此set包含指定元素,则返回 true |
| boolean remove(Object o) | 如果指定元素存在于此set中,则将其移除 |
| int size() | 返回此set中的元素的数量 |
| void clear() | 从此set中移除所有元素 |
4.1 HashSet
HashSet是我们学习的重点,哈希原理我们在下面讲HashMap时,细讲。
4.2 TreeSet
TreeSet底层由TreeMap实现。可排序,默认自然升序。
【示例】
public class Collection_09_SortedSet_01 {
public static void main(String[] args) throws ParseException {
//TreeSet可以自动排序
SortedSet ss = new TreeSet();
ss.add(1);
ss.add(22);
ss.add(2);
System.out.println(ss);
//TreeSet也是自动排序
ss = new TreeSet();
ss.add("abc");
ss.add("abd");
ss.add("ba");
ss.add("ac");
System.out.println(ss);
ss = new TreeSet();
String st1 = "2008-08-08";
String st2 = "2008-08-07";
String st3 = "2008-09-01";
String st4 = "2007-08-08";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
Date d1 = sdf.parse(st1);
Date d2 = sdf.parse(st2);
Date d3 = sdf.parse(st3);
Date d4 = sdf.parse(st4);
ss.add(d1);
ss.add(d2);
ss.add(d3);
ss.add(d4);
for (Object object : ss) {
Date date = (Date) object;
System.out.println(sdf.format(date));
}
}
}
【总结】
HashSet底层由HashMap实现
TreeSet底层由TreeMap实现
5. Collections工具类和Comparable、Comparator比较器
5.1 Collections工具类
Collections是一个包装工具类。它包含有各种有关集合操作的静态多态方法,此类不能实例化,服务于Java的Collection接口。
【常用方法】
sort、reverse、fill、copy、max、min、swap等
【Sort排序】
public static <T extends Comparable<? super T>> void sort(List
list)
1. 根据元素的自然顺序 对指定列表按升序进行排序。列表中的所有元素都必须实现 Comparable 接口。
2. 此外,列表中的所有元素都必须是可相互比较的(也就是说,对于列表中的任何 e1 和 e2 元素,e1.compareTo(e2) 不得抛出 ClassCastException)。
【示例】
public class Collection_11_SortedSet_03 {
public static void main(String[] args) {
// SortedSet products = new TreeSet(new ProductComparator());
@SuppressWarnings("unchecked")
SortedSet products = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
double price1 = ((Product1)o1).price;
double price2 = ((Product1)o2).price;
if (price1 == price2) {
return 0;
}else if (price1 > price2) {
return 1;
}else{
return -1;
}
}
});
Product1 p1 = new Product1(1.5);
Product1 p2 = new Product1(2.2);
Product1 p3 = new Product1(1.5);
products.add(p1);
products.add(p2);
products.add(p3);
System.out.println(products);
}
}
class Product1 {
double price;
public Product1(double price) {
super();
this.price = price;
}
@Override
public String toString() {
return "Product1 [price=" + price + "]";
}
}
5.2 Comparable、Comparator比较器
对象排序,就是比较大小,要实现Comparable或Comparator比较器之一,才有资格做比较排序。
【介绍】
1. Comparable:与对象紧相关的比较器,可以称“第一方比较器”。
2. Comparator:此为与具体类无关的第三方比较器。
【示例】
public class Collection_12_SortList {
@SuppressWarnings("unchecked")
public static void main(String[] args) {
List list = new ArrayList();
list.add(new User1(18));
list.add(new User1(14));
list.add(new User1(10));
Collections.sort(list,new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((User1)o1).age - ((User1)o2).age ;
}
});
System.out.println(list);
}
}
class User1{
int age;
public User1(int age) {
super();
this.age = age;
}
@Override
public String toString() {
return "User1 [age=" + age + "]";
}
}
6. Map接口
Map用于保存具有映射关系的数据,因此Map集合里保存两组值。
- 一组值用于保存key,一组值用于保存value
- key~value之间存在单向一对一关系,通过指定key可以找到唯一的value值
- key和value都可以是任何引用类型对象
- 允许存在value为null,但是只允许存在一个key为null
【常用方法】
| 方法 | 描述 |
|---|---|
| V put(K key, V value) | 将指定的值与此映射中的指定键关联 |
| boolean containsKey(Object key) | 如果此映射包含指定键的映射关系,则返回true |
| boolean containsValue(Object value) | 如果此映射将一个或多个键映射到指定值,则返回true |
| boolean isEmpty() | 如果此映射未包含键-值映射关系,则返回true |
| V get(Object key) | 返回指定键所映射的值,如果此映射不包含该键的映射关系,则返回null |
| Set keySet() | 返回此映射中包含的键的set集合 |
| Collection values() | 返回此映射中包含的值的Collection集合 |
| Set<Map.Entry<K,V>> entrySet() | 返回此映射中包含的映射关系的set集合 |
| boolean equals(Object o) | 返回指定的对象与此映射是否相等 |
| int hashCode() | 返回此映射的哈希码值 |
| V remove(Object key) | 如果存在一个键的映射关系,则将其从此映射中移除 |
| void clear() | 从此映射中移除映射关系 |
| int size() | 返回此映射中的键-值关系数 |
【示例】
public class Collection_14_Map_01 {
public static void main(String[] args) {
Map map = new HashMap();
map.put("A", "one");
map.put("B", "two");
map.put("C", "three");
map.put(1003, "rose");//Integer
map.put('A', "1000");
map.put("65", "1000");
map.put("'A'", "3000");
map.put("A", "2000");//value覆盖
//可以都是null,但没什么意义
//key只能有一个为null,因为唯一,value可以有很多null
map.put(null, null);
//8个
System.out.println(map.size());
//false
System.out.println(map.containsKey("1003"));
//true
System.out.println(map.containsValue("2000"));
//2000 根据key获取value值
System.out.println(map.get("A"));
System.out.println("--------");
//把map中的key取出来,形成set
Set s = map.keySet();
for (Object object : s) {
System.out.println(object + ":" + map.get(object));
}
System.out.println("-----------");
//把map中的所有entry取出,形成set
//并且entry覆写了toString方法,会以key=value的形式展示
