





文章目录
对抗性示例改进图像识别
摘要
对抗性示例通常被视为对ConvNets的威胁。然而,我们提出了相反的观点:如果以正确的方式利用,对抗性示例可以用来改进图像识别模型。我们提出了Enhanced Adversarial Training(Enhanced AT)方法——AdvProp,将对抗性示例视为额外的训练样本,以防止过拟合。我们方法的关键在于为对抗性示例使用单独的辅助批次归一化,因为它们与正常示例有不同的潜在分布。
我们展示了AdvProp如何改进多种图像识别任务上的模型,并且在模型更大的情况下表现更好。例如,将AdvProp应用于最新的EfficientNet-B7模型,在ImageNet数据集上取得了显著的改进:ImageNet(+0.7%),ImageNet-C(+6.5%),ImageNet-A(+7.0%),Stylized-ImageNet(+4.8%)。通过增强的EfficientNet-B8,我们的方法在没有额外数据的情况下实现了最新的85.5%的ImageNet top-1准确度。这个结果甚至超过了[24]中的最佳模型,后者是用35亿个Instagram图像(比ImageNet多3000倍)和约9.4倍的参数进行训练的。模型可以在此网址https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet 找到
1.引言
通过对图像添加不可察觉的扰动来制造对抗样本,可以导致卷积神经网络(ConvNets)进行错误预测。对抗样本的存在不仅揭示了ConvNets的有限泛化能力,还对这些模型在实际部署中构成安全威胁。自从首次发现ConvNets对对抗攻击的脆弱性以来[40],已经采取了许多努力[2, 7, 15, 16, 18, 23, 29, 36, 42, 45, 50]来提高网络的鲁棒性。在本文中,我们不再专注于对抗样本的防御,而是将注意力转向利用对抗样本来提高准确性。
早期的研究表明,使用对抗样本进行训练可以提升模型的泛化能力,但这种改进只在某些情况下被观察到,要么是在完全监督设置下的小型数据集(例如MNIST)上[7, 20],要么是在半监督设置下的较大型数据集上[26, 30]。与此同时,最近的研究[18, 16, 45]也表明,在大型数据集(例如ImageNet [33])上使用对抗样本进行监督学习会导致对干净图像的性能下降。总结起来,如何有效地利用对抗样本来帮助视觉模型仍然是一个未解决的问题。

图1. AdvProp 提高了图像识别能力。通过在 ImageNet 上训练模型,AdvProp 帮助 EfficientNet-B7 [41] 在 ImageNet [33] 上达到了 85.2% 的准确率,在 ImageNet-C [9] 上达到了 52.9% 的 mCE(均匀损坏错误,数值越低越好),在 ImageNet-A [10] 上达到了 44.7% 的准确率,并在风格化的 ImageNet [6] 上达到了 26.6% 的准确率,分别比其基础模型提升了 0.7%、6.5%、7.0% 和 4.8%。这些样本图像是从"金翅雀"类别中随机选择的。
我们观察到所有先前的方法都将干净图像和对抗样本混合训练,而不加区分,尽管它们应该来自不同的基础分布。我们假设在先前的研究中,干净样本和对抗样本之间的分布不匹配是导致性能下降的关键因素[16, 18, 45]。
本文中,我们提出了一种名为AdvProp(Adversarial Propagation)的新的训练方案,它通过一个简单但极其有效的双批归一化方法来解决分布不匹配问题。具体而言,我们提出使用两种批量归一化统计量,一种用于干净图像,另一种用于辅助对抗样本。这两种批量归一化可以正确地将两个分布分离在归一化层,以便准确地估计统计数据。我们展示了这种分布分离非常关键,使我们能够成功地提高模型性能,而不是通过对抗样本使其退化。
据我们所知,我们的工作是首次显示在大规模的ImageNet数据集上,对抗样本可以在全监督设置中改善模型性能。例如,使用AdvProp训练的EfficientNet-B7在top-1准确率方面达到了85.2%,比其原始版本提高了0.8%。当对扭曲图像上的模型进行测试时,AdvProp的改进效果更为明显。正如图1所示,AdvProp帮助EfficientNet-B7在ImageNet-C、ImageNet-A和Stylized-ImageNet上分别取得了9.0%、7.0%和5.0%的绝对改进。
由于AdvProp有效地防止了过拟合,并且在较大的网络中表现更好,我们开发了一个更大的网络,名为EfficientNet-B8,遵循[41]中类似的复合缩放规则。借助我们提出的AdvProp,EfficientNet-B8在ImageNet上实现了最先进的85.5%的top-1准确率,而无需任何额外的数据。这个结果甚至超过了[24]中报道的最佳模型,该模型在3.5亿个额外的Instagram图像上进行了预训练(比ImageNet多约3000倍),并且需要比我们的EfficientNet-B8多大约9.4倍的参数。
