







现在抢GPU搞智算、搞大模型训练太火了。我们先讲个小故事,把基本概念铺垫一下。
《射雕英雄传》大家都看过了哈,全真七子若是遇到黄老邪这样的BOSS,怎么办?单挑肯定打不过!

怎么办呢,群殴!但群殴也要讲究套路…
于是全真七子组了一个集群,这就是著名的天罡北斗阵。整体战斗力很强,正面硬钢黄老邪不落下风。

全真七子不仅师出同门,而且还是同代弟子。
大家的武功根基、配合默契程度极佳,所以组起阵来,可以运转如行云流水,没什么额外损耗,战斗力最强。

但是,在实际情况下,总能凑得这么整整齐齐,也是不容易的事儿。
比如谭处端遭到老毒物偷袭挂了,七子缺一子,凑不齐一整套了,怎么办?

可是这仗还要打,凑不齐整套的,那就用拼盘的。
本派弟子中的后起之秀可以临时顶一下,外部的好友高手也可以来帮个忙。

于是乎,我们就看到柯大侠上场补位。
跟原装天罡北斗阵相比,虽然默契度不大够,但照样有战斗力,能跟黄药师打个平手。

好了,射雕的故事先告一段落,通过这些练功的骚操作我们想说明几个事实:
1、大模型参数越卷越厉害,已经卷到了超级BOSS级别,不仅单卡不可能搞定,小规模集群也不行,必须万卡集群起步。(比如GPT4在1万-2.5万卡上训练,传说GPT5需要5万张H100)
2、因为各种客观原因(价格因素、供应链因素等等),我们很难凑齐一整套GPU来构建万卡集群;
3、国产卡的逐渐成熟和量产,让我们有机会尝试混合编队,凑一套能打的阵容,既能缓解算力荒,又具备更好的性价比,同时,还能让国产卡有用武之地,在实战中让其武功更加成熟。

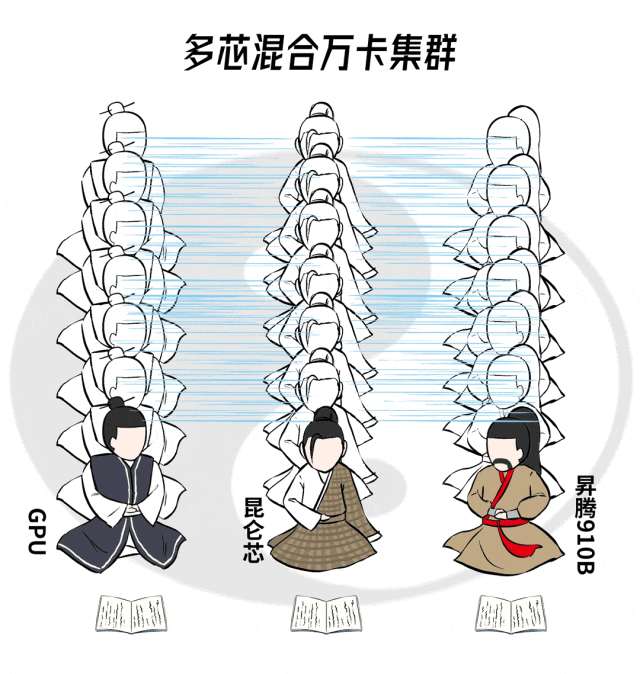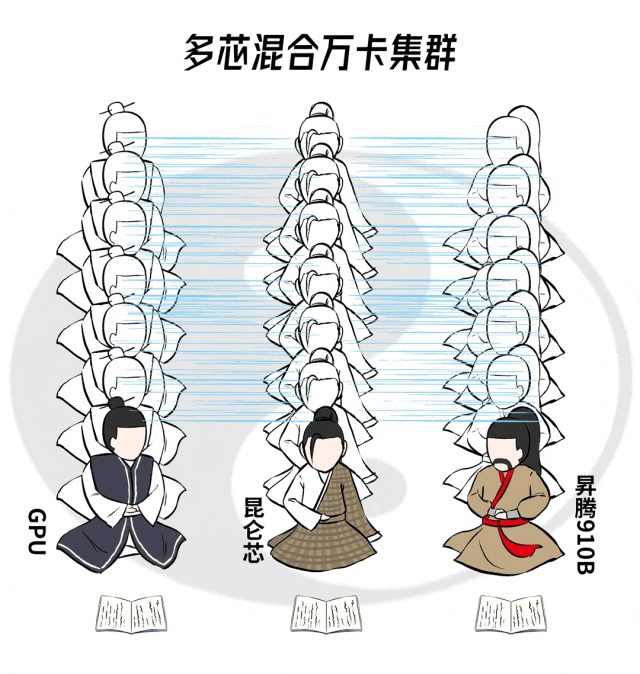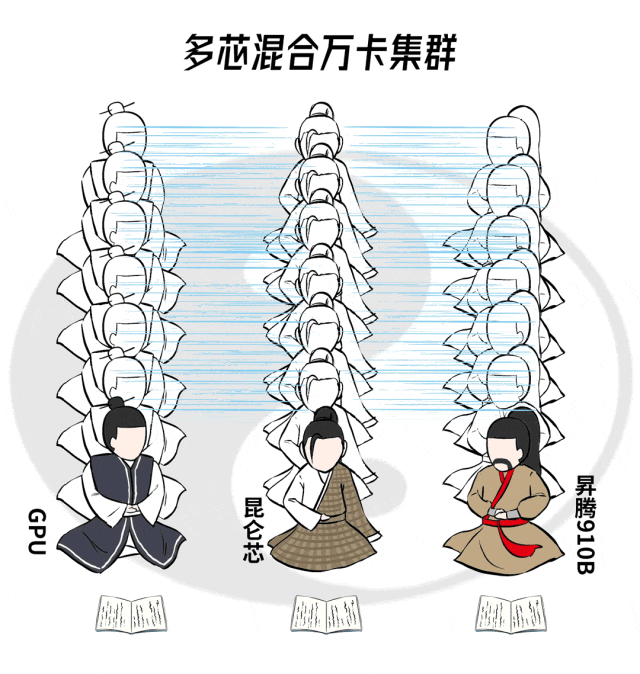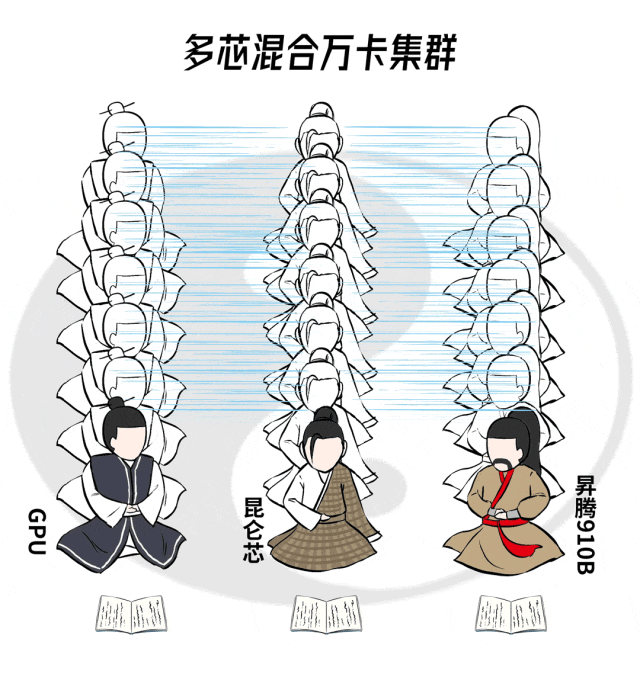
事儿就这么个事儿,但是要做起来并不容易,想要搞定多芯混合的AI算力集群,要过好几道坎儿。
我们先看原装「天罡北斗阵」是如何运转的,有三个关键点↓
❶参与布阵的弟子如何心意相通(GPU互通问题)
以N记为例,建立多卡集群,首先要完成GPU卡在物理层面连接:单台服务器内部GPU通过NVLink连接接,不同服务器之间的GPU通过IB或者RoCE网络连接。
下图展示了一台插了8张GPU卡的服务器的服务器内部,互联靠的就是NVLink。↓

