







1、MySQL和ElasticSeach的对比
MySQL适合做数据的持久化存储用于CRUD,ES适合做海量数据的检索和分析
ES的入门中文文档 https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
| 名称 | ||||
|---|---|---|---|---|
| MySQL | database(数据库) | table(表) | record(记录) | filed(字段) |
| ElasticSearch | index (索引) | type(类型) | document(文档) | property(属性) |
| es的一个索引支持一个类型,之前可以支持多个7.0以后完全移除(面试点,可以深入了解下为啥) | ||||
| es中的index如果用于插入场景下相当于mysql的insert,es的document是json格式的 |
1.1为什么es适合做海量检索 — 倒排索引
1、es将每一个文档存入索引的时候
①首先会将该文档完整存入某类型
②然后会单独维护一张倒排索引表,存入的时候会对该文档进行分词,得出分词还有文档id
2、当检索的时候
①会对检索的关键词进行分词
②根据分好的词去倒排索引表中查询有哪些命中的文档记录,按照命中率排序,检索出所有相关性的记录
2、安装
①通过docker安装elasticsearch
配置es的相关配置并通过docker启动
# docker下载elasticsearch
docker pull elasticsearch:7.4.2
# 将docker里的目录挂载到linux的/mydata目录中
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改权限,es需要访问权限
chmod -R 777 /mydata/elasticsearch/
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
②通过docker安装kibana (相当于Navicat 可是化界面)
# docker下载kibana
docker pull kibana:7.4.2
# kibana指定了了ES交互端口9200 # 5600位kibana主页端口
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://172.0.0.0:9200 -p 5601:5601 -d kibana:7.4.2
# 设置开机启动kibana
docker update kibana --restart=always
3、es的初步使用
3.1 查询
① 简单查询
get /_cat/nodes: 查看所有的节点
get /_cat/health:查看es的健康状况
get /_cat/master:查看主节点信息
get /_cat/indices: 查看所有索引(相当于show databasel;)
②中级查询
查询哪个索引下的哪个类型下的哪条数据
GET customer/external/1 # 查询customer索引下的external类型下的1号数据
查询某索引下的类型有哪些属性
GET customer/_mappings # 查询customer索引下有哪些类型(原本我打算这样使用),结果发现一个index只能对应一个type,这个可以看对应type的属性
查询索引下的类型下的所有数据
GET customer/external/_search # 查询customer索引下的external类型下的所有文档
3.2 新增
①发送put请求(put不允许不带id)
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1 # 在customer索引下的external类型下保存1号数据
{
"name":"张三"
}
# 乐观锁用法:通过“if_seq_no=1&if_primary_term=1”,当序列号匹配的时候,才进行修改,否则不修改。
put带id的保存,发送多次是一个更新操作
②发送post请求
post不指定id保存,会自动返回一个唯一id,多次发送是一个创建操作
POST customer/external # 在customer索引下的external类型下保存数据
{
"name":"张三"
}
post 带id就是保存更新2合1跟put带id一样
3.3更新
post更新,可带_update(带了内容一定要加doc,带了_update会对比原数据,如果没有修改则不会加版本号),也可以不带(不会检查原数据)
如果更新的属性原数据没有,就相当于新增属性
POST customer/external/1/_update # 更新customer索引下external类型下的1号文档
{"doc":{
"id":1
}}
3.4删除
删除哪个索引下的哪个类型下的哪个文档
DELETE customer/external/1 # 删除customer索引下external类型下的1号文档
删除索引(删库)
DELETE customer # 删除customer索引下所有数据
es不支持删类型(表),可以使用_delete_by_query删,但是专业度高
详情参考:https://cloud.tencent.com/developer/article/1737025
POST index_name/_delete_by_query
{
"query": { //这些是自定义查询条件,根据查询条件去批量删除
"match": {//请求体跟Search API是一样的
"message": "some message"
}
}
}
4、使用kibana操作es
打开kibana左下角拉出dev tools在里面写es语句
GET _search
{
"query": {
"match_all": {}
}
}
# 结果如下
took:耗费了几毫秒
timed_out:是否超时,false是没有,默认无timeout
_shards:shards fail的条件(primary和replica全部挂掉),不影响其他shard。默认情况下来说,一个搜索请求,会打到一个index的所有primary shard上去,当然了,每个primary shard都可能会有一个或多个replic shard,所以请求也可以到primary shard的其中一个replica shard上去。
hits.total:本次搜索,返回了几条结果
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据,默认查询前10条数据,按_score降序排序
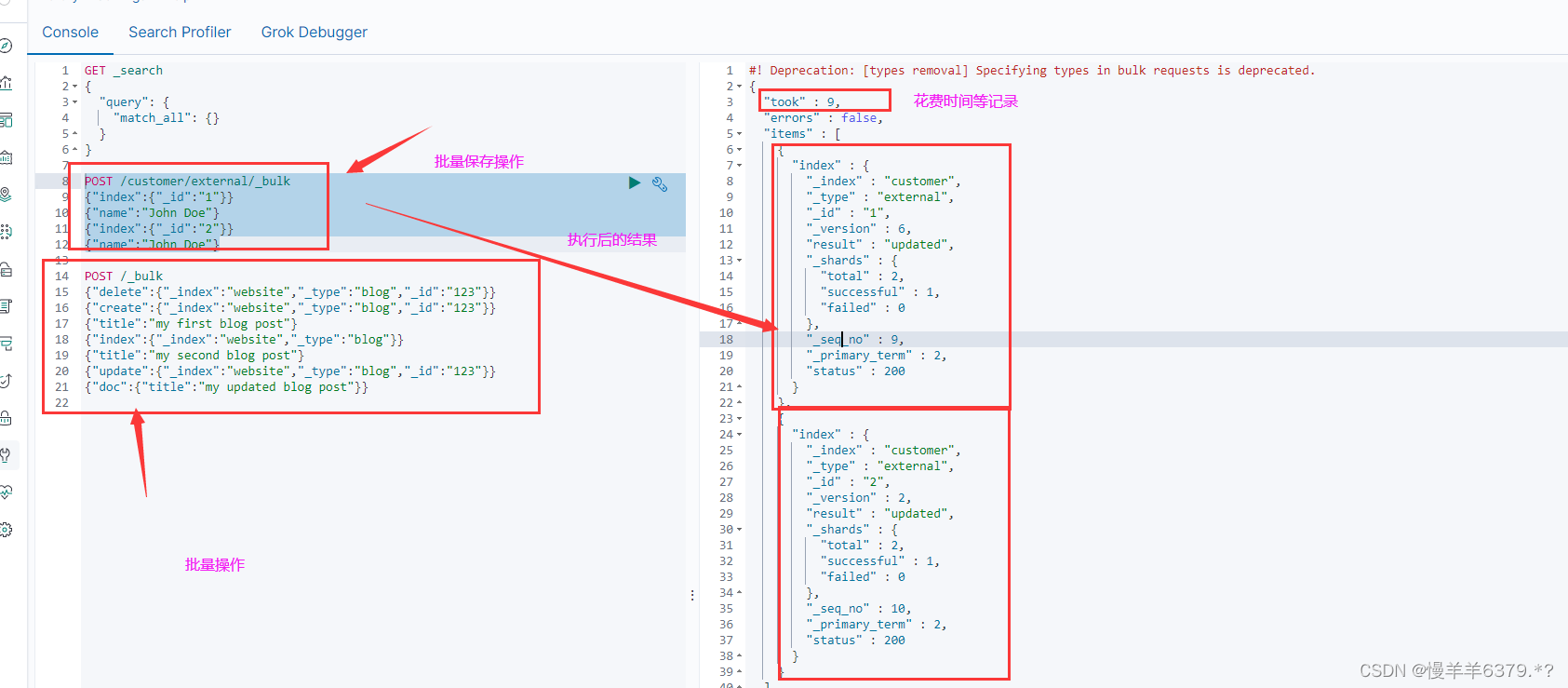
5、ES的高级检索Query DSL(domain-specific-language领域特定语言)
5.1 简单查询
前言:正在被查出来的文档要用的都在hits.hits中,具体值保存在source中