2.相关工作
对抗训练。 对抗训练是当前防御对抗性攻击的最先进技术的基础。它通过使用对抗性样本来训练网络。尽管对抗性训练显著提高了模型的鲁棒性,但如何在对抗性训练中提高对干净图像的准确性仍然未经深入探索。虚拟对抗训练(VAT)和深度联合训练尝试在半监督设置中利用对抗性样本,但它们需要大量额外的未标记图像。在监督学习设置下,对抗性训练通常被认为会降低对干净图像的准确性,例如在CIFAR-10上约有10%的下降,在ImageNet上约有15%的下降。研究者Tsipras等人认为,对抗性鲁棒性和标准准确性之间的权衡是不可避免的,并将这一现象归因于鲁棒分类器学习的特征表示与标准分类器有根本不同。其他研究则试图从对手样本的样本复杂性增加、训练数据量的限制或网络过度参数化的角度解释这种权衡现象。本文关注的是没有额外数据的标准监督学习。尽管使用了类似的对抗性训练技术,但我们站在与之前的工作相反的角度上,我们的目标是利用对抗性样本来提高对干净图像的识别准确性。
学习对抗性特征的益处。 许多工作证实,训练使用对抗性样本可以为ConvNets带来额外的特征。例如,与干净图像相比,对抗性样本使网络表示与显著的数据特征和人类感知更加一致 [43]。此外,这样训练的模型对高频噪声更加鲁棒 [47]。张等人 [51] 还认为,这些通过对抗性学习得到的特征表示对于纹理扭曲不敏感,更加关注形状信息。我们提出的AdvProp可以被描述为一种充分利用干净图像和对应的对抗性样本相互补充的训练范式。研究结果进一步表明,对于识别模型而言,对抗性特征确实有益,这与前面提到的研究得出的结论一致。
数据增强。 数据增强是将一组保留标签的图像变换应用于训练数据,起着防止网络过拟合的重要和有效作用 [17, 35, 8]。除了传统的方法如水平翻转和随机裁剪外,还提出了不同的增强技术,例如在图像中应用遮挡[5]或向图像区域添加高斯噪声 [22],或以凸方式混合图像对及其标签 [49]。最近的研究工作还表明,可以自动学习数据增强策略,以在图像分类 [3, 4, 19, 21, 52] 和目标检测 [53, 4] 上实现更好的性能。
我们的工作可以被视为数据增强的一种类型:通过注入噪声来创建额外的训练样本。然而,所有以前的尝试,无论是随机噪声(例如[18]中的表5展示了使用随机正态扰动训练的结果)还是对抗性噪声 [16, 18, 42],都无法提高对干净图像的准确性。
3.提高性能的初步方法
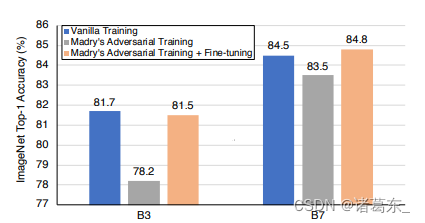
图2. 从在ImageNet上的实验中得出两个要点:(1)仅在对抗性样本上进行训练会导致性能下降;(2)仅仅是轮流使用对抗性样本和干净图像进行训练可以提高网络在干净图像上的性能。微调细节:我们在前175个时期使用对抗性样本来训练网络,然后在剩余的时期中使用干净图像进行微调。
Madry等人[23]将对抗训练定式为一个极小极大博弈,并专门在对抗性示例上训练模型以有效提高模型的稳健性。然而,如[23, 45]所示,这样训练的模型通常不能很好地推广到干净图像上。我们通过使用PGD攻击者1[23]在ImageNet上训练一个中型模型(EfficientNet-B3)和一个大型模型(EfficientNet-B7)来验证这个结果——相比其原始模型,这两个经过对抗训练的模型在干净图像上获得的准确性要低得多。例如,经过对抗训练的EfficientNet-B3只在干净图像上获得了78.2%的准确度,而原始训练的EfficientNet-B3则实现了81.7%的准确度(见图2)。
我们假设性能下降主要是由分布不匹配引起的——对抗性示例和干净图像来自两个不同的领域,因此仅在一个领域上进行训练不能很好地转移到另一个领域。如果这种分布不匹配可以得到适当的补救,即使在训练过程中使用对抗性示例,对干净图像的性能下降也应该得到缓解。为了验证我们的假设,我们在此采用一个简单的策略——首先使用对抗性示例对网络进行预训练,然后用干净图像进行微调。
结果如图2所示。正如预期的那样,这个简单的微调策略(标记为浅橙色)总是比Madry的对抗训练基准(标记为灰色)获得更高的准确性,例如,它可以将EfficientNet-B3的准确性提高3.3%。有趣的是,与仅使用干净图像的标准基准训练设置相比(标记为蓝色),这个微调策略有时甚至帮助网络实现更优秀的性能,例如,它将EfficientNet-B7的准确性提高了0.3%,在ImageNet上达到了84.8%的top-1准确度。
上面的观察结果提供了一个有希望的信号:如果恰当地利用对抗性示例,它们可以对模型性能产生益处。然而,我们注意到,这种方法通常不能提高性能,例如,尽管经过这种训练的EfficientNet-B3明显优于Madry的对抗训练基准,但它仍然略低于(-0.2%)基准训练设置。因此,一个自然的问题出现了:是否有可能以更有效的方式从对抗性示例中提取有价值的特征,从而进一步提高模型的性能?