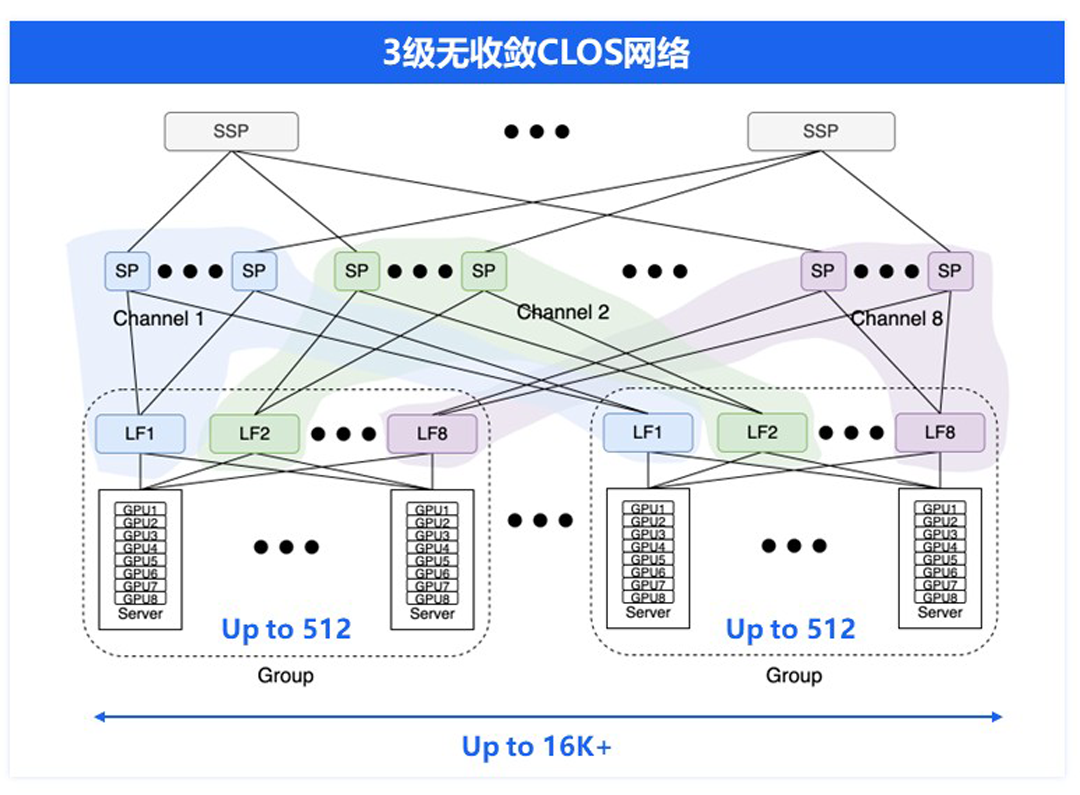
多台服务器之间的互联,百度智能云给出的示范是下面这样的,基于RoCE整个拓扑可以完成超过16000台服务器互联,GPU卡的数量超过10万张。
搞定物理连接后,接下来基于N记提供的NCCL(集合通信库),GPU之间就能实现互通互联、数据同步。
然后训练任务就可以一轮轮往下推进,直到大模型训练完成。

这个NCCL,就相当于同门师兄弟那种默契度,具备跨节点通信能力,让多GPU通信更高效、性能更好,还包含了容错能力和稳定性。
所以,这一步,如果用N记同构方案,就像原装全真七子摆阵,轻车熟路,没什么太大挑战。