①查询index下id属性为1的文档
get /index/_search
{
"query":{
"match":{
"id":1
}
}
}
②查询bank下面的所有文档根据create_time升序排序,只查第10-19条文档
get /bank/_search
{
"query":{
"match_all":{}
},
"sort":[
{"id":{"order":"desc" }}
],
"from":10,
"size":10
}
# 简写如下
get /bank/_search
{
"query":{
"match_all":{}
},
"sort":[{"id":"desc"}],
"from":10,
"size":10
}
③只返回想要的字段(相当于select指定列)
get /index/_search
{
"query":{
"match":{
"id":1
}
},
"_source":["id","name"]
}
④全文检索(类似模糊查询)根据倒排索引进行评分排序
get /index/_search
{
"query":{
"match":{
"name":"张三是男生"
}
}
}
⑤将需要匹配的值当成一个整体不可拆分的单词进行检索
get /index/_search
{
"query":{
"match_phrase":{
"name":"张三是男生"
}
}
}
也可以写成字段.keyword
get /index/_search
{
"query":{
"match":{
"name.keyword":"张三是男生"
}
}
}
他们的区别在于keyword是精确查找,match_phrase是模糊查找
如果文档name为张三是男生呀,就只有match_phrase可以查询出结果
⑥多字段模糊查询(name是张三或者别名是张三的文档)。是进行了分词的模糊匹配
get /index/_search
{
"query":{
"multi_match":{
"name":"张三",
"fields":["name","alias"]
}
}
}
5.2 复合查询
①查询必须满足gender是F且address是mill的文档
{
"query":{
"bool":{
"must":[
{"match":{"gender":"F"}},
{"match":{"address":"mill"}}
]
}
}
}
②查询必须满足gender是F且address是mill的文档,且年龄必须不是38的人
{
"query":{
"bool":{
"must":[
{"match":{"gender":"F"}},
{"match":{"address":"mill"}}
],
"must_not":[
{"match":{"age":38 }}
]
}
}
}
③should应该满足别名是李四的不满足也可以,可以调整相关性得分
{
"query":{
"bool":{
"must":[
{"match":{"gender":"F"}},
{"match":{"address":"mill"}}
],
"must_not":[
{"match":{"age":38 }}
],
"should":[
{"match":{"alisa":"李四"}}
]
}
}
}
④must_not在处理的时候会被当作filter,这个不会贡献相关性得分,must和should会贡献相关性得分
查询年龄在20-30且address为mill的文档
{
"query":{
"bool":{
"must":[
{ "range":{"age":{
"gte":20,
"lte":30
}}
},
{"match":{ "address":"mill"}
}
]
}
}
}
⑤filter 不会贡献相关性得分,适合对查出的结果进行过滤
{
"query":{
"bool":{
"filter":[
{ "range":{"age":{
"gte":20,
"lte":30
}}
},
{"match":{ "address":"mill"}
}
]
}
}
}
⑥term:适用于精确值的匹配 match:适合文本匹配(模糊查询)
get /index/_search
{
"query":{
"term":{
"age":18
}
}
}














 4434
4434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