4.方法论
第3节的结果表明,即使以简单的方式正确地整合来自对抗样本和干净图像的信息,也能改善模型的性能。然而,这种细调策略可能会部分覆盖从对抗样本中学到的特征,导致次优解。为了解决这个问题,我们提出了一种更优雅的方法,称为AdvProp,以共同学习干净图像和对抗样本。我们的方法通过显式地解耦标准化层上的批次统计量来处理分布不匹配的问题,从而更好地吸收来自对抗和干净特征的信息。在本节中,我们首先回顾了第4.1节中的对抗训练方案,然后介绍了如何通过辅助批标准化来实现混合分布的解耦学习(Sec. 4.2)。最后,我们总结了训练和测试的流程(Sec. 4.3)
4.1.对抗训练
首先我们回顾一下常规的训练设置,目标函数为:
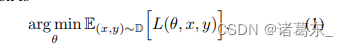
其中D是底层的数据分布,L(·,·,·)是损失函数,θ是网络参数,x是带有真实标签y的训练样本。
考虑到Madry的对抗训练框架[23],与使用原始样本进行训练不同,它使用恶意扰动的样本进行网络训练,
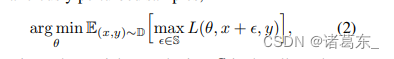
其中ε是对抗性扰动,S是允许的扰动范围。尽管这样训练的模型具有一些良好的特性,如[51、47、43]所述,但它们不能很好地推广到清晰图像[23、45]。
与Madry的对抗训练不同,我们的主要目标是通过利用对抗性示例的正则化能力来提高网络在清晰图像上的性能。因此,我们将对抗性图像视为额外的训练样本,并使用一组对抗性示例和清晰图像进行网络训练,正如[7、18]中建议的那样。
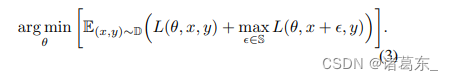
理想情况下,这样训练的模型应该同时享受对抗性领域和清晰领域的好处。然而,正如前期研究所观察到的[7、18],直接优化方程(3)通常比基本训练设置在清晰图像上表现较差。我们假设对抗性示例和清晰图像之间的分布差异阻止了网络准确有效地从两个领域中提取有价值的特征。接下来,我们将介绍如何通过我们的辅助批归一化设计恰当地解开不同分布之间的关系。
4.2.通过辅助批归一化实现解耦学习
批归一化(BN)[14]是许多最先进计算机视觉模型[8、12、39]的一个必要组件。具体而言,BN通过在每个小批量内计算平均值和方差,来对输入特征进行归一化处理。利用BN的一个内在假设是输入特征应该来自一个或几个相似的分布。如果一个小批量包含来自不同分布的数据,则该归一化行为可能会出现问题,从而导致统计估计不准确。
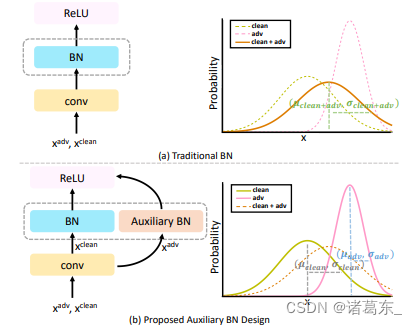
我们认为对抗性示例和清晰图像具有不同的底层分布,并且方程(3)中的对抗性训练框架本质上涉及一个双组分混合分布。为了将这种混合分布解开成两个更简单的分布分别用于清晰和对抗性图像,我们提出了一个辅助批归一化,以确保其正常化统计仅对对抗性示例进行。具体而言,如图3(b)所示,我们提出的辅助批归一化通过使属于不同领域的特征保持分开的BN,有助于解耦混合分布。否则,如图3(a)所示,仅维护一组BN统计会导致错误的统计估计,可能导致性能降低。
请注意,我们可以将这个概念推广到多个辅助批归一化(BN)上,其中辅助BN的数量由训练样本来源的数量决定。例如,如果训练数据包含清晰图像、失真图像和对抗性图像,则应该维护两个辅助BN。第5.4节中的消融研究表明,使用多个BN进行细粒度的解耦学习可以进一步提高性能。在未来的研究中,将进一步探索多个BN的更一般的用途。
4.3.AdvProp
我们在算法1中正式提出了AdvProp,以在训练过程中准确获取清晰和对抗性特征。对于每个清晰的小批量数据,我们首先使用辅助批归一化(BN)攻击网络,生成其对应的对抗性样本;接下来,我们将清晰的小批量数据和对抗性的小批量数据同时输入相同的网络,但对于损失计算使用不同的BN,即对于清晰的小批量数据使用主要的BN,对于对抗性的小批量数据使用辅助的BN;最后,我们最小化网络参数关于总损失的梯度以进行更新。换句话说,除了BN之外,卷积和其他层都是针对对抗性样本和清晰图像进行联合优化的。
值得注意的是,AdvProp中引入的辅助BN仅会增加网络训练的微不足道的额外参数,例如在EfficientNet-B7上仅比基线模型多0.5%的参数。在测试时,这些额外的辅助BN都会被丢弃,我们只使用主要的BN进行推断。

实验证明,这种解耦学习框架使网络获得比对抗性训练基线[7, 18]更强的性能。此外,与第3节中的微调策略相比,AdvProp还展示了卓越的性能,因为它使网络能够同时从对抗性样本和清晰样本中共同学习有用的特征。
5.实验
5.1.实验步骤
架构。 我们选择了EfficientNets [41] 的不同计算模式作为我们的默认架构,从轻量级的EfficientNet-B0到大型的EfficientNet-B7。与其他卷积神经网络相比,EfficientNet在准确性和效率方面表现更好。我们遵循[41]中的设置来训练这些网络:RMSProp优化器,衰减率为0.9,动量为0.9;批归一化动量为0.99;权重衰减为1e-5;初始学习率为0.256,每2.4个epoch衰减为原来的0.97;使用固定的AutoAugment策略[3]对训练图像进行增强。
对抗攻击者。 我们根据公式(3)使用对抗性样本和清晰图像的混合训练网络。我们选择具有L∞范数的投影梯度下降(PGD)[23]作为默认攻击者,用于即时生成对抗性样本。我们尝试不同扰动大小ε的PGD攻击者,范围从1到4。我们设置攻击者的迭代次数n=ε+1,除非ε=1的情况下n设置为1。攻击步长固定为α=1。
数据集。 我们使用标准的ImageNet数据集[33]来训练所有模型。除了在原始的ImageNet验证集上报告性能外,我们还通过在以下的测试集上进行测试来进一步验证模型的性能:
ImageNet-C [9]. ImageNet-C数据集旨在衡量网络对常见图像失真的鲁棒性。它包含15种多样化的失真类型,每种失真类型有五个不同程度的严重性,共计75个不同的失真水平。
ImageNet-A [10]. ImageNet-A数据集以对抗方式收集了7500张自然、未修改但“困难”的真实世界图像。这些图像来自一些具有挑战性的场景(例如遮挡和雾霾场景),对于识别任务来说是困难的。
Stylized-ImageNet [6]. Stylized-ImageNet数据集是通过使用AdaIN风格迁移[13],在保留自然图像的整体形状信息的同时去除本地纹理线索而创建的。如[6]所建议的,网络需要学习更多基于形状的表示来提高在Stylized-ImageNet上的准确性。