❷一招一式该怎么拆解(分布式并行策略)
在大模型训练中,为了提高训练速度,需要把任务拆分到集群的所有GPU中,让大家都干活,共同完成任务。
这就是分布式并行策略,有很多种,比如数据并行、流水线并行、张量并行。
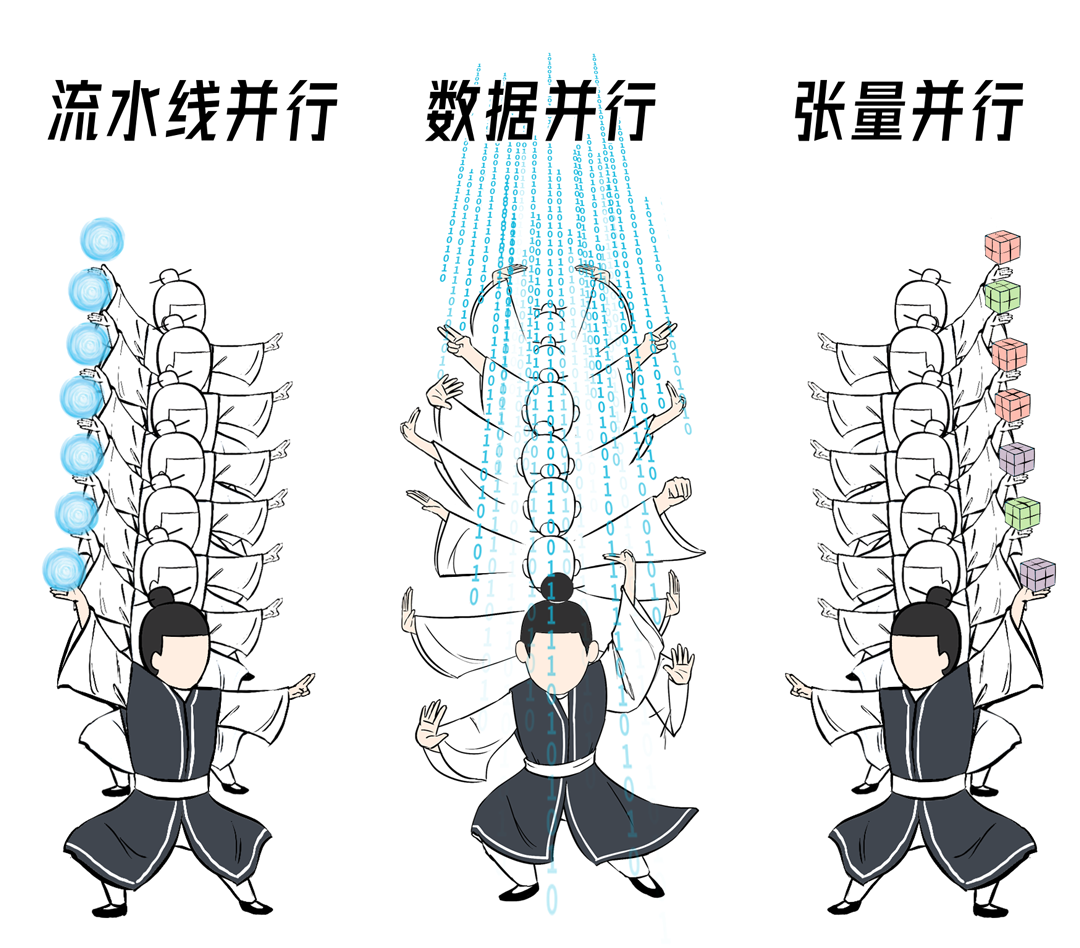
流水线并行:把模型按照神经元的层次进行拆分,不同层放到不同的GPU上去。
数据并行:每个GPU都拥有同样的模型副本,数据集则拆分成多份给到不同的GPU进行训练。
张量并行:联合多个GPU同时做一个张量计算,比如说矩阵乘法。
各种并行策略的目的,说白了就是要找到最优团队配合方式,每个人怎么出招。
面对大BOSS的时候,阵中所有人都必须全神贯注,步调一致,出招合理,谁都不能掉链子。
❸对敌时内功怎么运转(如何部署加速套件)
分布式并行策略制定好了,集群中每个GPU都领到了具体任务(一个个算子),为了让GPU更好的完成任务,还要来点加速套件。
也就是说,阵中每个人都要做到出招最伶俐、攻击力最强,这对内力修为要求很高。

这种内力(加速套件)需要包含数据加载、算子计算、多卡通信等各个方面的优化,比如数据预取加速、N记优化的算子加速能力、优化的NCCL能力等等。

小结一下,原装的「天罡北斗阵」,想有牛掰的整体战斗力,需要三板斧。
第一,搞定互联互通;第二,通过合理的分布式并行策略确保每张卡都有活干;第三,通过加速套件,提升每张卡和整体的战力输出。
看起来很有挑战,但大家是同门同派,而且还是同代弟子,同气连枝,所以难度小了很多。