Set set = map.entrySet();
for (Object object : set) {
System.out.println(object);
}
System.out.println("--------");
System.out.println(1);
System.out.println("1");
System.out.println('1');
}
}
1. HashMap类
【特点】
key无序不可重复
底层是哈希表
【哈希表实现原理】
HashMap实际上是一个"链表的数组"的数据结构,每个元素存放链表头结点的数组,即数组和链表的结合体。
当我们往HashMap中put元素的时候,先根据key的hashCode重新计算hash值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
只有相同的hash值的两个值才会被放到数组中的同一个位置上形成链表。
如果这两个Entry的key通过equals比较返回true,新添加Entry的value将覆盖集合中原有Entry的value,但key不会覆盖。
【总结】
HashMap中key的hashCode值决定了<k,v>键值对组成的entry在哈希表中的存放位置。
HashMap中key通过equals()比较,确定是覆盖key对应的value值还是在链表中添加新的entry。
综合前两条,需要重写hashCode()和equals()方法。
【示例】
public class Practice_05 {
public static void main(String[] args) {
List list = new ArrayList();
Stu s1 = new Stu(1, "张三", 10, 001);
Stu s2 = new Stu(1, "张三", 10, 002);
Stu s3 = new Stu(2, "王五", 14, 001);
Stu s4 = new Stu(3, "小李", 12, 002);
Stu s5 = new Stu(5, "小马", 11, 001);
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s4);
list.add(s5);
Set set = new HashSet();
set.add(s1);
set.add(s2);
set.add(s3);
set.add(s4);
set.add(s5);
//学号重复的人有几个,就是同时学两门课的人有几个
int a = list.size() - set.size();
System.out.println(a);
for (int i = 0; i < list.size(); i++) {
for (int j = 0; j < list.size()-1-i; j++) {
if ((Stu)list.get(i) == (Stu)list.get(j)) {
String s = ((Stu)list.get(j)).name;
System.out.println(s);
}
}
}
}
}
class Stu {
int id;
String name;
int age;
int stuId;
public Stu(int id, String name, int age, int stuId) {
super();
this.id = id;
this.name = name;
this.age = age;
this.stuId = stuId;
}
@Override
public String toString() {
return "Stu [id=" + id + ", name=" + name + ", age=" + age + ", stuId="
+ stuId + "]";
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}else if (obj instanceof Stu) {
Stu s = (Stu) obj;
if (this.id == s.id) {
return true;
}
}
return false;
}
public int hashCode(){
return 1;
}
}
【HashSet】
特点
1. HashSet底层由HashMap实现
2. 无序不可重复
【示例】
public class Collection_13_Set_01 {
public static void main(String[] args) {
Set s = new HashSet();
s.add(1);
s.add(1);
s.add(2);//id = 1;
System.out.println(s);
HashSet hs = new HashSet();
Employee e1 = new Employee("1000", "obama");
Employee e2 = new Employee("4000", "obalv");
Employee e3 = new Employee("2000", "张三");
Employee e4 = new Employee("3000", "张三");
Employee e5 = new Employee("1000", "张三");
Employee e6 = new Employee("5000", "李四");
// System.out.println(e1.hashCode());
// System.out.println(e2.hashCode());
// System.out.println(e3.hashCode());
// System.out.println(e4.hashCode());
// System.out.println(e5.hashCode());
// System.out.println(e6.hashCode());
hs.add(e1);
//如果重复就不添加
hs.add(e2);
hs.add(e3);
hs.add(e4);
hs.add(e5);
hs.add(e6);
System.out.println(hs.size());
for (Object object : hs) {
System.err.println(object);
}
}
}
class Employee{
String no;
String name;
public Employee(String no, String name) {
super();
this.no = no;
this.name = name;
}
@Override
public String toString() {
return "Employee [no=" + no + ", name=" + name + "]";
}
@Override
public boolean equals(Object obj) {
System.out.println("equals 执行了");
if (this == obj) {
return true;
}
if (obj instanceof Employee) {
Employee e = (Employee) obj;
if (no.equals(e.no)) {
return true;
}
}
return false;
}
static int i = 16;
@Override
public int hashCode() {
System.out.println("hashCode执行了");
return no.hashCode();
}
}
2. TreeMap
TreeMap是SortedMap接口的实现类,可以根据Key进行排序,HashMap没有这个功能。
【特点】
1. 底层由可排序二叉树实现
2. 不指定比较器默认按照key自然升序,指定比较器按照比较器排序
【示例】
public class Collection_15_SortedMap_01 {
public static void main(String[] args) {
@SuppressWarnings("unchecked")
SortedMap products = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
double price1 = ((Product)o1).price;
double price2 = ((Product)o2).price;
if (price1 == price2) {
return 0;
}else if (price1 < price2) {
return -1;
}else {
return 1;
}
}
});
Product p1 = new Product("water", 1.0);
Product p2 = new Product("苹果", 3.0);
Product p3 = new Product("香蕉", 2.0);
Product p4 = new Product("梨", 1.5);
//value 可以设置为已购买数量
products.put(p1, 4.0);
products.put(p2, 2.0);
products.put(p3, 1.0);
products.put(p4, 4.0);
//获取所有key,以Set形式返回
Set keys = products.keySet();
for (Object key : keys) {
Product p = (Product) key;
double value = (double)products.get(key);
System.out.println(p+"------>"+value+"kg 总价="+(value*p.price));
}
}
}
class Product{
String name;
double price;
public Product(String name, double price) {
super();
this.name = name;
this.price = price;
}
@Override
public String toString() {
return "Product [name=" + name + ", price=" + price + "]";
}
}
【总结】
