






首先要知道梯度下降的概念,拿二维的线性回归举例:
1. 初始化,得到一个初始线;
2. 有了初始线,可以计算所有点的误差,也就是损失函数;
对于线性回归,就是构造一个关于斜率w,以及一个关于截距b的损失函数L(w)和L(b)
3. 令,
然后导入上面的损失函数中。
这里的 t 是步长,表示梯度下降的幅度。在机器学习中,也称为学习率,因为他表示了每一步迭代,即每一次学习的影响和程度。
在我的理解中,t 值太大的话,容易错过最优值,反而导致下降速度变慢。
因此虽然你可以自拟learning rate,但在优化中还是推荐exact line search或者backtracking line search。
这里只介绍第一个,exact line search:
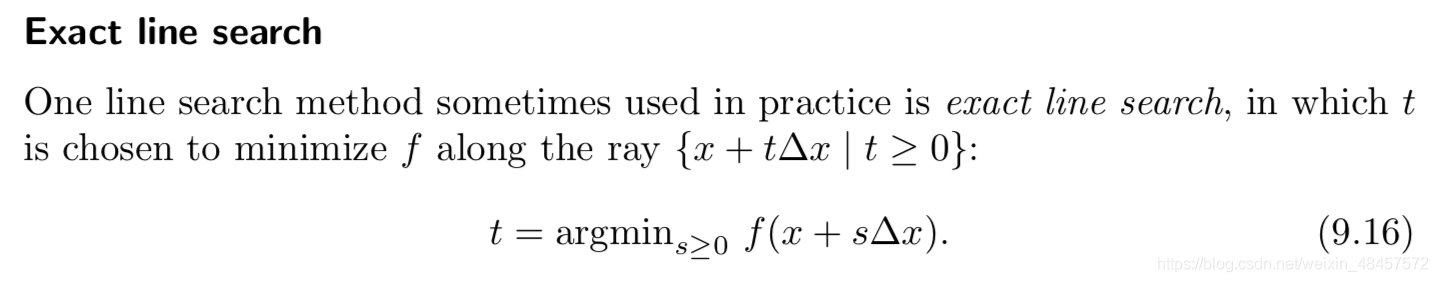
原理很简单就是把代入原损失函数后,你可以得到一个含有w和t的函数
因为损失函数通常都是二型范数,即平方差式子,最后得到的函数在假设w已知的情况下,可以得到t的最优值。
再将这个 t 值代入,你就得到了优化一步的斜率。
反复迭代,最终得到最优的w和b。
原理是这么个原理,但是每一次我们计算损失函数的时候,就有说法了。
如果我们把所有数据都用上,这种“顾全大局”的计算方式是最能体现优化效果的,我们称之为批量梯度下降。他可以通过迭代顺利到达最优点,而且每一次都肯定会有优化。
但是众所周知,我们已经是大数据时代了。
如果每一次都面对所有的样本,来计算损失函数L(w)的话,效率太慢了。如果有些数据集是以百万为单位的话,那么每次训练或者再训练模型的时候都要算一次损失函数,属实吃不消。
所以有了以下两种,每次只拿一部分的方法:
下图是一幅经典的图,来自吴恩达的深度学习课程:(蓝色是批量下降,紫色是随机下降,绿色是小批量下降)
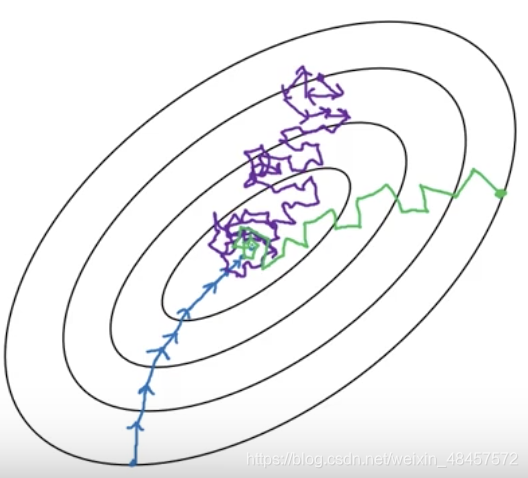
随机梯度下降:
随机梯度下降是每次随机抽取一个数据进行迭代。
这种方法可以让每次迭代的计算量最小,但既然是随机抽取一个数据,那么就会出现优化出来的w,其实不是往w最佳值的方向走的情况。
而且最终结果往往都不会是最优值,而是围绕着最佳值浮动,如图中的紫线所示。
小批量梯度下降:
小批量梯度下降是每次抽取好几个数据进行迭代。对于大型数据集来说,每批数据可以是数千或者上万。
如此一来,即保证了迭代的速度,由防止随机抽取单个样本带来的较大偏差。
虽然最后也可能得不到最优值,但围绕最优值波动的幅度更小,如图中的绿线所示。














 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