当换成多芯混合算力集群的时候,同样要面临这三板斧,但因为大家不是一个门派的,难度就太大了。
稍不留神,就可能走火入魔。

1、互联互通:昆仑芯服务器内部通过XPU Link连接,服务器间通过标准的RDMA网卡连接,卡卡之间使用XCCL通信库相互通信。昇腾910B服务器内部通过HCCS连接,服务器之间通过华为自研的内置RDMA连接,卡卡之间使用HCCL通信库进行相互通信。
2、并行策略:N记GPU和昆仑芯采用单机8卡的部署方式,昇腾910B则是机内16卡分为2个8卡通信组 。这意味着在AI框架下形成不同的集群拓扑,需要有针对性地制定分布式并行策略。
3、加速套件:由于GPU、昆仑芯、昇腾等芯片在计算能力,显存大小,I/O 吞吐,通信库等均存在差异,故需要面向具体芯片进行特定优化。
不同门派的弟子,内功外功招式套路都不在一个点上,如果在一个阵里,太难协调。
所以,遇到多芯片混合,业界稳妥的做法一般就是:一种芯片一个集群,不掺和,一个门派的弟子,一套阵法。
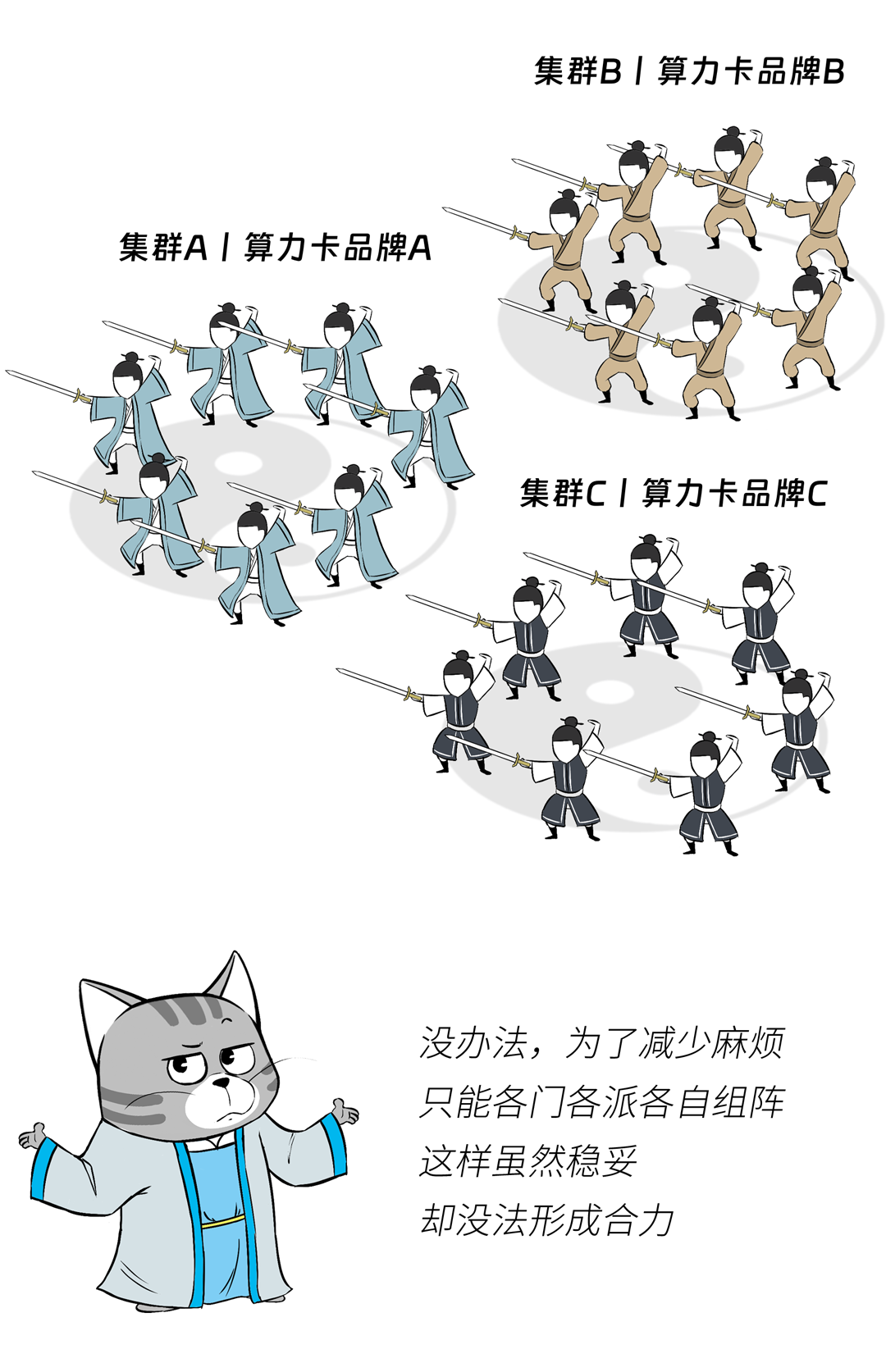
就解决不了我们前面的问题:抱团组成更大的集群。
如果真让不同门派的弟子,组成一个超级大阵,协同作战,近乎无损输出,就要搞定这几点:互联互通、并行策略、统一加速。

如今,这大模型江湖的顶级难题,被百度百舸攻克了。
百度百舸是如何做的呢?
跨芯片互联互通
前面已经讲过,N记GPU、昆仑芯、昇腾910B的物理连接方式和集合通信库都不一样。
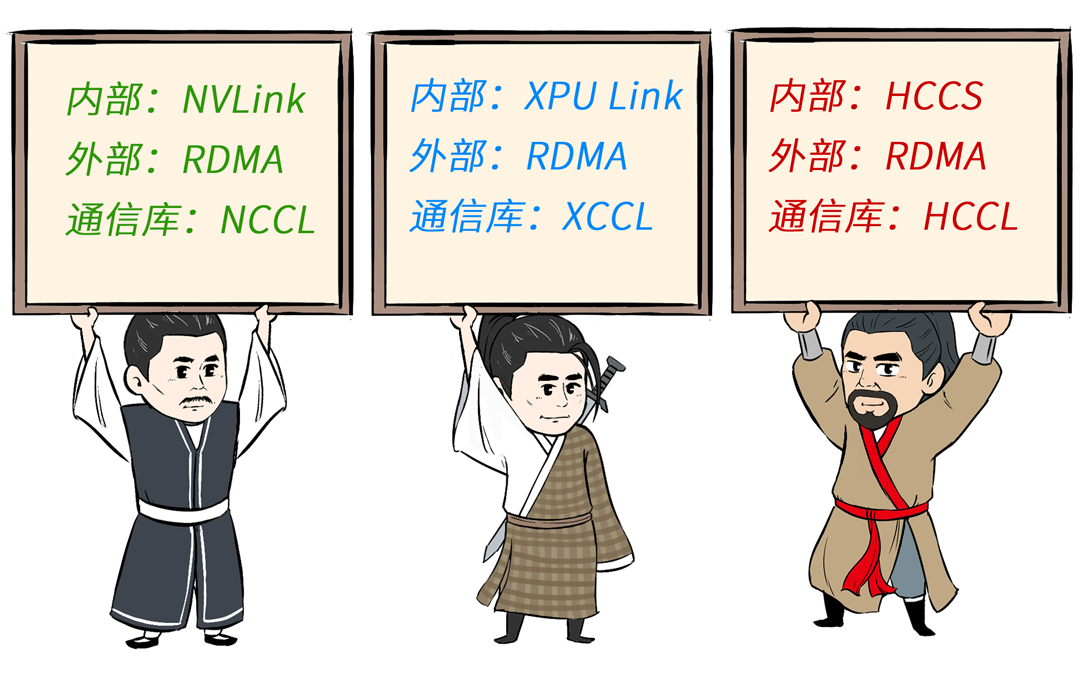
于是,百度百舸为了实现跨芯互联互通,使用了CPU转发来实现跨昇腾910B子集群和GPU子集群的连接。