TreeMap需要key实现Comparable接口,排序主要看compareTo()方法。
7. 泛型
泛型是指所操作的数据类型被指定为一个参数,在用到的时候再指定具体的类型。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法。
【示例】
- 定义一个对象池对象,可以根据需求存放各种类型对象。
class ProjectPool<T>{
private List<T> list = new ArrayList<T>();
public void add(T t){
list.add(t);
}
public int size(){
return list.size();
}
}
- 集合中使用泛型
List<Student> stuList = new ArrayList<Student>();
【总结】
1. 泛型能更早的发现错误,如类型转换错误
2. 使用泛型,那么在编译期将会发现很多之前要在运行期发现的问题
3. 代码量往往会少一些、运维成本减少
4. 抽象层次上更加面向对象
八、IO流
1. 流概述
1. 概念
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
2. 分类
按处理数据类型的不同,分为字节流和字符流
按数据流向的不同,分为输入流和输出流。(入和出是相对于内存来讲的)

按功能不同,分为节点流和处理流 节点流:直接操作数据源 处理流:对其他流进行处理
3. 抽象类定义
3.1 InputStream
InputStream的继承关系:蓝色为节点流,黑色为处理流(小红旗重点)
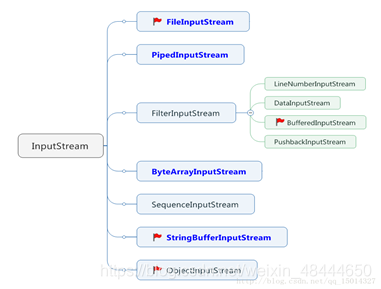
【常用方法】
| 方法 | 描述 |
|---|---|
| void close() | 关闭此输入流并释放与该流关联的所有系统资源 |
| abstract int read() | 从输入流读取下一个数据字节 |
| int read(byte[] b) | 从输入流中读取一定数量的字节并将其存储在缓冲区数组b中 |
| int read(byte[] b, int off, int len) | 将输入流中最多len个数据字节读入字节数组 |
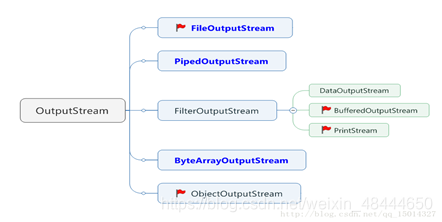
3.2 OutputStream
OutputStream的继承关系:蓝色为节点流,黑色为处理流(小红旗重点)
【常用方法】
| 方法 | 描述 |
|---|---|
| void close() | 关闭此输出流并释放与此流有关的所有系统资源 |
| void flush() | 刷新此输出流并强制写出所有缓冲的输出字节 |
| void write(byte[] b) | 将 b.length个字节从指定的字节数组写入此输出流 |
| void write(byte[] b, int off, int len) | 将指定字节数组中从偏移量 off 开始的 len 个字节写入此输出流 |
| abstract void write(int b) | 将指定的字节写入此输出流 |
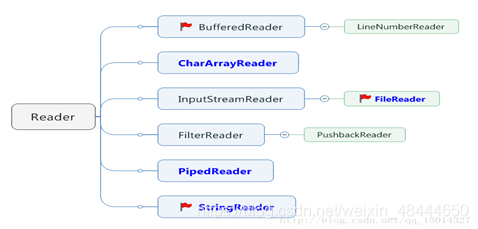
3.3 Reader
Reader的继承关系:蓝色为节点流,黑色为处理流(小红旗重点)
【常用方法】
| 方法 | 描述 |
|---|---|
| abstract void close() | 关闭该流 |
| int read() | 读取单个字符 |
| int read(char[] cbuf) | 将字符读入数组 |
| abstract int read(char[] cbuf, int off, int len) | 将字符读入数组的某一部分 |
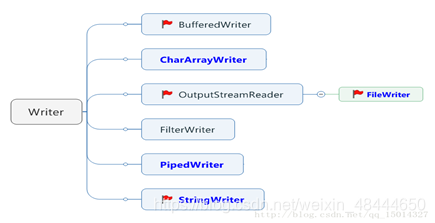
3.4 Writer
Writer的继承关系:蓝色为节点流,黑色为处理流(小红旗重点 )
【常用方法】
| 方法 | 描述 |
|---|---|
| void write(int c) | 写入单个字符 |
| void write(char[] cbuf) | 写入字符数组 |
| abstract void write(char[] cbuf, int off, int len) | 写入字符数组的某一部分 |
| void write(String str) | 写入字符串 |
| void write(String str, int off, int len) | 写入字符串的某一部分 |
| Writer append(char c) | 将指定字符添加到此writer |
| abstract void flush() | 刷新该流的缓冲 |
| abstract void close() | 关闭此流,但要先刷新它 |
2. File文件操作
1. 常用方法

还有一个重要方法: createNewFile() : 真正生成磁盘中的文件
2. 创建文件、删除文件
public class TestFileOperator {
public static void main(String[] args) throws Exception {
File txtFile = new File("auto_create.txt");
if (!txtFile.exists()) {
txtFile.createNewFile();
} else {
System.out.println("file existed");
System.out.println("txtFile.delete()=" + txtFile.delete());
}
}
}
3. 文件流
| 分类 | 字节流 | 字符流 |
|---|---|---|
| 文件输入流 | FileInputStream | FileReader |
| 文件输出流 | FileOutputStream | FileWriter |
4. 缓冲流
| 分类 | 字节流 | 字符流 |
|---|---|---|
| 文件输入流 | BufferedInputStream | BufferedReader |
| 文件输出流 | BufferedOutputStream | BufferedWriter |
【特点】
主要是为了提高效率而存在的,减少物理读取次数
提供readLine()、newLine()这样的便捷的方法(针对缓冲字符流)
在读取和写入时,会有缓存部分,调用flush为刷新缓存,将内存数据写入到磁盘
5. 转换流
| 输入流 | 输出流 |
|---|---|
| InputStreamReader | OutputStreamWriter |
【特点】
转换流是指将字节流向字符流的转换,主要有InputStreamReader和OutputStreamWriter
InputStreamReader主要是将字节流输入流转换成字符输入流
OutputStreamWriter主要是将字节流输出流转换成字符输出流
1. InputStreamReader
| 分类 | 方法 | 描述 |
|---|---|---|
| 构造方法 | InputStreamReader(InputStream in) | 用默认字符集的该对象 |
| InputStreamReader(InputStream in,Charset cs) | 创建使用给定字符集的该对象 | |
| InputStreamReader(InputStream in,CharsetDecoder dec) | 创建使用给定字符集解码器的该对象 | |
| InputStreamReader(InputStream in,String charsetName) | 创建使用指定字符集该对象 | |
| 常用方法 | void close() | 关闭该流并释放与之关联的所有资源 |
| String getEncoding() | 返回此流使用的字符编码的名称 | |
| int read() | 读取单个字符 | |
| int read(char[] cbuf, int offset, int length) | 将字符读入数组中的某一部分 | |
| boolean ready() | 判断此流是否已经准备好用于读取 |
2. OutputStreamWriter
参考InputStreamReader
6. 打印流
【特点】
打印流是输出最方便的类
包含字节打印流PrintStream,字符打印流PrintWriter
PrintStream是OutputStream的子类,把一个输出流的实例传递到打印流之后,可以更加方便地输出内容,相当于把输出流重新包装一下
PrintStream类的print()方法被重载很多次print(int i)、print(boolean b)、print(char c)
【标准输入/输出】
Java的标准输入/输出分别通过System.in和System.out来代表,在默认的情况下分别代表键盘和显示器,当程序通过System.in来获得输入时,实际上是通过键盘获得输入。当程序通过System.out执行输出时,程序总是输出到屏幕。
在System类中提供了三个重定向标准输入/输出的方法
static void setErr(PrintStream err) 重定向“标准”错误输出流
static void setIn(InputStream in) 重定向“标准”输入流
static void setOut(PrintStream out)重定向“标准”输出流
【示例】
public class IO_19_Copy_03 {
static String oldFilePath = "D:\\课件";
public static void main(String[] args) {
File file = new File(oldFilePath);
long startTime = System.currentTimeMillis();
checkMenu(file);
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
}
public static void checkMenu(File file) {
// 如果 是文件 就终止
if (file.isFile()) {
// 文件全路径
// D:\\14期\\课件\\06.22_JavaSE基础之数据类型和变量/笔记.doc
