






RNN循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一种主要用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN 具有循环连接,允许信息在网络中进行持续传递。
RNN 的基本结构包括一个序列输入(如文本、时间序列或视频帧等),并且每个时间步都会输出一个隐藏状态。这个隐藏状态可以被看作是网络对过去信息的记忆或总结。在每个时间步,RNN 会考虑当前输入和前一个时间步的隐藏状态,然后更新隐藏状态并产生输出。这种循环的结构使得 RNN 能够对序列中的每个元素进行建模,并且在处理具有时序关系的数据时非常有效。
由于 RNN 具有记忆能力,因此它在处理语言建模、机器翻译、时间序列预测等任务上表现出色。然而,传统的 RNN 存在梯度消失和梯度爆炸等问题,限制了其在长序列上的表现。为了解决这些问题,出现了一些改进的 RNN 变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),它们能够更好地捕捉长期依赖关系。
RNN包括输入层、隐藏层和输出层。与传统的前馈神经网络不同,RNN在隐藏层之间有循环连接,使得隐藏层可以在不同时间步之间传递。下图是RNN网络的基本结构图.
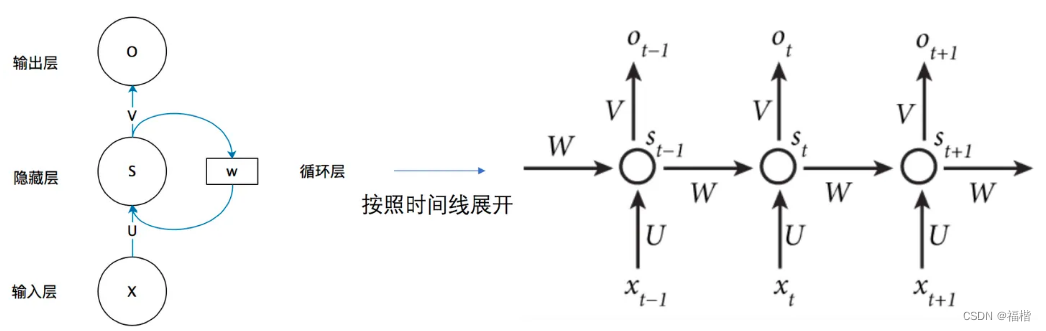
xt表示t时刻的输入, ot则表示t时刻隐藏层的状态,W是输入到隐藏层的权重,st表示隐藏层的值,用公式表示如下:
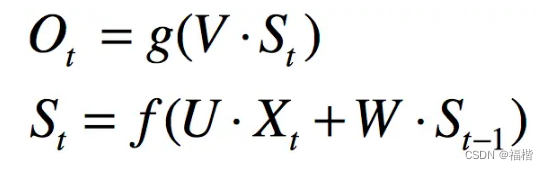
RNN工作原理
1.序列输入:RNN适用于处理序列数据,如文本,时间序列或这视频帧等等,每个时间步都有一个输入,表示序列中的一个元素。
2.隐藏状态: 在每个时间步,RNN 都会计算一个隐藏状态,这个隐藏状态可以被看作是网络对过去信息的记忆或总结。隐藏状态会在不同时间步之间传递,使得网络能够捕捉序列中的时序关系。
3.循环连接: RNN 的隐藏层之间有循环连接,允许信息在网络中进行持续传递。在每个时间步,当前输入和前一个时间步的隐藏状态会一起作为输入,用于计算当前时间步的隐藏状态。
4.输出: 在每个时间步,RNN 会根据当前输入和隐藏状态计算一个输出。输出可以用于预测、分类或生成任务。
RNN在许多领域都有着广泛的应用,包括自然语言处理(NLP),用于语言建模,情感分析,机器翻译等任务,还有时间序列分析用于股票预测,天气预测和信号处理等等,在视频处理方面可以应用于动作识别和视频生成等等.
但是传统的RNN存在梯度消失和梯度爆炸等问题,导致难以捕捉长期依赖关系.为了解决这些问题,一些更好的神经网络被提出,例如长短期记忆网络(LSTM)和门控循环单元(GRU),他们具有更好的记忆能力,能够有效处理长序列数据.
