



创建
-
创建数据库:
- create database db_yk;
-
创建表:
-
create tabler
create tabler tsudent( /*列名 数据类型 是否为null 是否是主键 标识规范*/ Id int not null primary key identity(1,1); Id int not null primary key identity(1,1); Name varcahr(30) not null Age int not null default(20) );
-
-
删除数据库
- drop database db_yk;
增删查改:
-
插入:insert into 表名(
列名) valuse (值);insert into 表名(Id,Name,Age) valuse(1,'王五',34) insert into 表名(Name,Age) valuse('王五',34)-
当主键设置了标识规范时无法写入,需要打开下面语句
SEX IDENTITY _INSERT 表名 ON; sex identity _insert /*要插入的内容*/ SEX IDENTITY _INSERT 表名 OFF; -
一次插入多条数据:union all:合并
insert into 表名(Id,Name,Age) select '王五',11 union all select '赵六',22 union all select '李四',33 -
2005年后的版本可以直接插入多条
INSERT INTO 表名(列名) VALUES ('张三'), ('李四') -
查询结果集插入表:
select Name,Age from Student
-
-
修改:update 表名 set Name = ‘王五’ , Age = 12 where id = 1 or id = 2;
- where:筛选
-
- or =
| - and =
&&= between
- or =
-
删除:delete from 表名 where id = 1 or id = 2;
-
truncate table 表名: 清空数据保留表结构
-
drop table 表名:清空数据,结构
-
-
查询:select * from 表名
-
查询所有列
select * from 表名 --从表中查询所有列 * 所有列 select top 1 * from //一行 -
查询部分列:
- where 筛选时字符串最好使用 in、 like
--方法1. select [Name] as ,Age from 表名 --方法2. select * from 表名 where id>1 where Name in
-
关键词:
-
where: //筛选
-
like
where Name like '李%' /*以李开头*/ where Name like '%李' /*以李结尾*/ where Name like '%李%' /*包含李的*/- in
-
-
赋值:
-
select
- set
-
-
declare: //声明变量
-
一个@ 是自定义的变量名,两个@@ 是自带的变量名
-
declare @a int;
-
-
go //执行<
-
as //是一个关键字,用于为列、表或子查询结果设置别名
-
union all //把多个数据源合并为一个数据源
-
DBCC checkident (‘表名’, reseed, 0) //把表的自动编号重置为0
表
-
表(Table)
-
列(Column)
-
行(Row)
-
主键(Primary Key):唯一标识表中每一行的列,不能重复。
-
外键(Foreign Key):用于建立表与表之间的关系。
index //索引
- 聚集索引
- 每个表只能有一个
- 键值决定了表中行的物理位置
- 非聚集索引
- 可以有多个
- 叶子节点指向表中的指针
- 唯一索引
- 全文索引
创建索引:
-
创建非聚集索引:
CREATE INDEX idx_student_name ON Student(StuName); -
创建聚集索引:
CREATE UNIQUE INDEX idx_student_id ON Student(StudentID);
数据类型
1. 值类型
| SQL 数据类型 | C# 数据类型 | 说明 |
|---|---|---|
| int | int | 32 位整数。 |
| bigint | long | 64 位整数。 |
| smallint | short | 16 位整数。 |
| tinyint | byte | 8 位无符号整数(0 到 255)。 |
| decimal(p, s) | decimal | 高精度小数,p 是总位数,s 是小数位数。 |
| float | float | 单精度浮点数。 |
| real | double | 双精度浮点数。 |
| bit | bool | 布尔值(0 或 1)。 |
2. 字符串类型
| SQL 数据类型 | C# 数据类型 | 说明 |
|---|---|---|
| char(n) | string | 固定长度字符串,n 是字符数。 |
| varchar(n) | string | 可变长度字符串,n 是最大字符数。 |
| text | string | 长文本数据。 |
| nchar(n) | string | 固定长度 Unicode 字符串。 |
| nvarchar(n) | string | 可变长度 Unicode 字符串。 |
| ntext | string | 长 Unicode 文本数据。 |
3. 日期和时间类型
| SQL 数据类型 | C# 数据类型 | 说明 |
|---|---|---|
| DATE | DateTime | 日期(年月日)。 |
| TIME | TimeSpan | 时间(时分秒)。 |
| DATETIME | DateTime | 日期和时间。 |
| DATETIME2 | DateTime | 更高精度的日期和时间。 |
| SMALLDATETIME | DateTime | 低精度日期和时间。 |
| TIMESTAMP | byte[] | 自动生成的二进制值,通常用于版本控制。 |