与ImageNet相比,ImageNet-C、ImageNet-A和Stylized-ImageNet的图像对于人类观察者来说都更具挑战性。
5.2.ImageNet结果及更多进展
ImageNet结果。 图4显示了在ImageNet验证集上的结果。我们将我们的方法与基本训练设置进行了比较。EfficientNets系列提供了一个强大的基线,例如,EfficientNet-B7的84.5%的Top-1准确率是ImageNet先前的最佳结果[41]。

图4。AdvProp在ImageNet上提升了模型的性能,超过了基本的训练基准线。如果使用更大的网络进行训练,这种改进将变得更加显著。我们最强的结果是使用AdvProp训练的EfficientNet-B7,在ImageNet上达到了85.2%的Top-1准确率。
由于使用AdvProp训练时不同的网络偏好不同的攻击者强度(我们将在下面讨论此问题),因此我们首先在图4中报告最佳结果。我们提出的AdvProp在所有网络上明显优于基本的训练基准线。性能提升与网络容量成正比,如果使用AdvProp进行训练,则较大的网络往往表现更好。例如,对于小于EfficientNet-B4的网络,性能提升最多为0.4%,但对于大于EfficientNet-B4的网络,性能提升至少为0.6%。
与先前的最佳结果相比,即84.5%的Top-1准确率,使用AdvProp训练的EfficientNet-B6(比EfficientNet-B7少约2倍的FLOPs)已经超过了0.3%。我们最强的结果是使用AdvProp训练的EfficientNet-B7,在ImageNet上实现了85.2%的Top-1准确率,比先前的最佳结果高出0.7%。
我们接下来在扭曲的ImageNet数据集上评估模型的泛化能力,这些数据集比原始的ImageNet更加困难。例如,尽管ResNet-50在ImageNet上表现出合理的性能(76.7%准确率),但在ImageNet-C上只能达到74.8%的mCE(平均损坏错误,数字越低越好),在ImageNet-A上只有3.1%的Top-1准确率,在Stylized-ImageNet上只有8.0%的Top-1准确率。
这些结果在表1中进行了总结。再次强调,我们提出的AdvProp在所有扭曲数据集上对所有模型都优于传统训练基准线。在这里,改进的幅度要比在原始ImageNet上更为显著。例如,AdvProp在ImageNet上改进了EfficientNet-B3的0.2%,而在ImageNet-C和Stylized-ImageNet上分别显著提升了5.1%和3.6%的性能。

表1显示,AdvProp显著提升了模型在ImageNet-C、ImageNet-A和Stylized-ImageNet上的泛化能力。其中,通过使用AdvProp训练的EfficientNet-B7在各个数据集上获得了最高的结果,分别为52.9%、44.7%和26.6%。对于ImageNet-C和Stylized-ImageNet,由于扭曲是针对尺寸为224×224×3的图像设计的,因此我们遵循之前的设置[6, 9],始终将测试图像的尺寸固定为224×224×3,以进行公平比较。
通过AdvProp训练的EfficientNet-B7在这些数据集上报告了最强的结果 — 在ImageNet-C上获得了52.9%的mCE,ImageNet-A上获得了44.7%的top-1准确率,以及Stylized-ImageNet上获得了26.6%的top-1准确率。如果模型不允许使用相应的扭曲训练[6]或额外的数据[24, 46],这些结果是迄今为止最好的。
综上所述,这些结果表明,AdvProp通过使模型学习比传统训练更丰富的内部表示,显著提高了泛化能力。这些更丰富的表示不仅为模型提供了更全局的形状信息,以更好地对Stylized-ImageNet数据集进行分类,还增强了模型对常见图像扭曲的鲁棒性。
对 Adversarial Attacker Strength 进行削弱实验。我们现在对 AdvProp 中的攻击者强度对网络性能的影响进行削弱实验。具体而言,攻击者的强度由扰动大小 ε 决定,其中较大的扰动大小表示攻击者更强。我们尝试了不同的 ε 值,范围从1到4,并在表2中报告了在 ImageNet 验证集上的相应准确率。
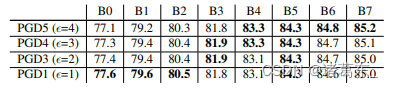
表2. 使用AdvProp训练的模型在ImageNet上的性能和不同攻击强度。通常情况下,较小的网络偏向于较弱的攻击者,而较大的网络则偏向于较强的攻击者。
通过使用AdvProp,我们观察到较小的网络通常更青睐较弱的攻击者。例如,轻量级的EfficientNet-B0通过使用1步PGD攻击者和扰动大小为1(表示为PGD1(ε=1))实现了最佳性能,明显优于使用5步PGD攻击者和扰动大小为4进行训练的模型(表示为PGD5(ε=4)),即77.6%对77.1%。这种现象可能是由于小型网络受到能够有效提取强有力对抗性示例信息的能力的限制,即使通过辅助的BN(Batch Normalization)将混合分布很好地解开。
同时,具有足够容量的网络倾向于偏向于较强的攻击者。通过将攻击者的强度从PGD1 (ε=1)增加到PGD5 (ε=4),AdvProp将EfficientNet-B7的准确率提高了0.2%。这个观察结果激发了我们后面的实验,即不断增加攻击者的强度,以充分发挥大型网络的潜力。
5.3.与对抗训练的比较
如图4和表1所示,AdvProp提高了模型的识别能力,比基于普通训练的基准模型更好。这些结果与之前的结论([18,42,16])相矛盾,即如果使用对抗样本进行训练,则总是会观察到性能下降。我们在这里提供一组说明这种不一致性的实验结果。我们默认选择PGD5(ε=4)作为攻击者,在训练过程中生成对抗性样本。
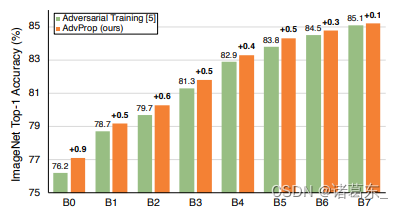
图5。AdvProp在ImageNet上明显优于对抗训练[7],尤其对于小型模型来说。
比较结果。我们将AdvProp与传统的对抗训练[7]进行比较,并在图5中报告ImageNet验证集的评估结果。与传统的对抗训练相比,我们的方法在所有模型上都能够始终获得更好的准确性。这个结果表明,仔细处理BN统计量的估计对于训练具有对抗性示例的更好模型非常重要。