String filePath = file.getAbsolutePath();
// E:\\14期\\课件\\06.22_JavaSE基础之数据类型和变量/笔记.doc
String newFilePath = "E" + filePath.substring(1);
// E:\\14期\\课件\\06.22_JavaSE基础之数据类型和变量/笔记.doc 文件对象
File newFile = new File(newFilePath);
// 输出流只能创建文件,不会创建目录,所以 需要判断目录是否存在
// getParentFile 上级文件对象
// E:\\14期\\课件\\06.22_JavaSE基础之数据类型和变量 文件对象
File paraentFile = newFile.getParentFile();
// 判断该路径是否存在,没有就创建
if (!paraentFile.exists()) {
// 创建目录
paraentFile.mkdirs();
}
// 到这里说明肯定有目录了,就进行复制操作即可
try (FileInputStream fis = new FileInputStream(filePath);
FileOutputStream fos = new FileOutputStream(newFilePath);
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream bos = new BufferedOutputStream(fos);) {
byte[] bytes = new byte[102400];
int tmp = 0;
while ((tmp = bis.read(bytes)) != -1) {
bos.write(bytes, 0, tmp);
}
bos.flush();
} catch (Exception e) {
e.printStackTrace();
}
return;
}
// 能到这里 说明是目录
File[] files = file.listFiles();
for (File subFile : files) {
checkMenu(subFile);
}
}
}
7. 对象流
| 输入流 | 输出流 |
|---|---|
| ObejctInputStream | ObejctOutputStream |
【概念】
1. 对象流,即为以Java对象为传输主体的IO过程。Java对象必须要被序列化后方可进行传输。
2. 所谓的对象的序列化就是将对象转换成二进制数据流的一种实现手段,通过将对象序列化,可以方便的实现对象的传输及保存。
3. 要想实现对象的序列化需要实现Serializable接口,但是Serializable接口中没有定义任何的方法,仅仅被用作一种标记,
4. 以被编译器作特殊处理。
5. 在Java中提供了ObejctInputStream 和ObjectOutputStream这两个类用于序列化对象的操作。
6. 对象的序列化的实现方便了对象间的克隆,使得复制品实体的变化不会引起原对象实体的变化。
九、网络编程
1 . 网络基础简介
计算机网络协议
网络协议的目的是为了在计算机物理连接之后进行交互的
目前,成熟的协议有2大类
OSI/ISO - 学术研究,教学用 - 学术上的标准
分为 : 物理层,数据链路层,网络层,传输层,会话层,表示层,应用层
TCP/IP - 实际使用 - 实际上的标准
分为 : 网络接口层,网际层,传输层,应用层
它们都是一整套协议族,并不是单个或者几个协议组成的
它们之间是一个有机的整体
计算机网络
分层思想 - 分工负责,各司其职,更清晰地处理相关问题
网络协议,整个体系,就是分层思想的体现我们使用TCP/IP协议为例进行讲解,不做深入研究
2. TCP/IP协议**
TCP/IP协议的分层
应用层,传输层,网络层,网络接口层。
应用层。实际上本层的内容并不是“应用”软件的“应用” 应用软件要想正常工作,是要基于应用层的协议的
HTTP/HTTPS(http://www.baiu.com)浏览互联网WWW服务(Web服务)
FTP(ftp://ftp.server.com)用于共享文件,现在很少使用,可能某些机构、大学内部会有这些服务器 SMTP发邮件的
传输层 传输层的作用是向应用层提供服务的 应用层那些协议要想正常工作,是要基于传输层协议的
TCP。面向连接,保证数据传输过程中的完整,有序,丢包重传。 性能其实有些低的,但这是数据准确传输必须付出的代价
UDP。无连接,它只管闷头发数据,不保证数据的准确性(完整,有序,无重传机制) 因为不用保证数据准确传输,所以它快
QQ的有些功能就会使用UDP(当然它也使用TCP) 我们聊天的时候,有些文字就打了个红叹号,没发送出去,这就是使用UDP的功能
3. Socket编程
Java对网络编程的支持,选择了传输层的2个协议,以TCP/UDP为基础,构建了自己的网络类继承体系。
Java的网络编程与异常、IO流、多线程部分的知识联系紧密。
网络编程的基础在于Socket编程,而Socket编程在初学阶段重点掌握TCP Socket即可。
TCP Socket编程分为服务端编程(ServerSocket类)与客户端编程(Socket类)。
我们可以使用telnet命令连接到服务器。
如telnet 127.0.0.1 8888
也可以使用Java Socket类编程实现
ServerSocket类
实现一个简单的服务器
//创建一个工作在端口8888的服务器对象
ServerSocket ss = new ServerSocket(8888);
//开启监听,调用下面的方法会使程序阻塞,一直到有客户端来连接本服务器的8888端口(可以通过telnet命令或者Socket客户端编程实现)
Socket socket = ss.accept();
//一旦有客户端连接,则返回对应的客户端对象socket
然后我们可以通过socket获取客户端的输入流与输出流,如果我们处理的是文本数据(绝大部分情况都是处理文本数据)再使用字节字符转换流进行包装转换。注意字符集。
向客户端发送信息使用:
OutputStreamWriter osw = new OutputStreamWriter(socket.getOutputStream(), "utf-8");
BufferedWriter bw = new BufferedWriter(osw);//PrintWriter与BufferedWriter二选一
PrintWriter out = new PrintWriter(osw);//PrintWriter与BufferedWriter二选一
但是PrintWriter可以解决不同系统间换行符的兼容性问题,而且语法上更接近System.out.println(),所以建议使用这个类。
接收客户端信息使用:
InputStreamReader isr = new InputStreamReader(socket.getInputStream(), "utf-8");
BufferedReader br = new BufferedReader(isr);
注意,操作完成后,一定要关闭资源(各种IO流、各种网络连接等)
Socket类
实现一个简单的客户端
//创建一个连接指定IP/域名及端口号的服务端连接对象
Socket socket = new Socket("127.0.0.1", 8888);
之后的操作可类比ServerSocket中对socket的使用。
只不过,服务端socket.getOutputStream()的内容就是客户端的socket.getInputStream();
服务端socket.getInputStream()的内容就是客户端的socket.getOutputStream()
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket,又称”套接字”。
应用程序通常通过”套接字”向网络发出请求或者应答网络请求。本质是编程接口(API),对TCP/IP的封装,
TCP/IP也要提供可供程序员做网络开发所用的接口,即为Socket编程接口。
2. TCP Socket模型
TCP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); * 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、开启监听,用函数listen();
5、接收客户端上来的连接,用函数accept();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
8、关闭监听;
TCP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置要连接的对方的IP地址和端口等属性;
5、连接服务器,用函数connect();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
【示例】
- socket服务端
public class TestTCPServer01 {
public static void main(String[] args) throws Exception {
// 1、创建一个服务器端Socket,即ServerSocket,指定绑定的端口,并监听此端口
ServerSocket ss = new ServerSocket(8888);
while (true) {
// 2、调用accept()方法开始监听,等待客户端的连接
Socket socket = ss.accept();
System.out.println("client" + " connect!");
// 3、获取输入流,并读取客户端信息
InputStream is = socket.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String info = null;
while ((info = br.readLine()) != null) {
System.out.println("Hello,i'm server,client say:" + info);
}
br.close();
}
}
}
- socket客户端
public class TestTCPClient01 {