下面是利用RNN对手写字体进行分类的例子.对MINST数据集建立一个分类器.
首先要进行数据准备工作,下载MINST数据集,导入其训练数据集和测试数据集,定义两个数据集的加载器train_loader和test_loader.
import torch
import time
import copy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torch.utils.data as Data
import hiddenlayer as hl
from torch import nn
from torchvision import transforms
train_data=torchvision.datasets.MNIST(
root=".data/MINST",
train=True,
transform=transforms.ToTensor(),
download=False
)
train_loader=Data.DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
num_workers=0
)
test_data=torchvision.datasets.MNIST(
root=".data/MINST",
train=False,
transform=transforms.ToTensor(),
download=False
)
test_loader=Data.DataLoader(
dataset=test_data,
batch_size=64,
shuffle=True,
num_workers=0
)这里要注意对于windows系统,不支持多进程操作,因此num_workers需要设为0.
在导入的数据集中,训练集有60000张28*28的灰度图像,测试集有10000张28*28 的灰度图像,下面我们需要定义一个分类器:
class RNNimc(nn.Module):
def __init__(self,input_dim,hidden_dim,layer_dim,output_dim):#输入数据维度,RNN神经元个数,RNN层数,隐藏层输出维度
super(RNNimc,self).__init__()
self.hidden_dim=hidden_dim
self.layer_dim=layer_dim
self.rnn=nn.RNN(input_dim, hidden_dim, layer_dim, batch_first=True, nonlinearity='relu')##激活函数
##batch_first输入数据的形式,序列第2位,batch第1位
self.fc1=nn.Linear(hidden_dim, output_dim)
def forward(self,x):
out, h_n=self.rnn(x, None)##None表示全用0初始化
out=self.fc1(out[:, -1, :])#out是RNN最后一层的输出特征,h_n是隐藏层的输出
return out
input_dim=28
hidden_dim=128
layer_dim=1
output_dim=10
MyRNNimc=RNNimc(input_dim,hidden_dim,layer_dim,output_dim)在这里我定义了RNNmic类,针对图像分类器,其值是图片中每行的数据像素点量,针对手写字体数据其值等于28,input_dim是图片每行的像素数量,hidden_dim是RNN神经元的个数,layer_dim=1是RNN的层数,out_put是隐藏层输出的维度,包含10类图像.
定义并确认好网络结构之后,就开始训练了,在这之前定义了优化器和损失函数,使用训练集对网络训练30个epoch.
optimizer=torch.optim.RMSprop(MyRNNimc.parameters(),lr=0.003)#优化器
criterion=nn.CrossEntropyLoss()#损失函数
train_loss_all=[]
train_acc_all=[]
test_loss_all=[]
test_acc_all=[]
num_epochs=30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch,num_epochs-1))