最大的改进观察到在使用EfficientNet-B0模型时,我们的方法击败传统的对抗训练0.9%。而使用更大的模型时,这种改进会减小-在扩展到EfficientNet-B5时仍为约0.5%,但对于EfficientNet-B6和EfficientNet-B7分别下降到0.3%和0.1%。
量化域之间的差异。上述观察的一个可能的假设是,更强大的网络具有更强的能力在混合分布上学习统一的内部表示,因此即使没有辅助的BN,也可以减轻归一化层上的分布不匹配问题。为了支持这个假设,我们采用了AdvProp训练的模型,并比较使用主要BN或辅助BN设置之间的性能差异。由于这些结果的网络除了BN层之外都是相同的,因此相应的性能差距经验地捕捉了对抗性例子和干净图像之间的分布不匹配程度。我们使用ImageNet验证集进行评估,并在表3中总结结果。

表3. 在ImageNet上使用主要BN和辅助BN之一的设置之间的性能比较。这种性能差异捕捉了对抗性例子和干净图像之间分布不匹配的程度
通过使用更大的网络进行训练,我们观察到这种性能差异变得越来越小。对于EfficientNet-B0,这种差距为3.4%,但对于EfficientNet-B7,它减小到1.9%。这表明,在大网络上学到的对抗性例子和干净图像的内部表示要比小网络上学到的内部表示更相似。因此,通过足够强大的网络,即使没有在归一化层上进行精心处理,也可能准确有效地学习混合分布。
为什么选择AdvProp?对于小型网络,我们的比较结果显示,AdvProp在很大程度上优于对抗训练基准线。我们主要将这种性能改进归因于通过辅助BN层实现的成功解耦学习。
AdvProp是一种基于对比度损失的自监督学习方法,其中通过引入辅助的Batch Normalization(BN)层来实现对抗训练。辅助的BN层与主要的BN层进行交互,激活辅助的BN层使其能够学习混合分布上的统计信息。这种解耦学习的方法使得辅助的BN层能够更好地捕捉到对抗性例子和干净图像之间的分布差异,并有助于网络更好地区分它们。
因此,借助AdvProp,我们能够显著提升小型网络的性能,超过传统的对抗训练方法。
尽管在ImageNet数据集上改进相对较小,但对于更大的网络,AdvProp在扭曲的ImageNet数据集上始终大幅优于对抗训练基准线。如表4所示,AdvProp在ImageNet-C上将EfficientNet-B7的性能提高了3.1%,在ImageNet-A上提高了4.3%,在Stylized-ImageNet上提高了1.5%,而对抗训练基准线则相对较低。
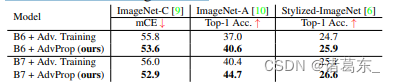
表4显示,相对于对抗训练基准线,AdvProp在扭曲的ImageNet数据集(如ImageNet-C)上展现出更强的泛化能力,特别是对于更大的模型。在这些扭曲的数据集上,AdvProp比对抗训练基准线在性能上表现更出色。
此外,使用AdvProp训练大型网络可以使其在面对更强攻击者时表现更好。例如,通过略微增加攻击者的强度(从PGD5(ε=4)到PGD7(ε=6)),AdvProp进一步帮助EfficientNet-B7在ImageNet上达到了85.3%的top-1准确率。相反,将这种攻击应用于传统的对抗训练则会使EfficientNet-B7的准确率降至85.0%,可能是由于对抗性示例和干净图像之间分布差异加剧导致的。
总结一下,AdvProp使得网络即使在容量受限的情况下也能够享受到对抗性示例的好处。对于容量足够的网络来说,与对抗训练相比,AdvProp展现出更强的泛化能力,并且更擅长利用模型容量进一步提高性能。
传统对抗训练中遗漏的部分。在我们复现的对抗训练中,我们注意到即使在大型网络上,它已经比普通训练的效果要好。例如,我们对EfficientNet-B7进行了对抗训练,在ImageNet上达到了85.1%的top-1准确率,比普通训练基准线高0.6%。然而,之前的研究[18,16]表明,对抗训练总是会降低性能。
相对于[18,16],我们在重新实施中进行了两个更改:(1)使用更强大的网络;(2)使用更弱的攻击者进行训练。例如,之前的研究在训练中使用像Inception或ResNet这样的网络,并设置扰动大小ε=16;而我们使用更强大的EfficientNet进行训练,并将扰动大小限制在较小的值ε=4。直观上,较弱的攻击者让对抗性示例的分布与干净图像的分布相差较小,而较大的网络更擅长弥合域之间的差异。这两个因素缓解了分布不匹配的问题,从而使网络更容易从两个领域中学习到有价值的特征。
5.4.消融实验
通过多个辅助批归一化实现细粒度解耦学习。按照[41]的方法,默认情况下我们使用AutoAugment [3]对网络进行训练,其中包括旋转和剪切等操作。我们推测这些操作会(稍微)改变原始数据分布,并提出添加额外的辅助批归一化(BN)来进一步解耦这些增强数据以进行细粒度学习。总共,我们保留一个主要的BN用于干净图像(不使用AutoAugment),并分别为使用AutoAugment和对抗性示例的干净图像添加两个辅助BN。
我们尝试了扰动大小在1到4之间的PGD攻击者,并在表5中报告了在ImageNet上的最佳结果。相较于默认的AdvProp方法,这种细粒度策略进一步提升了性能。它帮助EfficientNet-B0在仅有5.3M参数的情况下达到了77.9%的准确率,这是移动网络的最先进性能。相比之下,MobileNetv3具有5.4M参数和75.2%的准确率[11]。这些结果鼓励未来对更多的细粒度解耦学习与混合分布的研究,不仅仅局限在对抗性训练上

表格5。细粒度的AdvProp显著提高了Model在ImageNet上的准确性,特别是对于小型模型。我们通过为AutoAugment图像保留一个额外的辅助BN来进行细粒度的解耦学习。
与AutoAugment的比较。使用对抗性示例进行训练是一种数据增强的形式。我们选择标准的Inception风格预处理[38]作为基准,并比较同时应用AutoAugment或AdvProp的好处。我们使用PGD5(ε=4)对网络进行训练,并在ImageNet上评估性能。结果总结在表6中。对于小型模型,AutoAugment略优于AdvProp,尽管我们认为通过调整攻击者的强度可以弥补这个差距。对于大型模型,AdvProp明显优于AutoAugment。同时使用AutoAugment和AdvProp的训练比仅使用AdvProp要好。