public static void main(String[] args) throws Exception {
// 1、创建客户端Socket,指定服务器地址和端口
Socket s = new Socket("127.0.0.1", 8888);
// 2、获取输出流,向服务器端发送信息
OutputStream os = s.getOutputStream();
// 将输出流包装成打印流
PrintWriter pw = new PrintWriter(os);
pw.write("hello,i'm 天亮!");
pw.flush();
pw.close();
}
}
3. UDP Socket模型
UDP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、循环接收数据,用函数recvfrom();
5、关闭网络连接;
UDP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置对方的IP地址和端口等属性;
5、发送数据,用函数sendto();
6、关闭网络连接;
【示例】
- udp服务端
public class TestUDPServer01 {
public static void main(String args[]) throws Exception {
//创建一个socket
DatagramSocket ds = new DatagramSocket(7777);
//创建一个数据包
byte buf[] = new byte[1024];
DatagramPacket dp = new DatagramPacket(buf, buf.length);
//阻塞等待接收客户端发送的数据包
ds.receive(dp);
//数据包中携带的数据在数据包的buf字节数组中,将其转换成字符串
String para = new String(buf, "utf-8");
//打印传递的数据
System.out.println("client print=" + para);
}
}
- udp客户端
public class TestUDPClient01 {
public static void main(String args[]) throws Exception {
// 创建socket对象
DatagramSocket ds = new DatagramSocket();
// 创建指定端口的ip地址
InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1", 7777);
// 把要发送的数据转换成字节数组形式
String sendStr = "i'm 天亮 Thanks for your coming! Come on!";
byte[] buf = sendStr.getBytes("utf-8");
// 创建数据包,封装字节数组数据和目标ip地址
DatagramPacket dp = new DatagramPacket(buf, buf.length, inetSocketAddress);
// 发送数据包
ds.send(dp);
// 关闭socket
ds.close();
System.out.println("send done!");
}
}
十、多线程
1. 进程、线程基本概念
1. 进程介绍
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元。在操作系统中每启动一个应用程序就会启动一个进程与之相对应。不同进程之间的内存是独立的,不共享内存。
多进程引入的优点
单个进程独占高速CPU造成CPU空闲时间太多、使用率低。引入多进程则在不同进程之间并发共享高速CPU,使CPU空闲时间减少,提高CPU使用效率。
2. 线程介绍
线程也称轻量级进程,是程序执行的最小单元。一个进程可以启动多个线程。不同线程堆内存和方法区内存共享,栈内存独立,一个线程一个栈。
多线程引入的优点
提高进程的执行效率
【思考】
程序中main方法结束,程序就结束了吗?
答:main方法结束程序不一定结束了。main方法结束主线程结束。有可能其他的分支线程还在运行。
分支线程和主线程没有主次高低之分,只不过分支线程是由主线程分发的。
3. 进程与线程的区别
进程有独立的代码和数据空间,进程间切换成本开销大。
同一进程的多个线程间共享进程代码和数据空间,仅保留独立的线程栈、程序计数器,切换成本小。
多进程是操作系统中可见的并行运行的多个独立任务。
多线程是同一进程内不同的多个并行执行程序。
2. 线程使用
1. 定义
1.1定义线程有两种方式
继承Thread类
实现Runnable接口(因Java单继承,推荐使用实现接口的方式)
1.2语法格式
继承Thread类
// 线程入口方法
@Override
public void run() {
}
}
实现Runnable接口
// 线程入口方法
@Override
public void run() {
}
}
2. 创建和启动
线程启动是通过调用线程类的start()方法,使线程进入就绪状态。CPU时间片到来,则线程真正执行run方法。
【示例】
继承Thread类
//初始化线程对象
Thread t = new PrintThread("打印线程");
//正式启动线程
t.start();
实现Runnable接口
//初始化一个Runnable接口实现类的对象
PrintRunnable pr = new PrintRunnable();
//pt本身没有线程开启的能力,需要依附到Thread中才能开启线程
Thread pt = new Thread(pr, "打印线程");
// 开启线程执行
pt.start();
3. 生命周期
线程的生命周期存在五个状态:新建、就绪、运行、阻塞、死亡
新建:采用new语句创建完成
就绪:执行start后
运行:占用CPU时间
阻塞:执行了wait语句、执行了sleep语句和等待某个对象锁,等待输入的场合
终止:执行完run()方法
3. 线程控制
线程控制,即通过API控制线程状态之间的转换。
1. 优雅的结束
API提供了线程结束的方法:stop()方法。但是,该方法使用的过程中经常出现问题,会造成程序关闭延迟甚至死锁。
所以想要优雅的结束,可以通过设置标志位,来控制线程是否继续运行。
4. 线程同步
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法。
1. 线程同步的必要性
保证多线程安全访问竞争资源。
为了防止多个线程访问一个数据对象时,对数据造成的破坏。
2. 线程同步原理
上例可以看到我们在实现线程同步的时候,使用了synchronized关键字。该关键字修饰在方法上相当于对该方法加了锁。一个线程访问方法的时候需要先获得锁,然后才能执行该方法。此时,如果其他线程来了,发现锁已经被占用,则在方法调用处等待,直到锁被释放,再去竞争锁。获得锁,则执行该方法,否则,继续等待。
2.1线程锁
每个Java对象都有一个内置锁,有且只有一个。
当程序执行到非静态的synchronized同步方法时,(如果锁没被其他线程占用)自动获得该方法所属对象的锁。
不只是可以修饰在方法上同步方法,也可以对代码块加锁。
程序执行的时候,退出同步块或同步方法则释放锁。
【注意】
不必同步类中所有的方法,根据需要进行同步。
线程sleep睡眠时,它所持的锁不会释放。
线程可以获得多个锁。
同步损害并发性,应该尽可能缩小同步范围。
5. Lock
Lock和synchronized均是为了解决线程同步问题 ,Lock相对于synchronized的功能更多、使用更灵活、更面向对象。
【使用】
private Lock lock = new ReentrantLock();
public void take(){
lock.lock();
//同步部分
lock.unlock();
}
十一、新特性
1. Lambda表达式
1.1 介绍
Lambda表达式是一种没有名字的函数,也可称为闭包,是Java 8 发布的最重要新特性。
本质上是一段匿名内部类,也可以是一段可以传递的代码。 还有叫箭头函数的…
闭包
闭包就是能够读取其他函数内部变量的函数,比如在java中,方法内部的局部变量只能在方法内部使用,所以闭包可以理解为定义在一个函数内部的函数
闭包的本质就是将函数内部和函数外部链接起来的桥梁
1.2 特点
允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
1.3 应用场景
列表迭代
Map映射
Reduce聚合
代替一个不想命名的函数或是类,该函数或类往往并不复杂。
想尽量缩短代码量的各个场景均可以
1.4 代码实现
1.4.1 具体语法
1、(parameters) -> expression
2、(parameters) ->{ statements; }
1.4.2 语法特点
可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值
如果只有一条语句,并且是返回值语句,就可以不写return 不写 {}
如果写上{} 就必须写return 和 ;
如果有 多条语句,必须写{} return 和 ; 也必须写
案例说明-简单
// 1. 不需要参数,返回值为 5 () -> 5
// 2. 接收一个参数(数字类型),返回其2倍的值 x -> 2*x
// 3. 接受2个参数(数字),并返回他们的差值 (x, y) -> x – y
// 4. 接收2个int型整数,返回他们的和 (int x, int y) -> x + y
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void) (String s) ->
System.out.print(s)
1.4.3 集合遍历
public static void main(String[] args) {
String[] arr = { "one", "two", "three" };
List<String> list = Arrays.asList(arr);
// jdk1.7-老版写法
for (String ele : list) {
System.out.println(ele);
}
System.out.println("---");
// jdk1.8-新版写法
list.forEach(x -> {
System.out.println(x);