4. 二进制类型
| SQL 数据类型 | C# 数据类型 | 说明 |
|---|---|---|
BINARY(n) | byte[] | 固定长度二进制数据。 |
VARBINARY(n) | byte[] | 可变长度二进制数据。 |
IMAGE | byte[] | 存储大型二进制对象(如图片)。 |
5. 其他类型
| SQL 数据类型 | C# 数据类型 | 说明 |
|---|---|---|
| UNIQUEIDENTIFIER / newid() | Guid | 全局唯一标识符(GUID)。 |
| XML | string | 存储 XML 数据。 |
| JSON | string | 存储 JSON 数据。 |
类型转换
显示转换
通过 cast () 或 convert () 函数显式转换数据类型:
-- 字符串转数字
cast('123' as int) ;
-- 日期转字符串
select convert(convert(10), getdate(), 112) as yyyymmdd; -- 输出格式:20231001
-- 浮点数转整数
select cast(123.45 as decimal(5,0)) as integer_value;
数据格式化
日期格式化:
select format(getdate(), 'yyyy-MM-dd HH:mm:ss') as formatted_date;
数值格式化:
-- 保留两位小数
SELECT ROUND(123.456, 2) AS rounded_value;
-- 添加千位分隔符(SQL Server)
SELECT FORMAT(1234567.89, 'N2') AS formatted_num; -- 1,234,567.89
-- 转换为百分比
SELECT CONCAT(CAST(0.85 * 100 AS DECIMAL(5,1)), '%') AS percentage; -- 85.0%
选择、循环
判断
if…else
- begin --> {
- end --> }
if
begin
-- 判断为真
end
else
begin
-- 判断为假
end
case…when…then
CASE 是一个强大的条件表达式,它允许你在查询中根据不同的条件返回不同的值,类似于其他编程语言中的 switch 语句
简单使用:
when: 用于与 表达式 进行比较的值 //如果等于
then: 当 表达式 与对应的值相等时返回的结果 //就为
CASE expression -- 要进行比较的表达式
WHEN value1 THEN result1 -- 如果等于value1 就为 result1
WHEN value2 THEN result2
...
else else_result -- 如果 expression 与所有 WHEN 子句中的值都不相等时返回的结果
END -- 结束
select case
WHEN COUNT(*)%@PageSize=0
then count(*)/@PageSize
ELSE count(*)/@PageSize+1
END
AS TotalPage
FROM CustomerInfo
循环
while
declare @i int; -- 变量以@开头
set @i = 1; -- set 赋值
while @i <= 100 -- 当 @i<=100 时运行
begin -- {
-- 要执行循环的语句
set @i = @i +1
end -- }
关联查询
关联分类:外连接,内连接,交叉连接
外连接:左外连接,右外连接,全连接
内连接:自然连接(inner join),等值连接
交叉连接: cross join
内连接 inner join

**功能:**内连接是最常用的连接类型,它返回两个表中满足连接条件的所有记录。
SELECT 列名 FROM 表1
inner join 表2
ON 表1.列a = 表2.列a; -- 返回 表1 和 表2 中 列a 相同的记录。
外连接
左外连接 left join

功能:以左表为主,返回左表所有行,右表不匹配的行用 NULL 填充。
场景:查询所有订单(无论是否有客户信息),或统计未匹配数据。
语法:left join 表名 on 连接条件
SELECT 列名 FROM 表1
left join 表2
ON 表1.列a = 表2.列a; -- -- 返回 表1 中所有记录 与 表1和表2中列a相同的记录。
右外连接 right join
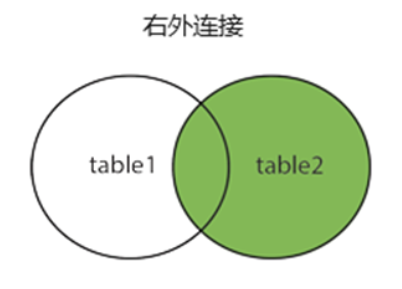
功能:以右表为主,返回右表所有行,左表不匹配的行用 NULL 填充。
场景:展示所有产品(无论是否有销售记录)。
语法:right join 表名 on 连接的条件
SELECT 列名 FROM 表1
right join 表2
ON 表1.列a = 表2.列a; -- -- 返回 表2 中所有记录 与 表1和表2中列a相同的记录。
全连接 full outer join
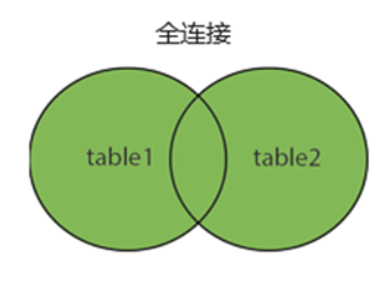
**功能:**全外连接返回两个表中的所有记录,当某行在另一个表中没有匹配的记录时,对应列的值为 NULL。
SELECT 列名 FROM 表1
full outer join 表2
ON 表1.列a = 表2.列a; -- 上述查询将返回 表1 表和 表2 表中的所有记录。
排序和分组
先where,再 group by,后 order by
排序 order by
排序: select * from 表名 order by 列名
- order by:对查询结果进行排序
-
升序:(默认asc可以去掉)
select * from 表名 order by 列名 asc -
降序:desc
select * from 表名 order by 列名 desc -
同时按多个列排序,排序有顺序:
select * from 表名 order by 列名1 asc 列名2 asc
分组(统计) group by
分组:select 列名1,列名2 from 表名
group by 列名1,列名2