同时,百度自研了集合通信库BCCL,可以实现 GPU、昆仑芯等标准 RDMA 设备的互联互通,使得通信效果达到最优。
这个BCCL呢,你可以认为是NCCL的异构增强版秘笈,可以让异构摆阵的各派弟子能够心意相通。

这样,三类算力卡(GPU、昆仑芯、昇腾910B)即完成了物理互连互通,又做到了心意相通。
超级混合大集群的雏形,就算形成了。
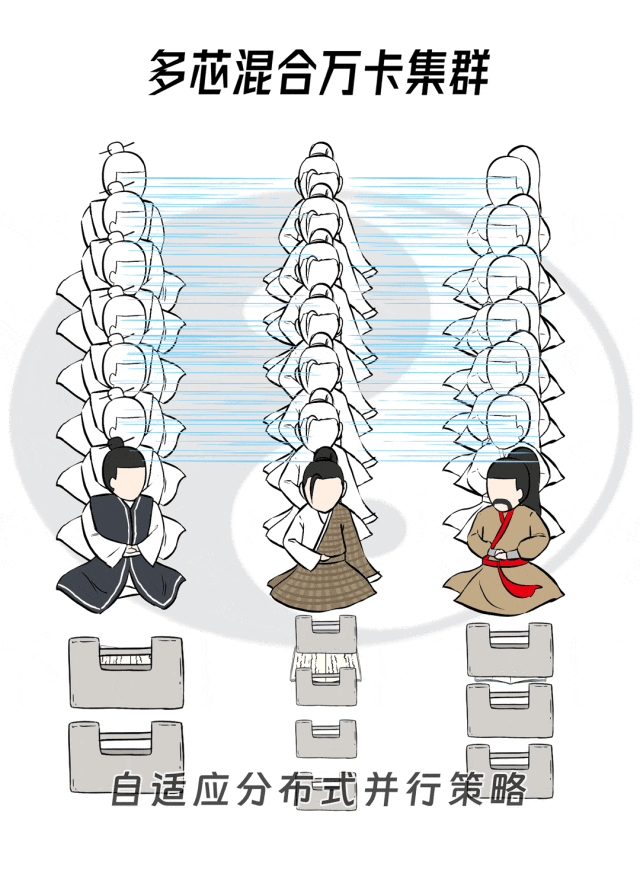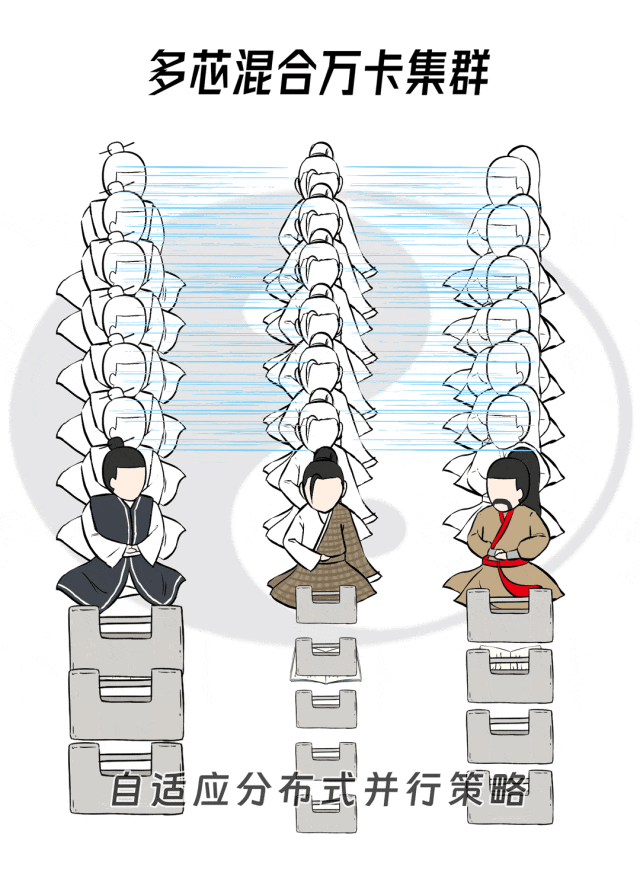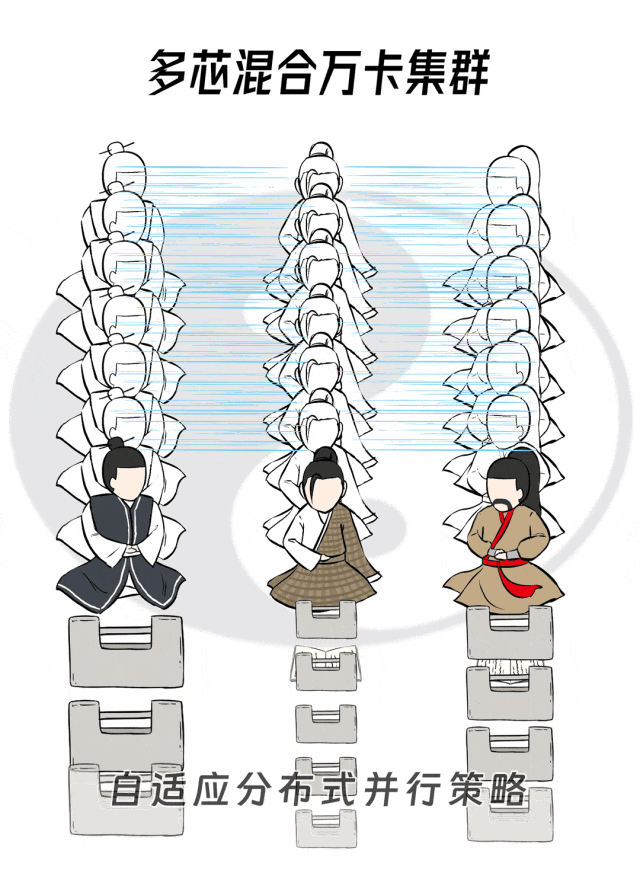