});
// 就类似于这种写法,相当于自己创建了一个方法,然后遍历调用这个方法
// 把 集合中每个元素作为参数传递进去,并打印参数
for (String string : list) {
m1(string);
}
}
public static void m1(String x) {
System.out.println(x);
}
1.4.4 集合排序
public static void main(String[] args) {
Integer[] arr = { 9, 8, 10, 1, 3, 5 };
// 把数组转换为list
List<Integer> list = Arrays.asList(arr);
// jdk1.7-旧版写法,使用比较器进行排序
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1 - o2;
}
});
System.out.println(list);
// jdk1.8-新版写法
// 把数组转换为list
list = Arrays.asList(arr);
list.sort((x, y) -> x - y);
System.out.println(list);
}
2. 函数式接口**
2.1 介绍
英文称为Functional Interface
其本质是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
核心目标是为了给Lambda表达式的使用提供更好的支持,进一步达到函数式编程的目标,可通过运用函数式编程极大地提高编程效率。
其可以被隐式转换为 lambda 表达式。
2.2 特点
函数式接口是仅制定一个抽象方法的接口
可以包含一个或多个静态或默认方法
专用注解即@FunctionalInterface
检查它是否是一个函数式接口,也可不添加该注解
如果有两个或以上 抽象方法,就不能当成函数式接口去使用,也不能添加@FunctionalInterface这个注解
如果只有一个抽象方法,那么@FunctionalInterface注解 加不加 都可以当做函数式接口去使用
回调函数
简单来说就是回调函数,方法的参数是一个方法,在这个方法中对传递的方法进行调用
2.3 应用场景
想通过函数式编程,提高编程效率的各种场景均可。
2.4 代码实现
2.4.1 无参情况
public class FunInterface_01 {
// 自定义静态方法,接收接口对象
public static void call(MyFunctionInter func) {
// 调用接口内的成员方法
func.printMessage();
}
public static void main(String[] args) {
// 第一种调用 : 直接调用自定义call方法,传入函数
FunInterface_01.call(() -> {
System.out.println("HelloWorld!!!");
});
// 第二种调用 : 先创建函数对象,类似于实现接口的内部类对象
MyFunctionInter inter = () -> {
System.out.println("HelloWorld2!!!!");
};
// 调用这个实现的方法
inter.printMessage();
}
}
// 函数式接口
@FunctionalInterface
interface MyFunctionInter {
void printMessage();
}
2.4.2 有参情况
public class FunInterface_02 {
// 自定义静态方法,接收接口对象
public static void call(MyFunctionInter_02 func, String message) {
// 调用接口内的成员方法
func.printMessage(message);
}
public static void main(String[] args) {
// 调用需要传递的数据
String message = "有参函数式接口调用!!!";
// 第一种调用 : 直接调用自定义call方法,传入函数,并传入数据
FunInterface_02.call((str) -> {
System.out.println(str);
}, message);
// 第二种调用 : 先创建函数对象,类似于实现接口的内部类对象
MyFunctionInter_02 inter = (str) -> {
System.out.println(str);
};
// 调用这个实现的方法
inter.printMessage(message);
}
}
// 函数式接口
@FunctionalInterface
interface MyFunctionInter_02 {
void printMessage(String message);
}
2.5 JDK自带常用的函数式接口
2.5.1 SUPPLIER接口
Supplier接口
代表结果供应商,所以有返回值,可以获取数据,有一个get方法,用于获取数据
public class _03_JdkOwn_01 {
private static String getResult(Supplier<String> function) {
return function.get();
}
public static void main(String[] args) {
// 1
String before = "张三";
String after = "你好";
// 把两个字符串拼接起来
System.out.println(getResult(() -> before + after));
// 2 //创建Supplier容器,声明为_03_JdkOwn类型
// 此时并不会调用对象的构造方法,即不会创建对象
Supplier<_03_JdkOwn_01> sup = _03_JdkOwn_01::new;
_03_JdkOwn_01 jo1 = sup.get();
_03_JdkOwn_01 jo2 = sup.get();
}
public _03_JdkOwn_01() {
System.out.println("构造方法执行了");
}
}
2.5.2 CONSUMER接口
Consumer接口
消费者接口所以不需要返回值有一个accept(T)方法,用于执行消费操作,可以对给定的参数T 做任意操作
public class _04_JdkOwn_02 {
private static void consumeResult(Consumer<String> function, String message) {
function.accept(message);
}
public static void main(String[] args) {
// 传递的参数
String message = "消费一些内容!!!";
// 调用方法
consumeResult(result -> {
System.out.println(result);
}, message);
}
}
2.5.3 FUNCTION<T,R>接口
Function<T,R>接口
表示接收一个参数并产生结果的函数顾名思义,是函数操作的
有一个Rapply(T)方法,Function中没有具体的操作,具体的操作需要我们去为它指定,因此apply具体返回的结果取决于传入的lambda表达式
public class _05_JdkOwn_03 {
// Function<参数, 返回值>
public static void convertType(Function<String, Integer> function,
String str) {
int num = function.apply(str);
System.out.println(num);
}
public static void main(String[] args) {
// 传递的参数
String str = "123";
// s是说明需要传递参数, 也可以写 (s)
convertType(s -> {
int sInt = Integer.parseInt(s);
return sInt;
}, str);
}
}
2.5.4 PREDICATE接口
Predicate接口 断言接口
就是做一些判断,返回值为boolean
有一个boolean test(T)方法,用于校验传入数据是否符合判断条件,返回boolean类型
public class _06_JdkOwn_04 {
// 自定义方法,并且 Predicate 接收String字符串类型
public static void call(Predicate<String> predicate, String isOKMessage) {
boolean isOK = predicate.test(isOKMessage);
System.out.println("isOK吗:" + isOK);
}
public static void main(String[] args) {
// 传入的参数
String input = "ok";
call((String message) -> {
// 不区分大小写比较,是ok就返回true,否则返回false
if (message.equalsIgnoreCase("ok")) {
return true;
}
return false;
}, input);
}
}
3. 方法引用和构造器调用
3.1概念说明
Lambda表达式的另外一种表现形式,提高方法复用率和灵活性。
3.2 特点
更简单、代码量更少、复用性、扩展性更高。
3.3 应用场景
若Lambda 体中的功能,已经有方法提供了实现,可以使用方法引用。
不需要再复写已有API的Lambda的实现。
3.4 代码实现
3.4.1 方法引用
方法引用-3种形式
3.4.1.1 对象的引用 :: 实例方法名
public static void main(String[] args) {
Integer intObj = new Integer(123456);
// 常规lambda写法
Supplier<String> su = () -> intObj.toString();
System.out.println(su.get());
// 方法引用写法