表格6。在ImageNet上,AutoAugment和AdvProp都提高了模型性能,相比于Inception风格的预处理基准。大型模型通常在AdvProp上表现更好,而不是AutoAugment。在所有网络上,同时使用两者的组合训练要比仅使用AdvProp好。
对于除PGD外的攻击者。我们在AdvProp中研究了应用不同攻击者对模型性能的影响。具体而言,我们对PGD进行了两种不同的修改:(1)我们不再限制扰动大小在ε-球内,将此攻击者命名为梯度下降(GD),因为它去除了PGD中的投影步骤;或者(2)我们跳过PGD中的随机噪声初始化步骤,将其变为IFGSM [18]。其他攻击超参数保持不变:最大扰动大小ε=4(如果适用),攻击迭代次数n=5,攻击步长α=1.0。
为简单起见,我们只对EfficientNet-B3、EfficientNet-B5和EfficientNet-B7进行实验,并报告在表格7中的ImageNet性能。我们观察到所有攻击者显著提高了模型性能,超过了基准的普通训练。这个结果表明,我们的AdvProp并不是为特定的攻击者(例如PGD)设计的,而是一种用于改进不同对抗性攻击者的图像识别模型的通用机制。
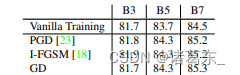
表格7。在使用不同攻击者进行训练时的ImageNet性能。通过使用AdvProp,所有攻击者都成功地改善了模型性能,超过了基准的普通训练。
ResNet结果。除了EfficientNets,我们还使用ResNet [8]进行了实验。我们将AdvProp与两个基准进行了比较:普通训练和对抗性训练。我们使用PGD5(ε=4)生成对抗性样本,并按照[8]的设置对所有网络进行训练。
我们在表格8中报告了在ImageNet上的模型性能。与普通训练相比,对抗性训练始终会降低模型性能,而AdvProp始终会在所有ResNet模型上带来更好的准确性。以ResNet-152为例,对抗性训练将基准性能降低了2.0%,但我们的AdvProp进一步提升了基准性能0.8%。

表格8。在ImageNet上对普通训练、对抗性训练和AdvProp进行性能比较。AdvProp在所有ResNet模型上报告了最佳结果。
在第5.3节中,我们表明如果使用大型的EfficientNets进行训练,对抗性训练可以提高性能。然而,这种现象在ResNet上没有观察到,即使使用大型的ResNet-200进行训练,对抗性训练仍然会导致较差的准确性。这可能表明在使用对抗性示例进行训练时架构设计也起着重要作用,我们将它留作未来的工作。
推动更大的模型边界。以前的结果表明,AdvProp在更大的网络上表现更好。为了推动边界,我们按照[41]中的复合缩放规则,进一步扩大EfficientNet-B7,训练了一个更大的网络EfficientNet-B8。
我们的AdvProp将EfficientNet-B8的准确性从84.8%提高到85.5%,在不使用额外数据的情况下,在ImageNet上实现了新的最先进准确性。这个结果甚至超过了[24]中报道的最佳模型,该模型在3.5亿额外的Instagram图像上进行了预训练(比ImageNet多大约3000倍),并且所需的参数数量(829M vs. 88M)是我们的EfficientNet-B8的大约9.4倍。
6.结论
以前的研究普遍将对抗性示例视为对ConvNets的威胁,并建议使用对抗性示例进行训练会导致对清晰图像的准确性下降。在这里,我们提供了一个不同的观点:使用对抗性示例来提高ConvNets的准确性。由于对抗性示例与正常示例具有不同的基础分布,我们提出在规范化层中使用辅助批量归一化,通过分别处理对抗性示例和清晰图像来实现解耦学习。我们的方法AdvProp显著提高了我们实验中所有ConvNets的准确性。我们的最佳模型在没有任何额外数据的情况下,在ImageNet上报告了最先进的85.5% top-1准确性。
参考文献
[1] Yair Carmon, Aditi Raghunathan, Ludwig Schmidt, John C
Duchi, and Percy S Liang. Unlabeled data improves adversarial robustness. In NeurIPS, 2019. 2
[2] Minhao Cheng, Qi Lei, Pin-Yu Chen, Inderjit Dhillon, and
Cho-Jui Hsieh. Cat: Customized adversarial training for improved robustness. arXiv preprint arXiv:2002.06789, 2020.
1
[3] Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation
policies from data. In CVPR, 2019. 2, 5, 7, 8
[4] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V
Le. Randaugment: Practical data augmentation with no separate search. arXiv preprint arXiv:1909.13719, 2019. 2
[5] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv
preprint arXiv:1708.04552, 2017. 2
[6] Robert Geirhos, Patricia Rubisch, Claudio Michaelis,
Matthias Bethge, Felix A Wichmann, and Wieland Brendel.
Imagenet-trained cnns are biased towards texture; increasing
shape bias improves accuracy and robustness. In ICLR, 2018.
1, 2, 5, 6, 7
[7] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy.
Explaining and harnessing adversarial examples. In ICLR,
2015. 1, 2, 3, 4, 6
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In CVPR,