- count() //统计满足条件的行数
- 使用聚合函数计算出来的列称为聚合列,聚合列可以不写到 group by 中
select
列1, 列2,
count(列1) as aaa -- 针对每个分组,统计(列1)列非空值的数量
from
表名 -- 从此表开始查
where
筛选语句
group by
列1, 列2 -- 指定分组依据的列(或表达式),(列1,和列2) 值都一样的放在一组
having
-- 筛选分组后的结果
order by -- 对查询结果进行排序
column1[ASC / DESC]; -- ASC: 升序(默认,可省略) DESC: 降序。
运算符
当字符串与数字相加,先把字符串转换为数字后再运算
EXISTS 是一个布尔运算符,用于检查子查询是否返回任何行。
内置函数
-
getdate() //获取现在时间
-
count () //
-
随机浮点数(0-1)不包含 0和1 :rand()
- 产生x-y之间的随机数:rand() * (b-a) + a
select rand() * (b-a) + a-- 生成一个 b-a 之间的随机数 -
四舍五入:round()
- 参数2为负数时表明小数点前位数
- 参数2为负数时表明小数点后位数
/*参数2.小数位*/ round(123.45,0) -- 0:小数位0个 /*参数3.为0时将舍入,为非0数时将截断*/ round(123.45,0,1) -- -
len(): 是一个常用的字符串函数,用于返回指定字符串表达式的字符数
字符串函数
-
截取
-
left():左截取字符串
select left('hello',3); -- 结果 hel -
right():右截取字符串
-
-
大小写
-
upper(‘hello’):转大写
-
lower(‘HELLO’):转小写
-
-
去除空格:trim( )
-
ltrim(’ hello’):去左边空格
-
rtrim('hello '):去右边空格
-
-
reverse
-
concat
聚合函数
计算
- 和:
- select sum(列名) from 表名
- 平均值:
- select avg(列名) from 表名
- 最大值:
- select MAX(列名) from 表名
- 最小值:
- select MIN(列名) from 表名
统计满足条件的行数:count
- count() //统计满足条件的行数
- count(*)/统计查询结果集中的行数
select count(列名) from 表 where 条件;
排名
为结果集中的行分配排名和序号,通常与 OVER() 子句结合使用,定义分組和排序规则
1. ROW_NUMBER()
- over:用于定义窗口函数的操作范围和排序规则。它指定了窗口函数在哪些行上进行计算,以及如何对这些行进行排序。
为结果集中的行分配唯一的连续序号,即使值相同也会生成不同序号。
/*把 列1 按照 列a 进行排序后保存到新建列 RowNumber 中*/
SELECT
列1
row_number() over (order by 列a desc) AS RowNumber
FROM 表名·;
2. RANK()
为行分配排名,如果值相同则排名相同,但后续排名会跳过(如并列第1后直接第3)。
SELECT
EmployeeID,
Salary,
RANK() OVER (ORDER BY Salary DESC) AS Rank
FROM Employees;
游标 cursor
@@fetch_status //游标状态
fetch //拉取
declare @a
declare @b
declare @c
/*1.声明游标*/
declare 定义游标名 cursor for
select * from 表名 where 筛选条件
/*2.打开游标*/
open 游标名;
/*3.逐行提取数据*/
fetch next from 游标名 into @a @b @c -- 获取下一行 (fetch 拉取)
while @@fetch_status = 0
begin-- {
/*业务逻辑*/
print @a
print @b
print @c
fetch next from 游标名 into @a @b @c -- 移到下一行
end-- }
/*4.关闭游标*/
close 游标名;
/*5.释放游标*/
deallocate 游标名;
分页
方法1:
使用 ROW_NUMBER() 函数
- WITH 名字 AS (…):定义了一个公共表表达式
- between:筛选出在指定范围内的数据,包含边界值
/*创建使用的变量*/
declare @PageNumber int = 2, -- 目标页码
@PageSize int = 10; -- 每页记录数
SELECT *
FROM (
SELECT
column1, column2, ..., -- 参照列
ROW_NUMBER() OVER (ORDER BY 列a [ASC | DESC]) AS RowNum
FROM 表名
) AS Subquery
where RowNum between 起始行号 and 结束行号;
-- 起始行号:(@PageNumber - 1) * @PageSize rows + 1
-- 结束行号: @PageNumber * @PageSize
方法2:
支持2012以上版本
- offset:偏移量
- order by:按照指定列对查询结果进行排序
- offset … rows:跳过指定数量的行
- fetch next… rows only:获取指定数量的行
/*创建使用的变量*/
declare @PageNumber int = 2, -- 目标页码
@PageSize int = 10; -- 每页记录数
SELECT * FROM 表名
order by 列名 -- 为所选列排序 默认升序
offset (@PageNumber - 1) * @PageSize rows -- 跳过结果集中的前..行数据
fetch next @PageSize rows only; -- 获取接下来的 .. 行数据
存储过程 proc
-
封装一段SQL语句,让SQL语句成一个整体,将来调用整体,性能高一些.