Supplier<String> su1 = intObj::toString;
System.out.println(su1.get());
}
3.4.1.2 类名 :: 静态方法名
public static void main(String[] args) {
// 常规lambda写法
// 前两个泛型是参数类型,第三个是返回值类型
BiFunction<Integer, Integer, Integer> bi = (x, y) -> Integer.max(x, y);
int apply = bi.apply(10, 11);
System.out.println(apply);
// 方法引用写法
BiFunction<Integer, Integer, Integer> bif = Integer::max;
int apply2 = bif.apply(10, 11);
System.out.println(apply2);
}
3.4.1.3 类名 :: 实例方法名
public static void main(String[] args) {
// 常规lambda写法
// 两个泛型都是参数类型
BiPredicate<String, String> predicate = (x, y) -> x.equals(y);
System.out.println(predicate.test("a", "a"));
// 方法引用写法
// 使用第一个参数调用成员方法把第二个参数传入
// ::前面的类型 要和 第一个参数的类型一致
BiPredicate<String, String> predicate2 = String::equals;
System.out.println(predicate2.test("a", "b"));
}
3.4.3 构造器调用
public static void main(String[] args) {
// 无参构造器
// 常规lambda写法
Supplier<Object> objSup = () -> new Object();
System.out.println(objSup.get());
// 方法引用写法
Supplier<Object> s1 = Object::new;
System.out.println(s1.get());
// 有参构造器
// 常规lambda写法
Function<String, Integer> func = (x) -> new Integer(x);
System.out.println(func.apply("123456"));
// 方法引用写法
Function<String, Integer> func2 = Integer::new;
System.out.println(func2.apply("123456"));
}
3.4.4 数组调用
public static void main(String[] args) {
// lambda传统写法
Function<Integer, Integer[]> fun = (n) -> new Integer[n];
Integer[] intArray1 = fun.apply(5);
intArray1[0] = 100;
System.out.println(intArray1[0]);
// 数组引用新写法
Function<Integer, Integer[]> fun1 = Integer[]::new;
Integer[] intArray = fun1.apply(5);
intArray[0] = 100;
System.out.println(intArray[0]);
}
4. Stream API
4.1 概念说明
数据渠道、管道,用于操作数据源(集合、数组等)所生成的元素序列。
集合讲的是数据,流讲的是计算
即一组用来处理数组,集合的API。
4.2 特点
Stream 不是数据结构,没有内部存储,自己不会存储元素。 Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。 Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。 不支持索引访问。 延迟计算 支持并行 很容易生成数据或集合 支持过滤,查找,转换,汇总,聚合等操作。
4.3 应用场景
流式计算处理,需要延迟计算、更方便的并行计算
更灵活、简洁的集合处理方式场景
4.4 代码实现
4.4.1 运行机制说明
Stream分为源source,中间操作,终止操作。
流的源可以是一个数组,集合,生成器方法,I/O通道等等。
一个流可以有零个或多个中间操作,每一个中间操作都会返回一个新的流,供下一个操作使用,一个流只会有一个终止操作。
中间操作也称为转换算子-transformation
Stream只有遇到终止操作,它的数据源会开始执行遍历操作。
终止操作也称为动作算子-action
4.4.2 代码实现
4.4.2.1 生成stream流的5种方式说明
public static void main(String[] args) {
// 1 通过数组,Stream.of()
String[] str = { "a", "b", "c" };
Stream<String> str1 = Stream.of(str);
// System.out.println(str1);
// 2 通过集合
List<String> strings = Arrays.asList("a", "b", "c");
Stream<String> stream = strings.stream();
System.out.println(stream);
// 3 通过Stream.generate方法来创建
// 这是一个无限流,通过这种方法创建在操作的时候最好加上limit进行限制
Stream<Integer> generate = Stream.generate(() -> 1);
generate.limit(10).forEach(x -> System.out.println(x));
// 4 通过Stream iterate
Stream<Integer> iterate = Stream.iterate(1, x -> x + 2);
iterate.limit(100).forEach(x -> System.out.println(x));
// 5 已有类的stream源生成API
String str2 = "123456";
IntStream chars = str2.chars();
chars.forEach(x -> System.out.println(x));
}
4.4.2.2 常用转换算子
常用转换算子 filter,distinct,map,limit,skip,flatMap等
filter : 对元素进行过滤筛选,不符合的就不要了
distinct : 去掉重复的元素
skip : 跳过多少元素
limit : 取一个集合的前几条数据
map :
可以理解是在遍历集合的过程中,对元素进行操作,比如判断集合元素是否是a 返回boolean
或者对集合元素进行更改数据,比如都加 --
flatMap : 解决一个字符串数组 返回单一的字符串使用flatMap
注意只用此算子是不会真正进行计算的,只有后边调用动作算子才会真正计算。
public static void main(String[] args) {
List<String> strings = Arrays.asList("a", "b", "c", "a");
Stream<String> stream = strings.stream();
/**
* 对元素进行过滤筛选,不符合的就不要了
*/
// collect 把符合条件的转换为集合strings,属于动作算子,因为不用动作算子这些转换算子不会执行,所以看不到结果
// 只要 a
List<String> value = stream.filter(x -> x.equals("a")).collect(Collectors.toList());
// 集合中只有 a 了
System.out.println(value);
// 使用过之后,需要重新生成stream
stream = strings.stream();
/**
* 跳过1个元素 原来是 abca 现在就是 bca
*/
value = stream.skip(1).collect(Collectors.toList());
// bca
System.out.println(value);
/**
* map : 可以理解是在遍历集合的过程中,对元素进行操作,比如判断集合元素是否是a 返回boolean
* 或者对集合元素进行更改数据,比如都加--
*/
stream = strings.stream();
// 判断集合元素,这样就是booelean 是a 就是true 否则就是false
List<Boolean> value1=stream.map(x -> x.equals("a")).collect(Collectors.toList());
// true,false,false,true
System.out.println(value1);
stream = strings.stream();
// 更改集合元素
value =stream.map(x -> x+"--").collect(Collectors.toList());
// a--, b--, c--, a--
System.out.println(value);
/**
* 去掉重复元素
*/
stream = strings.stream();
value = stream.distinct().collect(Collectors.toList());
// 去除一个a 只有a,b,c
System.out.println(value);
/**
* 取一个集合的前几条数据
*/
stream = strings.stream();
value = stream.limit(2).collect(Collectors.toList());
// ab
System.out.println(value);
/**
* 解决一个字符串数组 返回单一的字符串使用flatMap
*/
strings = Arrays.asList("1,2,3", "a,b,c");
stream = strings.stream();