2016. 2, 4, 8
[9] Dan Hendrycks and Thomas G Dietterich. Benchmarking
neural network robustness to common corruptions and surface variations. arXiv preprint arXiv:1807.01697, 2018. 1,
2, 5, 6, 7
[10] Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. arXiv
preprint arXiv:1907.07174, 2019. 1, 2, 5, 6, 7
[11] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh
Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu,
Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In ICCV, 2019. 7
[12] Gao Huang, Zhuang Liu, and Kilian Q Weinberger. Densely
connected convolutional networks. In CVPR, 2017. 4
[13] Xun Huang and Serge Belongie. Arbitrary style transfer in
real-time with adaptive instance normalization. In ICCV,
2017. 5
[14] Sergey Ioffe and Christian Szegedy. Batch normalization:
Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. 4
[15] Charles Jin and Martin Rinard. Manifold regularization for
adversarial robustness. arXiv preprint arXiv:2003.04286,
2018. 1
[16] Harini Kannan, Alexey Kurakin, and Ian Goodfellow. Adversarial logit pairing. arXiv preprint arXiv:1803.06373, 2018.
1, 2, 6, 7
[17] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks.
In NIPS, 2012. 2
[18] Alexey Kurakin, Ian Goodfellow, and Samy Bengio. Adversarial machine learning at scale. In ICLR, 2017. 1, 2, 3, 4, 6,
7, 8
[19] Joseph Lemley, Shabab Bazrafkan, and Peter Corcoran.
Smart augmentation learning an optimal data augmentation
strategy. IEEE Access, 2017. 2
[20] Yan Li, Ethan X Fang, Huan Xu, and Tuo Zhao. Inductive
bias of gradient descent based adversarial training on separable data. arXiv preprint arXiv:1906.02931, 2019. 1
[21] Sungbin Lim, Ildoo Kim, Taesup Kim, Chiheon Kim,
and Sungwoong Kim. Fast autoaugment. arXiv preprint
arXiv:1905.00397, 2019. 2
[22] Raphael Gontijo Lopes, Dong Yin, Ben Poole, Justin Gilmer,
and Ekin D Cubuk. Improving robustness without sacrificing
accuracy with patch gaussian augmentation. arXiv preprint
arXiv:1906.02611, 2019. 2
[23] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt,
Dimitris Tsipras, and Adrian Vladu. Towards deep learning
models resistant to adversarial attacks. In ICLR, 2018. 1, 2,
3, 5, 8
[24] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan,
Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe,
and Laurens van der Maaten. Exploring the limits of weakly
supervised pretraining. In ECCV, 2018. 1, 2, 6, 8
[25] Yifei Min, Lin Chen, and Amin Karbasi. The curious
case of adversarially robust models: More data can help,
double descend, or hurt generalization. arXiv preprint
arXiv:2002.11080, 2020. 2
[26] Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and
Shin Ishii. Virtual adversarial training: a regularization method for supervised and semi-supervised learning.