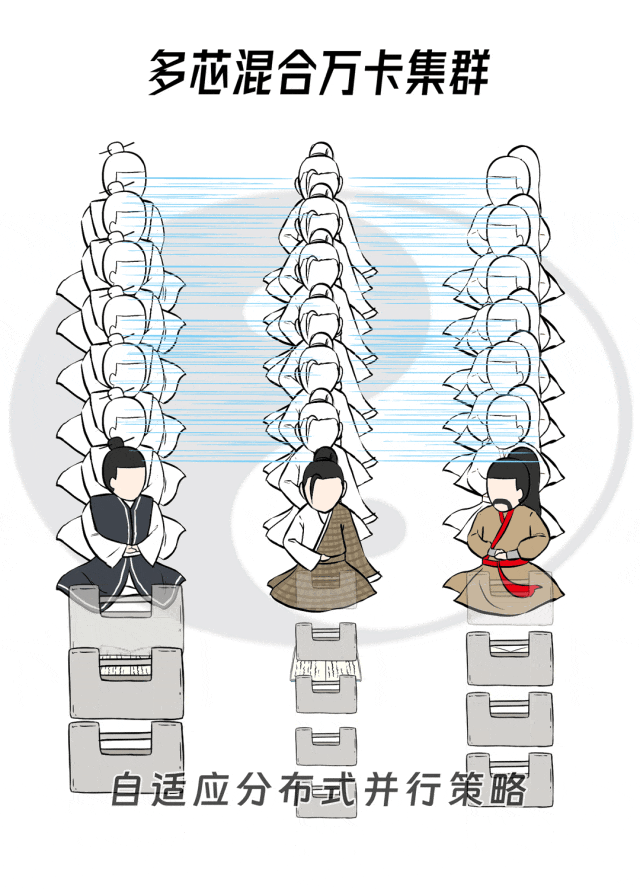
自适应并行策略搜索
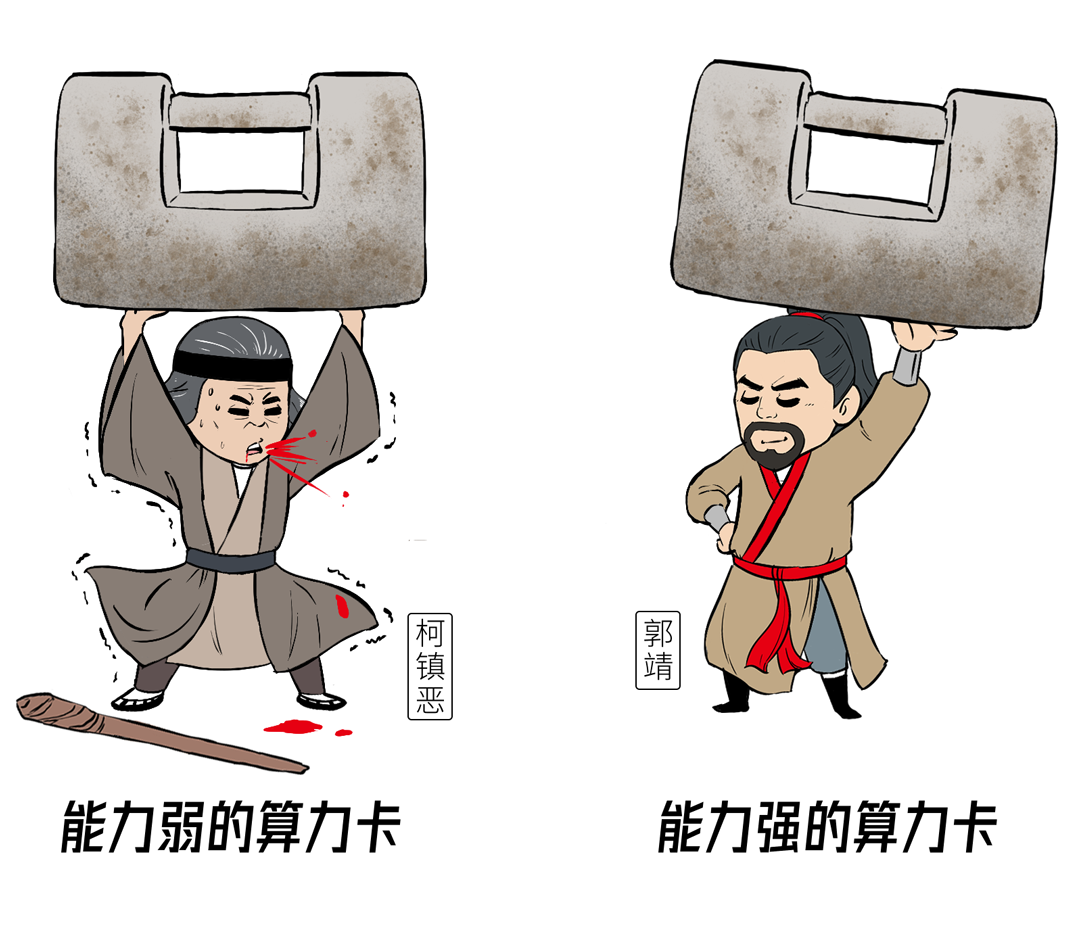
传统的并行策略,是基于每块GPU能力相同,按照等分的模式拆分大模型和训练数据。
但是,在异构芯片集群里,每家算力卡的能力都不一样,如果分相同的任务给他们,有人可能累到吐血,有的则会闲得蛋疼。
怎么办呢?
当然是根据每块算力卡扛活能力的不同,把原来均匀切分的任务变成不均匀切分,能力强的扛大活,能力弱的扛小活,人尽其力,物尽其用。