-
存储过程也有参数, 也有返回值、输入参数、输出参数
-
当存储过程复杂是建议使用事务管理
-
判断某个存储过程是否存在
-
定义一个存储过程:
- output:输出参数
create proc 存储过程名字
/*参数列表:参数名称、参数类型。每个参数以 , 隔开*/
@a varchar(50),
@b int,
@c int output -- 输出参数
as
begin -- {
执行语句
end -- }
go
-
调用:
- exec:执行
declare @v -- 用来接受输出参数 declare @return -- 用来接收返回值 exec @return = 存储过程名 '张三',10,@v output
事务
这些语句要么全部成功执行,要么全部不执行。事务确保了数据的一致性和完整性。
开始事务: begion transaction
提交事务:commit transaction //将事务中所有的操作永久保存到数据库中。
回滚事务:rollback transaction //撤销事务中已经执行的操作,将数据库恢复到事务开始前的状态。
方法1:
BEGIN TRANSACTION;
/*执行操作*/
if @@ERROR = 0
COMMIT TRANSACTION; -- 提交
else
ROLLBACK TRANSACTION; -- 回滚
方法2.异常处理:
- @@TRANCOUNT :于返回当前连接的活动事务的嵌套级别
BEGIN TRY
BEGIN TRANSACTION; -- 开始
-- 执行操作
COMMIT TRANSACTION; -- 提交
END TRY
BEGIN CATCH
if @@trancount > 0
ROLLBACK TRANSACTION; -- 回滚
throw; -- 重新抛出错误
END CATCH
事务的隔离级别
在并发环境下,为了控制事务之间的相互影响,可以设置不同的隔离级别。常见的隔离级别有:
- READ UNCOMMITTED:允许读取未提交的数据,可能会出现脏读、不可重复读和幻读问题。
- READ COMMITTED:只允许读取已提交的数据,避免了脏读,但可能会出现不可重复读和幻读问题。这是 SQL Server 的默认隔离级别。
- REPEATABLE READ:保证在同一个事务中多次读取同一数据的结果是一致的,避免了脏读和不可重复读,但可能会出现幻读问题。
- SERIALIZABLE:最高的隔离级别,保证在事务执行期间不会受到其他事务的干扰,避免了脏读、不可重复读和幻读问题,但会降低并发性能。
可以使用 SET TRANSACTION ISOLATION LEVEL 语句来设置隔离级别。
捕获异常
- throw:抛出异常
BEGIN try
--
END try
BEGIN catch
--
END catch
视图 view
- 视图是一种虚拟表,它并不实际存储数据,而是基于一个或多个表或其他视图的查询结果定义的。
- 视图可以简化数据查询、增强数据安全性、提供数据的逻辑独立性等。
- 视图中的列必须有命名
- 命名建议 v 开头
- 创建视图:
create view view_name -- 视图的名称
AS
select column1, column2 -- 要从表中选择的列
FROM table_name
where 筛选条件;
go;
-
使用视图
-- 查询视图 SELECT * FROM SalesEmployeesView;
自定义函数 function
创建:
create function f_add(@a int,@b int)
returns int -- 返回值类型(如果没有返回值可以不写)
as
begin-- {
函数体
end-- }
go
调用:
select dbo_f_add(1,2) as ffff;
触发器 trigger
会在:插入、删除、更新数据时自动触发
DML 触发器:
响应数据操作语言(DML)事件,如 INSERT、UPDATE 或 DELETE 语句。DML 触发器又可分为 AFTER 触发器和 INSTEAD OF 触发器。
- insert 触发器
- delete 触发器
- update 触发器
AFTER 触发器:在触发它的 DML 语句执行之后触发,可用于审计、日志记录等。
-- 创建 AFTER 触发器
create trigger 触发器名
ON 表名
AFTER DELETE -- AFTER DELETE 删除触发器
AS
BEGIN-- {
执行语句
END;-- }
INSTEAD OF 触发器:替代触发它的 DML 语句执行,可用于自定义数据操作逻辑。
DDL 触发器:
响应数据定义语言(DDL)事件,如 CREATE、ALTER 或 DROP 语句。DDL 触发器通常用于管理数据库架构的变更,例如防止误删除表。

















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