// 本来集合中有两个数据 "1,2,3" 和 "a,b,c"
// 会把每一个元素 以 , 分割,得到字符串数组
// 然后把数组中每一个元素,都单独拿出来
// 最终就会得到 1,2,3,a,b,c 6个元素
// 通过 collect 把这6个元素 放到集合中
value =stream.map(x -> x.split(",")).flatMap(arr -> Arrays.stream(arr)).collect(Collectors.toList());
// 1, 2, 3, a, b, c
System.out.println(value);
}
4.4.2.3 常用动作算子
循环 forEach
计算 min、max、count、average
匹配 anyMatch、allMatch、noneMatch、findFirst、findAny
汇聚 reduce
收集器 collect
public static void main(String[] args) {
List<String> strings = Arrays.asList("a", "b", "c");
Stream<String> stream = strings.stream();
// 测试forEach
stream.filter(x -> x.equals("a")).forEach(x -> System.out.println(x));
// 测试count
stream = strings.stream();
long cnt = stream.count();
System.out.println(cnt);
// 测试collect
stream = strings.stream();
List<String> list = stream.map(x -> x + "--").collect(
Collectors.toList());
System.out.println(list);
}
5. 接口中的默认方法和静态方法
5.1 概念说明
1.8之前接口中只能定义public static final的变量和public abstract修饰的抽象方法。
1.8及以后版本,不仅兼容1.8以前的,并新增了默认方法定义和静态方法定义的功能。即default方法和static方法。 让接口更灵活、更多变,更能够适应现实开发需要。
5.2 特点
默认方法
可以被重写,也可以不重写。如果重写的话,就按实现类的方法来执行。
调用的时候必须是实例化对象调用。
静态方法
跟之前的普通类的静态方法大体相同
唯一不同的是不能通过接口的实现类的对象来调用,必须是类.静态方法的方式。
5.3 应用场景
默认方法
是为了解决之前版本接口升级导致的大批实现类的强制重写方法升级的问题。
涉及到接口升级的场景可以多用,从而提高了程序的扩展性、可维护性。
静态方法
跟默认方法为类似,也是为了解决接口升级的问题,默认方法解决了接口方法增加后其子类不必要全部重写的问题,静态方法解决了一次编写静态方法所有接口及其子类通用的问题,跟lambda表达式并用效果更加,进一步提高了程序扩展性和可维护性。
允许在已有的接口中添加静态方法,接口的静态方法属于接口本身,不被继承,也需要提供方法的静态实现后,子类才可以调用。
5.4 代码实现
5.4.1 默认方法
public class _01_Interface {
public static void main(String[] args) {
MyInter inter = new MyInterImpl();
System.out.println(inter.add(3, 4));
inter.printMessage();
}
}
interface MyInter {
// 之前的用法
int add(int i, int j);
// 新加的默认方法
default void printMessage() {
System.out.println("在接口中的默认实现");
}
}
class MyInterImpl implements MyInter {
@Override
public int add(int i, int j) {
return i + j;
}
@Override
public void printMessage() {
System.out.println("在接口的实现类中的默认实现");
}
}
5.4.2 静态方法案例-1-一般情况
类名调用就行,各是各的,互不影响
public class _02_Interface {
public static void main(String[] args) {
Person.run();
Man.run();
}
}
interface Person {
public static void run() {
System.out.println("人类都可以跑!!!");
}
}
class Man implements Person {
public static void run() {
System.out.println("人类都可以跑,男人跑的更快!!!");
}
}
5.4.3 静态方法案例-2-高级使用
类名调用就行,各是各的,互不影响
public class _03_Interface {
public static void main(String[] args) {
Person_01 m1 = PersonFactory.create(Man_01::new);
m1.say();
}
}
interface PersonFactory {
public static Person_01 create(Supplier<Person_01> supplier) {
return supplier.get();
}
}
interface Person_01 {
default void say() {
System.out.println("人类会说话!!!");
}
public static void run() {
System.out.println("人类都可以跑!!!");
}
}
class Man_01 implements Person_01 {
@Override
public void say() {
System.out.println("人类会说话,男人说话更粗糙!!!");
}
public static void run() {
System.out.println("人类都可以跑,男人跑的更快!!!");
}
}
6. 新时间日期API
6.1 概念说明
新增了专用于处理时间日期API类,包括本地化、日期格式化等方面。
6.2 特点
对解决各类常见问题,更方便、更简单、更高效
6.3 应用场景
可以替换之前用Date类的各种功能操作,编程效率更高。
6.4 代码实现
6.4.1 新增核心类
均在java.time包下
LocalDate
LocalTime
LocalDateTime
DateTimeFormatter:解析和格式化日期或时间的类 由日期时间的格式组成的 类
Instant:时间戳类
Duration:间隔计算,可以计算两个时间的间隔
Period:间隔计算,计算两个日期的间隔
ZonedDate ZonedTime ZonedDateTime:时区处理类,均带有当前系统的默认时区
6.4.2 案例演示
public static void main(String[] args) {
/**
* 日期相关
*/
// 获取当前日期 yyyy-MM-dd
LocalDate now1 = LocalDate.now();
// 2020-07-11
System.out.println(now1);
// 获取年份 2020
System.out.println(now1.getYear());
// 获取月份 7
System.out.println(now1.getMonthValue());
// 获取当前是一年中的第几天 193
System.out.println(now1.getDayOfYear());
// 获取月中第几天 也就是 日期 11
System.out.println(now1.getDayOfMonth());
// 获取星期 SATURDAY (星期六)
System.out.println(now1.getDayOfWeek());
/**
* 时间相关
*/
// 获取当前时间 HH:mm:ss.SSS
LocalTime now2 = LocalTime.now();
// 18:33:38.429
System.out.println(now2);
/**
* 获取日期和时间
*
* 默认是 yyyy-MM-ddTHH:mm:ss.SSS
*
* 2020-07-11T18:35:12.954
*/
LocalDateTime now3 = LocalDateTime.now();
// 2020-07-11T18:35:12.954
System.out.println(now3);
/**
* 解析和格式化日期或时间的类 由日期时间的格式组成的 类
*
* 简单来说就是格式化日期和时间,自定义格式
*/
DateTimeFormatter formater = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH点mm分ss秒SSS毫秒");
String format = now3.format(formater);
// 2020年07月11日 18点36分34秒726毫秒
System.out.println(format);
/**
* 判断一个日期是在另一个日期之前或之后
*/
// 指定一个时间 now()是获取当前时间,of是指定时间
LocalDate of = LocalDate.of(2010, 12, 3);
// 判断 now1是否在of之后
boolean after = now1.isAfter(of);
// true
System.out.println(after);
// 判断 now1是否在of之前
boolean before = now1.isBefore(of);
// false
System.out.println(before);
}














 9728
9728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