这件事其实并不简单,要找到切分任务的最优解:采用什么样组合的分布式并行策略;在不同芯片的子集群中分配多少算量,比如分配多少训练数据,多少模型层数等。
但百度百舸有妙招,百度十数年的AI技术积累形成了一本宝典:AI效能矩阵图谱,记录了不同芯片的计算和I/O效率,以及各种并行策略所需要的计算量、存储量、通信量。

这些图谱数据了然于胸后,百度百舸的AI加速套件AIAK–LLM就可以实现针对多种芯片的自适应并行策略搜索功能,从而快速得到最优切分策略。

有了智能的任务切分策略,各种芯片混搭下的单一集群,在运行大模型多芯混合训练任务时,整体效能就可以实现最大化。
加速器抽象
到了这步,就需要解决各门各派内功心法的差异。
既要让集群全局高效运转,又不能让大家自废内功,去统一练一套新的。

于是,百度百舸推出了一个面向应用的「Accelerator 抽象层」,将芯片算子与上层策略解耦开来。
这个抽象层屏蔽了底层芯片在硬件层面的差异,芯片厂商仅需要进行各自芯片的算子调优,百度百舸将之前在N记沉淀的最佳优化策略平滑迁移到各种芯片上。
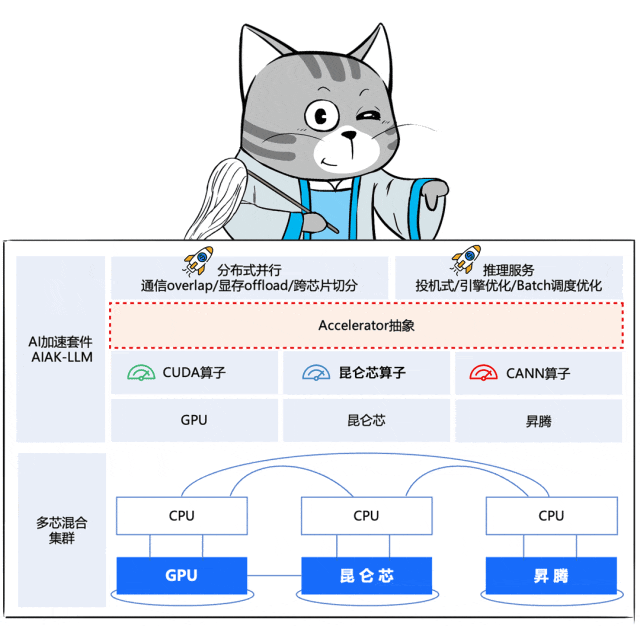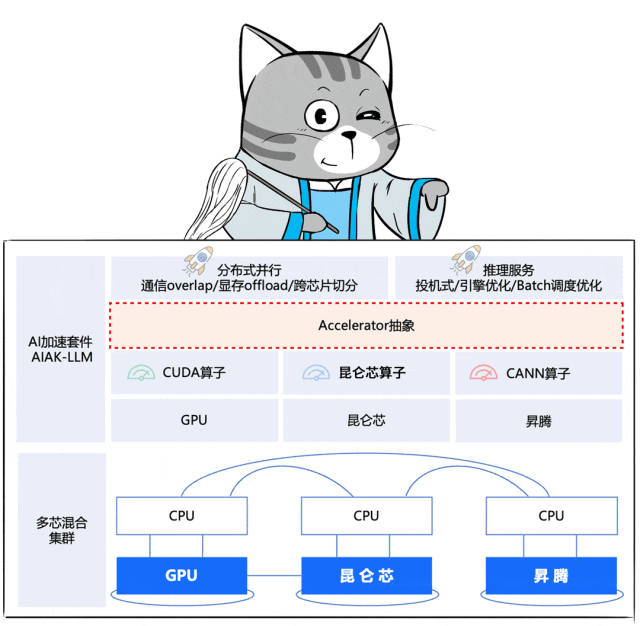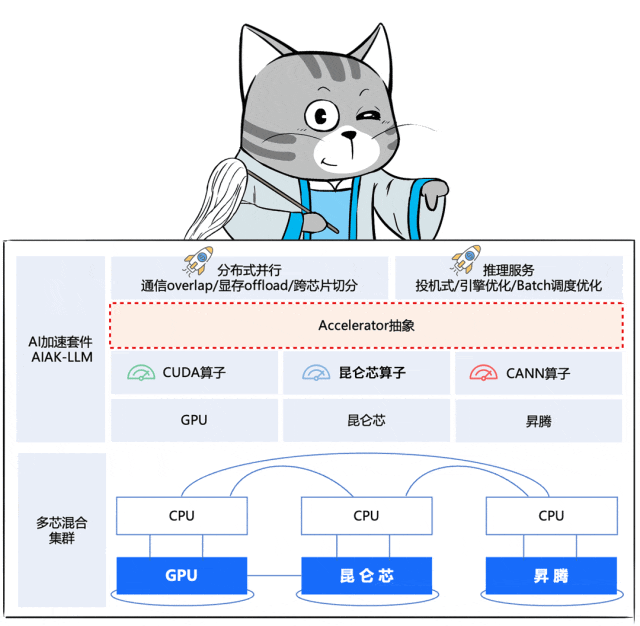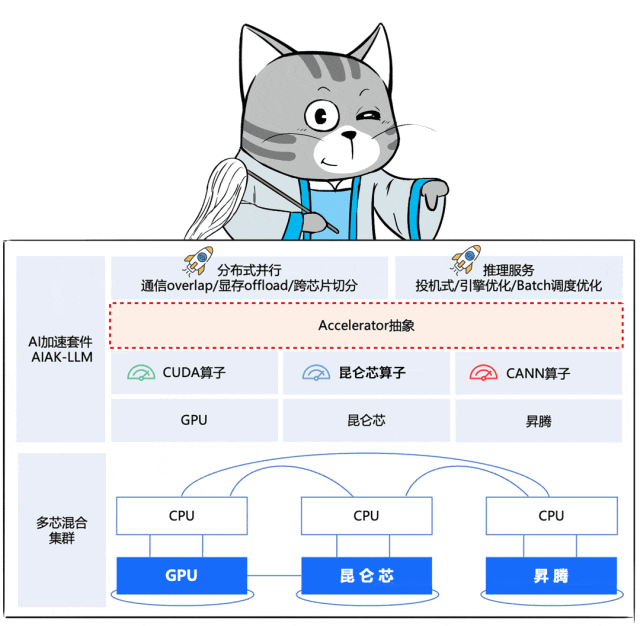
也就是说,百度百舸通过一个“化功大法”式的神操作,让各门派的原有内力发挥作用,能够打出最佳输出。
同时,还把自己修炼的心法糅合了进去(分布式并行优化、推理服务优化),两重内力叠加,共同提升大阵的战斗力。