TPAMI, 2018. 1, 2
[27] Amir Najafi, Shin-ichi Maeda, Masanori Koyama, and
Takeru Miyato. Robustness to adversarial perturbations in
learning from incomplete data. In NeurIPS, 2019. 2
[28] Preetum Nakkiran. Adversarial robustness may be at odds
with simplicity. arXiv preprint arXiv:1901.00532, 2019. 2
[29] Tianyu Pang, Xiao Yang, Yinpeng Dong, Kun Xu, Hang Su,
and Jun Zhu. Boosting adversarial training with hypersphere
embedding. arXiv preprint arXiv:2002.08619, 2020. 1
[30] Siyuan Qiao, Wei Shen, Zhishuai Zhang, Bo Wang, and Alan
Yuille. Deep co-training for semi-supervised image recognition. In ECCV, 2018. 1, 2
[31] Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John
Duchi, and Percy Liang. Understanding and mitigating the
tradeoff between robustness and accuracy. arXiv preprint
arXiv:2002.10716, 2020. 2
[32] Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John C
Duchi, and Percy Liang. Adversarial training can hurt generalization. arXiv preprint arXiv:1906.06032, 2019. 2
[33] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,
Aditya Khosla, Michael Bernstein, Alexander C. Berg, and
Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015. 1, 5
[34] Ludwig Schmidt, Shibani Santurkar, Dimitris Tsipras, Kunal
Talwar, and Aleksander Madry. Adversarially robust generalization requires more data. In NeurIPS. 2
[35] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR,
2019. 2
[36] David Stutz, Matthias Hein, and Bernt Schiele. Confidencecalibrated adversarial training and detection: More robust
models generalizing beyond the attack used during training.
arXiv preprint arXiv:1910.06259, 2019. 1
[37] David Stutz, Matthias Hein, and Bernt Schiele. Disentangling adversarial robustness and generalization. In CVPR,
2020. 2
[38] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet,
Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent
Vanhoucke, and Andrew Rabinovich. Going deeper with
convolutions. In CVPR, 2015. 8
[39] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe,
Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In CVPR, 2016.
4
[40] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan
Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In ICLR, 2014. 1
[41] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model
scaling for convolutional neural networks. In ICML, 2019.
1, 2, 5, 7, 8
[42] Florian Tramer, Alexey Kurakin, Nicolas Papernot, Ian `
Goodfellow, Dan Boneh, and Patrick McDaniel. Ensemble
adversarial training: Attacks and defenses. In ICLR, 2018.
1, 2, 6
[43] Dimitris Tsipras, Shibani Santurkar, Logan Engstrom,
Alexander Turner, and Aleksander Madry. There is no free
lunch in adversarial robustness (but there are unexpected
benefits). arXiv:1805.12152, 2018. 2, 3
[44] Jonathan Uesato, Jean-Baptiste Alayrac, Po-Sen Huang, Alhussein Fawzi, Robert Stanforth, and Pushmeet Kohli. Are
labels required for improving adversarial robustness? In
NeurIPS, 2019. 2
[45] Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille,
and Kaiming He. Feature denoising for improving adversarial robustness. In CVPR, 2019. 1, 2, 3
[46] Qizhe Xie, Eduard Hovy, Minh-Thang Luong, and Quoc Le.
Self-training with noisy student improves imagenet classification. arXiv preprint arXiv:1911.04252, 2019. 6
[47] Dong Yin, Raphael Gontijo Lopes, Jonathon Shlens, Ekin D
Cubuk, and Justin Gilmer. A fourier perspective on
model robustness in computer vision. arXiv preprint
arXiv:1906.08988, 2019. 2, 3
[48] Runtian Zhai, Tianle Cai, Di He, Chen Dan, Kun He, John
Hopcroft, and Liwei Wang. Adversarially robust generalization just requires more unlabeled data. arXiv preprint
arXiv:1906.00555, 2019. 2
[49] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and
David Lopez-Paz. mixup: Beyond empirical risk minimization. In ICLR, 2018. 2
[50] Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric P Xing,
Laurent El Ghaoui, and Michael I Jordan. Theoretically principled trade-off between robustness and accuracy. In ICML,
2021. 1
[51] Tianyuan Zhang and Zhanxing Zhu. Interpreting adversarially trained convolutional neural networks. In ICML, 2019.
2, 3
[52] Xinyu Zhang, Qiang Wang, Jian Zhang, and Zhao Zhong.
Adversarial autoaugment. 2020. 2
[53] Barret Zoph, Ekin D Cubuk, Golnaz Ghiasi, Tsung-Yi Lin,
Jonathon Shlens, and Quoc V Le. Learning data augmentation strategies for object detection. arXiv preprint
arXiv:1906.11172, 2019. 2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