MyRNNimc.train()#设置模型为训练模式
corrects=0
train_num=0
for step,(b_x,b_y) in enumerate(train_loader):
xdata=b_x.view(-1,28,28)
output=MyRNNimc(xdata)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)#计算真实值和预测值之间的差值
optimizer.zero_grad()#可以避免迭代过程中梯度的不正确累积
loss.backward()
optimizer.step()
loss += loss.item()*b_x.size(0)#取出张量具体位置的元素值
corrects += torch.sum(pre_lab == b_y.data)
train_num+=b_x.size(0)
train_loss_all.append(loss/train_num)
train_acc_all.append(corrects.double().item()/train_num)
print('{} Train Loss: {:.4f} Train Acc: {:.4f}'.format(epoch,train_loss_all[-1],train_acc_all[-1]))
MyRNNimc.eval()
corrects=0
test_num=0
for step,(b_x,b_y) in enumerate(test_loader):
xdata=b_x.view(-1,28,28)
output=MyRNNimc(xdata)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)
loss+=loss.item()*b_x.size(0)
corrects+=torch.sum(pre_lab==b_y.data)
test_num+=b_x.size(0)
test_loss_all.append(loss/test_num)
test_acc_all.append(corrects.double().item()/test_num)
print('{} Test Loss: {:.4f} Test Acc: {:.4f}'.format(epoch, test_loss_all[-1], test_acc_all[-1]))
torch.save(MyRNNimc.state_dict(), 'myRNNimc.pth')
MyRNNimc.load_state_dict(torch.load('myRNNimc.pth'))
训练过程:
训练之后,我们将网络在训练集和测试集上的损失即预测精度利用折线图可视化
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
train_loss_all_np=np.array(train_loss_all)
test_loss_all_np=np.array(test_loss_all)
plt.plot(train_loss_all_np,"ro-",label="Train loss")
plt.plot(test_loss_all_np,"bs-",label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1,2,2)
train_acc_all_np=np.array(train_acc_all)
test_acc_all_np=np.array(test_acc_all)
plt.plot(train_acc_all_np,"ro-",label="Train acc")
plt.plot(test_acc_all_np,"bs-",label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()得到的折线图如下:
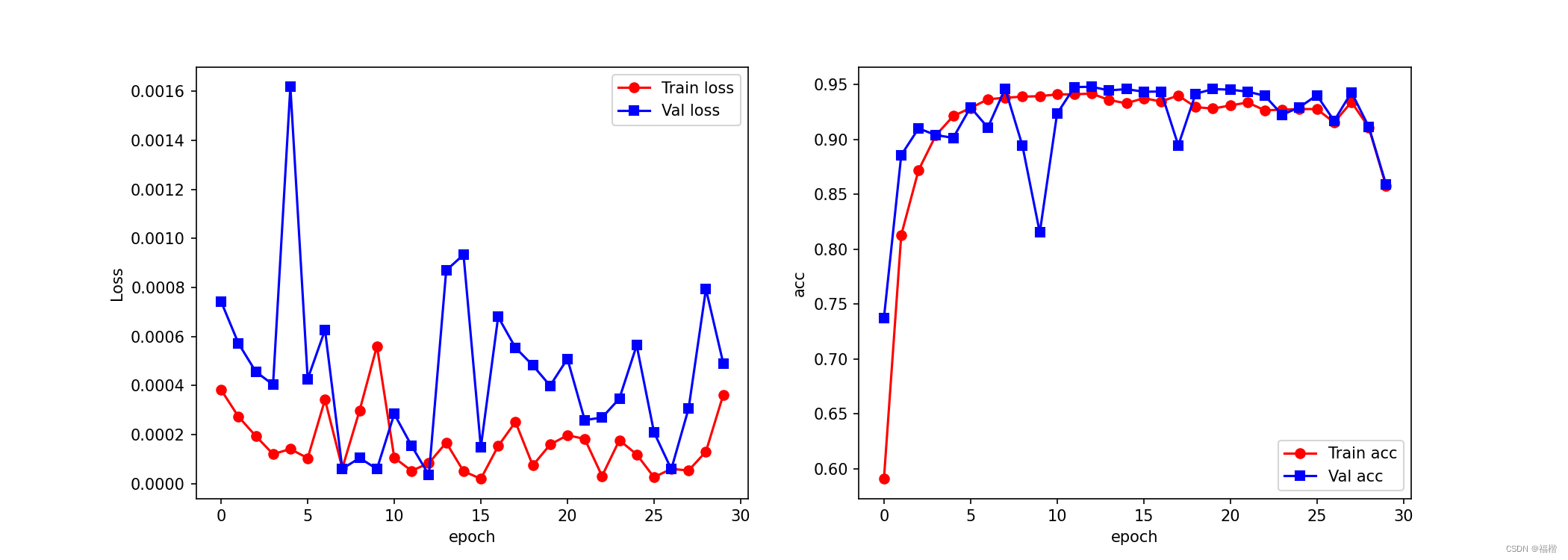 训练集的预测精度大约稳定在0.92左右,测试集的预测精度波动较大,趋向于0.94.
训练集的预测精度大约稳定在0.92左右,测试集的预测精度波动较大,趋向于0.94.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