这三步走完,混合版的「天罡北斗阵」就算组好了。
实战效果到底怎么样呢?
百度给出了多芯混合训练的效能指标,计算公式是这样的↓
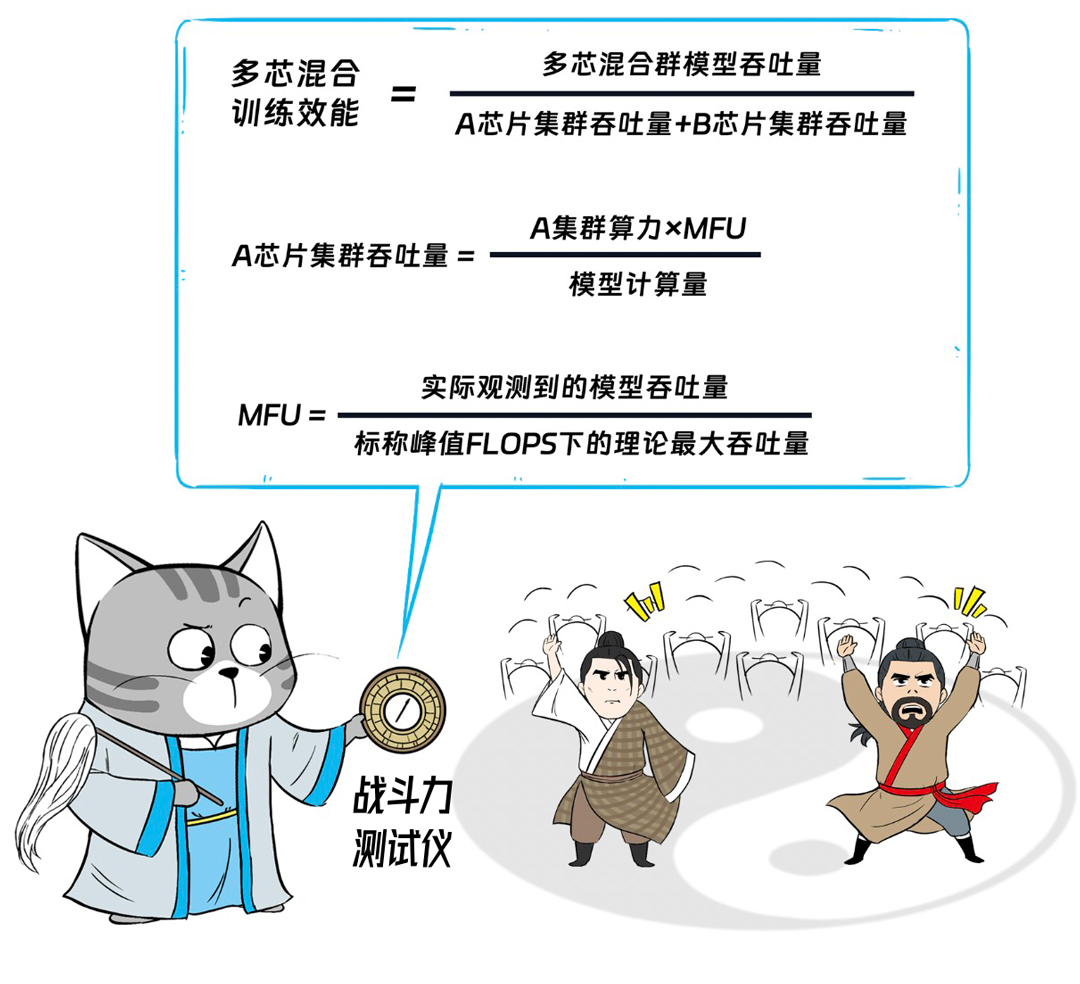
目前,百度百舸的百卡和千卡规模混合效能分别达到了惊人的97%和95%。
什么概念呢?
假设战斗力为100的A门派弟子,战斗力为80的B门派弟子,他们联合组成百人大阵,整体战斗力可以达到:(100+80)×97%=174.6!

至此,百度百舸的混合算力大阵,正式破关而出!
这套方案,可以基于百度智能云公有云交付,为云租户提供高性价比智算服务,也可以通过专有云ABC Stack进行交付,帮助用户建设异构智算中心。

在当下乃至未来相当长一段时间内,GPU算力卡短缺都是常态。
百度百舸的多芯混合训练方案,在算力近乎零损耗的前提下,可以实现新旧算力统一融合,助力大模型训练突破单一算力局限。




《时代》周刊全球100大最具影响力企业:百度获评领导者



点击阅读原文,立即合作咨询
















 7
7











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









